Introduction
Imagine a world where coding becomes as seamless as conversing with a friend, where complex programming tasks are tackled with just a few prompts. This is not science fiction—this is CodeLlama, the revolutionary tool leveraging Meta’s Llama 2 model to transform the way we write and understand code. In this article, we’ll delve into how CodeLlama can enhance your development process, making code generation, commenting, conversion, optimization, and debugging more efficient than ever before. Let’s explore how this powerful open-source model is reshaping the future of coding.

Learning Objectives
- Understand how CodeLlama enhances code generation and optimization.
- Learn to leverage CodeLlama for efficient code commenting and documentation.
- Explore methods for converting code between different programming languages using CodeLlama.
- Gain insights into using CodeLlama for advanced debugging and error resolution.
- Discover practical applications and use cases of CodeLlama in real-world development scenarios.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is CodeLlama?
- Performance of CodeLlama
- CodeLlama Capabilities
- Installing CodeLlama
- Understanding Code Generation
- Generating SQL Queries Using Database Schema
- Understanding Code Commenting
- Understanding Code Conversion
- Understanding Code Optimization
- Understanding Code Debugging
- Conclusion
- Frequently Asked Questions
What is CodeLlama?
CodeLlama represents an advanced framework that facilitates the generation and discussion of code, leveraging the capabilities of Llama 2 (open source large language model by Meta). It is a open-source model that uses prompts to generate code .This platform aims to streamline developer workflows, enhance efficiency, and simplify the learning process for developers. It helps to generate both code snippets and explanations in natural language related to programming. CodeLlama offers robust support for a wide array of contemporary programming languages such as Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash, among others.
The CodeLlama model was proposed in CodeLlama: Open Foundation Models for Code.
CodeLlama is a family of large language models for code, based on Llama 2, offering state-of-the-art performance, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. It comes in multiple flavors, including foundation models, Python specializations, and instruction-following models. All models are trained on 16k token sequences and show improvements on inputs with up to 100k tokens. CodeLlama reaches state-of-the-art performance on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively.

CodeLlama is a fine-tuned version of Llama 2 (an open- source model by Meta) and is available in three models:
- CodeLlama: foundation code model.
- CodeLlama Python: fine-tuned for Python.
- CodeLlama: Instruct, which is fine-tuned for understanding natural language instructions.
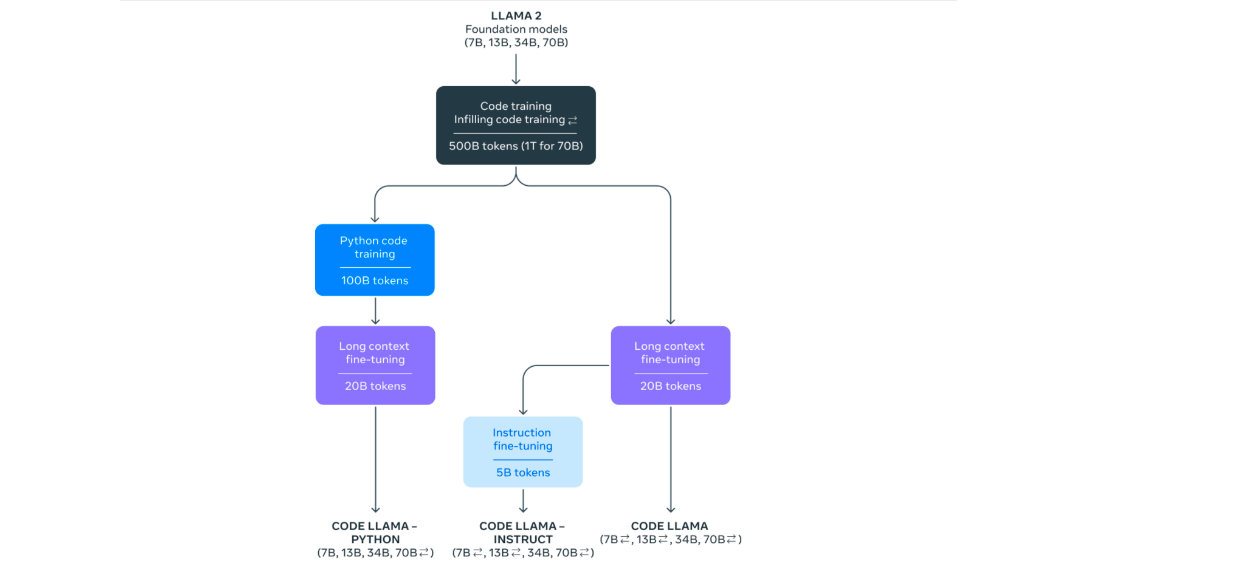
Performance of CodeLlama
CodeLlama has demonstrated state-of-the-art performance on several coding benchmarks, including HumanEval and Mostly Basic Python Programming (MBPP). It outperforms other publicly available models in code-specific tasks.
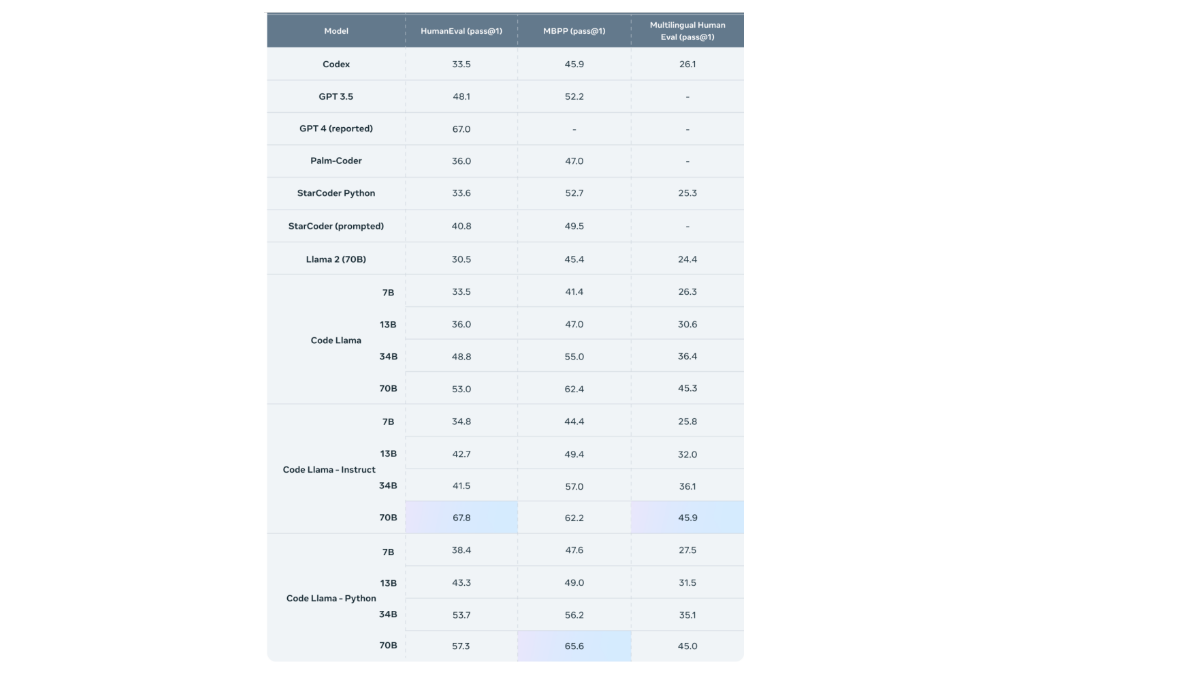
Source: Meta AI : https://ai.meta.com/blog/code-llama-large-language-model-coding/
CodeLlama Capabilities
- Code Generation: CodeLlama assists in generating code across various programming languages. Users can provide prompts in natural language to generate the desired code.
- Code Commenting: Commented code elucidates how your program functions and the intentions behind it. Comments themselves do not impact the execution of your program but are invaluable for individuals reading your code. CodeLlama facilitates the process of adding comments to code.
- Code Conversion: A developer uses multiple programming languages like Python, Pyspark, SQL etc and might sometimes want to convert a code to different programming language for e.g Python to Pyspark. CodeLlama can be used to convert the code efficiently and in no time.
- Code Optimization: Code optimization is a program transformation approach that aims to enhance code by reducing resource consumption (i.e., CPU and memory) while maintaining high performance. In code optimization, high-level generic programming structures are substituted with low-level programming codes. Use CodeLlama to write effective and optimized code.
- Code Debugging: As software developers, the code we write inevitably doesn’t always perform as anticipated—it can sometimes behave unexpectedly. When these unexpected situations arise, our next challenge is to determine why. While it might be tempting to spend hours scrutinizing our code, a more efficient approach is to use a debugging tool. CodeLlama aids developers in debugging their code effectively.
Here are examples that illustrate the installation process, how to provide prompts, and generate responses using CodeLlama in various categories. Code-Llama Instruct, excels in understanding and interpreting natural language queries, effectively discerning user expectations and providing relevant responses to prompts.
Installing CodeLlama
We have used “CodeLlama-7b-Instruct-hf” for the generating responses in the examples below:
Step1: Import the Required Libraries
!pip install -q transformers einops accelerate langchain bitsandbytesStep2: Login into Hugging Face
Generate a token on hugging face and put that token in the login to connect to hugging face.
!huggingface-cli loginStep3: Install Github Repo
Install the Github repo for installing it locally on the system you will have to:
!git clone https://huggingface.co/codellama/CodeLlama-7b-Instruct-hfStep4: Load the Model in the Memory
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
import transformers
import torch
model = "/content/CodeLlama-7b-Instruct-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)Understanding Code Generation
CodeLlama can generate code in various programming languages. Providing an appropriate prompt can yield effective and efficient code.
To use CodeLlama, we utilize a prompt template where we define the roles of the system and the user. Modify your question and assign it to the user to obtain the desired result. The pipeline takes the prompt as input along with different parameters for the large language model.
system = "Provide answers in python"
user = "create graph using pyneo library"
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
add_special_tokens=False
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")This query will produce Python code using the PyNeo library to generate a graph. The provided code includes instructions for importing necessary libraries and outlines various methods for graph creation. Additionally, the code includes explanations and comments to enhance user understanding of each component. The length of the output will vary depending on the number of tokens assigned in the pipeline.

Result:
To create a graph using PyNeo, you can use the `py2neo.create_graph()` function.
This function takes a dictionary of graph properties as an argument,
and returns a `Graph` object.
Here's an example of how you can use `py2neo.create_graph()` to create a graph:
```
import py2neo
# Create a graph
graph = py2neo.create_graph({
"name": "My Graph",
"description": "A graph created using PyNeo"
})
# Add nodes and edges to the graph
node1 = graph.create_node({"name": "Node 1"})
node2 = graph.create_node({"name": "Node 2"})
edge = graph.create_edge(node1, node2, {"label": "knows"})
# Print the graph
print(graph)
```
This will create a graph with two nodes and one edge, a
nd print the graph to the console.
You can also use the `py2neo.create_graph()` function to
create a graph from a file. For example:
```
import py2neo
# Create a graph from a file
graph = py2neo.create_graph("my_graph.json")
# Print the graph
print(graph)
```
This will create a graph from the JSON file `my_graph.json`,
and print the graph to the console.
You can also use the `py2neo.create_graph()`
function to create a graph from a string. For example:
```
import py2neo
# Create a graph from a string
graph = py2neo.create_graph("""
{
"name": "My Graph",
"description": "A graph created using PyNeo"
}
""")
# Print the graph
print(graph)
```
This will create a graph from the JSON string, and
print the graph to the console.
I hope this helps! Let me know if you have any questions.This example is to generate code in pyspark for connecting to azure and querying a folder.
system = "Provide answers in pyspark"
user = "Help me write pyspark code to connect with Azure adls account abc
and container pqr using a sas token to read file sales parquet from
container folder sales_data and get product wise sales for each month"
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
#inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
add_special_tokens=False
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
#import csvThis query will produce the following result: it imports the necessary libraries in PySpark, provides code to initiate the session, sets up the account and connects to it, and then performs a group-by operation to find sales per product per month.
Result:
```
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.appName("Azure ADLS").getOrCreate()
# Set the Azure ADLS account and container
account = "abc"
container = "pqr"
# Set the SAS token
sas_token = "your_sas_token"
# Create a DataFrame from the Azure ADLS account and container
df = spark.read.format("parquet") \
.option("path", f"abfss://{container}@{account}.dfs.core.windows.net/sales_data") \
.option("sasToken", sas_token) \
.load()
# Group the DataFrame by product and month
df_grouped = df.groupBy("product", "month")
# Calculate the total sales for each product and month
df_grouped.agg(F.sum("sales").alias("total_sales"))Generating SQL Queries Using Database Schema
Code-Llama is an excellent tool for turning natural language questions into accurate SQL statements. It outperforms even the best models, especially for tasks involving code and text-to-SQL conversions, which is the main focus of this article. Its user-friendly design makes generating SQL queries easy and seamless. In most cases, the query is executed on an existing database.
Below is the example where we give natural language prompt to generate SQL query with database schema.
The database schema can be provided in below format:
table1= """
CREATE TABLE customer
(
custid VARCHAR(6),
fname VARCHAR(30),
mname VARCHAR(30),
ltname VARCHAR(30),
city VARCHAR(15),
mobileno VARCHAR(10),
occupation VARCHAR(10),
dob DATE,
CONSTRAINT customer_custid_pk PRIMARY KEY(custid)
);
CREATE TABLE branch
(
bid VARCHAR(6),
bname VARCHAR(30),
bcity VARCHAR(30),
CONSTRAINT branch_bid_pk PRIMARY KEY(bid)
);
CREATE TABLE account
(
acnumber VARCHAR(6),
custid VARCHAR(6),
bid VARCHAR(6),
opening_balance INT(7),
aod DATE,
atype VARCHAR(10),
astatus VARCHAR(10),
CONSTRAINT account_acnumber_pk PRIMARY KEY(acnumber),
CONSTRAINT account_custid_fk FOREIGN KEY(custid) REFERENCES customer(custid),
CONSTRAINT account_bid_fk FOREIGN KEY(bid) REFERENCES branch(bid)
);
CREATE TABLE trandetails
(
tnumber VARCHAR(6),
acnumber VARCHAR(6),
dot DATE,
medium_of_transaction VARCHAR(20),
transaction_type VARCHAR(20),
transaction_amount INT(7),
CONSTRAINT trandetails_tnumber_pk PRIMARY KEY(tnumber),
CONSTRAINT trandetails_acnumber_fk FOREIGN KEY(acnumber) REFERENCES account(acnumber)
);
CREATE TABLE loan
(
custid VARCHAR(6),
bid VARCHAR(6),
loan_amount INT(7),
CONSTRAINT loan_customer_custid_bid_pk PRIMARY KEY(custid,bid),
CONSTRAINT loan_custid_fk FOREIGN KEY(custid) REFERENCES customer(custid),
CONSTRAINT loan_bid_fk FOREIGN KEY(bid) REFERENCES branch(bid)
);
"""The question in natural language can be asked in the below format:
question = 'Write a query to display account id, customer’s firstname, customer’s lastname for the customer’s whose account is Active.'
prompt = f"[INST] Write MYSQL query to answer the following question given the database schema.
Please wrap your code answer using ```: Schema: {table1} Question: {question} [/INST]
Here is the MYSQL query to answer to the question: {question}: ``` "
ans = pipeline(prompt, max_new_tokens=200)
print(ans[0]['generated_text'].split('```')[2])This query will result in :

SELECT account.acnumber, customer.fname, customer.ltname
FROM account
INNER JOIN customer ON account.custid = customer.custid
WHERE account.astatus = 'Active';Understanding Code Commenting
The codes can be commented using CodeLlama. Below are some examples of how to do it:
user = """please complete the code with comments
'''def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return 1'''
"""
prompt = f"<s>[INST] {user.strip()} [/INST]"
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
add_special_tokens=False
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
The query will result in code with comments (as shown below) and explains the code as well.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
Result: Here is the complete code with comments:
```
def fibonacci(n):
# Base case: If n is 0 or 1, return the value
if n == 0:
return 0
elif n == 1:
return 1
else:
# Recursive case: If n is greater than 1,
#return the sum of the previous two values
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
# Base case: If n is 0 or 1, return the value
if n == 0:
return 0
elif n == 1:
return 1
else:
# Check if the value is already in the memoization table
if n in memo:
return memo[n]
else:
# If not, calculate the value and add it to the memoization table
memo[n] = fibonacci(n-1) + fibonacci(n-2)
return memo[n]
```
The `fibonacci` function is the same as the one you provided,
but with comments added to explain what each line does.
The `fibonacci_memo` function is similar,
but it uses a memoization table to store the values of `fibonacci`
for previous inputs. This allows the function to avoid recalculating the
same values multiple times, which can make the function much faster for large inputs.
The `memo` dictionary is initialized to an empty dictionary,
and it is used to store the values of `fibonacci` for previous inputs.
The `if n in memo` statement checks if the value is already in the memoization
table, and if it is, the function returns the value from the table.
If the value is not in the table, the function calculates the value
and adds it to the table before returning it.Understanding Code Conversion
Here , we are converting binary search code in Python to Java:
system = "Provide answers in Java"
user = """convert the following python code to Java
'''
def binarySearch(array, x, low, high):
while low <= high:
mid = low + (high - low)//2
if array[mid] == x:
return mid
elif array[mid] < x:
low = mid + 1
else:
high = mid - 1
return -1
array = [3, 4, 5, 6, 7, 8, 9]
x = 4
result = binarySearch(array, x, 0, len(array)-1)
if result != -1:
print("Element is present at index " + str(result))
else:
print("Not found")
'''
"""
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
#inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2000,
add_special_tokens=False
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")This will result in :
Result: Here is the Java equivalent of the given Python code:
```
import java.util.Arrays;
public class BinarySearch {
public static int binarySearch(int[] array, int x, int low, int high) {
while (low <= high) {
int mid = low + (high - low) / 2;
if (array[mid] == x) {
return mid;
} else if (array[mid] < x) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
}
public static void main(String[] args) {
int[] array = {3, 4, 5, 6, 7, 8, 9};
int x = 4;
int result = binarySearch(array, x, 0, array.length - 1);
if (result!= -1) {
System.out.println("Element is present at index " + result);
} else {
System.out.println("Not found");
}
}
}
```
Note that in Java, the `Arrays.binarySearch()` method can be used instead of the custom implementation, which would simplify the code.
Understanding Code Optimization
system = "Provide answers in python"
user = """Please optimize the following code to reduce runtime
'''
input_list = [1, 2, -3]
output_list = []
for x in input_list:
if x >= 0:
output_list.append(1)
else:
output_list.append(0)
'''
"""
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
#inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2000,
add_special_tokens=False
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")This will use list comprehension instead of a for loop, providing an optimized version of the previous code.
Result: Here's a more efficient way to write the same code in Python:
```
output_list = [1 if x >= 0 else 0 for x in input_list]
```
This uses a list comprehension to create a new list with the same length as `input_list`, where each element is either 1 or 0 depending on whether the corresponding element in `input_list` is greater than or equal to 0.
This approach is more efficient because it avoids the need to iterate over the input list multiple times, and it also avoids the need to create and append elements to the output list. Instead, it creates the entire output list in one go, which can be much faster for large input lists.Understanding Code Debugging
system = "Please fix the code"
user = """I faced an error when I run my program using python: The error is like this:
ZeroDivisionError: division by zero
My codes looks like below
'''
x = 0
y = 0
z = x/y'''
how to avoid that error in python. My desired output is z = 0 and see the error and fix it
"""
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
#inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
sequences = pipeline(
prompt,
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2000,
add_special_tokens=False
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
This will result in the following result. Here it explains what the error is and then gives the code to rectify it.
Result:The error you are seeing is because you are trying to divide by zero,
which is not allowed in Python.
To fix this error, you can add a check to make sure that
`y` is not equal to zero before dividing.
Here is an example of how you can modify your code to avoid this error:
```
x = 0
y = 0
z = 0
if y!= 0:
z = x/y
else:
print("Error: division by zero")
```
This code will first check if `y` is equal to zero.
If it is, it will print an error message and set `z` to zero.
If `y` is not equal to zero, it will divide `x` by `y` and
set `z` to the result.
Alternatively, you can use the built-in `try` and `except` blocks to catch the error and handle it appropriately. Here is an example of how you can modify your code to use this approach:
```
x = 0
y = 0
z = 0
try:
z = x/y
except ZeroDivisionError:
print("Error: division by zero")
```
This code will try to divide `x` by `y` and set `z` to the result.
If an error occurs, it will catch the error and print an error message.
I hope this helps! Let me know if you have any questions.Conclusion
Through the release of CodeLlama, helps communities to do things more efficiently. The tailored CodeLlama is one stop solution for all coding needs and developers can benefit a lot from it.
Also, Developers should evaluate their models using code-specific evaluation benchmarks and perform safety studies on code-specific use cases. It should be used responsibly.
Key Takeaways
- CodeLlama enhances coding efficiency through advanced code generation and natural language processing.
- Also supports various programming languages and tasks, including code generation, commenting, conversion, and debugging.
- It outperforms other open models on coding benchmarks, demonstrating state-of-the-art performance.
- CodeLlama provides specialized models for general coding, Python, and instruction-following.
- It is open-source, facilitating both research and commercial applications with a permissive license.
Frequently Asked Questions
Q1. What is CodeLlama ?
A. CodeLlama is an advanced framework that leverages the Llama 2 large language model to generate and discuss code, enhancing developer workflows and efficiency.
Q2. What programming languages does CodeLlama support?
A. CodeLlama supports a wide array of contemporary programming languages, including Python, C++, Java, PHP, Typescript (JavaScript), C#, and Bash.
Q3. What are the main capabilities of CodeLlama?
A. CodeLlama can generate code, add comments, convert code between languages, optimize code, and assist in debugging.
Q4. What makes CodeLlama’s performance notable?
A. CodeLlama demonstrates state-of-the-art performance among open models on several coding benchmarks, including HumanEval and MBPP.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Shalu Tyagi
Analytical & process-oriented data scientist with strong mathematical and statistical background. Working in a banking organisation where i am involved in building OCR solutions, Syndicate fraud networks and fraud analytics. Experienced in Building advance Cognitive solutions for the extremely complex business process for Jio, Logistics, R&D and oil industries.
Skilled in Data Science, Machine Learning, Deep Learning and Optimization. Highly Proficient in OCR, Graph Theory, Predictive Analytics and Optimisation.
Currently Working in banking industry as a Senior Data Scientist and is actively involved in exploring new cutting-edge Ai technologies. My recent work revolves around LLMs, OCR and Graph Theory.







Excellent blog on coding and different capabilities of CodeLlama.
Great write up on CodeLlama. Enriching know how on a trending topic.
Great write up on CodeLlama. Enriching knowhow on a trending topic. Great work.