Introduction
Imagine that you are about to produce a Python package that has the potential to completely transform the way developers and data analysts assess their models. The trip begins with a straightforward concept: a flexible RAG evaluation tool that can manage a variety of metrics and edge circumstances. You’ll go from initializing your package with poetry to creating a solid evaluator class and testing your code as you dive into this post. You will get knowledge on how to create your package, calculate BLEU and ROUGE scores, and post it online. By the end, you will have gained more insight into Python packaging and open-source contributions in addition to having a working tool that is ready for usage by the general public.
Learning Outcomes
- Learn to initialize and structure a Python package using poetry.
- Develop and implement an evaluator class for multiple metrics.
- Calculate and evaluate metrics such as BLEU and ROUGE scores.
- Write and execute tests to ensure code functionality and robustness.
- Build and publish a Python package to PyPI, including handling distributions and licensing.
This article was published as a part of the Data Science Blogathon.
Table of contents
Initializing Your Package with Poetry
Now that we have the requirements we can start by initializing a new python package using poetry. The reason for choosing poetry is:
- It removes the need for managing multiple virtual environments.
- It supports all types of python package formats, both native and legacy packages.
- It ensures the right version even for the dependencies through the `poetry.lock` file.
- Pypi ready with a single command.
Install poetry using the command for almost all the OS:
curl -sSL https://install.python-poetry.org | python3 -Then we can create a new repository with the boilerplate using the following command.
poetry new package_nameThere will be few generic questions for which you can press the enter and leave it as default. Then you will land in a folder structure similar to this.
poetry-demo
├── pyproject.toml
├── README.md
├── poetry_demo
│ └── __init__.py
└── tests
└── __init__.pyThough the structure is just fine, we can use the `src` layout compared to the `flat` layout as discussed in the official Python documentation. We shall be following the `src` layout in the rest of the blog.
Designing the Core Evaluator Class
The heart of our package contains all the source code to power the Python evaluator package. It contains the base class that is going to be inherited by all the metrics that we wish to have. So this class has to be the most robust and utmost care must be taken during construction. This class will have the necessary logic needed for basic initialization, a method to get the result from the metric, and another method(s) for handling user input to be readily consumable.
All these methods must have their own scope and proper data types defined. The reason to focus more on the data types is because Python is dynamically typed. Hence, we must ensure the proper use of variables as these cause errors only at runtime. So there must be test suites to catch these minute errors, rather than using a dedicated type-checking compiler. Well and good if we use proper typing in Python.
Defining Evaluator Class
Now that we saw what all the evaluator class must contain and why it’s the most important we are left with the implementation of the same. For building this class we are inheriting the ABC – Abstract Base Class provided by python. The reason for choosing this class is that it contains all the concrete features upon which we can build our evaluator base class. Now let’s define the inputs and outputs of the evaluator class.
- Inputs: Candidates[list of string], References[list of string]
- Methods: `padding` (to ensure the length of candidates and references are the same), `get_score` (method to calculate the final result of the evaluation metrics)
# src/evaluator_blog/evaluator.py
import warnings
from typing import Union, List
from abc import ABC, abstractmethod
class BaseEvaluator(ABC):
def __init__(self, candidates: List, references: List) -> None:
self.candidates = candidates
self.references = references
@staticmethod
def padding(
candidates: List[str], references: List[str]
) -> Union[List[str], List[str]]:
"""_summary_
Args:
candidates (List[str]): The response generated from the LLM
references (List[str]): The response to be measured against
Returns:
Union[List[str], List[str]]: Ensures equal length of `candidates` and `references`
"""
_msg = str(
"""
The length of references and candidates (hypothesis) are not same.
"""
)
warnings.warn(_msg)
max_length = max(len(candidates), len(references))
candidates.extend([""] * (max_length - len(candidates)))
references.extend([""] * (max_length - len(references)))
return candidates, references
@staticmethod
def list_to_string(l: List) -> str:
assert (
len(l) >= 1
), "Ensure the length of the message is greater than or equal to 1"
return str(l[0])
@abstractmethod
def get_score(self) -> float:
"""
Method to calculate the final result of the score function.
Returns:
Floating point value of the chosen evaluation metric.
"""Here we can find that the `__init()__` method contains the parameters required that is the basic requirement for any evaluator metric i.e. candidates and references.
Then the padding required to ensure both the `candidates` and `references` contain the same length defined as the static method because we don’t need to initialize this everytime we call. Therefore, the staticmethod decorator contains the required logic.
Finally, for the `get_score()` we use abstractmethod decorator meaning all the classes that inherit the base evaluator class must definitely contain this method.
Implementing Evaluation Metrics
Now comes the heart of the implementation of the library, the evaluation of the metrics. Currently for the calculation we make use of respective libraries that perform the task and display the metric score. We mainly use `candidates` i.e. the LLM generated response and `references` i.e. the ground truth and we calculate the value respectively. For simplicity we calculate the BLEU and Rouge score. This logic is extensible to all the metrics available in the market.
Calculating BLEU Scores
Abbreviated as Bilingual Evaluation Understudy is one of the common evaluation metrics of machine translation(candidates) that is quick, inexpensive, and language-independent. It has marginal errors in comparison to manual evaluation. It compares the closeness of machine translation to the professional human responses(references) and returns the evaluation as a metric score in the range of 0-1, with anything towards 1 being termed as a close match. They consider n-gram(s) (chunks of n words) in a sentence from candidates. Eg. unigrams (1 gram) considers every word from candidates and references and return the normalized score termed as the precision score.
But it doesn’t always work well considering if the same word appears multiple times it accounts for the final score for each appearance which typically is incorrect. Therefore BLEU uses a modified precision score where it clips the number of word matches and normalizes it with the number of words in the candidate. Another catch here is it doesn’t take the word ordering into account. Therefore bleu score considers multiple n-grams and displays the precision scores of 1-4 grams with other parameters.
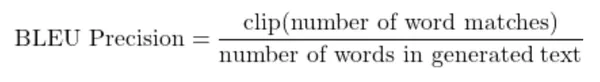

Advantages
- Faster computation and simple calculations involved.
- Widely used and easy to benchmark results.
Disadvantages
- Doesn’t consider the meaning of translation.
- Doesn’t take into account the sentence format.
- Though it is bilingual, it struggles with non-english languages.
- Hard to compute scores when human translations are already tokenized.
# src/evaluator_blog/metrics/bleu.py
from typing import List, Callable, Optional
from src.evaluator_blog.evaluator import BaseEvaluator
from nltk.translate.bleu_score import corpus_bleu, SmoothingFunction
"""
BLEU implementation from NLTK
"""
class BLEUScore(BaseEvaluator):
def __init__(
self,
candidates: List[str],
references: List[str],
weights: Optional[List[float]] = None,
smoothing_function: Optional[Callable] = None,
auto_reweigh: Optional[bool] = False,
) -> None:
"""
Calculate BLEU score (Bilingual Evaluation Understudy) from
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002.
"BLEU: a method for automatic evaluation of machine translation."
In Proceedings of ACL. https://aclanthology.org/P02-1040.pdf
Args:
weights (Optional[List[float]], optional): The weights that must be applied to each bleu_score. Defaults to None.
smoothing_function (Optional[Callable], optional): A callable function to overcome the problem of the sparsity of training data by adding or adjusting the probability mass distribution of words. Defaults to None.
auto_reweigh (Optional[bool], optional): Uniformly re-weighting based on maximum hypothesis lengths if largest order of n-grams < 4 and weights is set at default. Defaults to False.
"""
super().__init__(candidates, references)
# Check if `weights` is provided
if weights is None:
self.weights = [1, 0, 0, 0]
else:
self.weights = weights
# Check if `smoothing_function` is provided
# If `None` defaulted to method0
if smoothing_function is None:
self.smoothing_function = SmoothingFunction().method0
else:
self.smoothing_function = smoothing_function
# If `auto_reweigh` enable it
self.auto_reweigh = auto_reweigh
def get_score(
self,
) -> float:
"""
Calculate the BLEU score for the given candidates and references.
Args:
candidates (List[str]): List of candidate sentences
references (List[str]): List of reference sentences
weights (Optional[List[float]], optional): Weights for BLEU score calculation. Defaults to (1.0, 0, 0, 0)
smoothing_function (Optional[function]): Smoothing technique to for segment-level BLEU scores
Returns:
float: The calculated BLEU score.
"""
# Check if the length of candidates and references are equal
if len(self.candidates) != len(self.references):
self.candidates, self.references = self.padding(
self.candidates, self.references
)
# Calculate the BLEU score
return corpus_bleu(
list_of_references=self.references,
hypotheses=self.candidates,
weights=self.weights,
smoothing_function=self.smoothing_function,
auto_reweigh=self.auto_reweigh,
)Measuring ROUGE Scores
Abbreviated as Recall Oriented Understudy for Gisting Evaluation is one of the common evaluation metrics for comparing model-generated summaries with multiple human summaries. In a naive way, it compares the n-grams of both the machine and human-generated summary. This is called the Rouge-n recall score. To ensure more relevancy in machine generated summary to the human summary we can calculate the precision score. As we have both precision and recall scores we can calculate the f1-score. It’s normally recommended to consider multiple values of `n`. A small variant in rouge is the rouge-l score which considers the sequence of words and computes the LCS (longest common subsequence). In the same way, we can get the precision and recall score. A slight advantage here is it considers the molecularity of the sentence and produces relevant results.

Advantages
- Highly effective for evaluating the quality of automatic text summarization by comparing n-grams and longest common subsequences.
- ROUGE can be applied to any language, making it versatile for multilingual text analysis and evaluation.
Disadvantages
- ROUGE focuses on surface-level text matching (n-grams), which might not capture deeper semantic meaning and coherence.
- The accuracy of ROUGE heavily depends on the quality and representativeness of the reference summaries
# src/evaluator_blog/metrics/rouge.py
import warnings
from typing import List, Union, Dict, Callable, Tuple, Optional
from ..evaluator import BaseEvaluator
from rouge_score import rouge_scorer
class RougeScore(BaseEvaluator):
def __init__(
self,
candidates: List,
references: List,
rouge_types: Optional[Union[str, Tuple[str]]] = [
"rouge1",
"rouge2",
"rougeL",
"rougeLsum",
],
use_stemmer: Optional[bool] = False,
split_summaries: Optional[bool] = False,
tokenizer: Optional[Callable] = None,
) -> None:
super().__init__(candidates, references)
# Default `rouge_types` is all, else the user specified
if isinstance(rouge_types, str):
self.rouge_types = [rouge_types]
else:
self.rouge_types = rouge_types
# Enable `use_stemmer` to remove word suffixes to improve matching capability
self.use_stemmer = use_stemmer
# If enabled checks whether to add newlines between sentences for `rougeLsum`
self.split_summaries = split_summaries
# Enable `tokenizer` if user defined or else use the `rouge_scorer` default
# https://github.com/google-research/google-research/blob/master/rouge/rouge_scorer.py#L83
if tokenizer:
self.tokenizer = tokenizer
else:
self.tokenizer = None
_msg = str(
"""
Utilizing the default tokenizer
"""
)
warnings.warn(_msg)
def get_score(self) -> Dict:
"""
Returns:
Dict: JSON value of the evaluation for the corresponding metric
"""
scorer = rouge_scorer.RougeScorer(
rouge_types=self.rouge_types,
use_stemmer=self.use_stemmer,
tokenizer=self.tokenizer,
split_summaries=self.split_summaries,
)
return scorer.score(self.list_to_string(self.candidates), self.list_to_string(self.references))
Testing Your Package
Now that we have the source file ready before the actual usage we must verify the working of the code. That’s where the testing phase comes into the picture. In Python library format/convention/best practice, we write all the tests under the folder named `tests/`. This naming convention makes it easy for developers to understand that this folder has its significance. Though we have multiple development tools we can restrict the library using type checking, error handling, and much more. This caters to the first round of checking and testing. But to ensure edge cases and exceptions, we can use unittest, and pytest as the go-to frameworks. With that being said we just go with setting up the basic tests using the `unittest` library.
Writing Effective Unit Tests
The key terms to know with respect to `unittest` is the test case and test suite.
- Test case: Smallest unit of testing where we evaluate the inputs against a set of outputs.
- Test suite: A collection of test cases, suites or both. Used to aggregate tests to work together.
- Naming convention: This must be prefixed with `tests_` to the file name as well as the function name. The reason is the parser will detect them and add them to the test suite.
Build the wheel
Wheel is basically a python package i.e. installed when we run the command `pip install <package_name>`. The contents of the wheel are stored in the ‘.whl’ file. The wheel file is stored at `dist/`. There’s a built distribution `.whl` and the source distribution `.gz`. Since we are using poetry we can build the distribution using the build command:
poetry buildIt generates the wheel and zip file inside the `dist/` folder in the root of the folder.
dist/
├── package_name-0.0.1-py3-none-any.whl
└── package_name-0.0.1.tar.gz
Aliter, The equivalent python command is installing the `build` package and then running the build command from the root of the folder.
python3 -m pip install --upgrade build
python3 -m buildCreating Source and Binary Distributions
Let us now look in to creating source and binary distributions.
Source Distribution (sdist)
`sdist` is the source distribution of the package that contains source code and metadata to build from external tools like pip or poetry. `sdist` is required to be built before `bdist`. If `pip` doesn’t find the build distribution, the source distribution acts as a fallback. Then it builds a wheel out of it and then installs the package requirements.
Binary Distribution (bdist)
`bdist` contains the necessary files that need to be moved to the correct location of the target device. One of the best-supported formats is `.whl`. Point to be noted it doesn’t have compiled python files.
License
While open-sourcing the package to the external world it’s always advisable to have a license that shows the extent to which your code can be reused. While creating a repository in GitHub we have the option to select the license there. It creates a `LICENSE` file with usage options. If you are unsure which license to choose then this external resource is a perfect one to the rescue.

Publish the Package
Now that we have all the requirements we need to publish the package to the external world. So we are using the publish command which abstracts all the steps with a single command.
test.pypi.org
If you are unsure how the package would perform or for testing purposes it is advised to publish to a test.pypi.org rather than directly uploading to the official repository. This gives us the flexibility to test the package before sharing it with everyone.
pypi.org
The official Python package contains all the private and public software published by the Python community. It’s useful for authors and organizations to share their packages through an official central repository. All that it takes to publish your package to the world is this single command.
poetry publish --build --username $PYPI_USERNAME --password $PYPI_PASSWORDConclusion
By the end of this article, you have successfully published a Python package that is ready to be used by millions. We have initialized a new package using poetry, worked on the use case, wrote the tests, built the package, and published them to the Pypi repository. This will add more value for yourself and also help you to understand the various open-source Python package repositories on how they are structured. Last but not least, this is just the beginning and we can make it as extensible as possible. We can refer to the open-source Python packages and distributions, and get inspiration from the same.
Key Takeaways
- Master Python package creation and management with poetry.
- Implement and customize evaluation metrics for diverse use cases.
- Build and test robust Python packages with unit testing frameworks.
- Publish your package to PyPI and understand distribution formats.
- Gain insights into open-source package development and licensing practices.
Frequently Asked Questions
Q1. What is the purpose of this article?
A. The article helps you create and publish a Python package, focusing on a RAG evaluator tool that can be used by the community for various evaluation metrics.
Q2. Why should I use poetry for managing my Python package?
A. Poetry simplifies dependency management and packaging by integrating version control, virtual environments, and publishing tasks into a single tool, making development and distribution easier.
Q3. What evaluation metrics are covered in the article?
A. The article details how to calculate BLEU and ROUGE scores, which are commonly used metrics for assessing the quality of machine-generated text in comparison to reference texts.
Q4. How can I test the functionality of my Python package?
A. You can test your package using frameworks like unittest or pytest to ensure the code works as expected and handles edge cases, providing confidence before publishing.
Q5. What are the steps for publishing a Python package?
A. Build your package using poetry or build, test it on test.pypi.org, and then publish it to the official pypi.org repository using the poetry publish command to make it available to the public.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A seasoned software and ML developer with likes to share knowledge on the latest skills, frameworks, and technologies. Writes about Data Science and Machine learning and love to build and ship projects.


