Introduction
Imagine sifting through thousands of photos to find that one perfect shot—tedious, right? Now, picture a system that can do this in seconds, instantly presenting you with the most similar images based on your query. In this article, you’ll dive into the fascinating world of image similarity search, where we’ll transform photos into numerical vectors using the powerful VGG16 model. With these vectors indexed by FAISS, a tool designed to swiftly and accurately locate similar items, you’ll learn how to build a streamlined and efficient search system. By the end, you’ll not only grasp the magic behind vector embeddings and FAISS but also gain hands-on skills to implement your own high-speed image retrieval system.
Learning Objectives
- Understand how vector embeddings convert complex data into numerical representations for analysis.
- Learn the role of VGG16 in generating image embeddings and its application in image similarity search.
- Gain insight into FAISS and its capabilities for indexing and fast retrieval of similar vectors.
- Develop skills to implement an image similarity search system using VGG16 and FAISS.
- Explore challenges and solutions related to high-dimensional data and efficient similarity searches.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Understanding Vector Embeddings
- Advantages of Vector Embeddings
- What is VGG16?
- Using FAISS for Indexing
- Code Implementation using Vector Embeddings
- Step 1: Import Libraries
- Step 2: Load Images from Folder
- Step 3: Load Pre-trained Model and Remove Top Layers
- Step 4: Compute Embeddings Using VGG16
- Step 5: Create FAISS Index
- Step 6: Load Images and Compute Embeddings
- Step 7: Search for Similar Images
- Step 8: Example Usage
- Step 9: Display Results
- Step 10: Display Images Using cv2_imshow
- Challenges Faced
- Frequently Asked Questions
Understanding Vector Embeddings
Vector embeddings are a way to represent data like images, text, or audio as numerical vectors. In this representation similar items are positioned near each other in a high-dimensional space, which helps computers quickly find and compare related information.
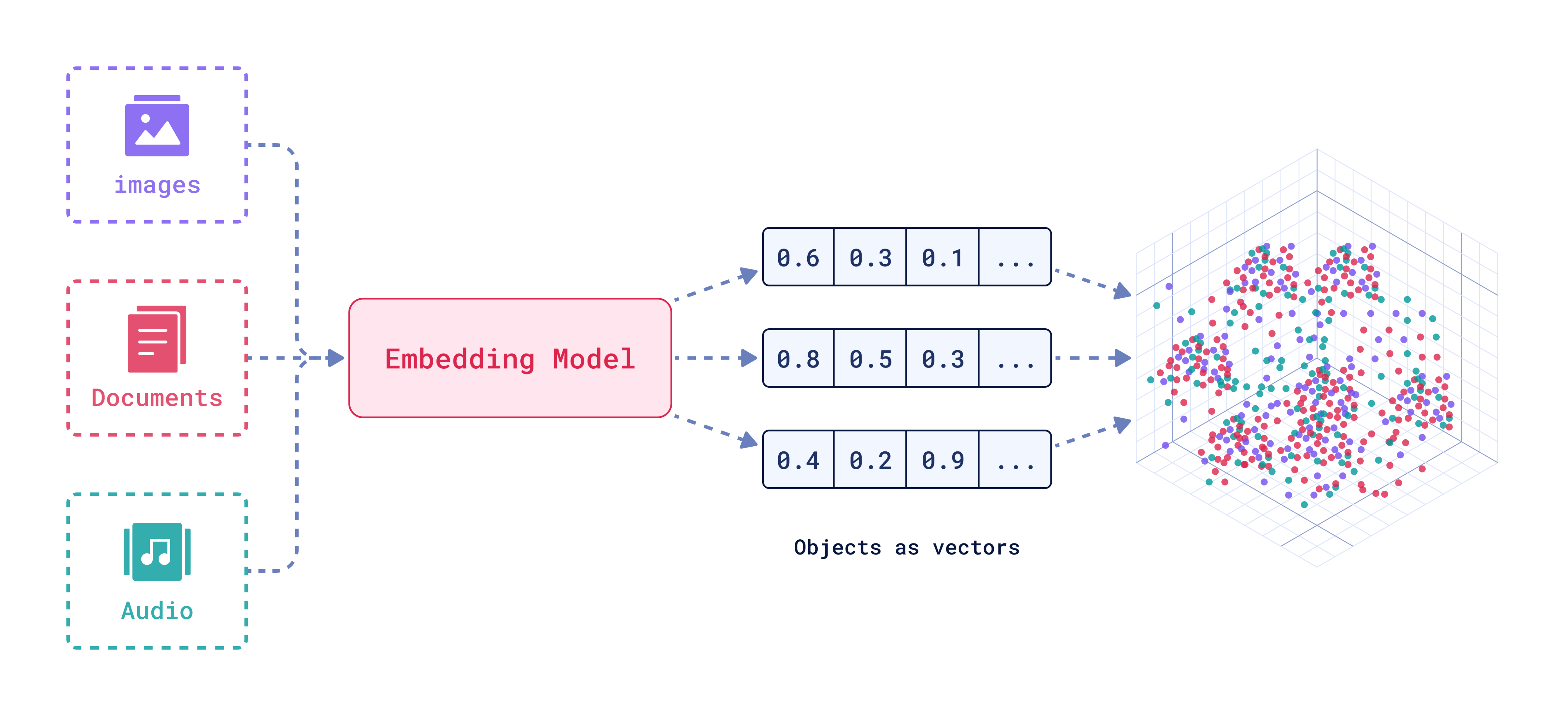
Advantages of Vector Embeddings
Let us now explore advantages of vector embeddings in detail.
- Vector embeddings are time efficient as distance between vectors can be computed rapidly.
- Embeddings handle large dataset efficiently making them scalable and suitable for big data applications.
- High-dimensional data, such as images, can represent lower-dimensional spaces without losing significant information. This representation simplifies storage and enhances space efficiency. It captures the semantic meaning between data items, leading to more accurate results in tasks requiring contextual understanding, such as NLP and image recognition.
- Vector embeddings are versatile as they can be applied to different data types
- Pre-trained embeddings and vector databases are available which reduce the need for extensive training of data thus we save on computational resources.
- Traditionally feature engineering techniques require manual creation and selection of features, embeddings automate feature engineering process by learning features from data.
- Embeddings are more adaptable to new inputs better as compared to rule-based models.
- Graph based approaches also capture complex relations but require more complex data structures and algorithms, embeddings are computationally less extensive.
What is VGG16?
We will be using VGG16 to calculate our image embeddings .VGG16 is a Convolutional Neural Network it is an object detection and classification algorithm. The 16 stands for the 16 layers with learnable weights in the network.
Starting with an input image and resizing it to 224×224 pixels with three color channels . These are now passed to a convolutional layers which are like a series of filters that look at small parts of the image. Each filter here captures different features such as edges, colors, textures and so on. VGG16 uses 3X3 filters which means that they look at 3X3 pixel area at a time. There are 13 convolutional layers in VGG16.This is followed by the Activation Function (ReLU) which stands for Rectified Linear Unit and it adds non linearity to the model which allows it to learn more complex patters.
Next are the Pooling Layers which reduce the size of the image representation by taking the most important information from small patches which shrinks the image while keeping the important features.VGG16 uses 2X2 pooling layers which means it reduces the image size by half. Finally the Fully Connected Layer receives the output and uses all the information that the convolutional layers have learned to arrive at a final conclusion. The output layer determines which class the input image most likely belongs to by generating probabilities for each class using a softmax function.

First load the model then use VGG16 with pre-trained weights but remove the last layer that gives the final classification. Now resize and preprocess the images to fit the model’s requirements which is 224 X 224 pixels and finally compute embeddings by passing the images through the model from one of the fully connected layers.
Using FAISS for Indexing
Facebook AI Research developed Facebook AI Similarity Search (FAISS) to efficiently search and cluster dense vectors. FAISS excels at handling large-scale datasets and quickly finding items similar to a query.
What is Similarity Searching ?
FAISS constructs an index in RAM when you provide a vector of dimension (d_i). This index, an object with an add method, stores the (x_i) vector, assuming a fixed dimension for (x_i).
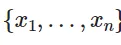
After the structure is constructed when a new vector x is provided in dimension d it performs the following operation. Computing the argmin is the search operation on the index.
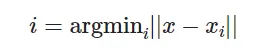
FAISS find the items in the index closest to the new item.
Here || .|| represents the Euclidean distance (L2). The closeness is measured using Euclidean distance.
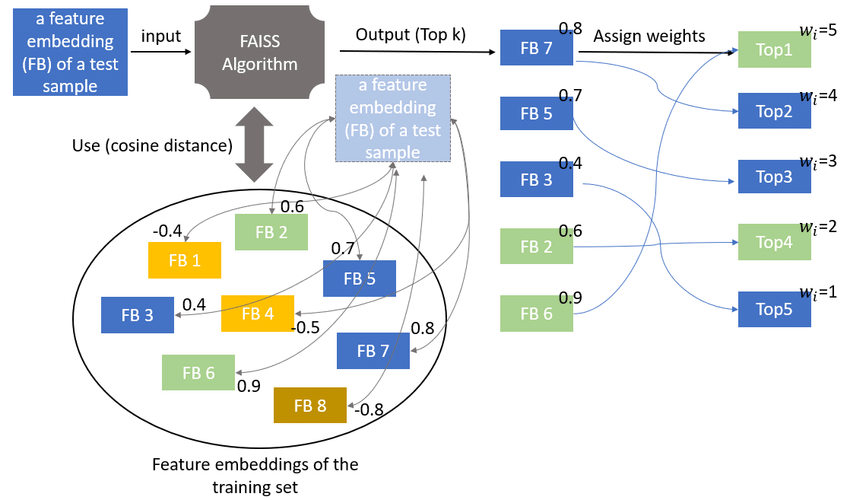
Code Implementation using Vector Embeddings
We will now look into code Implementation for detection of similar images using vector embeddings.
Step 1: Import Libraries
Import necessary libraries for image processing, model handling, and similarity searching.
import cv2
import numpy as np
import faiss
import os
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.preprocessing import image
from keras.models import Model
from google.colab.patches import cv2_imshowStep 2: Load Images from Folder
Define a function to load all images from a specified folder and its subfolders.
# Load images from folder and subfolders
def load_images_from_folder(folder):
images = []
image_paths = []
for root, dirs, files in os.walk(folder):
for file in files:
if file.endswith(('jpg', 'jpeg', 'png')):
img_path = os.path.join(root, file)
img = cv2.imread(img_path)
if img is not None:
images.append(img)
image_paths.append(img_path)
return images, image_pathsStep 3: Load Pre-trained Model and Remove Top Layers
Load the VGG16 model pre-trained on ImageNet and modify it to output embeddings from the ‘fc1’ layer.
# Load pre-trained model and remove top layers
base_model = VGG16(weights='imagenet')
model = Model(inputs=base_model.input, outputs=base_model.get_layer('fc1').output)Step 4: Compute Embeddings Using VGG16
Define a function to compute image embeddings using the modified VGG16 model.
# Compute embeddings using VGG16
def compute_embeddings(images)
embeddings = []
for img in images:
img = cv2.resize(img, (224, 224))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input(img)
img_embedding = model.predict(img)
embeddings.append(img_embedding.flatten())
return np.array(embeddings)Step 5: Create FAISS Index
Define a function to create a FAISS index from the computed embeddings.
def create_index(embeddings):
d = embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(embeddings)
return indexStep 6: Load Images and Compute Embeddings
Load images, compute their embeddings, and create a FAISS index.
images, image_paths = load_images_from_folder('images')
embeddings = compute_embeddings(images)
index = create_index(embeddings)Step 7: Search for Similar Images
Define a function to search for the most similar images in the FAISS index.
def search_similar_images(index, query_embedding, top_k=1):
D, I = index.search(query_embedding, top_k)
return IStep 8: Example Usage
Load a query image, compute its embedding, and search for similar images.
# Search for similar images
def search_similar_images(index, query_embedding, top_k=1):
D, I = index.search(query_embedding, top_k)
return IStep 9: Display Results
Print the indices and file paths of the similar images.
print("Similar images indices:", similar_images_indices)
for idx in similar_images_indices[0]:
print(image_paths[idx])Step 10: Display Images Using cv2_imshow
Display the query image and the most similar images using OpenCV’s cv2_imshow.
print("Query Image")
cv2_imshow(query_image)
cv2.waitKey(0) # Wait for a key press to close the image
for idx in similar_images_indices[0]:
similar_image = cv2.imread(image_paths[idx])
print("Most Similar Image")
cv2_imshow(similar_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

I have made use of Vegetable images dataset for code implementation a similar dataset can be found here.
Challenges Faced
- Storing high dimensional embeddings for a large number of images consumes a large amount of memory.
- Generating embeddings and performing similarity searches can be computationally intensive
- Variations in image quality, size and format can affect the accuracy of embeddings.
- Creating and updating the FAISS index can be time-consuming incase of very large datasets.
Conclusion
We explored the creation of an image similarity search system by leveraging vector embeddings and FAISS (Facebook AI Similarity Search). We began by understanding vector embeddings and their role in representing images as numerical vectors, facilitating efficient similarity searches. Using the VGG16 model, we computed image embeddings by processing and resizing images to extract meaningful features. We then created a FAISS index to efficiently manage and search through these embeddings.
Finally, we demonstrated how to query this index to find similar images, highlighting the advantages and challenges of working with high-dimensional data and similarity search techniques. This approach underscores the power of combining deep learning models with advanced indexing methods to enhance image retrieval and comparison capabilities.
Key Takeaways
- Vector embeddings transform complex data like images into numerical vectors for efficient similarity searches.
- VGG16 model extracts meaningful features from images, creating detailed embeddings for comparison.
- FAISS indexing accelerates similarity searches by efficiently managing and querying large sets of image embeddings.
- Image similarity search leverages advanced indexing techniques to quickly identify and retrieve comparable images.
- Handling high-dimensional data involves challenges in memory usage and computational resources but is crucial for effective similarity searches.
Frequently Asked Questions
Q1. What are vector embeddings?
A. Vector embeddings are numerical representations of data elements, such as images, text, or audio. They position similar items close to each other in a high-dimensional space, enabling efficient similarity searches and comparisons by computers.
Q2. Why are vector embeddings used?
A. Vector embeddings simplify and accelerate finding and comparing similar items in large datasets. They allow for efficient computation of distances between data points, making them ideal for tasks requiring quick similarity searches and contextual understanding.
Q3. What is FAISS (Facebook AI Similarity Search)?
A. FAISS, developed by Facebook AI Research, efficiently searches and clusters dense vectors. Designed for large-scale datasets, it quickly retrieves similar items by creating and searching through an index of vector embeddings.
Q4. How does FAISS operate?
A. FAISS operates by creating an index from the vector embeddings of your data. When you supply a new vector, FAISS searches the index to find the closest vectors. It typically measures similarity using Euclidean distance (L2).
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Aadya Singh is a passionate and enthusiastic individual excited about sharing her knowledge and growing alongside the vibrant Analytics Vidhya Community. Armed with a Bachelor's degree in Bio-technology from MS Ramaiah Institute of Technology in Bangalore, India, she embarked on a journey that would lead her into the intriguing realms of Machine Learning (ML) and Natural Language Processing (NLP).
Aadya's fascination with technology and its potential began with a profound curiosity about how computers can replicate human intelligence. This curiosity served as the catalyst for her exploration of the dynamic fields of ML and NLP, where she has since been captivated by the immense possibilities for creating intelligent systems.
With her academic background in bio-technology, Aadya brings a unique perspective to the world of data science and artificial intelligence. Her interdisciplinary approach allows her to blend her scientific knowledge with the intricacies of ML and NLP, creating innovative and impactful solutions.





