Introduction
Many methods have been proven effective in improving model quality, efficiency, and resource consumption in Deep Learning. The distinction between fine-tuning vs full training vs training from scratch can help you decide which approach is right for your project. Then, we will review them individually and see where and when to use them, using code snippets to illustrate their advantages and disadvantages.
Learning Objectives:
- Understand the differences between fine-tuning vs full training vs training from scratch in Deep Learning.
- Identify the appropriate use cases for training a model from scratch.
- Recognize when to use full training on large, established datasets.
- Learn the advantages and disadvantages of each training approach.
- Gain practical knowledge through example code snippets for each training method.
- Evaluate the resource requirements and performance implications of each approach.
- Apply the right training strategy for specific Deep Learning projects.
Table of contents
What is Training from Scratch?
It means building and training a new model on the fly using your dataset. Starting with random initial weights and continuing the whole training process.
Use Cases
- Unique Data: When the dataset used is unique and vastly different from any present dataset.
- Novel Architectures: While designing new model architectures or trying out new methods.
- Research & Development: This is used in academic research or for advanced applications where models based on every possible database are insufficient.
Pros
- Flexible: You can fully control the model architecture and training process to adapt them to your data’s particularities.
- Custom Solutions: Regarding highly specialized tasks such as those with possibly no pre-trained models available.
Example Code
Here’s an example using PyTorch to train a simple neural network from scratch:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# Define a simple neural network
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = torch.flatten(x, 1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# Load the dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# Initialize the model, loss function, and optimizer
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training loop
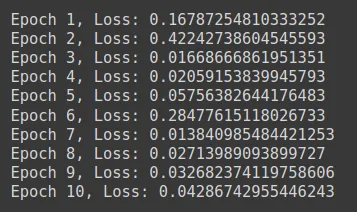
for epoch in range(10):
for images, labels in train_loader:
optimizer.zero_grad()
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
What is Full Training?
Full training typically refers to training a model from scratch but on a large and well-established dataset. This approach is common for developing foundational models like VGG, ResNet, or GPT.
Use Cases
- Foundational Models: Training large models intended to be used as pre-trained models for other tasks.
- Benchmarking: Comparing different architectures or techniques on standard datasets to establish benchmarks.
- Industry Applications: Creating robust and generalized models for widespread industrial use.
Advantages
- High Performance: These models can achieve state-of-the-art performance on specific tasks. They often serve as the backbone for many applications and are fine-tuned for specialized tasks.
- Standardization: It helps establish benchmark models. Models trained on large, diverse datasets can generalize well across various tasks and domains.
Disadvantages
- Resource-demanding: It requires extensive computational power and time. Training models like ResNet or GPT-3 involve multiple GPUs or TPUs over several days or weeks.
- Expertise Needed: Tuning hyperparameters and ensuring proper convergence requires deep knowledge. This includes understanding model architecture, data preprocessing, and optimization techniques.
Example Code
Here’s an example using TensorFlow to train a CNN on the CIFAR-10 dataset:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# Load the CIFAR-10 dataset
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize the images
train_images, test_images = train_images / 255.0, test_images / 255.0
# Define a CNN model
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# Compile the model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# Train the model
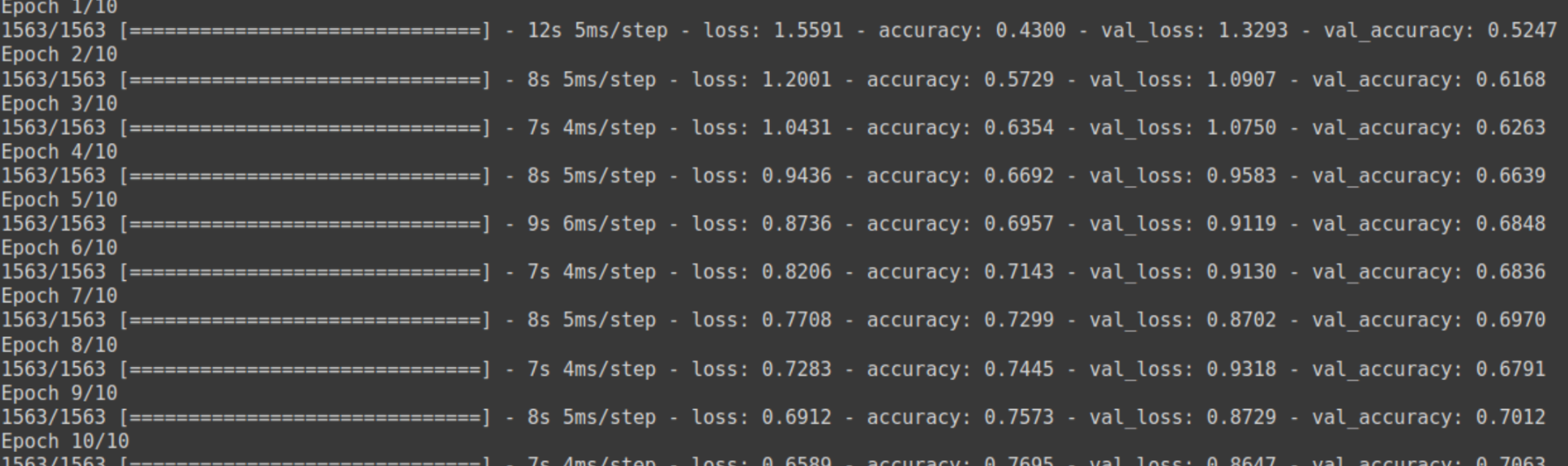
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
What is Fine-Tuning?
Utilizing a pre-trained model and making minor modifications to make it suitable for a particular task. You generally freeze the first few layers and train the rest on your dataset.
Use Cases
- Transfer Learning: Fine-tuning comes in if your dataset is small or you have limited hardware resources. It uses the knowledge of already pre-trained models.
- Domain Adaptation: Turning a general model to work into a specialized domain(e.g., medical imaging and sentiment analysis).
Benefits
- Efficiency: It consumes lower computational power and time. Training from scratch would require more resources, but fine-tuning can be done with fewer resources.
- Model Performance: The model performs well in many cases, even with little data. Pre-trained layers learn general features that are useful for most tasks.
Cons
- Less Flexibility: You do not fully control the initial layers of the model. You depend on the architecture and training of a pre-trained model.
- Overfitting Risk: Training a model to work with such a limited amount of data should be approached with caution to avoid overfitting the system. Overfitting may occur with fine-tuning if the new dataset is too small or too similar to the pre-trained data.
Example Code
Here’s an example using Keras to fine-tune a pre-trained VGG16 model on a custom dataset:
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Load the pre-trained VGG16 model and freeze its layers
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
for layer in base_model.layers:
layer.trainable = False
# Add custom layers on top of the base model
model = models.Sequential([
base_model,
layers.Flatten(),
layers.Dense(256, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Load and preprocess the dataset
train_datagen = ImageDataGenerator(rescale=0.5)
train_generator = train_datagen.flow_from_directory(
'path_to_train_data',
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
# Fine-tune the model
history = model.fit(train_generator, epochs=10, steps_per_epoch=100)
Fine-Tuning vs Full Training vs Training from Scratch
| Aspect | Training from Scratch | Full Training | Fine-Tuning |
| Definition | Building and training a new model from random initial weights. | Training a model from scratch on a large, established dataset. | Adapting a pre-trained model to a specific task by training some layers. |
| Use Cases | Unique data, novel architectures, research & development. | Foundational models, benchmarking, industry applications. | Transfer learning, domain adaptation, limited data or resources. |
| Advantages | Full control, custom solutions for specific needs. | High performance, establishes benchmarks, robust and generalized models. | Efficient, less resource-intensive, good performance with little data. |
| Disadvantages | Highly resource-demanding requires extensive computational power and expertise. | Less flexibility and risk of overfitting with small datasets. | High performance establishes benchmarks and robust and generalized models. |
Similarities Between Fine-Tuning vs Full Training vs Training from Scratch
- Machine Learning Models: All three methods involve machine learning models for various tasks.
- Training Process: Each method involves training a neural network, though the data and initial conditions may vary.
- Optimization: All methods require optimization algorithms to minimize the loss function.
- Performance Evaluation: All three methods require evaluating model performance using metrics like accuracy, loss, etc.
How to Decide Which One is Best for you?
1. Dataset Size and Quality:
- Training from Scratch: It is best to have a unique, large dataset is significantly different from existing datasets.
- Full Training: This is ideal if you can access large, well-established datasets and the resources to train a model from scratch.
- Fine-tuning: It is suitable for small datasets or for leveraging the knowledge from a pre-trained model.
2. Resources Available:
- Training from Scratch: Requires substantial computational resources and time.
- Full Training: Extremely resource-intensive, often requiring multiple GPUs/TPUs and considerable training time.
- Fine-tuning: Less resource-intensive, can be performed with limited hardware and in less time.
3. Project Goals:
- Training from Scratch: This is for projects needing customized solutions and novel model architectures.
- Full Training: This is for creating foundational models that can be used as benchmarks or for widespread applications.
- Fine-Tuning: For domain-specific tasks where a pre-trained model can be adapted to improve performance.
4. Expertise Level:
- Training from Scratch: Requires in-depth knowledge of machine learning, model architecture, and optimization techniques.
- Full Training: Requires expertise in hyperparameter tuning, model architecture, and extensive computational setup.
- Fine-tuning: More accessible for practitioners with intermediate knowledge, leveraging pre-trained models to achieve good performance with fewer resources.
Considering these factors, you can determine your deep learning project’s most appropriate training method.
Conclusion
Your specific case, data availability, computer resources, and target performance influence whether to fine-tune, fully train or train from scratch. Training from scratch is flexible but requires substantial resources and large datasets. Full training on established datasets is good for developing basic models and benchmarking. Fine-tuning efficiently uses pre-trained models and adjusts them for particular tasks with limited data.
Knowing these differences, you can choose the suitable approach for your machine learning project that maximizes performance and resource utilization. Whether you are constructing a new model, comparing architectures, or modifying existing ones, the right training strategy will be fundamental to achieving your ambitions in machine learning.
Frequently Asked Questions
Q1. What is the difference between fine-tuning, full training, and training from scratch in machine learning?
A. Fine-tuning involves using a pre-trained model and slightly adjusting it to a specific task. Full training refers to building a model from scratch using a large, well-established dataset. Training from scratch means building and training a new model entirely on your dataset, starting with randomly initialized weights.
Q2. When should I use training from scratch?
A. Training from scratch is ideal when you have a unique dataset significantly different from any existing dataset, are developing new model architectures or experimenting with novel techniques, or are conducting academic research or working on cutting-edge applications where existing models are insufficient.
Q3. What are the advantages of training a model from scratch?
A. The advantages are complete control over the model architecture and training process, allowing you to tailor them to your data’s specific characteristics. It is suitable for highly specialized tasks where pre-trained models are unavailable.
Q4. What is full training, and when should it be used?
A. Full training involves a model from scratch using a large and well-established dataset. It is typically used to develop foundational models like VGG, ResNet, or GPT, benchmark different architectures or techniques, and create robust and generalized industrial models.
Hi, I am Janvi, a passionate data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.







