Introduction
In this article, we are going to explore a new tool, EmbedAnything, and see how it works and what you can use it for. EmbedAnything is a high-performance library that allows you to create image and text embeddings directly from files using local embedding models as well as cloud-based embedding models. We will also see an example of this in action with a scenario where we want to group fashion images together based on the apparel that they show.

Table of Contents
What Are Embeddings?
If you are working in the AI space or worked with large language models (LLMs), you would have definitely come across the term embeddings. In simple words, embeddings are a compressed representation of a sentence or a word. It is basically a vector of floating point numbers. It could be of any size ranging from 100 to as big as 5000.
How Are Embeddings Made?
Embedding models have evolved a lot over the years. The earliest models were based on one hot encoding or word occurrences. However, with new technological developments and more data availability, embedding models have become more powerful.
Pre-Transformer Era
The simplest way to represent a word as an embedding is using a one-hot encoding with the total vocabulary size of the text corpus. However, this is extremely inefficient as the representation is very sparse, and the size of the embedding is as big as the vocabulary size, which can be up to millions.
The next approach is using an NGram model, which uses a simple, fully connected neural network. There are two methods Skip-gram and Continuous Bag of Words (CBOW). These methods are very efficient and fall under the Word2Vec umbrella. CBOW predicts the target word from its context, while Skip-gram tries to predict the context words from the target word.
Another approach is GloVe (Global Vectors for Word Representation). GloVe focuses on leveraging the statistical information of word co-occurrence across a large corpus.
Post Transformer Era
Bidirectional Encoder Transformer
One of the earliest ways to build contextual embeddings using transformers was BERT. What is BERT, if you wonder? It’s a self-supervised way of predicting masked words. It means if we [MASK] one word in a sentence, it just tries to predict what that word could be, and thus, the information moves both from the left to right and right to left of the masked word.
Sentence Embeddings
What we have seen so far are ways to create word embeddings. But in many cases, we want to capture a representation of a sentence instead of just the words in the sentence. There are several ways to create sentence embeddings from word embeddings. One of the most prevalent methods is using pre-trained models like SBERT (Sentence BERT). These are trained by creating a dataset of similar pairs of sentences and performing contrastive learning with similarity scores.
There are several methods for using sentence embedding models. The easiest is to use cloud-based embedding models like OpenAI, Jina, or Cohere. There are several local models as well on Hugging Face that can be used like AllMiniLM6.
Multimodal Embeddings
Multimodal embeddings are vector representations that encode information from multiple types of data into a common vector space. This allows models to understand and correlate information across different modalities. One of the most used multimodal embedding models is CLIP, which embeds text and images in a shared embedding space.
Where Are These Embeddings Used?
Embeddings have a lot of applications across various industries. Here are some of the most common use cases:
Information Retrieval
- Search Engines: Embeddings are used to improve search relevance by understanding the semantic meaning of queries and documents.
- Retrieval Augmented Generation (RAG): Embeddings are used to retrieve knowledge for Large Language models. This is called LLM Grounding.
- Document Clustering and Topic Modeling: Embeddings help in grouping similar documents together and discovering latent topics in a corpus
Multimodal Applications
- Image Captioning: Combining text and image embeddings to generate descriptive captions for images.
- Visual Question Answering: Using both visual and textual embeddings to answer questions about images.
- Multimodal Sentiment Analysis: Combining text, image, and audio embeddings to analyze sentiment from multimedia content.
How Does EmbedAnything Help?
AI models are not easy to run. They are computationally very intensive, not easy to deploy, and hard to monitor. EmbedAnything lets you run embedding models efficiently and makes them deployment-friendly.
Here are some of the benefits of using EmbedAnything:
- Compatibility with Local and Cloud Models: Seamless integration with local and cloud-based embedding models.
- High-Speed Performance: Fast processing to meet demanding application requirements.
- Multimodal Capability: Flexibility to handle various modalities.
- CPU and GPU Acceleration: Performance optimization for both CPU and GPU environments.
- Lightweight Design: Minimized footprint for efficient resource utilization.
Let us see in detail some of these advantages in detail:
Keeping it Local
While cloud-based embedding services like OpenAI, Jina, and Mistral offer convenience, many users require the flexibility and control of local embedding models. Here’s why local models are crucial for some use cases:
- Cost-Effectiveness: Cloud services often charge per API call or model usage. Running embeddings locally on your own hardware can significantly reduce costs, especially for projects with frequent or high-volume embedding needs.
- Data Privacy: Certain data, like medical records or financial documents, might be too sensitive to upload to the cloud. Local embedding keeps your data confidential and under your control.
- Offline Functionality: An internet connection isn’t always guaranteed. Local models ensure your embedding tasks can run uninterrupted even without an internet connection.
Performance
EmbedAnything is built with Rust. This makes it faster and provides type safety and a much better development experience. But why is speed so crucial in this process?
Creating embeddings from files involves two steps that demand significant computational power:
- Extracting Text from Files, Especially PDFs: Text can exist in different formats such as markdown, PDFs, and Word documents. However, extracting text from PDFs can be challenging and often causes slowdowns. It is especially difficult to extract text in manageable batches as embedding models have a context limit. Breaking the text into paragraphs containing focused information can help.
- Inferencing on the Transformer Embedding Model: The transformer model is usually at the core of the embedding process, but it is known for being computationally expensive. To address this, EmbedAnything utilizes the Candle Framework by Hugging Face, a machine-learning framework built entirely in Rust for optimized performance.
The Benefit of Rust for Speed
By using Rust for its core functionalities, EmbedAnything offers significant speed advantages:
- Rust is Compiled: Unlike Python, Rust compiles directly to machine code, resulting in faster execution.
- Memory Management: Rust enforces memory management simultaneously, preventing memory leaks and crashes that can plague other languages.
- Rust achieves true multithreading.
CPU and GPU Acceleration with Candle
Running language models or embedding models locally can be difficult, especially when you want to deploy a product that utilizes these models. If you use the transformers library from Hugging Face in Python, you will depend on PyTorch for tensor operations. This, in turn, has a dependency on Libtorch, which means that you will need to include the entire Libtorch library with your product. Also, Candle allows inferences on CUDA-enabled GPUs right out of the box. We will soon post on how we use Candle to increase the performance and decrease the memory usage of EmbedAnything.
Multimodality
Finally, let’s see how EmbedAnything handles multimodality. When a directory is passed for embedding to EmbedAnything, the file extension is checked to see if it is text or image, and a suitable embedding model is used to generate the embeddings. Thus, it is very easy to embed documents regardless of their file type, be it .docx, .md, .pdf. Images can also be directly embedded. In future versions, there will also be the ability to embed audio files.
How to Use EmbedAnything
Let’s look at an example of how convenient it is to use EmbedAnything. We will look at the zero-shot classification of fashion images. Let’s say we have some images like this:
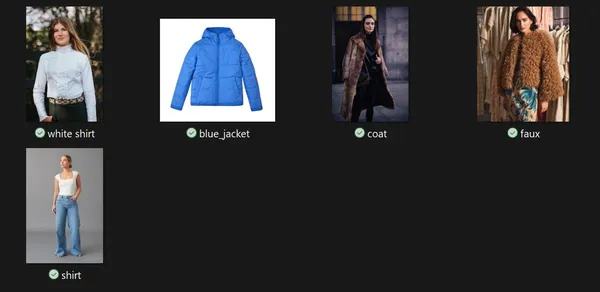
We want the model to categorize them as [‘Shirt’, ‘Coat’, ‘Jeans’, ‘Skirt’, ‘Hat’, ‘Shoes’, ‘Bag’].
To get started, you’ll need to install the embed-anything package:
pip install embed-anythingNext, import the necessary dependencies:
import embed_anything
import numpy as np
from PIL import Image
import matplotlib.pyplot as pltWith just two lines of code, you can obtain the embeddings for all the images in a directory using CLIP embeddings:
data = embed_anything.embed_directory("images", embeder= "Clip") # embed "images" folder
embeddings = np.array([data.embedding for data in data])#import csvDefine the labels that you want the model to predict and embed the labels:
labels = ['Shirt', 'Coat', 'Jeans', 'Skirt', 'Hat', 'Shoes', 'Bag']
label_embeddings = embed_anything.embed_query(labels, embeder= "Clip")
label_embeddings = np.array([label.embedding for label in label_embeddings])
fig, ax = plt.subplots(1, 5, figsize=(20, 5))
for i in range(len(data)):
similarities = np.dot(label_embeddings, data[i].embedding)
max_index = np.argmax(similarities)
image_path = data[i].text
# Open and plot the image
img = Image.open(image_path)
ax[i].imshow(img)
ax[i].axis('off')
ax[i].set_title(labels[max_index])That’s it. Now, we just check the similarities between the image embeddings and the label embeddings and assign the label to the image with the highest similarity. We can also visualize the output.

Conclusion
With EmbedAnything, adding more images to the folder or more labels to the list is effortless. This method scales very well and does not require any training, making it a powerful tool for zero-shot classification tasks
In this article, we learned about embedding models and how to use EmbedAnything to enhance your embedding pipeline, speeding up the generation process with just a few lines of code.
You can check out EmbedAnything, here.
We are actively looking for contributors to build and extend the pipeline to make embeddings easier and more powerful.
AI Developer @ Serpentine AI || TU Eindhoven
Making Starlight - Semantic Search Engine for Windows in Rust 🦀.
Building EmbedAnything - A minimal embeddings pipeline built on Candle.
I love watching large AI models train.





