Introduction
In today’s data-driven landscape, businesses must integrate data from various sources to derive actionable insights and make informed decisions. This crucial process, called Extract, Transform, Load (ETL), involves extracting data from multiple origins, transforming it into a consistent format, and loading it into a target system for analysis. With data volumes growing at an unprecedented rate, organizations face significant challenges in maintaining their ETL processes’ speed, accuracy, and scalability. This guide delves into strategies for optimizing data integration and creating efficient ETL workflows.

Learning Objectives
- Understand ETL processes to integrate and analyze data from diverse sources effectively.
- Evaluate and select appropriate ETL tools and technologies for scalability and compatibility.
- Implement parallel data processing to enhance ETL performance using frameworks like Apache Spark.
- Apply incremental loading techniques to process only new or updated data efficiently.
- Ensure data quality through profiling, cleansing, and validation within ETL pipelines.
- Develop robust error handling and retry mechanisms to maintain ETL process reliability and data integrity.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Understanding Your Data Sources
- Choosing the Right Tools and Technologies
- Parallel Data Processing
- Implementing Incremental Loading
- Detailed Steps and Example Code
- Monitoring and Optimising Performance
- Data Quality Assurance
- Error Handling and Retry Mechanisms
- Scalability and Resource Management
- Frequently Asked Questions
Understanding Your Data Sources
Before diving into ETL development, it’s crucial to have a comprehensive understanding of your data sources. This includes identifying the types of data sources available, such as databases, files, APIs, and streaming sources, and understanding the structure, format, and quality of the data within each source. By gaining insights into your data sources, you can better plan your ETL strategy and anticipate any challenges or complexities that may arise during the integration process.
Choosing the Right Tools and Technologies
Selecting the appropriate tools and technologies is critical for building efficient ETL pipelines. Numerous ETL tools and frameworks are available in the market, each offering unique features and capabilities. Some popular options include Apache Spark, Apache Airflow, Talend, Informatica, and Microsoft Azure Data Factory. When choosing a tool, consider scalability, ease of use, integration capabilities, and compatibility with your existing infrastructure. Additionally, evaluate whether the tool supports the specific data sources and formats you need to integrate.
Parallel Data Processing
One highly effective way to enhance ETL process performance is by parallelizing data processing tasks. This involves dividing these tasks into smaller, independent units that can run simultaneously across multiple processors or nodes. By harnessing the power of distributed systems, parallel processing can dramatically reduce processing time. Apache Spark is a widely used framework that supports parallel data processing across extensive clusters. By partitioning your data and utilizing Spark’s capabilities, you can achieve substantial performance gains in your ETL workflows.
To run the provided PySpark script, you must install the necessary dependencies. Here’s a list of the required dependencies and their installation commands:
- PySpark: This is the primary library for working with Apache Spark in Python.
- Pandas (optional if you need to manipulate data with Pandas before or after Spark processing).
You can install these dependencies using pip:
pip install pyspark pandasfrom pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder \
.appName("ParallelETLExample") \
.getOrCreate()
# Define the function to process each partition
def process_partition(partition):
# Example processing: convert to list of tuples (this can be any transformation logic)
return [(row['id'], row['name'], row['age']) for row in partition]
# Load data from source
source_data = spark.read.csv("file:///home/rahul/source_data.csv", header=True, inferSchema=True)
# Perform parallel processing
processed_data = source_data.repartition(4).rdd.mapPartitions(process_partition)
# Convert processed RDD back to DataFrame
processed_df = processed_data.toDF(['id', 'name', 'age'])
# Show the processed data
processed_df.show()
# Write processed data to destination
processed_df.write.csv("file:///home/rahul/processed_data", mode="overwrite", header=True)
# Stop Spark session
spark.stop()
In this example, we’re using Apache Spark to parallelize data processing from a CSV source. The repartition(4) method distributes the data across four partitions for parallel processing, improving efficiency.
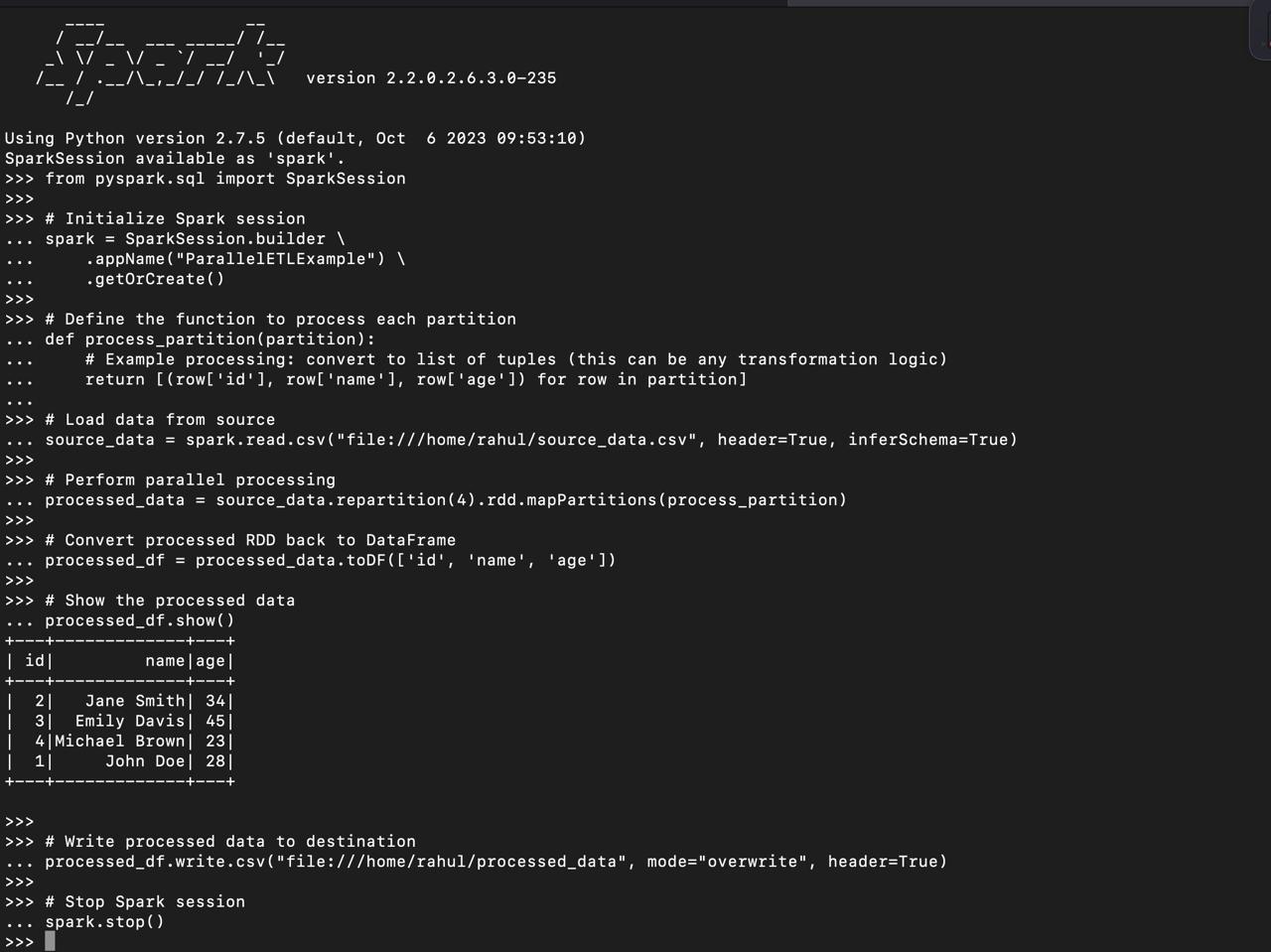
source_data.csv file, here’s a small example of how you can create it locally:
id,name,age
1,John Doe,28
2,Jane Smith,34
3,Emily Davis,45
4,Michael Brown,23Implementing Incremental Loading
Instead of processing the entire dataset each time, consider using incremental loading techniques to handle only new or updated data. Incremental loading focuses on identifying and extracting just the data that has changed since the last ETL run, which reduces processing overhead and minimizes resource use. This approach can be implemented by maintaining metadata or using change data capture (CDC) mechanisms to track changes in your data sources over time. By processing only the incremental changes, you can significantly boost the efficiency and performance of your ETL processes.
Detailed Steps and Example Code
Let’s walk through an example to demonstrate how incremental loading can be implemented using SQL. We’ll create a simple scenario with source and target tables and show how to load new data into a staging table and merge it into the target table.
Step 1: Create the Source and Target Tables
First, let’s create the source and target tables and insert some initial data into the source table.
sql
-- Create source table
CREATE TABLE source_table (
id INT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255),
timestamp DATETIME
);
-- Insert initial data into source table
INSERT INTO source_table (id, column1, column2, timestamp) VALUES
(1, 'data1', 'info1', '2023-01-01 10:00:00'),
(2, 'data2', 'info2', '2023-01-02 10:00:00'),
(3, 'data3', 'info3', '2023-01-03 10:00:00');
-- Create target table
CREATE TABLE target_table (
id INT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255),
timestamp DATETIME
);
In this SQL example, we’re loading new data from a source table into a staging table based on a timestamp column. Then, we use a merge operation to update existing records in the target table and insert new records from the staging table.
Step 2: Create the Staging Table
Next, create the staging table that temporarily holds the new data extracted from the source table.
-- Create staging table
CREATE TABLE staging_table (
id INT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255),
timestamp DATETIME
);
Step 3: Load New Data into the Staging Table
We’ll write a query to load new data from the source table into the staging table. This query will select records from the source table where the timestamp is greater than the maximum timestamp in the target table.
-- Load new data into staging table
INSERT INTO staging_table
SELECT *
FROM source_table
WHERE source_table.timestamp > (SELECT MAX(timestamp) FROM target_table);Step 4: Merge Data from Staging to Target Table
Finally, we use a merge operation to update existing records in the target table and insert new records from the staging table.
-- Merge staging data into target table
MERGE INTO target_table AS t
USING staging_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET t.column1 = s.column1, t.column2 = s.column2, t.timestamp = s.timestamp
WHEN NOT MATCHED THEN
INSERT (id, column1, column2, timestamp)
VALUES (s.id, s.column1, s.column2, s.timestamp);
-- Clear the staging table after the merge
TRUNCATE TABLE staging_table;Explanation of Each Step
- Extract New Data: The INSERT INTO staging_table statement extracts new or updated rows from the source_table based on the timestamp column. This ensures that only the changes since the last ETL run are processed.
- Merge Data: The MERGE INTO target_table statement merges the data from the staging_table into the target_table.
- Clear Staging Table: After the merge operation, the TRUNCATE TABLE staging_table statement clears the staging table to prepare it for the next ETL run.
Monitoring and Optimising Performance
Regularly monitoring your ETL processes is crucial for pinpointing bottlenecks and optimizing performance. Use tools and frameworks like Apache Airflow, Prometheus, or Grafana to track metrics such as execution time, resource utilization, and data throughput. Leveraging these performance insights allows you to fine-tune ETL workflows, adjust configurations, or scale infrastructure as needed for continuous efficiency improvements. Additionally, implementing automated alerting and logging mechanisms can help you identify and address performance issues in real time, ensuring your ETL processes remain smooth and efficient
Data Quality Assurance
Ensuring data quality is crucial for reliable analysis and decision-making. Data quality issues can arise from various sources, including inaccuracies, inconsistencies, duplicates, and missing values. Implementing robust data quality assurance processes as part of your ETL pipeline can help identify and rectify such issues early in the data integration process. Data profiling, cleansing, validation rules, and outlier detection can be employed to improve data quality.
# Perform data profiling
data_profile = source_data.describe()
# Identify duplicates
duplicate_rows = source_data.groupBy(source_data.columns).count().where("count > 1")
# Data cleansing
cleaned_data = source_data.dropna()
# Validate data against predefined rules
validation_rules = {
"column1": lambda x: x > 0,
"column2": lambda x: isinstance(x, str),
}
invalid_rows = cleaned_data.filter ----(write Filter conditions here)...
In this Python example, we perform data profiling, identify duplicates, perform data cleansing by removing null values, and validate data against predefined rules to ensure data quality.
Error Handling and Retry Mechanisms
Despite best efforts, errors can occur during the execution of ETL processes for various reasons, such as network failures, data format mismatches, or system crashes. Implementing error handling and retry mechanisms is essential to ensure the robustness and reliability of your ETL pipeline. Logging, error notification, automatic retries, and back-off strategies can help mitigate failures and ensure data integrity.
from tenacity import retry, stop_after_attempt, wait_fixed
@retry(stop=stop_after_attempt(3), wait=wait_fixed(2))
def process_data(data):
# Process data
...
# Simulate potential error
if error_condition:
raise Exception("Error processing data")
try:
process_data(data)
except Exception as e:
# Log error and notify stakeholders
logger.error(f"Error processing data: {e}")
notify_stakeholders("ETL process encountered an error")
This Python example defines a function to process data with retry and back-off mechanisms. If an error occurs, the function retries the operation up to three times with a fixed wait time between attempts.
Scalability and Resource Management
As data volumes and processing requirements grow, ensuring the scalability of your ETL pipeline becomes paramount. Scalability involves efficiently handling increasing data volumes and processing demands without compromising performance or reliability. Implementing scalable architectures and resource management strategies allows your ETL pipeline to scale seamlessly with growing data loads and user demands. Techniques such as horizontal scaling, auto-scaling, resource pooling, and workload management can help optimize resource utilization and ensure consistent performance across varying workloads and data volumes. Additionally, leveraging cloud-based infrastructure and managed services can provide elastic scalability and alleviate the burden of infrastructure management, allowing you to focus on building robust and scalable ETL processes.
Conclusion
Efficient data integration is critical for organizations to unlock the full potential of their data assets and drive data-driven decision-making. By implementing strategies such as parallelizing data processing, incremental loading, and performance optimization, you can streamline your ETL processes and ensure the timely delivery of high-quality insights. Adapt these strategies to your specific use case and leverage the right tools and technologies to achieve optimal results. With a well-designed and efficient ETL pipeline, you can accelerate your data integration efforts and gain a competitive edge in today’s fast-paced business environment.
Key Takeaways
- Understanding your data sources is crucial for effective ETL development. It allows you to anticipate challenges and plan your strategy accordingly.
- Choosing the right tools and technologies based on scalability and compatibility can streamline your ETL processes and improve efficiency.
- Parallelizing data processing tasks using frameworks like Apache Spark can significantly reduce processing time and enhance performance.
- Implementing incremental loading techniques and robust error-handling mechanisms ensures data integrity and reliability in your ETL pipeline.
- Scalability and resource management are essential considerations to accommodate growing data volumes and processing requirements while maintaining optimal performance and cost efficiency.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Q1. What is ETL, and why is it important?
A. ETL stands for Extract, Transform, Load. It is a process used to extract data from various sources, transform it into a consistent format, and load it into a target system for analysis. ETL is crucial for integrating data from disparate sources and making it accessible for analytics and decision-making.
Q2. How can I improve the performance of my ETL processes?
A. You can improve the performance of your ETL processes by parallelizing data processing tasks, implementing incremental loading techniques to process only new or updated data, optimizing resource allocation and utilization, and monitoring and optimizing performance regularly.
Q3. What are some common challenges in ETL development?
A. Common challenges in ETL development include dealing with diverse data sources and formats, ensuring data quality and integrity, gracefully handling errors and exceptions, managing scalability and resource constraints, and meeting performance and latency requirements.
Q4. What tools and technologies are commonly used for ETL?
A. Several ETL tools and technologies are available, including Apache Spark, Apache Airflow, Talend, Informatica, Microsoft Azure Data Factory, and AWS Glue. The choice of tool depends on factors such as scalability, ease of use, integration capabilities, and compatibility with existing infrastructure.
Q5. How can I ensure data quality in my ETL processes?
A. Ensuring data quality in ETL processes involves implementing data profiling to understand the structure and quality of data, performing data cleansing and validation to correct errors and inconsistencies, establishing data quality metrics and rules, and monitoring data quality continuously throughout the ETL pipeline.
My Name is Rahul Patidar. Currently working as senior Data engineer With Jio Financial Services (JFS).
I have 6 Years of Experience in Data engineering fields. I have expertise in spark, scala.kafka,hive etc.
My Previous 2 guide on Analytics Vidhya on sqoop and hive won the first price in guide section.





