Introduction
One of the toughest things about making powerful models in machine learning is fiddling with many levels. Hyperparameter optimization—adjusting those settings to end up with something that’s not horrible—might be the most important part of it all. In this blog post, complete with code snippets, we’ll cover what this means and how to do it.
Overview
- Realize the significance of hyperparameters in machine learning models.
- Learn various hyperparameter optimization methods, such as manual tuning, grid search, random search, Bayesian optimization, and gradient-based optimization.
- Implementing hyperparameter optimization techniques with popular libraries like scikit-learn and scikit-optimize
- Learn how to choose the right optimization strategy depending on model complexity, search space dimensionality, or available computational resources

Table of contents
- Getting Started With Optimization For Hyperparameters
- Importance Of Hyperparameter Optimization
- Example 1: Grid Search for Logistic Regression
- Example 2: Bayesian Optimization for a Random Forest Classifier
- Example 3: Random Search with Optuna for a Random Forest Classifier
- Frequently Asked Questions (FAQs)
Getting Started With Optimization For Hyperparameters
To get started, we need to understand hyperparameters. In a machine learning model, we decide on these settings before training begins. They control aspects like the network architecture and the number of layers. They also influence how the model learns the data. For example, when using gradient descent, hyperparameters include the learning rate. Regularization strength can also achieve similar goals but through entirely different means.
Importance Of Hyperparameter Optimization
It should come as no surprise then that where these hyperparameters end up being set has massive implications for your final result. You know the deal with underfitting and overfitting, right? Well, if not, just think back to when Winamp had skins; underfit models cannot take advantage of all available information, whilst overfit ones don’t know what they were trained on. So we’re trying to achieve some Goldilocks situation (i.e., just right) where our parameters generalize well across unseen examples without sacrificing too much performance on known data.
There are many ways to optimize hyperparameters, including manual tuning and automated methods. Below are some commonly used techniques:
- Manual Tuning: This method requires manually trying different combinations of hyperparameters and evaluating the model’s performance. Although straightforward, it may take too much time and prove ineffective, particularly for models with numerous hyperparameters.
- Grid Search: Grid search is an exhaustive evaluation of all possible combinations of hyperparameters within a specified range. Although comprehensive, it can be computationally expensive, especially for high-dimensional search spaces.
- Random Search: Unlike trying out every combination, random search selects hyperparameter values randomly from a specified distribution. It can be more efficient than a grid search, especially with large spaces.
- Bayesian Optimization: Bayesian optimization involves building a probabilistic model that drives the search towards optimal hyperparameters. It examines areas of interest while intelligently overlooking those that do not show potential within the search space.
- Gradient-Based Optimization: This treats hyperparameters as additional parameters that can be improved using methods based on gradients (e.g., stochastic gradient descent). Primarily, it is effective for differentiable hyperparameters such as learning rates
Having covered the theoretical aspects, let’s look at some code examples to show how hyperparameter optimization can be implemented practically. This blog post will use Python with the scikit-learn library, which offers various tools for tuning hyperparameters.
Example 1: Grid Search for Logistic Regression
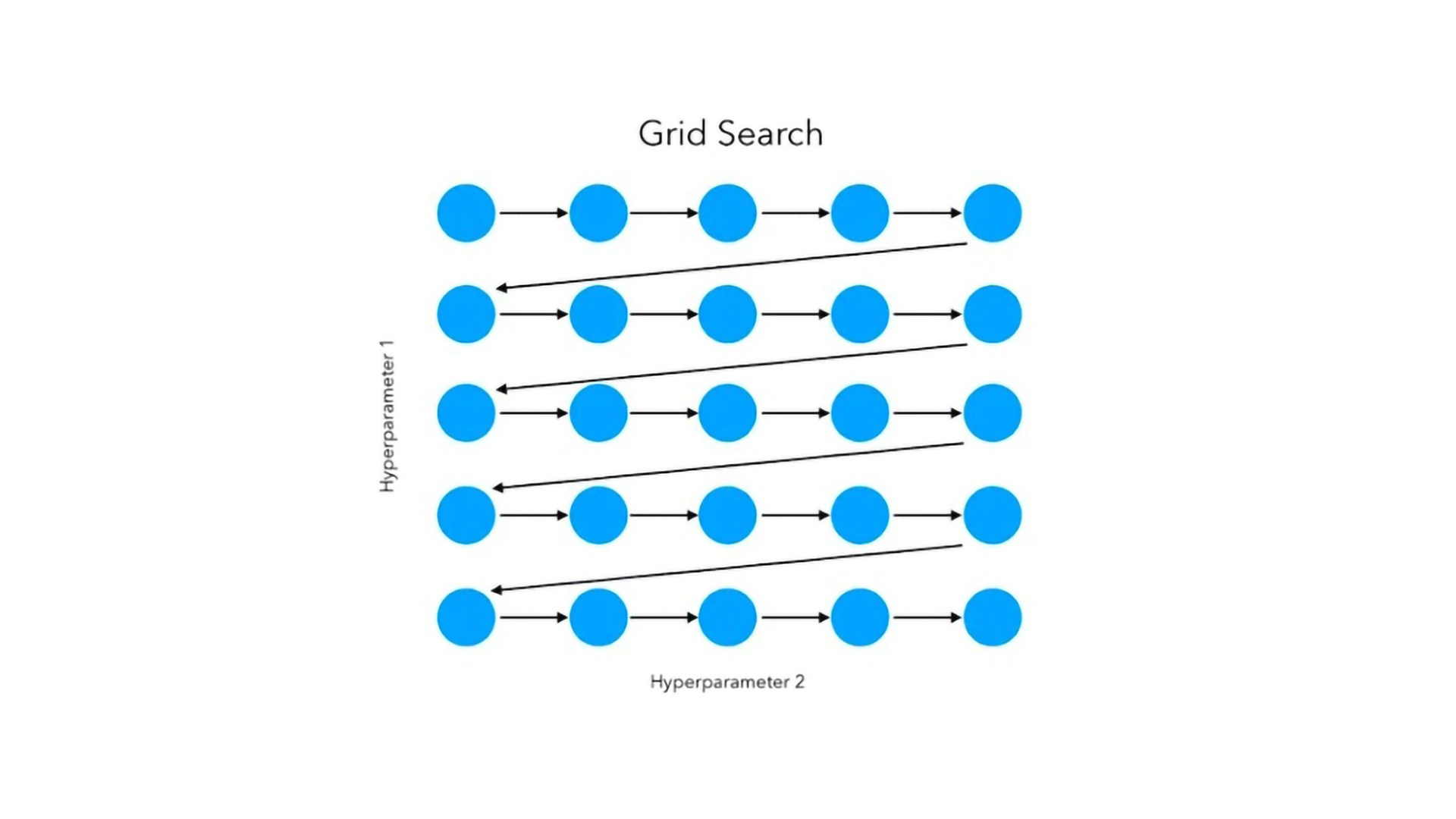
Suppose that a logistic regression model needs regularisation strength (C) optimization alongside penalty type (penalty), then it can be done by grid search, where all possible combinations of these two hyper-parameters are tried until the most appropriate one is found.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Define the hyperparameter grid
param_grid = {
'C': [0.001, 0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2']
}
# Create the logistic regression model
model = LogisticRegression()
# Perform grid search
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Get the best hyperparameters and the corresponding score
best_params = grid_search.best_params_
best_score = grid_search.best_score_
print(f"Best hyperparameters: {best_params}")
print(f"Best accuracy score: {best_score}")In this example, we define a grid of hyperparameter values for the regularization strength (C) and the penalty type (penalty). We then use the `GridSearchCV` class from scikit-learn to perform an exhaustive search over the specified grid, evaluating the model’s performance using 5-fold cross-validation and accuracy as the scoring metric. Finally, we print the best hyperparameters and the corresponding accuracy score.
Example 2: Bayesian Optimization for a Random Forest Classifier
Bayesian optimization is a powerful technique for hyperparameter tuning, especially when dealing with high-dimensional search spaces or when the objective function is expensive to evaluate. Let’s see how we can use it to optimize a random forest classifier:
from sklearn.ensemble import RandomForestClassifier
from skopt import BayesSearchCV
# Define the search space
search_spaces = {
'max_depth': (2, 20),
'max_features': (1, 'log2'),
'n_estimators': (10, 500),
'min_samples_split': (2, 20),
'min_samples_leaf': (1, 10)
}
# Create the random forest model
model = RandomForestClassifier(random_state=42)
# Perform Bayesian optimization
bayes_search = BayesSearchCV(
model,
search_spaces,
n_iter=100,
cv=3,
scoring='accuracy',
random_state=42
)
bayes_search.fit(X_train, y_train)
# Get the best hyperparameters and the corresponding score
best_params = bayes_search.best_params_
best_score = bayes_search.best_score_
print(f"Best hyperparameters: {best_params}")
print(f"Best accuracy score: {best_score}")
For instance, one may limit the depth, the number of features, and the number of estimators and specify other hyperparameters like minimum samples required for splitting or leaf nodes in a random forest classifier. Here, we employ the “BayesSearchCV” class from the sci-kit-optimize library to conduct Bayesian optimization by performing 100 iterations with 3-fold cross-validation using the accuracy score metric, then displaying the best hyperparameters along with their corresponding accuracies.
Example 3: Random Search with Optuna for a Random Forest Classifier
Let’s explore how to use Optuna to perform a random search for optimizing the hyperparameters of a random forest classifier:
import optuna
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
# Load the breast cancer dataset
data = load_breast_cancer()
X, y = data.data, data.target
# Define the objective function to optimize
def objective(trial):
max_depth = trial.suggest_int('max_depth', 2, 32)
n_estimators = trial.suggest_int('n_estimators', 100, 1000)
max_features = trial.suggest_categorical('max_features', ['auto', 'sqrt', 'log2'])
rf = RandomForestClassifier(max_depth=max_depth,
n_estimators=n_estimators,
max_features=max_features,
random_state=42)
score = cross_val_score(rf, X, y, cv=5, scoring='accuracy').mean()
return score
# Create an Optuna study and optimize the objective function
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
# Print the best hyperparameters and the corresponding score
print('Best hyperparameters: ', study.best_params)
print('Best accuracy score: ', study.best_value)The examples above are just a few approaches and tools that can be used while working on hyperparameter optimization tasks. The selection process should consider factors such as model complexity, search space dimensionality, or available computational resources.
Key Takeaways
1. Hyperparameters greatly influence how well a machine learning model performs; therefore, selecting appropriate values for them can lead to higher accuracy and better generalization.
2. There are different ways to search through hyperparameter spaces, from manually to more complex techniques such as grid search, random search, bayesian optimization, or gradient descent if you’re feeling really adventurous. But most people stick with something simple like brute force instead.
One should recall that hyperparameter optimization is an iterative process that might require constant monitoring and adjustment of hyperparameters to achieve the best performance.
Understanding and applying techniques for hyperparameter optimization can unlock the full potential of your machine learning models, which will result in higher accuracy and generalization across various applications, among other things.
Conclusion
Hyperparameter tuning is an important part of creating successful machine-learning models. When you explore this field systematically, finding an optimal setup for them will help unlock potentials hidden in your data, leading to better accuracy generalization capabilities, among others.
Whether you choose manual tuning, grid search, random search, Bayesian optimization, or gradient-based methods, understanding the principles and techniques of hyperparameter optimization will empower you to create robust and reliable machine-learning solutions.
Join the Certified AI & ML BlackBelt Plus Program for custom learning tailored to your goals, personalized 1:1 mentorship from industry experts, and dedicated job placement assistance. Enroll now and transform your future!
Frequently Asked Questions (FAQs)
Q1. What exactly do we mean by hyperparameters in machine learning?
A. Before training starts, values for these settings are decided on a model-wide basis; they control its behavior, architecture construction, and learning process execution, such as but not limited to learning rates, regularization strengths, numbers of hidden layers, and maximum depths for decision trees.
Q2. Why should one care about hyperparameter optimization at all?
A. Otherwise, poorly selected hyperparameters might result in underfitting (too simple models) or overfitting (memorizing training data without generalization). Therefore, the main idea behind this process is finding the best combination that maximizes performance on a given task out of all possible configurations.
Q3. What techniques can be used for hyperparameter optimization?
A. Common techniques involve manual tuning, grid search, random search, Bayesian optimization, and gradient-based optimization. Each has strengths and weaknesses, and the choice depends on factors like model complexity, search space dimensionality, and computational resources available.
Q4. How do you choose the right hyperparameter optimization technique?
A. The answer depends on various factors such as how simple or complex your models are going to be; what’s the size of the space through which we can explore those model parameters (i.e., number of dimensions); but also it heavily relies upon how much CPU time/ GPU time but then they are more likely talking about RAM memory.
With 4 years of experience in model development and deployment, I excel in optimizing machine learning operations. I specialize in containerization with Docker and Kubernetes, enhancing inference through techniques like quantization and pruning. I am proficient in scalable model deployment, leveraging monitoring tools such as Prometheus, Grafana, and the ELK stack for performance tracking and anomaly detection.
My skills include setting up robust data pipelines using Apache Airflow and ensuring data quality with stringent validation checks. I am experienced in establishing CI/CD pipelines with Jenkins and GitHub Actions, and I manage model versioning using MLflow and DVC.
Committed to data security and compliance, I ensure adherence to regulations like GDPR and CCPA. My expertise extends to performance tuning, optimizing hardware utilization for GPUs and TPUs. I actively engage with the LLMOps community, staying abreast of the latest advancements to continually improve large language model deployments. My goal is to drive operational efficiency and scalability in AI systems.


