Introduction
By incorporating visual capabilities into the potent language model GPT-4, ChatGPT-4 Vision, or GPT-4V, signifies a noteworthy breakthrough in the field of artificial intelligence. With this improvement, the model can now process, comprehend, and produce visual content, making it a flexible tool suitable for various uses. The primary functions of ChatGPT-4 Vision, such as image analysis, video analysis, and image generation, will be covered in detail in this article, along with some examples of how these features could be used in different contexts.

Overview
- ChatGPT-4 Vision integrates visual capabilities with GPT-4, enabling image and video processing alongside text generation.
- Image analysis by ChatGPT-4 Vision includes object detection, classification, and scene understanding, offering accurate and efficient insights.
- Key features include object detection for automated tasks, image classification for various industries, and scene understanding for advanced applications.
- ChatGPT-4 Vision can generate images from text descriptions, providing innovative solutions for design, content creation, and more.
- Video analysis capabilities of ChatGPT-4 Vision include action recognition, motion detection, and event identification, enhancing various fields like security and sports analytics.
- Practical applications span healthcare diagnostics, retail visual search, security surveillance, and interactive learning, demonstrating ChatGPT-4 Vision’s versatility.
Table of contents
- Image Analysis
- Implementation of Image Analysis
- Image Analysis with Local Images
- Passing multiple images
- Image Generation
- Implementation of Image Generation
- Output
- Image variation of an existing image
- Output
- Video Analysis
- Implementation of Video Analysis
- Practical Applications of GPT-4 Vision
- Medical Care
- E-commerce and retail
- Frequently Asked Questions
Image Analysis
Extracting useful information from images is known as image analysis. It allows for the completion of tasks like object detection, image classification, and scene comprehension. With its sophisticated neural network architecture, ChatGPT-4 Vision is able to complete these tasks with a high degree of efficiency and accuracy.
Key Features
- Object Detection is the process of finding and identifying items in an image. Its uses include inventory management, driverless cars, and automated surveillance.
- Image classification: Classifying images into predetermined groups is known as image classification. This helps with disease identification in medical imaging, social media content moderation, and retail product classification.
- Understanding the scene: Examining the background and connections between the many elements in a picture can be beneficial for applications in robots, augmented reality, and virtual help.
Example Use Case
ChatGPT-4 Vision in a smart home security system may examine security camera footage to find anomalous activity or intruders. It can categorize things like people, pets, and cars and set off alarms according to pre-established security guidelines.
Implementation of Image Analysis
First, let’s install the necessary dependencies
!pip install openai
!pip install requestsImporting necessary libraries
import openai
import requests
import base64
from openai import OpenAI
from PIL import Image
from io import BytesIO
from IPython.display import displayImage Analysis with url
client = OpenAI(api_key='Enter your Key')
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Describe me this image"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
response.choices[0].message.contentIn the above code, we are passing the url of the image along with the prompt to describe the image in the url. Below is the image which we are passing.

Output

Image Analysis with Local Images
api_key = "Enter your key"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "/content/cat.jpeg"
# Getting the base64 string
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe me this image"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
In the above, we pass the image of the cat below, showing the mode to describe the image.

Output
print(response.json()["choices"][0]["message"]["content"])
Passing multiple images
from openai import OpenAI
client = OpenAI(api_key='Enter your Key')
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Tell me the difference and similarities of these two images",
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/3/3f/Walking_tiger_female.jpg/1920px-Walking_tiger_female.jpg",
},
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/7/73/Lion_waiting_in_Namibia.jpg",
},
},
],
}
],
max_tokens=300,
)
In the above code, we pass in multiple images using their URLs. Below are the images that we are passing.


We prompted the comparison of these two images to find their similarities and differences.
Output
print(response.choices[0].message.content)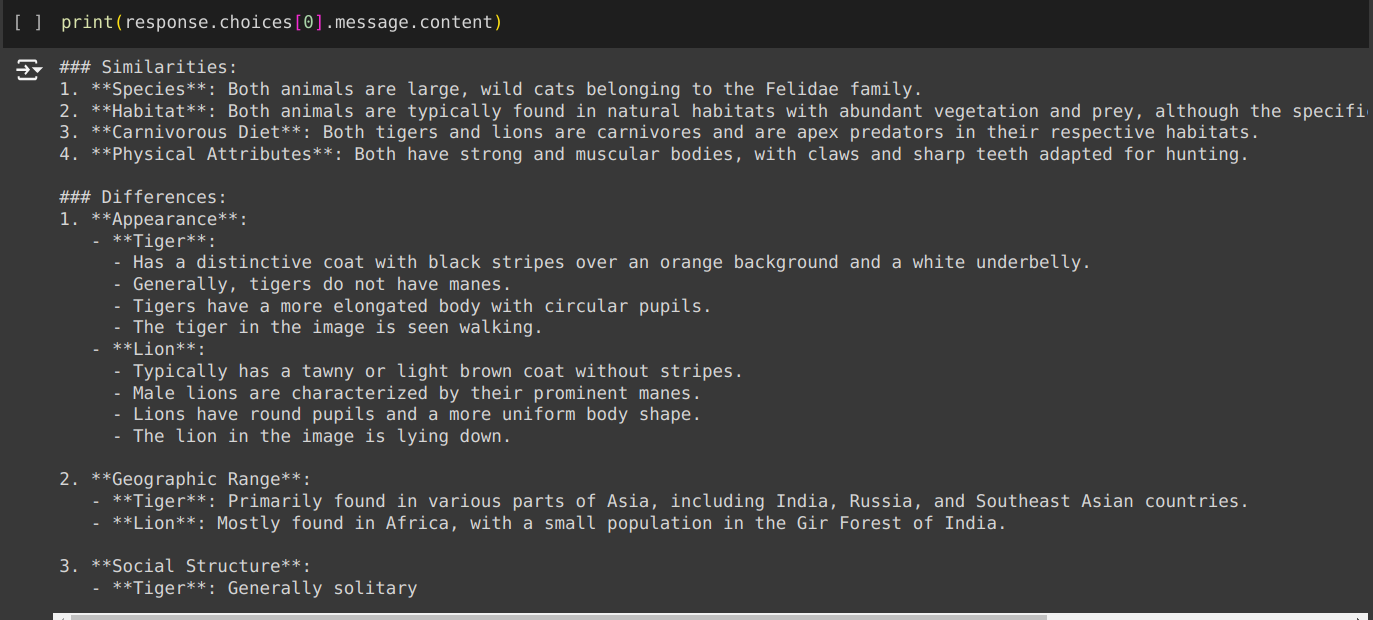
Image Generation
One of ChatGPT-4 Vision’s most intriguing features is its capacity to produce visuals from textual descriptions. This creates new opportunities for design, content production, and creative applications.
Key Features
- Text-to-Image Generation: the process of producing visuals from comprehensive written descriptions. This has applications in the entertainment, education, and advertising sectors.
- Style Transfer: Transferring an image’s style to another is known as style transfer. This helps create material on social networking, graphic design, and digital art.
- Image editing is the process of altering preexisting images in response to text instructions. It can improve activities involving manipulation, restoration, and photo editing.
Example Use Case
Designers in the fashion business can use ChatGPT-4 Vision to create visuals of garment designs from written descriptions. This can speed up the design process, enable virtual prototyping, and improve idea exchange.
Also read: Here’s How You Can Use GPT 4o API for Vision, Text, Image & More.
Implementation of Image Generation
The Images API provides three methods for interacting with images:
- Creating images from scratch based on a text prompt (DALL- E 3 and DALL – E 2)
- Creating variations of an existing image (DALL – E 2 only)
Creating Images using prompt
from openai import OpenAI
client = OpenAI(api_key='Enter your key')
response = client.images.generate(
model="dall-e-3",
prompt="a white siamese cat",
size="1024x1024",
quality="standard",
n=1,
)
image_url = response.data[0].url
We have prompted the DALL-E 3 mode to create a white Siamese cat image.
# Download the image
image_response = requests.get(image_url)
# Open the image using PIL
image = Image.open(BytesIO(image_response.content))
# Display the image
display(image)Output

Image variation of an existing image
from openai import OpenAI
client = OpenAI(api_key='Enter your key')
response = client.images.create_variation(
model="dall-e-2",
image=open("/content/spider_man.png", "rb"),
n=1,
size="1024x1024"
)
image_url = response.data[0].url
We are using DALL-E 2 to create a variation of the existing image. We are passing the below image to the API to create a variation.

# Download the image
image_response = requests.get(image_url)
# Open the image using PIL
image = Image.open(BytesIO(image_response.content))
# Display the image
display(image)Output

We can see that the model has created a variation of our image.
Video Analysis
Actionable insights can be extracted through the processing of video streams, expanding the scope of picture analysis into the temporal domain. Action identification, motion detection, and event detection in videos are among the functions that ChatGPT-4 Vision is capable of.
Key Features
- Action Recognition: Recognising particular movements made by participants in a video. This can be used in surveillance, human-computer interaction, and sports analytics.
- Motion detection: This can benefit animation, video surveillance, and traffic monitoring applications.
- Event detection: It is the process of locating important occurrences in a video. It can be applied in various fields, including security for incident detection, entertainment for automated highlight generation, and healthcare for patient activity monitoring.
Example Use case
ChatGPT-4 Vision can analyze game videos in sports analytics to identify player activities like basketball dribbling, shooting, and passing. This data can provide insights into player performance, game strategy, and training efficacy.
Also read: How to Use DALL-E 3 API for Image Generation?
Implementation of Video Analysis
import cv2
import base64
import requests
def encode_image(image):
_, buffer = cv2.imencode('.jpg', image)
return base64.b64encode(buffer).decode('utf-8')
def extract_frames(video_path, frame_interval=30):
cap = cv2.VideoCapture(video_path)
frames = []
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if frame_count % frame_interval == 0:
frames.append(frame)
frame_count += 1
cap.release()
return frames
def analyze_frame(frame, api_key):
base64_image = encode_image(frame)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe me this image"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
return response.json()
def analyze_video(video_path, api_key, frame_interval=30):
frames = extract_frames(video_path, frame_interval)
analysis_results = []
for frame in frames:
result = analyze_frame(frame, api_key)
analysis_results.append(result)
return analysis_results
# Path to your video
video_path = "/content/Kendall_Jenner.mp4"
api_key = "Enter your key"
# Analyze the video
results = analyze_video(video_path, api_key)
for result in results:
print(result['choices'][0]["message"]["content"])In the above code, we are taking a video of a celebrity doing a ramp walk; we are taking our frames at an interval of 30 and making an API call to know the description.
Output

Also read: Guide to Language Processing with GPT-4 in Artificial Intelligence
Practical Applications of GPT-4 Vision
Here are the applications of GPT-4 Vision:
Medical Care
In the medical field, GPT-4 Vision uses image analysis to help diagnose diseases, such as MRIs and X-rays. It can help medical practitioners make well-informed decisions by highlighting areas of concern and offering second viewpoints.
For instance
Medical imaging analysis identifies anomalies in X-rays, such as tumors or fractures, and gives radiologists comprehensive descriptions of these findings.
E-commerce and retail
GPT-4 Vision improves the shopping experience for both retail and online customers by offering thorough product descriptions and visual search features. Customers can upload photographs to locate related items or recommendations based on their visual preferences.
For instance
Visual Search: Enabling customers to contribute photographs in order to search for products, such as locating a dress that resembles one that a famous person has worn.
Automated Product Descriptions: Generating detailed product descriptions based on images, improving catalog management and user experience.
Conclusion
GPT-4 Vision is a revolutionary advancement in artificial intelligence that seamlessly combines natural language comprehension with visual analysis. Its applications are used in various sectors, including healthcare, retail, security, and education. They offer creative solutions and improve user experiences. Using sophisticated transformer topologies and multimodal learning, GPT-4 Vision creates new avenues for engaging with and comprehending the visual world.
Frequently Asked Questions
Q1. What is GPT-4 Vision?
Ans. GPT-4 Vision is an advanced AI model that integrates natural language processing with image and video analysis capabilities, allowing for detailed interpretation and generation of visual content.
Q2. What are the primary applications of GPT-4 Vision?
Ans. Key applications include healthcare (medical imaging analysis), retail (visual search and product descriptions), security (video surveillance and intrusion detection), and education (interactive learning and assignment evaluation).
Q3. How does GPT-4 Vision perform image analysis?
Ans. GPT-4 Vision identifies objects, scenes, and activities within images and generates detailed natural language descriptions of the visual content.
Q4. Can GPT-4 Vision analyze videos?
Ans. Yes, GPT-4 Vision can analyze sequences of frames in videos to identify actions, events, and changes over time, enhancing applications in security, entertainment, and more.
Q5. Is GPT-4 Vision capable of generating images?
Ans. Yes, GPT-4 Vision can generate images from textual descriptions, which is useful in creative design and prototyping applications.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.





