Introduction
This article provides an in-depth exploration of vector databases, emphasizing their significance, functionality, and diverse applications, with a focus on Pinecone, a leading vector database platform. It explains the fundamental concepts of vector embeddings, the necessity of vector databases for enhancing large language models, and the robust technical features that make Pinecone efficient. Additionally, the article offers practical guidance on creating vector databases using Pinecone’s web interface and Python, discusses common challenges, and showcases various use cases such as semantic search and recommendation systems.
Learning Outcomes
- Understand the core principles and functionality of vector databases and their role in managing high-dimensional data.
- Gain insights into the features and applications of Pinecone in enhancing large language models and AI-driven systems.
- Acquire practical skills in creating and managing vector databases using Pinecone’s web interface and Python API.
- Learn to identify and address common challenges and optimize the use of vector databases in various real-world applications.
Table of contents
- What is Vector Database?
- Need for Vector Databases
- Features of Pinecone Vector Database
- Getting Started with Pinecone
- Ways to Create Vector Database with Pinecone
- Vector Database Using Pinecone’s UI
- Vector Database Using Code
- Use Cases of Pinecone Vector Database
- Challenges of Pinecone Vector Database
- Frequently Asked Questions
What is Vector Database?
Vector databases are specialized storage systems optimized for managing high-dimensional vector data. Unlike traditional relational databases that use row-column structures, vector databases employ advanced indexing algorithms to organize and query numerical vector representations of data points in n-dimensional space.
Core concepts include vector embeddings, which are dense numerical representations of data (text, images, etc.) in high-dimensional space, and similarity metrics, which are mathematical functions (e.g., cosine similarity, Euclidean distance) used to quantify the closeness of vectors. Approximate Nearest Neighbor (ANN) Search: Algorithms for efficiently finding similar vectors in high-dimensional spaces.
Need for Vector Databases
Large Language Models (LLMs) process and generate text based on vast amounts of training data. Vector databases enhance LLM capabilities by:
- Semantic Search: Transforming text into dense vector embeddings enables meaning-based queries rather than lexical matching.
- Retrieval Augmented Generation (RAG): Efficiently fetching relevant context from large datasets to improve LLM outputs.
- Scalable Information Retrieval: Handling billions of vectors with sub-linear time complexity for similarity searches.
- Low-latency Querying: Optimized index structures allow for millisecond-level query times, crucial for real-time AI applications.
Pinecone is a widely recognized vector database in the industry, known for addressing challenges such as complexity and dimensionality. As a cloud-native and managed vector database, Pinecone offers vector search (or “similarity search”) for developers through a straightforward API. It effectively handles high-dimensional vector data using a core methodology based on Approximate Nearest Neighbor (ANN) search, which efficiently identifies and ranks matches within large datasets.
Features of Pinecone Vector Database
Key technical features include:
Indexing Algorithms
- Hierarchical Navigable Small World (HNSW) graphs for efficient ANN search.
- Optimized for high recall and low latency in high-dimensional spaces.
Scalability
- Distributed architecture supporting billions of vectors.
- Automatic sharding and load balancing for horizontal scaling.
Real-time Operations
- Support for concurrent reads and writes.
- Immediate consistency for index updates.
Query Capabilities
- Metadata filtering for hybrid searches.
- Support for batched queries to optimize throughput.
Vector Optimizations
- Quantization techniques to reduce memory footprint.
- Efficient compression methods for vector storage.
Integration and APIs
RESTful API and gRPC support:
- Client libraries in multiple programming languages (Python, Java, etc.).
- Native support for popular ML frameworks and embedding models.
Monitoring and Management
- Prometheus-compatible metrics.
- Detailed logging and tracing capabilities.
Security Features
- End-to-end encryption
- Role-based access control (RBAC)
- SOC 2 Type 2 compliance
Pinecone’s architecture is specifically designed to handle the challenges of vector similarity search at scale, making it well-suited for LLM-powered applications requiring fast and accurate information retrieval from large datasets.
Getting Started with Pinecone
The two key concepts in the Pinecone context are index and collection, although for the sake of this discussion, we will concentrate on index. Next, we will be ingesting data—that is, PDF files—and developing a retriever to comprehend the same.
So the lets understand what purpose does Pinecone Index serves.
In Pinecone, an index represents the highest level organizational unit of vector data.
- Pinecone’s core data units, vectors, are accepted and stored using an index.
- It serves queries over the vectors it contains, allowing you to search for similar vectors.
- An index manipulates its contents using a variety of vector operations. In practical terms, you can think of an index as a specialized database for vector data. When you make an index, you provide essential characteristics.
- The vectors’ dimension (such as 2-dimensional, 768-dimensional, etc.) that needs to be stored 2.
- The query-specific similarity measure (e.g., cosine similarity, Euclidean etc.)
- Also we can chose the dimension as per model like if we choose mistral embed model then there will be 1024dimensions.
Pinecone offers two types of indexes
- Serverless indexes: These automatically scale based on usage, and you pay only for the amount of data stored and operations performed.
- Pod-based indexes: These use pre-configured units of hardware (pods) that you choose based on your storage and performance needs. Understanding indexes is crucial because they form the foundation of how you organize and interact with your vector data in Pinecone.
Collections
A collection is a static copy of an index in Pinecone. It serves as a non-query representation of a set of vectors and their associated metadata. Here are some key points about collections:
- Purpose: Collections are used to create static backups of your indexes.
- Creation: You can create a collection from an existing index.
- Usage: You can use a collection to create a new index, which can differ from the original source index.
- Flexibility: When creating a new index from a collection, you can change various parameters such as the number of pods, pod type, or similarity metric.
- Cost: Collections only incur storage costs, as they are not query-able.
Here are some common use cases for collections:
- Temporarily shutting down an index.
- Copying data from one index to a different index.
- Making a backup of your index.
- Experimenting with different index configurations.
Ways to Create Vector Database with Pinecone
Pinecone offers two methods for creating a vector database:
- Using the Web Interface
- Programmatically with Code
While this guide will primarily focus on creating and managing an index using Python, let’s first explore the process of creating an index through Pinecone’s user interface (UI).
Vector Database Using Pinecone’s UI
Follow these steps to begin:
- Visit the Pinecone website and log in to your account.
- If you’re new to Pinecone, sign up for a free account.
After completing the account setup, you’ll be presented with a dashboard. Initially, this dashboard will display no indexes or collections. At this point, you have two options to familiarize yourself with Pinecone’s functionality:
- Create your first index from scratch.
- Load sample data to explore Pinecone’s features.
Both options provide excellent starting points for understanding how Pinecone’s vector database works and how to interact with it. The sample data option can be particularly useful for those new to vector databases, as it provides a pre-configured example to examine and manipulate.
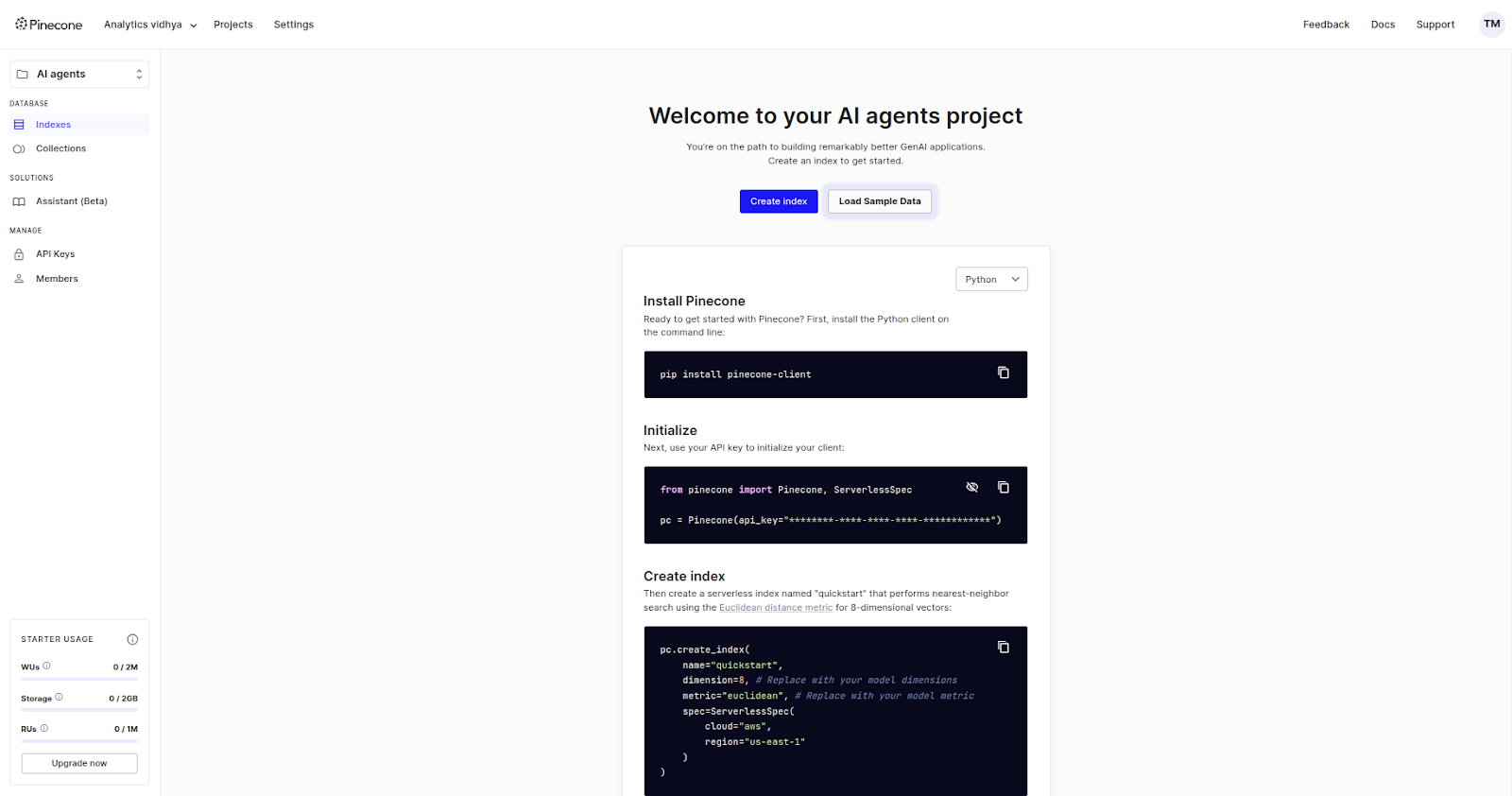
First, we’ll load the sample data and create vectors for it.
Click on “Load Sample Data” and then submit it.
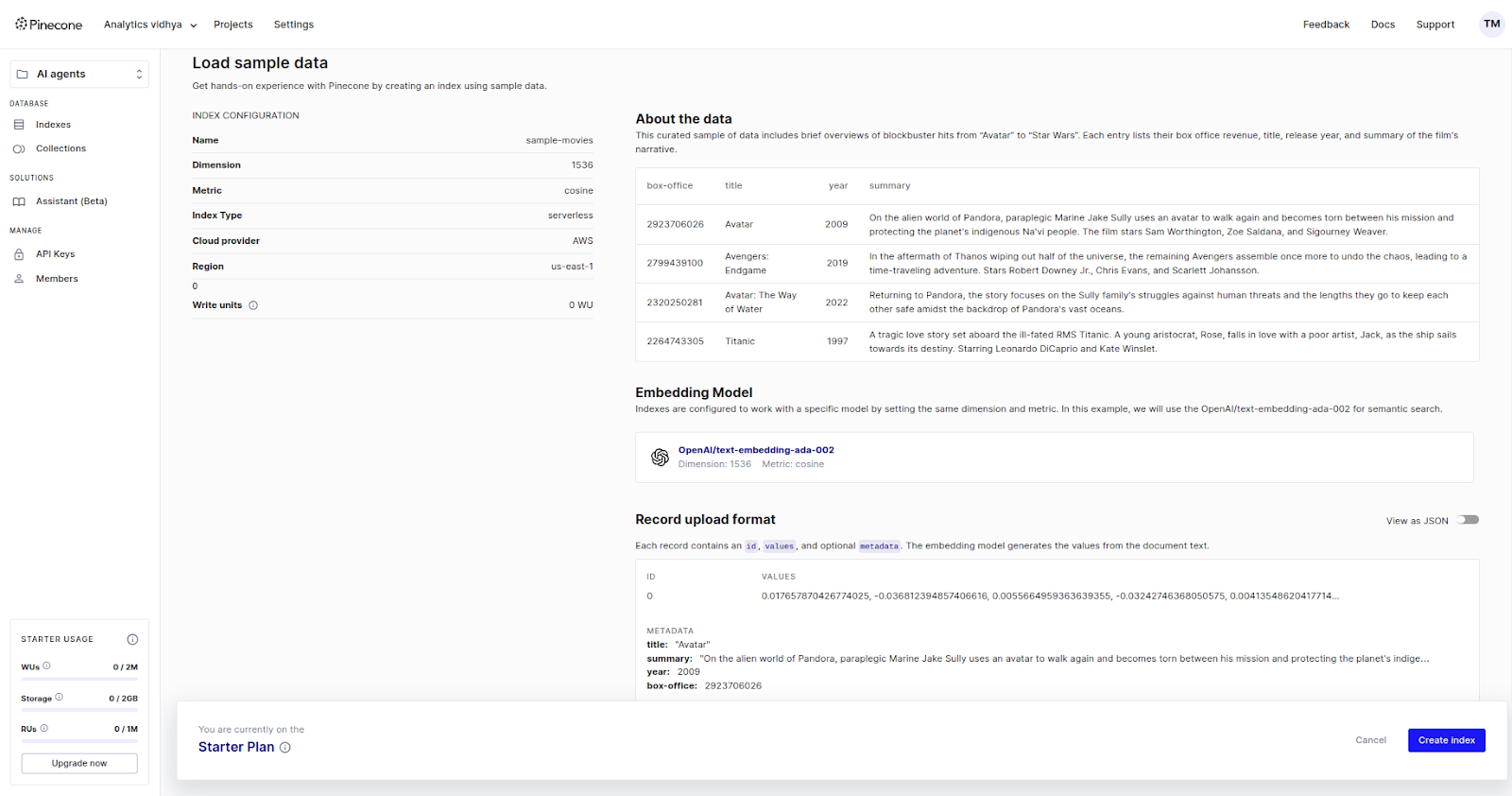
Here, you will find that this vector database is for blockbuster movies, including metadata and related information. You can see the box office numbers, movie titles, release years, and short descriptions. The embedding model used here is OpenAI’s text-embedding-ada model for semantic search. Optional metadata is also available along with IDs and values.
After Submission
In the indexes column, you will see a new index named `sample-movies`. When you select it, you can view how vectors are created and add metadata as well.
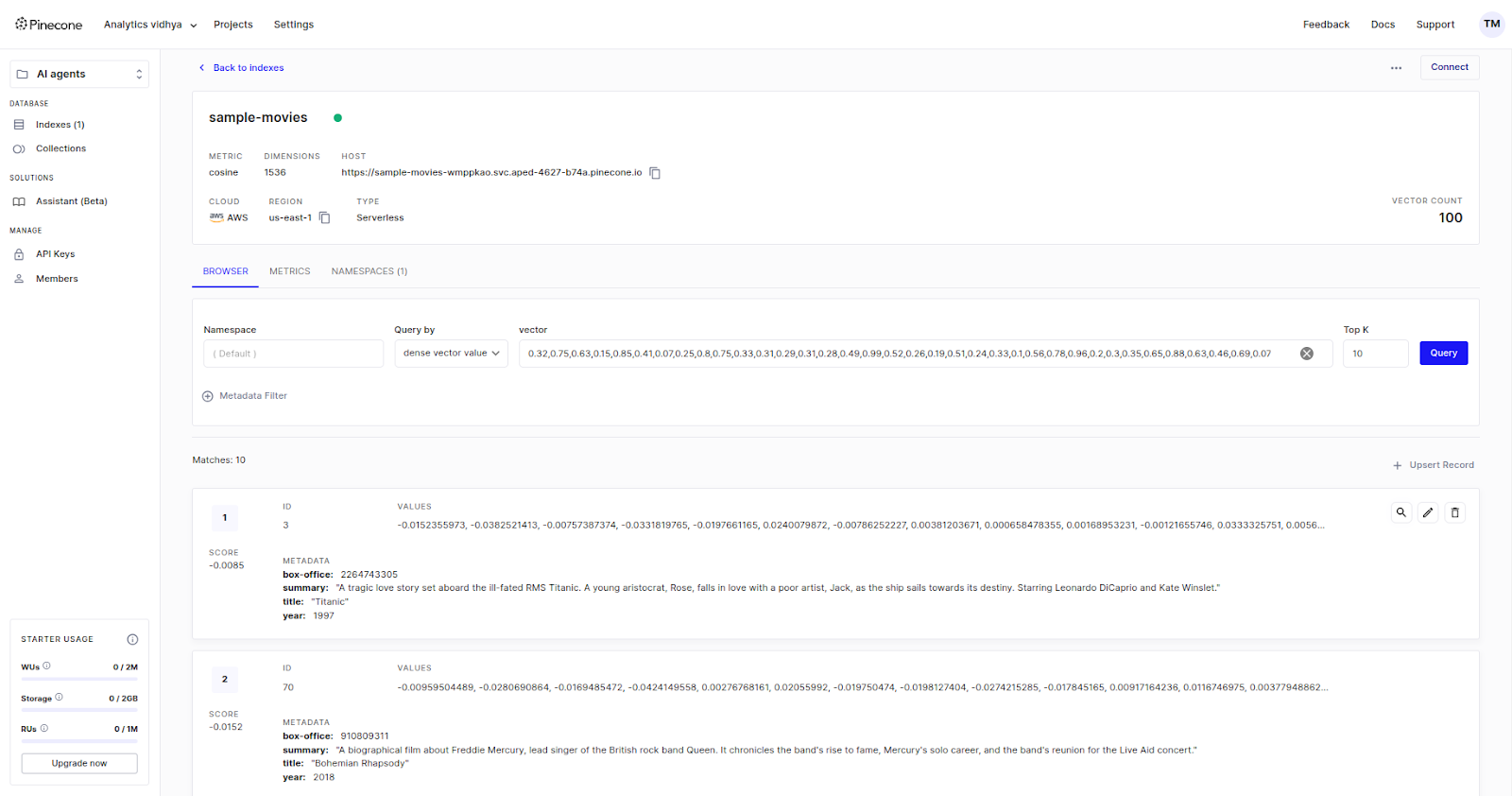
Now, let’s create our custom index using the UI provided by Pinecone.
Create Your First Index
To create your first index, click on “Index” in the left side panel and select “Create Index.” Name your index according to the naming convention, add configurations such as dimensions and metrics, and set the index to be serverless.
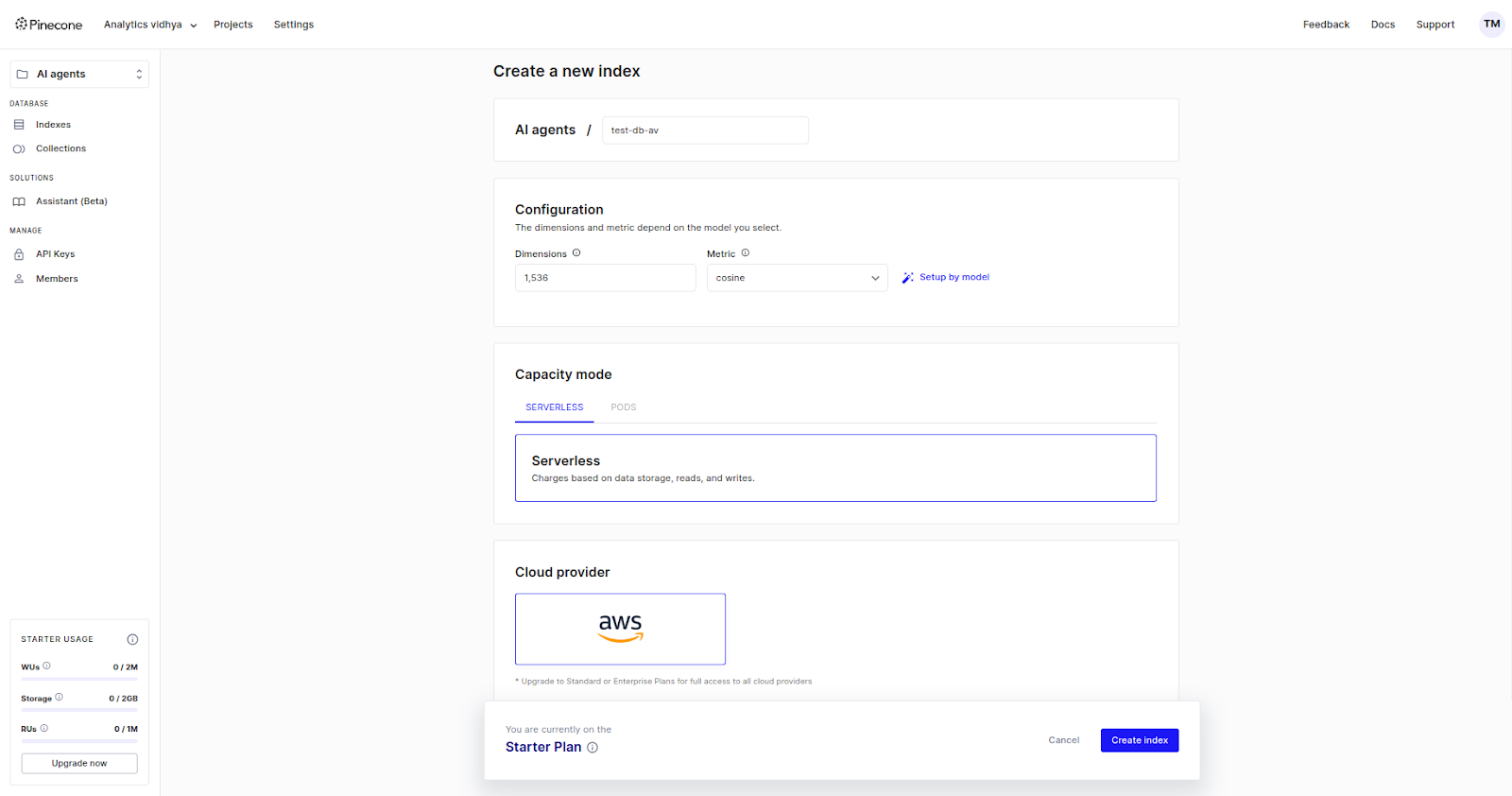
You can either enter values for dimensions and metrics manually or choose a model that has default dimensions and metrics.


Next, select the location and set it to Virginia (US East).
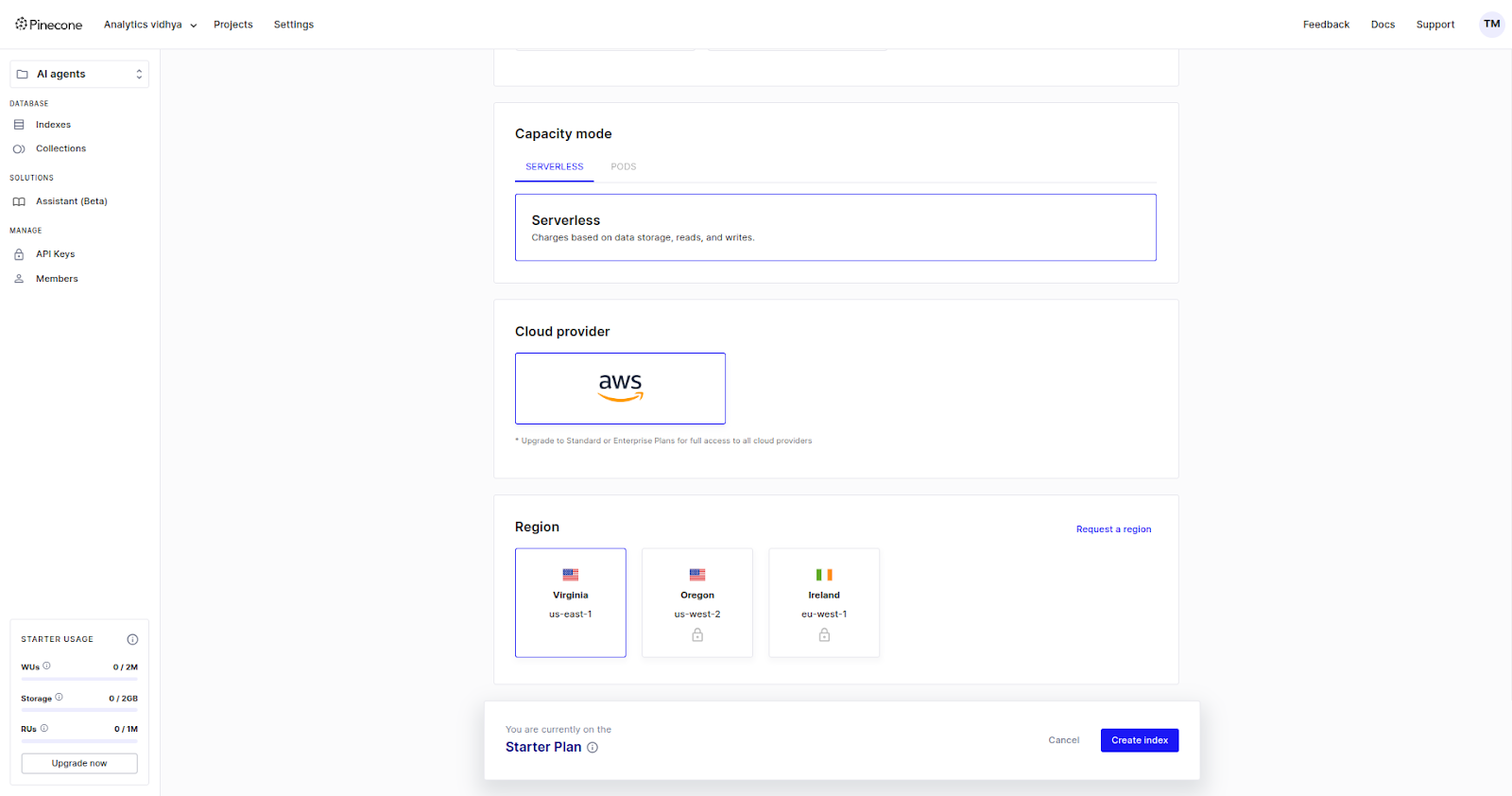
Next, let’s explore how to ingest data into the index we created or how to create a new index using code.
Also Read: How Do Vector Databases Shape the Future of Generative AI Solutions?
Vector Database Using Code
We’ll use Python to configure and create an index, ingest our PDF, and observe the updates in Pinecone. Following that, we’ll set up a retriever for document search. This guide will demonstrate how to build a data ingestion pipeline to add data to a vector database.
Vector databases like Pinecone are specifically engineered to address these challenges, offering optimized solutions for storing, indexing, and querying high-dimensional vector data at scale. Their specialized algorithms and architectures make them crucial for modern AI applications, particularly those involving large language models and complex similarity search tasks.
We are going to use Pinecone as the vector database. Here’s what we’ll cover:
- How to load documents.
- How to add metadata to each document.
- How to use a text splitter to divide documents.
- How to generate embeddings for each text chunk.
- How to insert data into a vector database.
Prerequisites
- Pinecone API Key: You will need a Pinecone API key. Sign-up for a free account to get started and obtain your API key after signing up.
- OpenAI API Key: You will need an OpenAI API key for this session. Log in to your platform.openai.com account, click on your profile picture in the upper right corner, and select ‘API Keys’ from the menu. Create and save your API key.
Let us now explore steps to create vector database using code.
Step1: Install Dependencies
First, install the required libraries:
!pip install pinecone langchain langchain_pinecone langchain-openai langchain-community pypdf python-dotenvStep2: Importing Necessary Libraries
import os
from dotenv import load_dotenv
import pinecone
from pinecone import ServerlessSpec
from pinecone import Pinecone, ServerlessSpec
from langchain.text_splitter import RecursiveCharacterTextSplitter # To split the text into smaller chunks
from langchain_openai import OpenAIEmbeddings # To create embeddings
from langchain_pinecone import PineconeVectorStore # To connect with the Vectorstore
from langchain_community.document_loaders import DirectoryLoader # To load files in a directory
from langchain_community.document_loaders import PyPDFLoader # To parse the PDFsStep3: Environment Setup
Let us now look into the detailing of environment setpup.
Load API keys:
# os.environ["LANGCHAIN_API_KEY"] = os.getenv("LANGCHAIN_API_KEY")
os.environ["OPENAI_API_KEY"] = "Your open-api-key"
os.environ["PINECONE_API_KEY"] = "Your pinecone api-key"Pinecone Configuration
index_name = "transformer-test" #give the name to your index, or you can use an index which you created previously and load that.
#here we are using the new fresh index name
pc = Pinecone(api_key="Your pinecone api-key")
#Get your Pinecone API key to connect after successful login and put it here.
pc
Step4: Index Creation or Loading
if index_name in pc.list_indexes().names():
print("index already exists" , index_name)
index= pc.Index(index_name) #your index which is already existing and is ready to use
print(index.describe_index_stats())
else: #crate a new index with specs
pc.create_index(
name=index_name,
dimension=1536, # Replace with your model dimensions
metric="cosine", # Replace with your model metric
spec=ServerlessSpec(
cloud="aws"
region="us-east-1"
)
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
index= pc.Index(index_name)
print("index created")
print(index.describe_index_stats())
And if you go to the pine cone UI-page you will see your new index has been created.

Step5: Data Preparation and Loading for Vector Database Ingestion
Before we can create vector embeddings and populate our Pinecone index, we need to load and prepare our source documents. This process involves setting up key parameters and using appropriate document loaders to read our data files.
Setting Key Parameters
DATA_DIR_PATH = "/content/drive/MyDrive/Data" # Directory containing our PDF files
CHUNK_SIZE = 1024 # Size of each text chunk for processing
CHUNK_OVERLAP = 0 # Amount of overlap between chunks
INDEX_NAME = index_name # Name of our Pinecone indexThese parameters define where our data is located, how we’ll split it into chunks, and which index we’ll be using in Pinecone.
Loading PDF Documents
To load our PDF files, we’ll use LangChain’s DirectoryLoader in conjunction with the PyPDFLoader. This combination allows us to efficiently process multiple PDF files from a specified directory.
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
loader = DirectoryLoader(
path=DATA_DIR_PATH, # Directory containing our PDFs
glob="**/*.pdf", # Pattern to match PDF files (including subdirectories)
loader_cls=PyPDFLoader # Specifies we're loading PDF files
)
docs = loader.load() # This loads all matching PDF files
print(f"Total Documents loaded: {len(docs)}")Output:
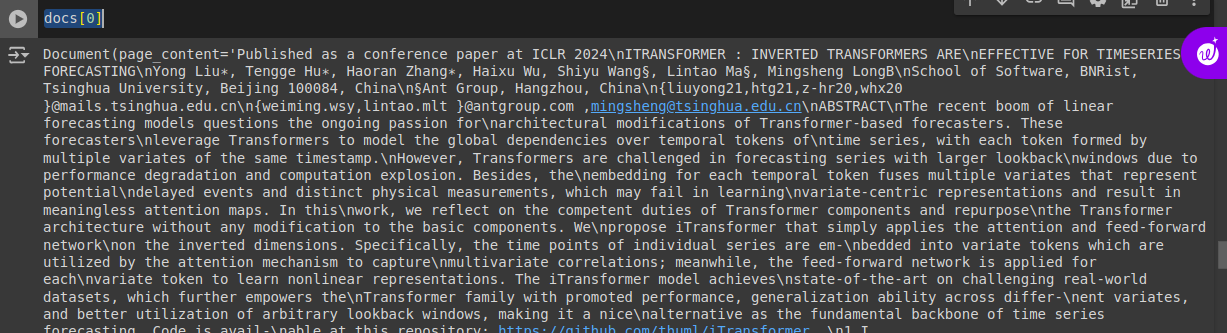
type(docs[24])
# we can convert the Document object to a python dict using the .dict() method.
print(f"keys associated with a Document: {docs[0].dict().keys()}")
print(f"{'-'*15}\nFirst 100 charachters of the page content: {docs[0].page_content[:100]}\n{'-'*15}")
print(f"Metadata associated with the document: {docs[0].metadata}\n{'-'*15}")
print(f"Datatype of the document: {docs[0].type}\n{'-'*15}")
# We loop through each document and add additional metadata - filename, quarter, and year
for doc in docs:
filename = doc.dict()['metadata']['source'].split("\\")[-1]
#quarter = doc.dict()['metadata']['source'].split("\\")[-2]
#year = doc.dict()['metadata']['source'].split("\\")[-3]
doc.metadata = {"filename": filename, "source": doc.dict()['metadata']['source'], "page": doc.dict()['metadata']['page']}
# To veryfy that the metadata is indeed added to the document
print(f"Metadata associated with the document: {docs[0].metadata}\n{'-'*15}")
print(f"Metadata associated with the document: {docs[1].metadata}\n{'-'*15}")
print(f"Metadata associated with the document: {docs[2].metadata}\n{'-'*15}")
print(f"Metadata associated with the document: {docs[3].metadata}\n{'-'*15}")
for i in range(len(docs)) :
print(f"Metadata associated with the document: {docs[i].metadata}\n{'-'*15}")Step6: Optimizing Data for Vector Databases
Text chunking is a crucial preprocessing step in preparing data for vector databases. It involves breaking down large bodies of text into smaller, more manageable segments. This process is essential for several reasons:
- Improved Storage Efficiency: Smaller chunks allow for more granular storage and retrieval.
- Enhanced Search Precision: Chunking enables more accurate similarity searches by focusing on relevant segments.
- Optimized Processing: Smaller text units are easier to process and embed, reducing computational load.
Common Chunking Strategies
- Character Chunking: Divides text based on a fixed number of characters.
- Recursive Character Chunking: A more sophisticated approach that considers sentence and paragraph boundaries.
- Document-Specific Chunking: Tailors the chunking process to the structure of specific document types.
For this guide, we’ll focus on Recursive Character Chunking, a method that balances efficiency with content coherence. LangChain provides a robust implementation of this strategy, which we’ll utilize in our example.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1024,
chunk_overlap=0
)
documents = text_splitter.split_documents(docs)In this code snippet, we’re creating chunks of 1024 characters with no overlap between chunks. You can adjust these parameters based on your specific needs and the nature of your data.
For a deeper dive into various chunking strategies and their implementations, refer to the LangChain documentation on text splitting techniques. Experimenting with different approaches can help you find the optimal chunking method for your particular use case and data structure.
By mastering text chunking, you can significantly enhance the performance and accuracy of your vector database, leading to more effective LLM applications.
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP
)
documents = text_splitter.split_documents(docs)
len(docs), len(documents)
#output ;
(25, 118)Step7: Embedding and Vector Store Creation
embeddings = OpenAIEmbeddings(model = "text-embedding-ada-002") # Initialize the embedding model
embeddings
docs_already_in_pinecone = input("Are the vectors already added in DB: (Type Y/N)")
# check if the documents were already added to the vector database
if docs_already_in_pinecone == "Y" or docs_already_in_pinecone == "y":
docsearch = PineconeVectorStore(index_name=INDEX_NAME, embedding=embeddings)
print("Existing Vectorstore is loaded")
# if not then add the documents to the vectore db
elif docs_already_in_pinecone == "N" or docs_already_in_pinecone == "n":
docsearch = PineconeVectorStore.from_documents(documents, embeddings, index_name=index_name)
print("New vectorstore is created and loaded")
else:
print("Please type Y - for yes and N - for no")
Using the Vector Store for Retrieval
# Here we are defing how to use the loaded vectorstore as retriver
retriver = docsearch.as_retriever()
retriver.invoke("what is itransformer?")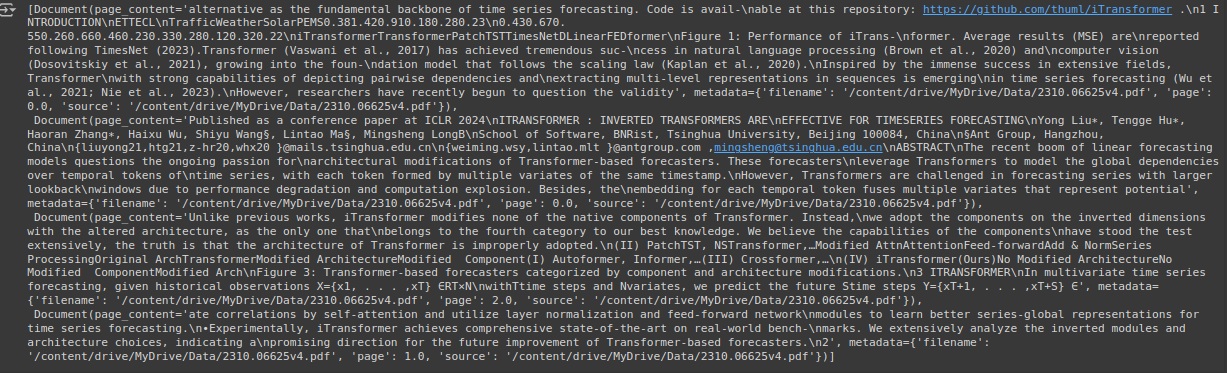
Using metadata as retreiver
retriever = docsearch.as_retriever(search_kwargs={"filter": {"source": "/content/drive/MyDrive/Data/2310.06625v4.pdf", "page": 0}})
retriver.invoke(" Flash Transformer ?")
Use Cases of Pinecone Vector Database
- Semantic search: Enhancing search capabilities in applications, e-commerce platforms, or knowledge bases.
- Recommendation systems: Powering personalized product, content, or service recommendations.
- Image and video search: Enabling visual search capabilities in multimedia applications.
- Anomaly detection: Identifying unusual patterns in various domains like cybersecurity or finance.
- Chatbots and conversational AI: Improving response relevance in AI-powered chat systems.
- Plagiarism detection: Comparing document similarities in academic or publishing contexts.
- Facial recognition: Storing and querying facial feature vectors for identification purposes.
- Music recommendation: Finding similar songs based on audio features.
- Fraud detection: Identifying potentially fraudulent transactions or activities.
- Customer segmentation: Grouping similar customer profiles for targeted marketing.
- Drug discovery: Finding similar molecular structures in pharmaceutical research.
- Natural language processing: Powering various NLP tasks like text classification or named entity recognition.
- Geospatial analysis: Finding patterns or similarities in geographic data.
- IoT and sensor data analysis: Identifying patterns or anomalies in sensor data streams.
- Content deduplication: Finding and managing duplicate or near-duplicate content in large datasets.
Pinecone Vector Database offers powerful capabilities for working with high-dimensional vector data, making it suitable for a wide range of AI and machine learning applications. While it presents some challenges, particularly in terms of data preparation and optimization, its features make it a valuable tool for many modern data-driven use cases.
Challenges of Pinecone Vector Database
- Learning curve: Users may need time to understand vector embeddings and how to effectively use them.
- Cost management: As data scales, costs can increase, requiring careful resource planning. Can be expensive for large-scale usage compared to self-hosted solutions Pricing model may not be ideal for all use cases or budget constraints
- Data preparation: Generating high-quality vector embeddings can be challenging and resource-intensive.
- Performance tuning: Optimizing index parameters for specific use cases may require experimentation.
- Integration complexity: Incorporating vector search into existing systems may require significant changes.
- Data privacy concerns: Storing sensitive data as vectors may raise privacy and security questions.
- Versioning and consistency: Maintaining consistency between vector data and source data can be challenging.
- Limited control over infrastructure: Being a managed service, users have less control over the underlying infrastructure.
Key Takeaways
- Vector databases like Pinecone are crucial for enhancing LLM capabilities, especially in semantic search and retrieval augmented generation.
- Pinecone offers both serverless and pod-based indexes, catering to different scalability and performance needs.
- The process of creating a vector database involves several steps: data loading, preprocessing, chunking, embedding, and vector storage.
- Proper metadata management is essential for effective filtering and retrieval of documents.
- Text chunking strategies, such as Recursive Character Chunking, play a vital role in preparing data for vector databases.
- Regular maintenance and updating of the vector database are necessary to ensure its relevance and accuracy over time.
- Understanding the trade-offs between index types, embedding dimensions, and similarity metrics is crucial for optimizing performance and cost in production environments.
Also Read: Top 15 Vector Databases in 2024
Conclusion
This guide has demonstrated two primary methods for creating and utilizing a vector database with Pinecone:
- Using the Pinecone Web Interface: This method provides a user-friendly approach to create indexes, load sample data, and explore Pinecone’s features. It’s particularly useful for those new to vector databases or for quick experimentation.
- Programmatic Approach using Python: This method offers more flexibility and control, allowing for integration with existing data pipelines and customization of the vector database creation process. It’s ideal for production environments and complex use cases.
Both methods enable the creation of powerful vector databases capable of enhancing LLM applications through efficient similarity search and retrieval. The choice between them depends on the specific needs of the project, the level of customization required, and the expertise of the team.
Frequently Asked Questions
Q1. What is a vector database?
A. A vector database is a specialized storage system optimized for managing high-dimensional vector data.
Q2. How does Pinecone handle vector data?
A. Pinecone uses advanced indexing algorithms, like Hierarchical Navigable Small World (HNSW) graphs, to efficiently manage and query vector data.
Q3. What are the main features of Pinecone?
A. Pinecone offers real-time operations, scalability, optimized indexing algorithms, metadata filtering, and integration with popular ML frameworks.
Q4. How can I use Pinecone for semantic search?
A. You can transform text into vector embeddings and perform meaning-based queries using Pinecone’s indexing and retrieval capabilities.
I'm Sahitya Arya, a seasoned Deep Learning Engineer with one year of hands-on experience in both Deep Learning and Machine Learning. Throughout my career, I've authored more than three research papers and have gained a profound understanding of Deep Learning techniques. Additionally, I possess expertise in Large Language Models (LLMs), contributing to my comprehensive skill set in cutting-edge technologies for artificial intelligence.


