Introduction
Polars is a high-performance DataFrame library designed for speed and efficiency. It leverages all available cores on your machine, optimizes queries to minimize unnecessary operations, and manages datasets larger than your RAM. With a consistent API and strict schema adherence, Python Polars ensures predictability and reliability. Written in Rust, it offers C/C++ level performance, fully controlling critical parts of the query engine for optimal results.
Overview:
- Learn about Polars, a high-performance DataFrame library in Rust.
- Discover Apache Arrow, which Polars leverages for fast data access and manipulation.
- Polars supports deferred, optimized operations and immediate results, offering flexible query execution.
- Uncover the streaming capabilities of Polars, especially its ability to handle large datasets in chunks.
- Understand Polars strict schemas to ensure data integrity and predictability, minimizing runtime errors.

Key Concepts of Polars
- Apache Arrow Format: Polars uses Apache Arrow, an efficient columnar memory format, to enable fast data access and manipulation. This ensures high performance and seamless interoperability with other Arrow-based systems.
- Lazy vs Eager Execution: It supports lazy execution, deferring operations for optimization, and eager execution, performing operations immediately. Lazy execution optimizes computations, while eager execution provides instant results.
- Streaming: Polars can handle streaming data and processing large datasets in chunks. This reduces memory usage and is ideal for real-time data analysis.
- Contexts: Polars contexts define the scope of data operations, providing structure and consistency in data processing workflows. The primary contexts are selection, filtering, and aggregation.
- Expressions: Expressions in Polars represent data operations like arithmetic, aggregations, and filtering. They allow for the efficient building of complex data processing and its pipelines.
- Strict Schema Adherence: It enforces a strict schema, requiring known data types before executing queries. This ensures data integrity and reduces runtime errors.
Also Read: Is Pypolars the New Alternative to Pandas?
Python Polars Expressions
Install Polars with ‘pip install polars.’
We can read the data and describe it like in Pandas
import polars as pl
df = pl.read_csv('iris.csv')
df.head() # this will display shape, datatypes of the columns and first 5 rows
df.describe() # this will display basic descriptive statistics of columnsNext up we can select different columns with basic operations.
df.select(pl.sum('sepal_length').alias('sum_sepal_length'),
pl.mean('sepal_width').alias('mean_sepal_width'),
pl.max('species').alias('max_species'))
# retuens a data frame with given column names and operations performed on them.We can also select using polars.selectors
import polars.selectors as cs
df.select(cs.float()) # returns all columns with float data types
# we can also search with sub-strings or regex
df.select(cs.contains('width')) # returns the columns that have 'width' in the name.Now we can use conditionals.
df.select(pl.col('sepal_width'),
pl.when(pl.col("sepal_width") > 2)
.then(pl.lit(True))
.otherwise(pl.lit(False))
.alias("conditional"))
# This returns an additional column with boolean values with true when sepal_width > 2Patterns in the strings can be checked, extracted, or replaced.
df_1 = pl.DataFrame({"id": [1, 2], "text": ["123abc", "abc456"]})
df_1.with_columns(
pl.col("text").str.replace(r"abc\b", "ABC"),
pl.col("text").str.replace_all("a", "-", literal=True).alias("text_replace_all"),
)
# replace one match of abc at the end of a word (\b) with ABC and all occurrences of a with -Filtering columns
df.filter(pl.col('species') == 'setosa',
pl.col('sepal_width') > 2)
# returns data with only setosa species and where sepal_width > 2Groupby in this high-performance dataframe library in Rust.
df.group_by('species').agg(pl.len(),
pl.mean('petal_width'),
pl.sum('petal_length'))
The above returns the number of values by species and the mean of petal_width, the sum of petal_length by species.
Joins
In addition to typical inner, outer, and left joins, polars have ‘semi’ and ‘anti.’ Let’s look at the ‘semi’ join.
df_cars = pl.DataFrame(
{
"id": ["a", "b", "c"],
"make": ["ford", "toyota", "bmw"],
}
)
df_repairs = pl.DataFrame(
{
"id": ["c", "c"],
"cost": [100, 200],
}
)
# now an inner join produces with multiple rows for each car that has had multiple repair jobs
df_cars.join(df_repairs, on="id", how="semi")
# this produces a single row for each car that has had a repair job carried outThe ‘anti’ join produces a DataFrame showing all the cars from df_cars for which the ID is not present in the df_repairs DataFrame.
We can concat dataframes with simple syntax.
df_horizontal_concat = pl.concat(
[
df_h1,
df_h2,
],
how="horizontal",
) # this returns wider dataframe
df_horizontal_concat = pl.concat(
[
df_h1,
df_h2,
],
how="vertical",
) # this returns longer dataframeLazy API
The above examples show that the eager API executes the query immediately. The lazy API, on the other hand, evaluates the query after applying various optimizations, making the lazy API the preferred option.
Let’s look at an example.
q = (
pl.scan_csv("iris.csv")
.filter(pl.col("sepal_length") > 5)
.group_by("species")
.agg(pl.col("sepal_width").mean())
)
# how query graph without optimization - install graphviz
q.show_graph(optimized=False)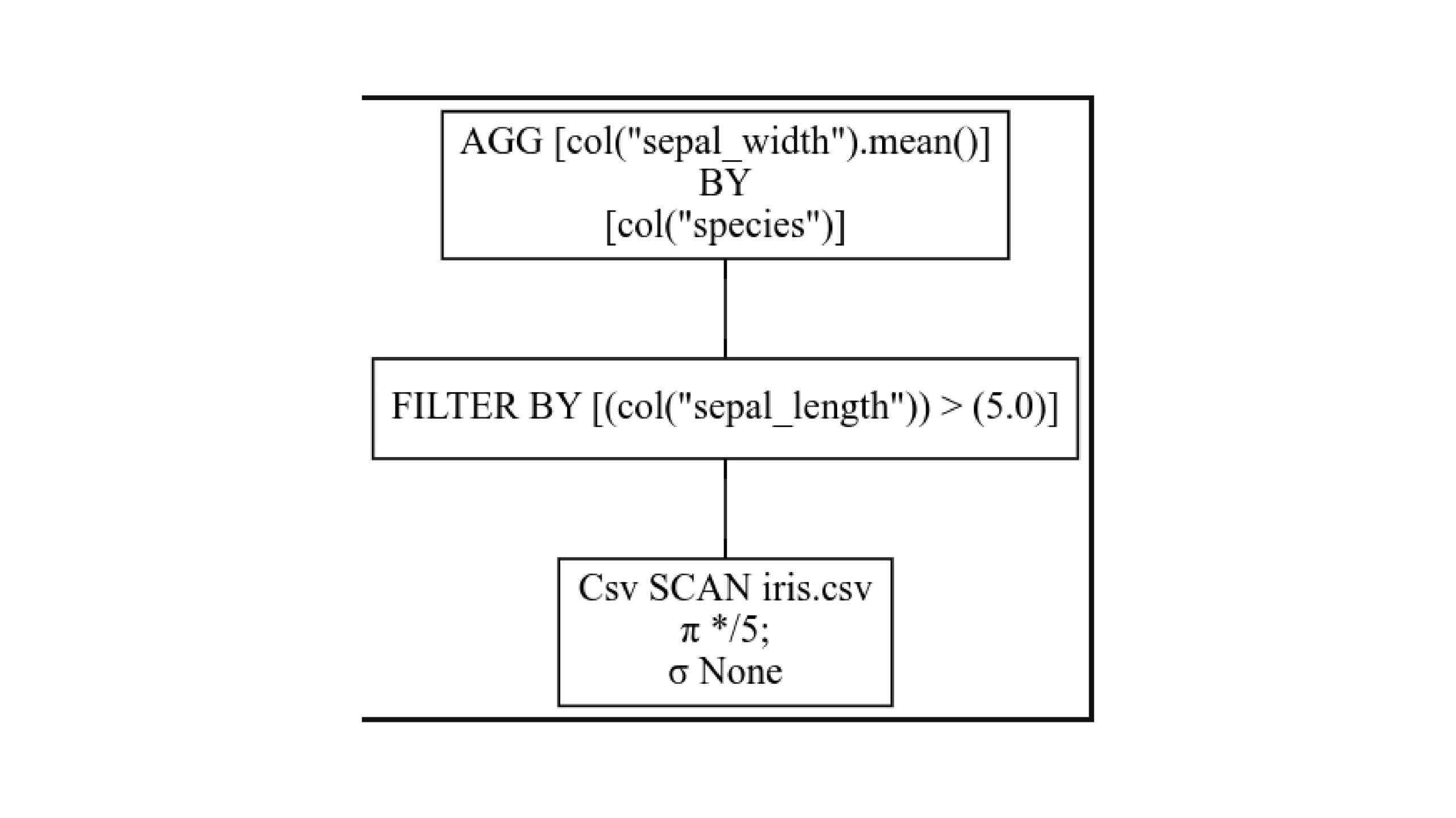
Read from bottom to top. Each box is one stage in the query plan. Sigma stands for SELECTION and indicates selection based on filter conditions. Pi stands for PROJECTION and indicates choosing a subset of columns.
Here, we choose all five columns, and no selections are made while reading the CSV file. Then, we filter by the column and aggregate one after another.
Now, look at the optimized query plan with q.show_graph(optimized=True)
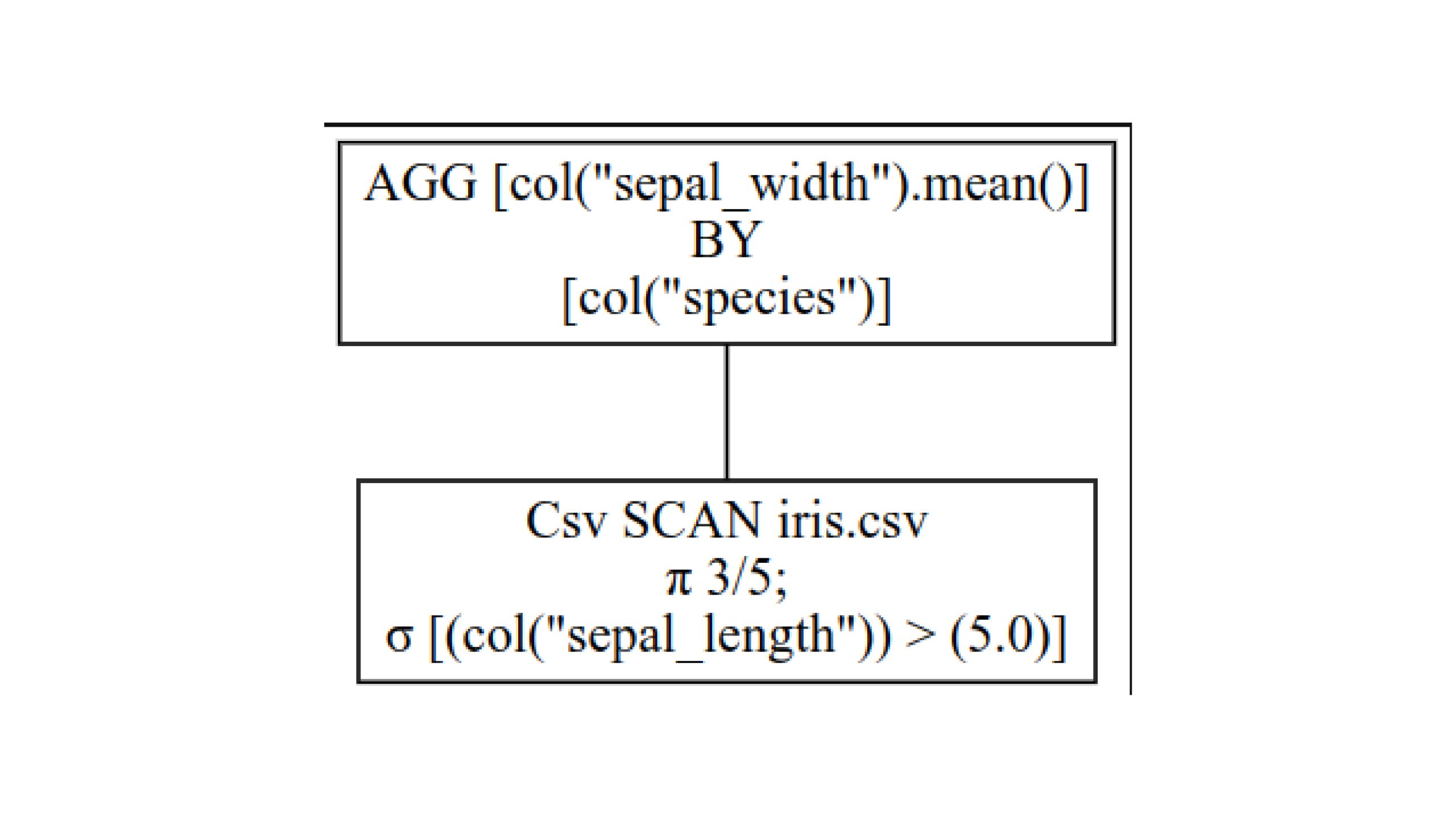
Here, we choose only 3 out of 5 columns, as subsequent queries are done on only them. Even in them, we select data based on the filter condition. We are not loading any other data. Now, we can aggregate the selected data. Thus, this method is much faster and requires less memory.
We can collect the results now. We can process the data in batches if the whole dataset doesn’t fit in the memory.
q.collect()
# to process in batches
q.collect(streaming=True)Polars is growing in popularity, and many libraries like scikit-learn, seaborn, plotly, and others support Polars.
Conclusion
Polars offers a robust, high-performance DataFrame library for speed, efficiency, and scalability. With features like Apache Arrow integration, lazy and eager execution, streaming data processing, and strict schema adherence, Polars stands out as a versatile tool for data professionals. Its consistent API and use of Rust ensure optimal performance, making it an essential tool in modern data analysis workflows.
Frequently Asked Questions
Q1. What is Python Polars, and how does it differ from other DataFrame libraries like Pandas?
A. Polars is a high-performance DataFrame library designed for speed and efficiency. Unlike Pandas, Polars leverages all available cores on your machine, optimizes queries to minimize unnecessary operations, and can manage datasets larger than your RAM. Additionally, this high-performance dataframe is written in Rust, offering C/C++ level performance.
Q2. What are the key benefits of using Apache Arrow with Polars?
A. Polars uses Apache Arrow, an efficient columnar memory format, which enables fast data access and manipulation. This integration ensures high performance and seamless interoperability with other Arrow-based systems, making it ideal for handling large datasets efficiently.
Q3. What is the difference between lazy and eager execution in Polars?
A. Lazy execution in Polars defers operations for optimization, allowing the system to optimize the entire query plan before executing it, which can lead to significant performance improvements. Eager execution, on the other hand, performs operations immediately, providing instant results but without the same level of optimization.
Q4. How do Polars handle streaming data?
A. Polars can process large datasets in chunks through their streaming capabilities. This approach reduces memory usage and is ideal for real-time data analysis, enabling the high-performance dataframe to efficiently handle data that exceeds the available RAM.
Q5. What is strict schema adherence in Polars, and why is it important?
A. Polars requires strict schema adherence, which requires knowing data types before executing queries. This ensures data integrity, reduces runtime errors, and allows for more predictable and reliable data processing, making it a robust choice for data analysis.
I am working as an Associate Data Scientist at Analytics Vidhya, a platform dedicated to building the Data Science ecosystem. My interests lie in the fields of Natural Language Processing (NLP), Deep Learning, and AI Agents.





