Retrieval Augmented Generation systems, better known as RAG systems, have quickly become popular for building Generative AI assistants on custom enterprise data. They avoid the hassles of expensive fine-tuning of Large Language Models (LLMs). One of the key advantages of RAG systems is you can easily integrate your data, augment your LLM’s intelligence, and give more contextual answers to your questions.
However, a whole set of problems can make RAG systems underperform and, worse, give wrong answers to your questions! In this guide, we will look at a way to see how AI Agents can augment the capabilities of a traditional RAG system and improve on some of its limitations.
Overview
- Traditional RAG systems have limitations like a lack of real-time data and the potential for irrelevant document retrieval.
- The proposed Agentic Corrective RAG system uses AI agents to enhance RAG capabilities and address limitations.
- It incorporates a document grading step to check the relevance of retrieved documents to the query.
- If retrieved documents are irrelevant, it rephrases the query and performs a web search for up-to-date information.
- The system uses LangGraph, integrating components like document retrieval, grading, query rewriting, and web search.
- It aims to provide more accurate and up-to-date responses by combining static knowledge with real-time web information.
- The implementation demonstrates improved performance on queries requiring current information or outside the scope of the initial knowledge base.
Table of contents
- Traditional RAG System Architecture
- Traditional RAG System Limitations
- Corrective RAG System
- The Rise of AI Agents
- Agentic Corrective RAG System Workflow
- Detailed Agentic Corrective RAG System Architecture
- Hands-on Implementation of our Agentic RAG System with LangGraph
- Build a Vector Database for Wikipedia Data
- Create a Query Retrieval Grader
- Build a QA RAG Chain
- Create a Query Rephraser
- Load Web Search Tool
- Build Agentic RAG components
- Build the Agent Graph with LangGraph
- Test our Agentic RAG System
- Conclusion
Traditional RAG System Architecture
A Retrieval Augmented Generation (RAG) system architecture typically consists of two major steps:
- Data Processing and Indexing
- Retrieval and Response Generation
Step 1: Data Processing and Indexing
In Step 1, Data Processing and Indexing, we focus on getting our custom enterprise data into a more consumable format by loading the text content and other artifacts like tables and images, splitting large documents into smaller chunks, converting them into embeddings using an embedder model and then storing these chunks and embeddings into a vector database as depicted in the following figure.

Step 2: Retrieval and Response Generation
In Step 2 of the workflow, the process begins with the user posing a question. You retrieve chunks of relevant documents similar to the input question from the vector database. Then, you forward these documents along with the question to a Large Language Model (LLM) to generate a human-like response, as depicted in the accompanying figure.

This two-step workflow is commonly used in the industry to build a traditional RAG system; however, it comes with its own set of limitations.
Traditional RAG System Limitations
Traditional RAG systems have several limitations, some of which are mentioned as follows:
- They are not privy to real-time data
- The system is as good as the data you have in your vector database
- A bad retrieval strategy can lead to irrelevant documents being used to answer questions
- LLM can be prone to hallucinations or not being able to answer questions
In this article, we will focus particularly on the limitations of the RAG system, which does not have access to real-time data, as well as make sure the retrieved document chunks are actually relevant to answer the question. This will allow the RAG system to answer questions on more recent events and real-time data and be less prone to hallucinations.
Corrective RAG System
The inspiration for our agentic RAG system will be based on the solution proposed in the paper, Corrective Retrieval Augmented Generation, Yan et al. , where they propose a workflow as depicted in the following figure to enhance a regular RAG system. The key idea here is to retrieve document chunks from the vector database as usual and then use an LLM to check if each retrieved document chunk is relevant to the input question.
If all the retrieved document chunks are relevant, then it goes to the LLM for a normal response generation like a standard RAG pipeline. However, suppose some retrieved documents are not relevant to the input question. In that case, we rephrase the input query, search the web to retrieve new information related to the input question, and then send it to the LLM to generate a response.

The key novelty in this approach involves searching the web, augmenting static information in the vector database with live and real-time data, and checking whether retrieved documents are relevant to the input question—something that simple embedding cosine similarity cannot capture.
The Rise of AI Agents
AI Agents or Agentic AI systems have seen a rise, especially in 2024, which enables us to build Generative AI systems that can reason, analyze, interact, and take actions automatically. The whole idea of Agentic AI is to build completely autonomous systems that can understand and manage complex workflows and tasks with minimal human intervention. Agentic systems can grasp nuanced concepts, set and pursue goals, reason through tasks, and adapt their actions based on changing conditions. These systems can consist of a single agent or multiple agents. The example below shows two agents working together to transform the user’s instructions into functioning code snippets.

One can use various frameworks to build Agentic AI systems, including CrewAI, LangChain, LangGraph, AutoGen, and many more. Using these frameworks enables us to develop complex workflows with ease. Remember, an agent is basically one or more LLMs having access to a set of tools that they can leverage based on specific prompt-based instructions to answer user questions.
We will be using LangGraph for our practical implementation of our Agentic RAG system. LangGraph, built on top of LangChain, facilitates the creation of cyclical graphs essential for developing AI agents powered by LLMs. The widely-used NetworkX library inspires its interface. It enables the coordination and checkpointing of multiple chains (or actors) through cyclic computational steps. LangGraph treats Agent workflows as a cyclical Graph structure, as depicted in the following figure.

The main components in any LangGraph agent include:
- Nodes: Functions or LangChain Runnable objects such as tools
- Edges: Specify directional paths between nodes
- Stateful Graphs: Manage and update state objects while processing data through nodes
LangGraph leverages this to facilitate cyclical LLM call executions with state persistence, which AI agents often require.
Agentic Corrective RAG System Workflow
In this section, we will see a high-level workflow of the main components in our Agentic RAG system and the execution flow among these components. The following figure illustrates this in detail.

Each component in this workflow is represented by a node. There are two major flows here in this Agentic RAG system. One flow is the regular RAG system workflow, where we have a user question and retrieve context documents from the vector database. However, we introduce an additional step here based on the corrective RAG paper where we use an LLM to check if all retrieved documents are relevant to the user question (in the grade node); if they are all relevant, then we generate a response using an LLM as shown in the following snapshot.

The other flow occurs in case at least one or more of the retrieved context documents from the vector database are irrelevant to the user question, as depicted in the following snapshot. Then, we leverage an LLM to rewrite the user query and optimize it for search on the web. Next, we leverage a web search tool to search the web using this rephrased query and get some new documents. Finally, we send the query and any relevant context documents (including the web search documents) to an LLM to generate a response.

Detailed Agentic Corrective RAG System Architecture
Now, deep dive into a detailed system architecture for our Agentic Corrective RAG System. We will understand each component and what happens step-by-step in the workflow. The following illustration depicts this in detail.
We will start with a user query that goes to the vector database (we will be using Chroma) and retrieves some context documents. There is a possibility that no documents could be retrieved if the user query is based on recent events or topics outside the scope of our initial data in the vector database.
In the next step, we will send our user query and context documents to an LLM and make it act as a document grader. It will grade each context document as ‘Yes’ or ‘No’ depending on whether they are relevant to the user query in terms of meaning and context.
The next step involves the decision node where there are two possible pathways, let’s consider the first path which is taken if ALL the context documents are relevant to the user query.
If all the documents are relevant to the input query, then we go through a standard RAG flow where the documents and query are sent to an LLM to generate a contextual response as an answer for the user query.
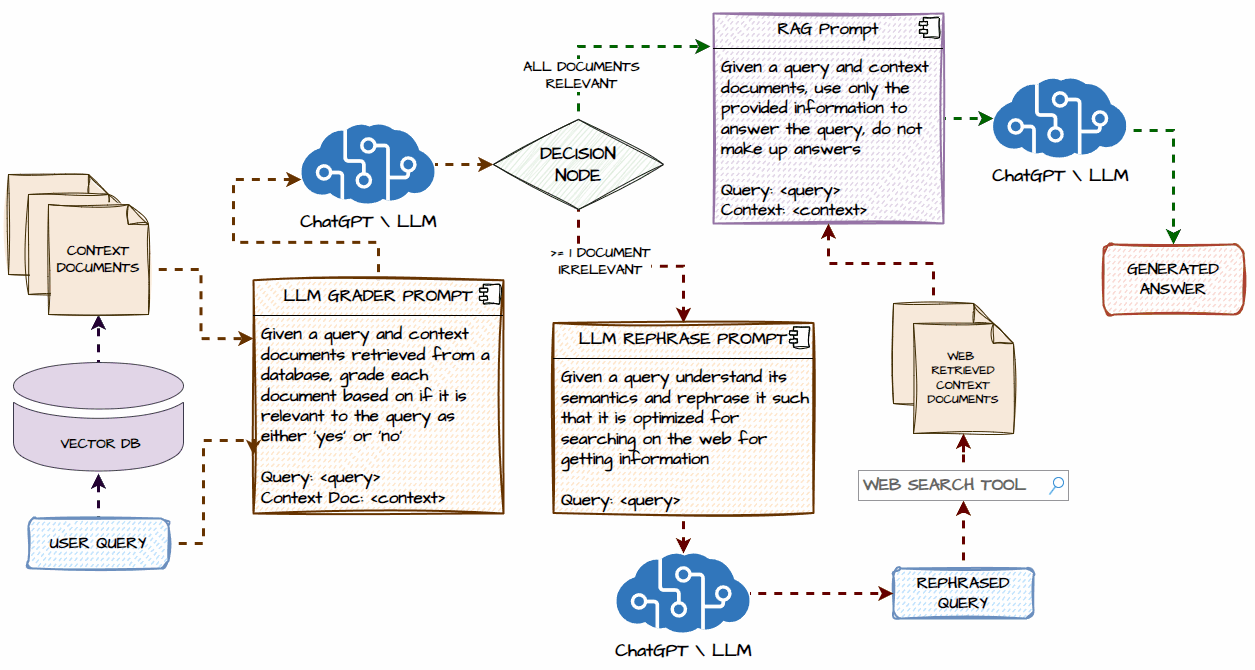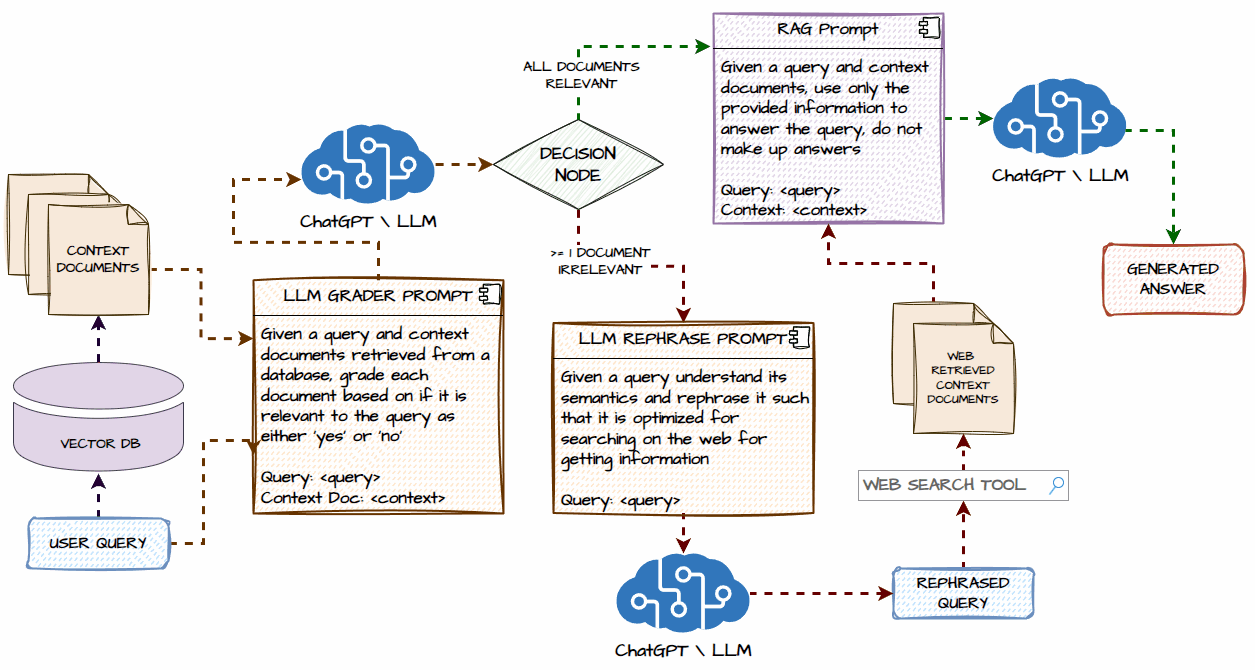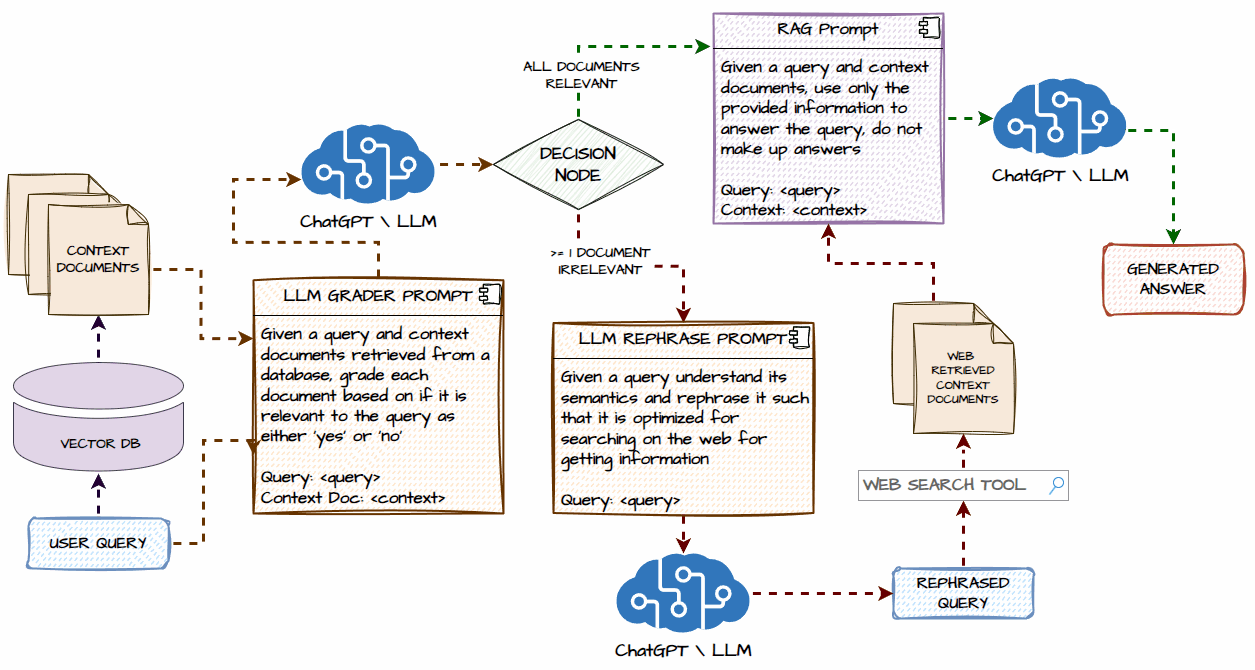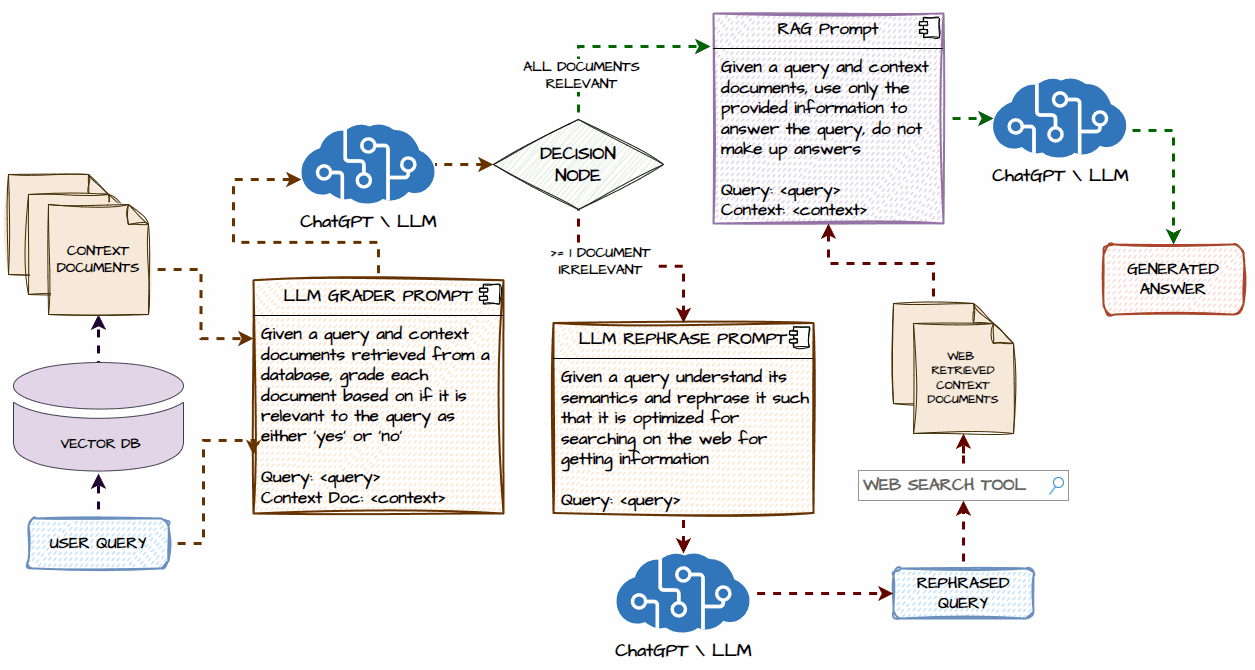
The other path is taken from the decision node only if at least one or more context documents are irrelevant to the user query OR there are no context documents for the given user query. Then, we take the user query, send it to an LLM, and ask it to rephrase the user query to optimize it for searching on the web.
The next step involves invoking the web search tool, in our implementation we will be using the Tavily Web Search API tool to search the web and get relevant information as context documents and then add them to the list of any relevant context documents retrieved from the vector database.
The next step is going through the same RAG flow of response generation using the query and context documents, including the real-time information retrieved from the web.
Hands-on Implementation of our Agentic RAG System with LangGraph
We will now implement the Agentic RAG System we have discussed so far using LangGraph. We will be loading some documents from Wikipedia into our vector database, the Chroma database. and also using the Tavily Search tool for web search. Connections to LLMs and prompting will be made with LangChain, and the agent will be built using LangGraph. For our LLM, we will be using ChatGPT GPT-4o, which is a powerful LLM that has native support for tool calling. However, you are free to use any other LLM, also including open-source LLMs, it is recommended to use a powerful LLM, fine-tuned for tool calling to get the best performance.
Install Dependencies
We start by installing the necessary dependencies, which are going to be the libraries we will be using to build our system.
!pip install langchain==0.2.0
!pip install langchain-openai==0.1.7
!pip install langchain-community==0.2.0
!pip install langgraph==0.1.1
!pip install langchain-chroma==0.1.1Enter Open AI API Key
We enter our Open AI key using the getpass() function, so we don’t accidentally expose our key in the code.
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')Enter Tavily Search API Key
We enter our Open AI key using the getpass() function, so we don’t accidentally expose our key in the code. Get a free API key from here.
TAVILY_API_KEY = getpass('Enter Tavily Search API Key: ')Setup Environment Variables
Next, we setup some system environment variables that will be used later when authenticating LLMs and searching APIs.
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEYBuild a Vector Database for Wikipedia Data
We will now build a vector database for retrieval and search by taking a subset of documents from Wikipedia. We have already extracted these documents from Wikipedia and stored them in an archived file.
Open AI Embedding Models
LangChain enables us to access Open AI embedding models, which include the newest models: a smaller and highly efficient text-embedding-3-small model and a larger and more powerful text-embedding-3-large model. We need an embedding model to convert our document chunks into embeddings before storing them in our vector database.
from langchain_openai import OpenAIEmbeddings
# details here: https://openai.com/blog/new-embedding-models-and-api-updates
openai_embed_model = OpenAIEmbeddings(model='text-embedding-3-small')Get the Wikipedia Data
We have downloaded and made the wikipedia documents available in an archive file on Google Drive, you can either download it manually or use the following library to download it.
If you can’t download using the following code, go to:
Google Drive Link: https://drive.google.com/file/d/1oWBnoxBZ1Mpeond8XDUSO6J9oAjcRDyW
Download it and manually upload it on Google Colab
Using Google Colab: !gdown 1oWBnoxBZ1Mpeond8XDUSO6J9oAjcRDyW
Load and Chunk Documents
We will now unzip the data archive, load the documents, split and chunk them into more manageable document chunks before indexing them.
import gzip
import json
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
wikipedia_filepath = 'simplewiki-2020-11-01.jsonl.gz'
docs = []
with gzip.open(wikipedia_filepath, 'rt', encoding='utf8') as fIn:
for line in fIn:
data = json.loads(line.strip())
#Add documents
docs.append({
'metadata': {
'title': data.get('title'),
'article_id': data.get('id')
},
'data': ' '.join(data.get('paragraphs')[0:3])
# restrict data to first 3 paragraphs to run later modules faster
})
# We subset our data to use a subset of wikipedia documents to run things faster
docs = [doc for doc in docs for x in ['india']
if x in doc['data'].lower().split()]
# Create docs
docs = [Document(page_content=doc['data'],
metadata=doc['metadata']) for doc in docs]
# Chunk docs
splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=300)
chunked_docs = splitter.split_documents(docs)
chunked_docs[:3]OUTPUT
[Document(page_content='Basil ("Ocimum basilicum") ( or ) is a plant of the
Family Lamiaceae. It is also known as Sweet Basil or Tulsi..... but this
likely was a linguistic reworking of the word as brought from Greece.',
metadata={'title': 'Basil', 'article_id': '73985'}),
Document(page_content='The Roerich Pact is a treaty on Protection of Artistic
and Scientific Institutions and Historic Monuments, ...... He became a
successful painter. One of his paintings was purchased by Nicholas II of
Russia.', metadata={'title': 'Roerich’s Pact', 'article_id': '259745'}),
Document(page_content='Nicolas "Nico" Hülkenberg (born 19 August 1987 in
Emmerich am Rhein, North Rhine-Westphalia) is a German racing driver......
For the season, he is the third driver for the Force India team.', metadata=
{'title': 'Nico Hülkenberg', 'article_id': '260252'})]
Create a Vector DB and Persist on the Disk
Here, we initialize a connection to a Chroma vector DB client and save the data to disk by initializing the Chroma client and passing the directory where we want to save the data. We also specify to use the Open AI embedding model to transform each document chunk into an embedding and to store the document chunks and their corresponding embeddings in the vector database index.
from langchain_chroma import Chroma
# create vector DB of docs and embeddings - takes < 30s on Colab
chroma_db = Chroma.from_documents(documents=chunked_docs,
collection_name='rag_wikipedia_db',
embedding=openai_embed_model,
# need to set the distance function to cosine else it uses Euclidean by default
# check https://docs.trychroma.com/guides#changing-the-distance-function
collection_metadata={"hnsw:space": "cosine"},
persist_directory="./wikipedia_db")Setup a Vector Database Retriever
Here, we use the Similarity with Threshold Retrieval strategy, which uses cosine similarity and retrieves the top 3 similar documents based on the user input query and also introduces a cutoff to not return any documents that are below a certain similarity threshold (0.3 in this case).
similarity_threshold_retriever = chroma_db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={"k": 3,
"score_threshold": 0.3})
We can then test if our retriever is working on some sample queries.
query = "what is the capital of India?"
top3_docs = similarity_threshold_retriever.invoke(query)
top3_docsOUTPUT
[Document(page_content='New Delhi () is the capital of India and a union
territory of the megacity of Delhi. .......population of about 9.4 Million
people.', metadata={'article_id': '5117', 'title': 'New Delhi'}),
Document(page_content="Mumbai (previously known as Bombay until 1996) is a
natural harbor on the west coast of India, and is the capital city of
Maharashtra state. ...... It also has the Hindi film and television
industry, known as Bollywood.", metadata={'article_id': '5114', 'title':
'Mumbai'}),
Document(page_content='The Republic of India is divided into twenty-eight
States,and ...... Territory.', metadata={'article_id': '22215', 'title':
'States and union territories of India'})]
For queries without relevant documents in the vector database, we will get an empty list, as shown in the following example query.
query = "what is langgraph?"
top3_docs = similarity_threshold_retriever.invoke(query)
top3_docsOUTPUT
[]Create a Query Retrieval Grader
Here, we will use an LLM itself to grade if any retrieved document is relevant to the given question – The answer will be either yes or no. The LLM, in our case, will be GPT-4o.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model for LLM output format
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM for grading
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt template for grading
SYS_PROMPT = """You are an expert grader assessing relevance of a retrieved document to a user question.
Follow these instructions for grading:
- If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant.
- Your grade should be either 'yes' or 'no' to indicate whether the document is relevant to the question or not."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", SYS_PROMPT),
("human", """Retrieved document:
{document}
User question:
{question}
"""),
]
)
# Build grader chain
doc_grader = (grade_prompt
|
structured_llm_grader)We can test out this grader on some sample user queries and see how relevant are the retrieved context documents from the vector database.
query = "what is the capital of India?"
top3_docs = similarity_threshold_retriever.invoke(query)
for doc in top3_docs:
print(doc.page_content)
print('GRADE:', doc_grader.invoke({"question": query,
"document": doc.page_content}))
print()OUTPUT
New Delhi () is the capital of India ......
GRADE: binary_score='yes'
Mumbai (previously known as Bombay until 1996) ......
GRADE: binary_score='no'
The Republic of India is divided ......
GRADE: binary_score='no'
We can see that the LLM does a pretty good job of detecting relevant and irrelevant documents about the user query.
Build a QA RAG Chain
Here, we will connect our retriever to an LLM, GPT-4o, in our case, and build our Question-answering RAG chain. Remember, this will be our traditional RAG system, which we will integrate with an AI Agent later.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
# Create RAG prompt for response generation
prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If no context is present or if you don't know the answer, just say that you don't know the answer.
Do not make up the answer unless it is there in the provided context.
Give a detailed answer and to the point answer with regard to the question.
Question:
{question}
Context:
{context}
Answer:
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
# Initialize connection with GPT-4o
chatgpt = ChatOpenAI(model_name='gpt-4o', temperature=0)
# Used for separating context docs with new lines
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# create QA RAG chain
qa_rag_chain = (
{
"context": (itemgetter('context')
|
RunnableLambda(format_docs)),
"question": itemgetter('question')
}
|
prompt_template
|
chatgpt
|
StrOutputParser()
)The idea here is to get the user query, retrieve the context documents from the vector database or web search, and then send them as inputs to the RAG prompt mentioned above, which goes into GPT-4o to generate a human-like response. Let’s test out a few queries in our traditional RAG system now.
query = "what is the capital of India?"
top3_docs = similarity_threshold_retriever.invoke(query)
result = qa_rag_chain.invoke(
{"context": top3_docs, "question": query}
)
print(result)OUTPUT
The capital of India is New Delhi. It is also a union territory and part of
the megacity of Delhi.
Let’s now try a question that is out of context, such that no context documents related to the question are there in the vector database.
query = "who won the champions league in 2024?"
top3_docs = similarity_threshold_retriever.invoke(query)
result = qa_rag_chain.invoke(
{"context": top3_docs, "question": query}
)
print(result)OUTPUT
I don't know the answer. The provided context does not contain information
about the winner of the Champions League in 2024.
The RAG system behaves as expected; the shortcoming here is that it cannot answer out-of-context questions, which is what we will try to improve on in the next steps
Also read: Build an AI Coding Agent with LangGraph by LangChain
Create a Query Rephraser
We will now build a query rephraser, which will use an LLM, GPT-4o in our case, to rephrase the input user query into a better version that is optimized for web search. This will help us get better context information from the web for our query.
# LLM for question rewriting
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Prompt template for rewriting
SYS_PROMPT = """Act as a question re-writer and perform the following task:
- Convert the following input question to a better version that is optimized for web search.
- When re-writing, look at the input question and try to reason about the underlying semantic intent / meaning.
"""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", SYS_PROMPT),
("human", """Here is the initial question:
{question}
Formulate an improved question.
""",
),
]
)
# Create rephraser chain
question_rewriter = (re_write_prompt
|
llm
|
StrOutputParser())Let’s try this on a sample question to see how our rephraser chain works.
query = "who won the champions league in 2024?"
question_rewriter.invoke({"question": query})OUTPUT
Who was the winner of the 2024 UEFA Champions League?
Load Web Search Tool
Here, we will use the Tavily API for our web searches, so we load up a connection to this API. For our searches, we will use the top 3 search results as additional context information; however, you are free to load in more search results.
from langchain_community.tools.tavily_search import TavilySearchResults
tv_search = TavilySearchResults(max_results=3, search_depth='advanced',max_tokens=10000)Build Agentic RAG components
Here, we will build the key components of our Agentic Corrective RAG System as per the workflow we discussed earlier in our guide. These functions will be put into relevant agent nodes via LangGraph later on when we build our agent.
Graph State
This is used to store and represent the state of the agent graph as we traverse through various nodes. It will store and keep track of the user query, a flag variable telling us if a web search is needed, a list of context documents (retrieved from the vector database and \ or web search), and the LLM-generated response.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM response generation
web_search_needed: flag of whether to add web search - yes or no
documents: list of context documents
"""
question: str
generation: str
web_search_needed: str
documents: List[str]Retrieve function for retrieval from Vector DB
This will be used to get relevant context documents from the vector database using our retriever, which we built earlier. Remember, as this will be a node in the agent graph, later on, we will be getting the user question from the graph state and then pass it to our retriever to get relevant context documents from the vector database.
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents - that contains retrieved context documents
"""
print("---RETRIEVAL FROM VECTOR DB---")
question = state["question"]
# Retrieval
documents = similarity_threshold_retriever.invoke(question)
return {"documents": documents, "question": question}Grade documents
This will be used to determine whether the retrieved documents are relevant to the question using an LLM Grader. It sets the web_search_needed flag as Yes if at least one document is not contextually relevant OR no context documents were retrieved. Otherwise, it sets the flag as No if all documents are contextually relevant to the given user query. It updates the state graph by ensuring context documents consist of only relevant documents.
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
by using an LLM Grader.
If any document are not relevant to question or documents are empty - Web Search needs to be done
If all documents are relevant to question - Web Search is not needed
Helps filtering out irrelevant documents
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search_needed = "No"
if documents:
for d in documents:
score = doc_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
web_search_needed = "Yes"
continue
else:
print("---NO DOCUMENTS RETRIEVED---")
web_search_needed = "Yes"
return {"documents": filtered_docs, "question": question,
"web_search_needed": web_search_needed}Rewrite query
This will be used to rewrite the input query to produce a better question optimized for web search using an LLM, this will also update the query in the state graph so it can be accessed by other nodes in our agent graph which we will be creating shortly.
def rewrite_query(state):
"""
Rewrite the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased or re-written question
"""
print("---REWRITE QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}Web Search
This will be used to search the web using the web search tool for the given query and retrieve some information from the web, which can be used as additional context documents in our RAG system. We will use the Tavily Search API tool in our system, as discussed earlier. This function also updates the state graph, especially the list of context documents, with new documents retrieved from the web for the rephrased user query.
from langchain.schema import Document
def web_search(state):
"""
Web search based on the re-written question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = tv_search.invoke(question)
web_results = "\n\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"documents": documents, "question": question}Generate Answer
This is the standard LLM response generation function from query and context documents in an RAG system. We also update the generation field in the state graph so we can access it anytime in our agent graph and output the response to the user as needed.
def generate_answer(state):
"""
Generate answer from context document using LLM
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE ANSWER---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = qa_rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question,
"generation": generation}Decide to Generate
This will use this as a conditional function to check the web_search_needed flag from the agent graph state and decide whether to generate a web search or a response. It will return the function name to call. If a web search is necessary, the system returns the rewrite_query string, prompting our agentic RAG system to follow the flow of query rephrasing, search, and response generation. If a web search is unnecessary, the function will return the generate_answer string, enabling our RAG system to go into the regular flow of generating a response from the given context documents and query. You will use this function in the conditional node of our agent graph to route the flow to the correct function based on the two possible pathways.
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
web_search_needed = state["web_search_needed"]
if web_search_needed == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: SOME or ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, REWRITE QUERY---")
return "rewrite_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE RESPONSE---")
return "generate_answer"Build the Agent Graph with LangGraph
Here, we will use LangGraph and build the agent as a graph using the functions we implemented in the previous section, put them in relevant nodes as per our Agentic RAG system architecture, and connect them with relevant edges as per the defined workflows
from langgraph.graph import END, StateGraph
agentic_rag = StateGraph(GraphState)
# Define the nodes
agentic_rag.add_node("retrieve", retrieve) # retrieve
agentic_rag.add_node("grade_documents", grade_documents) # grade documents
agentic_rag.add_node("rewrite_query", rewrite_query) # transform_query
agentic_rag.add_node("web_search", web_search) # web search
agentic_rag.add_node("generate_answer", generate_answer) # generate answer
# Build graph
agentic_rag.set_entry_point("retrieve")
agentic_rag.add_edge("retrieve", "grade_documents")
agentic_rag.add_conditional_edges(
"grade_documents",
decide_to_generate,
{"rewrite_query": "rewrite_query", "generate_answer": "generate_answer"},
)
agentic_rag.add_edge("rewrite_query", "web_search")
agentic_rag.add_edge("web_search", "generate_answer")
agentic_rag.add_edge("generate_answer", END)
# Compile
agentic_rag = agentic_rag.compile()We can now visualize our Agentic RAG System workflow using the following code.
from IPython.display import Image, display, Markdown
display(Image(agentic_rag.get_graph().draw_mermaid_png()))
Test our Agentic RAG System
Finally, we are ready to test our Agentic RAG System live on some user queries! Since we placed print statements inside relevant functions in our graph nodes, we can see them print as the execution occurs in the graph.
query = "what is the capital of India?"
response = agentic_rag.invoke({"question": query})OUTPUT
---RETRIEVAL FROM VECTOR DB---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: SOME or ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, REWRITE QUERY---
---REWRITE QUERY---
---WEB SEARCH---
---GENERATE ANSWER—
We can see that some documents retrieved from the vector database were not relevant so it has also retrieved context information from the web successfully and generated a response, we can check out the generated response now.
display(Markdown(response['generation']))OUTPUT
The capital city of India is New Delhi. It is a union territory within the
larger metropolitan area of Delhi and is situated in the north-central part
of the country on the west bank of the Yamuna River. New Delhi was formally
dedicated as the capital in 1931 and has a population of about 9.4 million
people.
Let’s try another scenario where no relevant context documents exist in the vector database for the given user query.
query = "who won the champions league in 2024?"
response = agentic_rag.invoke({"question": query})OUTPUT
---RETRIEVAL FROM VECTOR DB---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: SOME or ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, REWRITE QUERY---
---REWRITE QUERY---
---WEB SEARCH---
---GENERATE ANSWER---
The system seems to be working as expected, it doesn’t have any context documents so it retrieves new information from the web using the web search tool to generate a response to our query. We can check the response now.
display(Markdown(response['generation']))OUTPUT
The winner of the 2024 UEFA Champions League was Real Madrid. They secured
victory in the final against Borussia Dortmund with goals from Dani Carvajal
and Vinicius Junior.
Let’s test our last scenario to check whether the flow works fine. In this scenario, all retrieved documents from the vector database are relevant to the user query, so ideally, no web search should take place.
query = "Tell me about India"
response = agentic_rag.invoke({"question": query})OUTPUT
---RETRIEVAL FROM VECTOR DB---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE RESPONSE---
---GENERATE ANSWER—
Our agentic RAG system is working quite well as you can see in this case it does not do a web search as all retrieved documents are relevant for answering the user question. We can now check out the response.
display(Markdown(response['generation']))OUTPUT
India is a country located in Asia, specifically at the center of South Asia.
It is the seventh largest country in the world by area and the largest in
South Asia. . . . . . .
India has a rich and diverse history that spans thousands of years,
encompassing various languages, cultures, periods, and dynasties. The
civilization began in the Indus Valley, . . . . . .
Conclusion
In this guide, we went through an in-depth understanding of the current challenges in traditional RAG systems, the role and importance of AI Agents, and how Agentic RAG systems can tackle some of these challenges. We discussed at length a detailed system architecture and workflow for an Agentic Corrective RAG system inspired by the Corrective Retrieval Augmented Generation paper. Last but not least, we implemented this Agentic RAG system with LangGraph and tested it on various scenarios. Check out this Colab notebook for easy access to the code and try improving this system by adding more capabilities like additional hallucination checks and more!
Unlock your potential with the GenAI Pinnacle Program where you can learn how to build such Agentic AI systems in detail! Revolutionize your AI learning and development journey through 1:1 mentorship with Generative AI experts, an advanced curriculum offering over 200 hours of intensive learning, and mastery of 26+ GenAI tools and libraries. Elevate your skills and become a leader in AI.
Head of Community, Principal AI Scientist at Analytics Vidhya, Published Author and AI Advisor with over 10 years of global experience working with Fortune 100 companies, startups and academic organizations






