Introduction
Meta AI (formerly Facebook AI) has introduced a revolutionary AI model called SAM (Segment Anything Model), representing a significant leap forward in computer vision and image segmentation technology. This article explores SAM’s features, capabilities, potential applications, and implications for various industries.

Overview
- Meta AI’s Segment Anything Model (SAM) offers groundbreaking flexibility in image segmentation based on user prompts.
- SAM excels in identifying and segmenting objects across diverse contexts without additional training.
- The Segment Anything Dataset (SA-1B) is the largest of its kind, designed to foster extensive applications and research.
- SAM’s architecture integrates an image encoder, prompt encoder, and mask decoder for real-time interactive performance.
- Future uses of SAM span AR, medical imaging, autonomous vehicles, and more, democratizing advanced computer vision.
Table of contents
- What is SAM?
- Key Components of the Segment Anything Project
- Historical Context of Segmentation Approaches
- How Does SAM Works? [Promptable Segmentation]
- The Research on this Model
- Segment Anything Project
- Segment Anything Data Engine
- Segment Anything Dataset (SA-1B)
- Future Implications of SAM: A Vision for Advanced AI Applications
- Frequently Asked Questions
What is SAM?
SAM, or Segment Anything Model, is an AI model developed by Meta AI that can identify and outline any object in an image or video based on user prompts. It’s designed to be flexible, efficient, and capable of generalizing to new objects and situations without additional training.
The Vision of Segment Anything at its core, the Segment Anything project seeks to break down barriers that have traditionally limited the accessibility and applicability of advanced image segmentation techniques. By reducing the need for task-specific modeling expertise, extensive computational resources, and custom data annotation, Meta AI is paving the way for a more inclusive and versatile approach to computer vision.
Key Components of the Segment Anything Project
Here’s the key component of SAM:
- Segment Anything Model (SAM) is a foundation model for image segmentation, designed to be promptable and adaptable to a wide range of tasks. Its key features include:
- Generalizability: SAM can identify and segment objects not encountered during training, demonstrating remarkable zero-shot transfer capabilities.
- Versatility: The model can generate masks for any object in images or videos, regardless of the domain or context.
- Promptability: Users can guide SAM using various types of prompts, making it highly flexible and user-friendly.
- Segment Anything 1-Billion mask dataset (SA-1B) Alongside SAM, Meta AI is releasing the SA-1B dataset, which is:
- The largest segmentation dataset ever created
- Designed to enable a broad set of applications
- Intended to foster further research into foundation models for computer vision
- Open Access Meta AI is making both SAM and the SA-1B dataset available to the research community:
- The SA-1B dataset is available for research purposes
- SAM is released under the permissive Apache 2.0 open license
Historical Context of Segmentation Approaches
To understand the significance of SAM, it’s crucial to examine the historical context of segmentation approaches:
Traditional Segmentation Approaches
- Interactive Segmentation:
- Could segment any class of object.
- Required manual guidance and iterative refinement.
- Time-consuming and labor-intensive.
- Automatic Segmentation:
- Allowed for automatic segmentation of predefined object categories.
- Required substantial manually annotated training data (thousands of examples).
- Needed significant computing resources and technical expertise.
- Limited to specific, pre-trained object categories.
SAM’s Unified and Flexible Approach
SAM transcends the limitations of both interactive and automatic segmentation by offering:
- Versatility: A single model capable of both interactive and automatic segmentation.
- Promptable Interface: It allows for flexible use across various segmentation tasks through engineered prompts (clicks, boxes, text, etc.).computer vision applications
- Generalization Capabilities:
- Trained on a diverse dataset of over 1 billion masks
- Can generalize to new object types and images beyond its training data
- Eliminates the need for task-specific data collection and model fine-tuning in most cases
Key Advantages of SAM’s Approach
Here are the advantages:
- Task Generalization: SAM can adapt to various segmentation tasks without retraining or fine-tuning.
- Domain Generalization: The model can effectively segment objects in new domains or image types not encountered during training.
- Reduced Barriers: Practitioners can now tackle complex segmentation tasks without requiring extensive datasets or specialized model training.
- Flexibility: SAM’s promptable interface allows for creative problem-solving in various segmentation scenarios.
Implications for the Field
SAM’s generalized approach to segmentation has far-reaching implications:
- Democratization: Makes advanced segmentation capabilities accessible to a broader range of users and applications.
- Innovation Catalyst: Enables rapid prototyping and development of new computer vision applications.
- Research Opportunities: Opens new avenues for exploring foundation models in computer vision.
- Interdisciplinary Applications: Facilitates the adoption of advanced segmentation techniques in diverse fields, from medical imaging to environmental monitoring.
How Does SAM Works? [Promptable Segmentation]
SAM’s innovative approach to segmentation is rooted in promptable AI, drawing inspiration from recent advancements in natural language processing and computer vision:
Foundation Model Approach
SAM is designed as a foundation model capable of zero-shot and few-shot learning for new datasets and tasks, similar to large language models in NLP. This approach allows SAM to adapt to various segmentation tasks without extensive retraining.
Prompt-Based Segmentation
SAM is trained to return a valid segmentation mask for any prompt. Prompts can be foreground/background points, a rough box or mask, freeform text, or any information indicating what to segment in an image. Even when a prompt is ambiguous and could refer to multiple objects, the output is a reasonable mask for one of those objects.
Model Architecture and Constraints
SAM’s design is optimized for real-time performance and broad accessibility. It’s designed to run in real-time on a CPU in a web browser, enabling interactive use by annotators for efficient data collection. The model balances segmentation quality with runtime performance, yielding effective results in practice.
Technical Components
SAM’s architecture consists of an image encoder, a prompt encoder, and a mask decoder. The image encoder produces a one-time embedding for the input image. The lightweight prompt encoder converts any prompt into an embedding vector in real-time. The mask decoder combines these embeddings to predict segmentation masks.
Performance Metrics
After the initial image embedding computation, SAM can produce a segment in just 50 milliseconds for any given prompt, operating within a web browser environment.
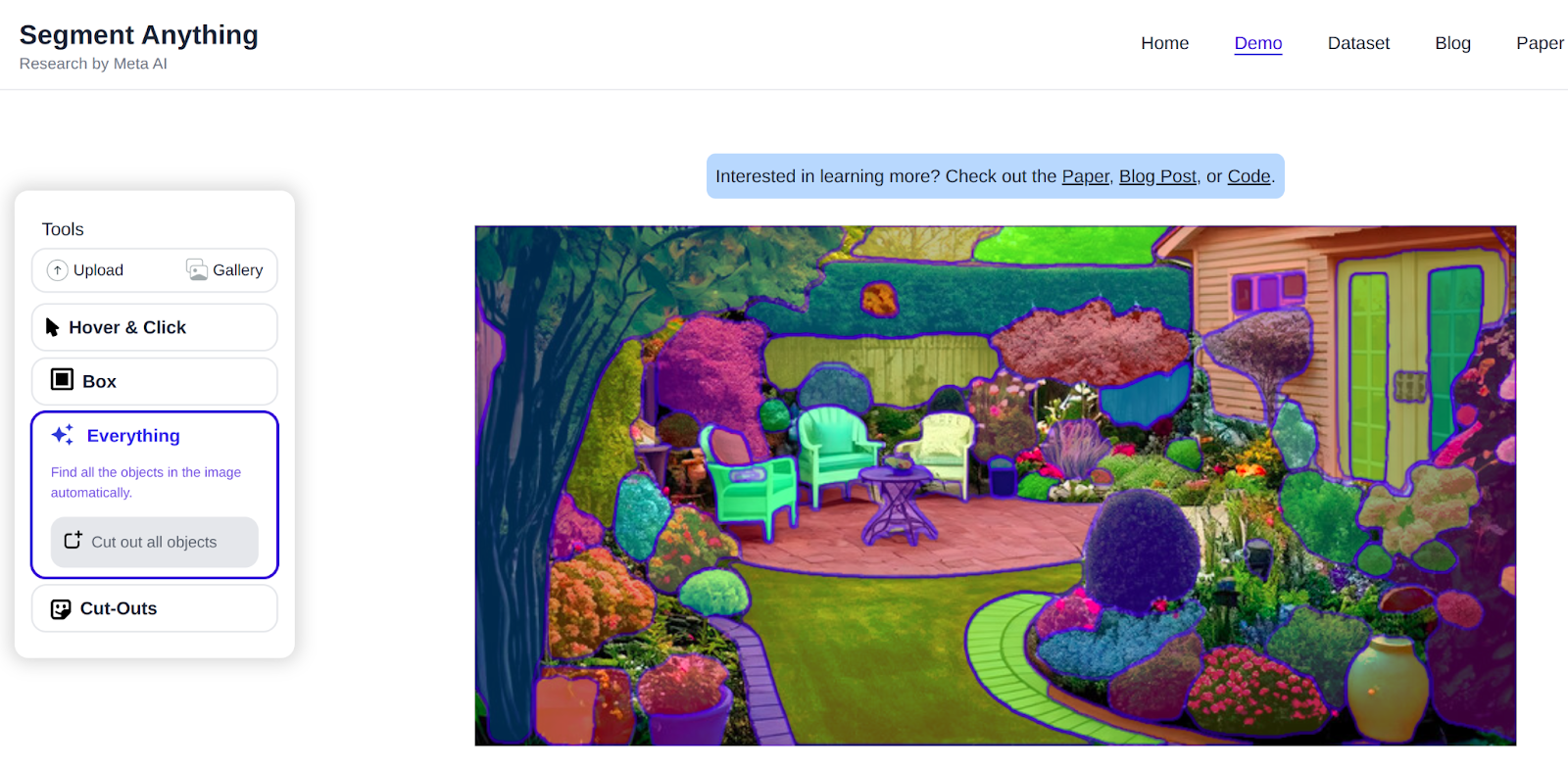
Here is an example of implementation of the SAM model on a given picture, You can simply hover and segment objects, or box out everything.
Input Image
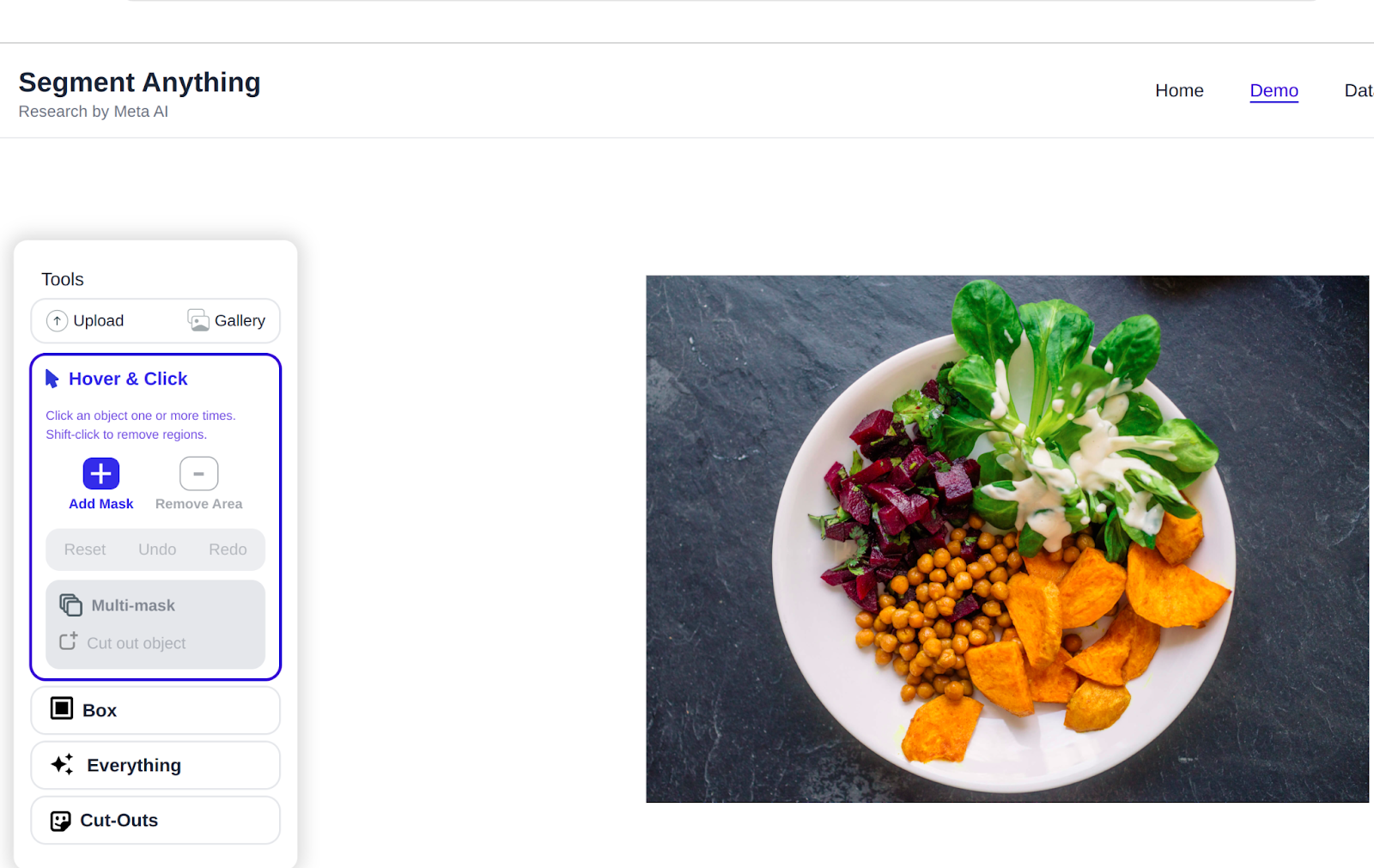
Output:
Here, you can check out the demo yourself for a given image.
There are multiple options provided UI to check out the features provided by the segmentation model,
You can upload a picture or choose one from their gallery of images.
Here, we uploaded a picture

After uploading a picture,
You will find many options to play with the model, you can start by hovering and clicking on any object to see how precisely it segments.
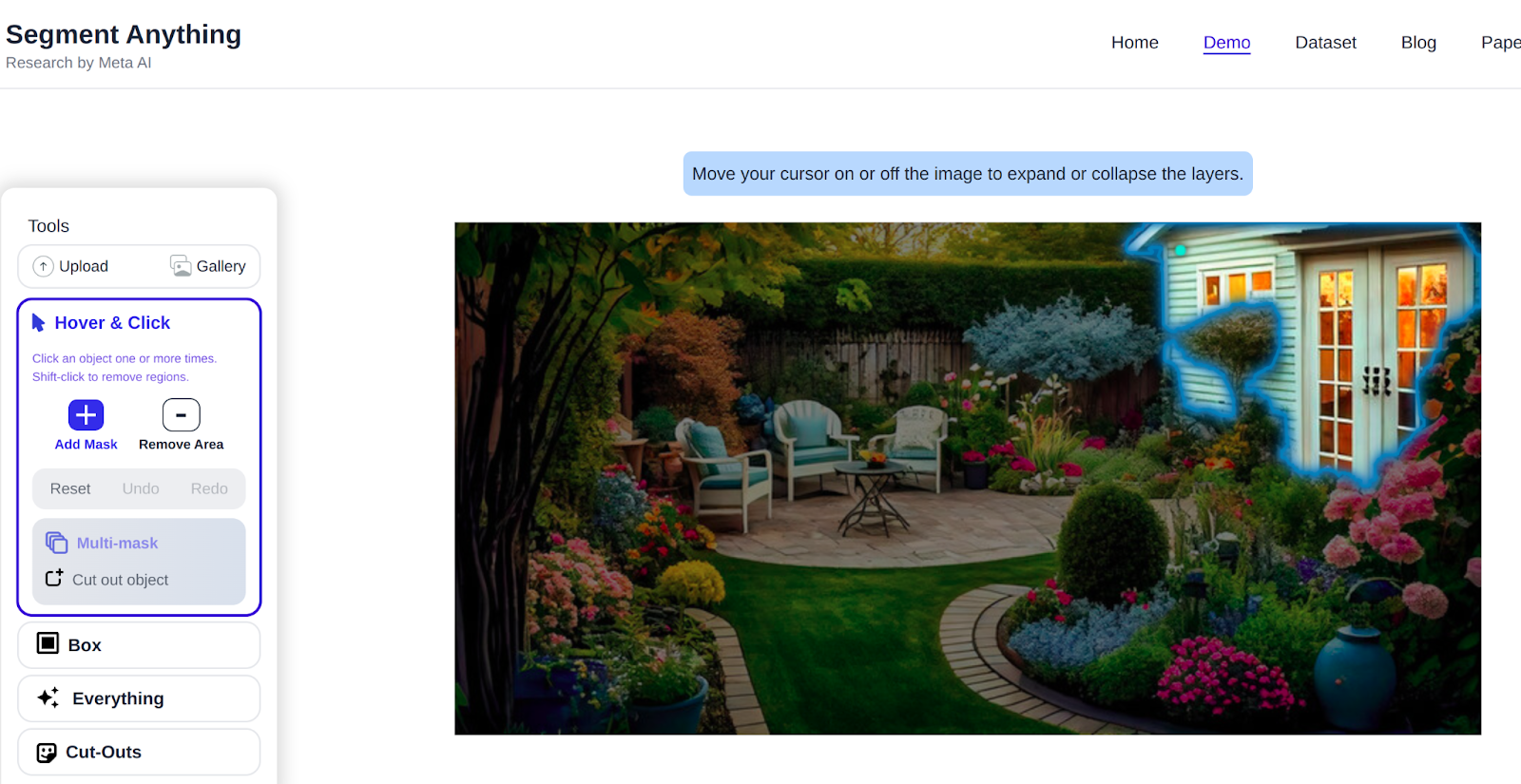
Then Next you can box any object in the picture, Using your mouse cursor, you drag a ractangular box in the picture to segment object and then keep the cut outs as well.

In the Cut Outs options, you can find your cutouts:

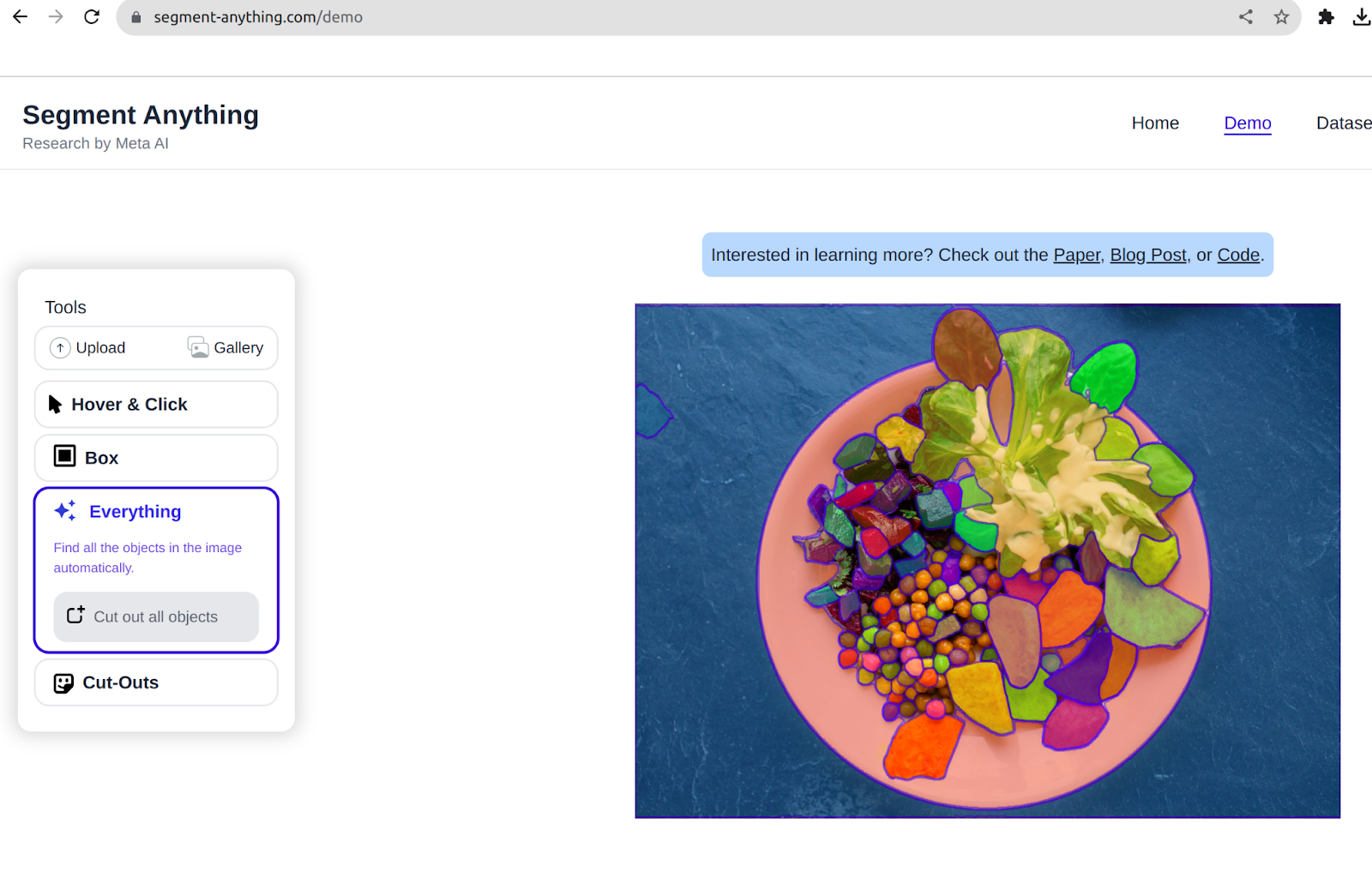
Or you can click on everything to check out each object well-segmented:
Also read: Introduction to Image Segmentation
The Research on this Model
The Segment Anything project introduces a new task, model, and dataset for image segmentation. The key components are:
- Task: Promptable segmentation, where the model returns a valid segmentation mask for any given prompt (e.g., points, boxes, text) indicating what to segment in an image.
- Model: The Segment Anything Model (SAM) is designed to be promptable and efficient. It consists of an image encoder, a prompt encoder, and a mask decoder, and it can generate masks in real-time (∼50ms) in a web browser.
- Dataset: SA-1B, the largest segmentation dataset to date, contains over 1 billion masks on 11 million licensed and privacy-respecting images.
The researchers developed a “data engine” to create this massive dataset, involving assisted-manual, semi-automatic, and fully automatic annotation stages.
SAM demonstrates impressive zero-shot performance on various tasks, often competitive with or superior to prior fully supervised results. The model can generalize to new image distributions and tasks without additional training.
The paper also addresses responsible AI concerns, studying potential fairness issues and biases in the model and dataset.
The researchers are releasing both SAM and SA-1B to foster further research into foundation models for computer vision. They evaluate SAM on numerous tasks, including edge detection, object proposal generation, and instance segmentation, showcasing its versatility and effectiveness in zero-shot transfer scenarios
Also Read: Deep Learning for Image Segmentation with TensorFlow
Segment Anything Project
The Segment Anything project introduces a new task, model, and dataset for image segmentation. Key components include:
- Task: Promptable segmentation, inspired by next token prediction in NLP. The model returns a valid segmentation mask for any given prompt (e.g., points, boxes, text, masks), indicating what to segment in an image, even when prompts are ambiguous.
- Model: The Segment Anything Model (SAM) consists of:
- An image encoder (pre-trained Vision Transformer)
- A flexible prompt encoder for sparse and dense prompts
- A fast mask decoder
SAM can generate multiple output masks for ambiguous prompts and predicts confidence scores for each mask. It’s designed for efficiency, with the prompt encoder and mask decoder running in a web browser on CPU in ~50ms.

- Pre-training: SAM is trained using a simulated sequence of prompts for each sample, comparing predictions against ground truth.
- Zero-shot transfer: The model can adapt to various segmentation tasks through prompt engineering without additional training.
- Efficiency and real-time performance: SAM’s design allows for real-time interactive prompting, making it suitable for various applications and integration into larger systems.
- Training: The model is trained using a combination of focal loss and dice loss, with a simulated interactive setup using randomly sampled prompts in multiple rounds per mask.
The researchers emphasize the power of prompting and composition in enabling a single model to accomplish a wide range of tasks, potentially even those unknown at the time of model design. This approach is compared to other foundation models like CLIP and its role in the DALL·E image generation system.
Segment Anything Data Engine
Segment Anything Data Engine, which was used to create the SA-1B dataset containing 1.1 billion masks. The data engine operated in three stages:
Assisted-manual Stage
- Professional annotators used a browser-based tool powered by SAM to label masks interactively.
- Annotators labeled both “stuff” and “things” without semantic constraints.
- SAM was retrained 6 times as more data was collected, improving efficiency.
- 4.3M masks were collected from 120k images.
- Annotation time decreased from 34 to 14 seconds per mask.
Semi-automatic stage
- Aimed to increase mask diversity.
- A bounding box detector was used to detect confident masks automatically.
- Annotators focused on labeling additional unannotated objects.
- 5.9M additional masks were collected from 180k images.
- The model was retrained 5 times during this stage.
- The average number of masks per image increased from 44 to 72.
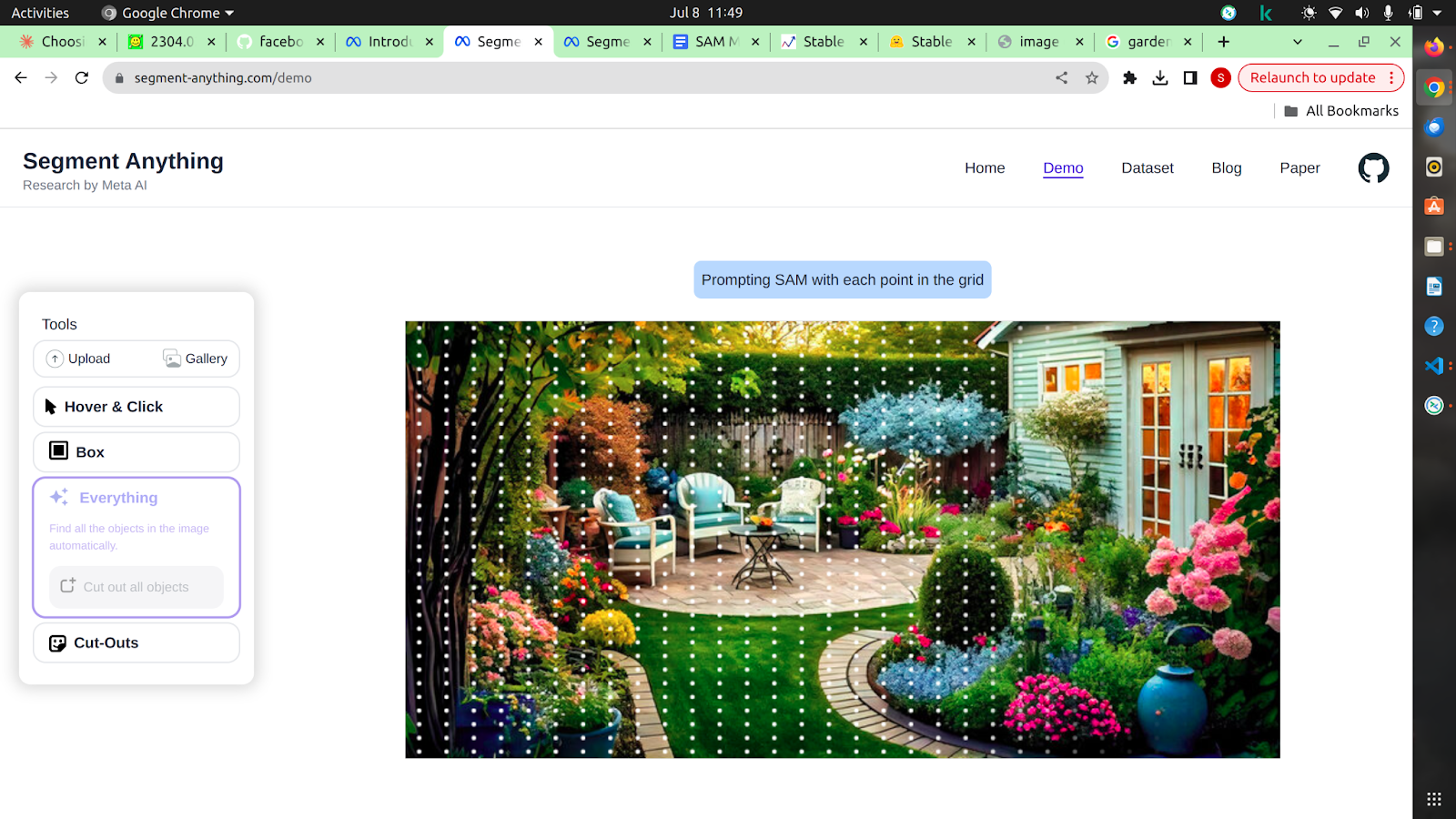
Fully automatic stage
- Annotation became fully automatic due to model improvements.
- An ambiguity-aware model was used to predict valid masks for ambiguous cases.
- Prompted the model with a 32×32 regular grid of points.
- Selected confident and stable masks, then applied non-maximal suppression.
- Processed multiple overlapping zoomed-in image crops for smaller masks.
- Applied to all 11M images in the dataset, producing 1.1B high-quality masks.
This data engine approach allowed the researchers to create a massive, diverse dataset of segmentation masks, which was crucial for training the highly capable Segment Anything Model (SAM).
Also Read: Semantic Segmentation: Introduction to the Deep Learning Technique Behind Google Pixel’s Camera!
Segment Anything Dataset (SA-1B)
The SA-1B dataset consists of 11 million diverse, high-resolution, licensed, and privacy-protecting images with 1.1 billion high-quality segmentation masks. Key features include:
Images
- 11 million licensed images
- High resolution (3300×4950 pixels on average)
- Downsampled to 1500 pixels on the shortest side for release
- Faces and vehicle license plates blurred
Masks
- 1.1 billion masks, 99.1% generated automatically
- High quality: 94% of masks have over 90% IoU with professionally corrected versions
- Only automatically generated masks are included in the final dataset
Comparison to existing datasets
- SA-1B has 11 times more images and 400 times more masks than the largest existing segmentation dataset
- Greater coverage of image corners compared to other datasets
- More small and medium-sized masks per image
Geographic distribution
- Images from most countries worldwide
- The three countries with the most images are from different parts of the world
The researchers hope that SA-1B will support their own work and serve as a valuable resource for the broader computer vision research community, fostering new developments in foundation models and dataset creation.
Future Implications of SAM: A Vision for Advanced AI Applications
The advent of SAM, facilitated by SA-1B, has revolutionized research and opened doors for further advancements in image segmentation. This foundational technology allows other researchers to train models for diverse applications, fostering the development of new datasets with enhanced annotations, including text descriptions associated with each mask.
Also Read: Image Segmentation Algorithms With Implementation in Python – An Intuitive Guide
What Lies Ahead?
Looking towards the future, SAM holds the potential to identify everyday items via AR glasses, providing users with real-time reminders and instructions. Its applications span a wide range of domains, from aiding farmers in agriculture to assisting biologists in their research. By sharing their research and datasets, the creators aim to accelerate advancements in segmentation and broader image and video understanding. The promptable segmentation model, acting as a component in larger systems, showcases the power of composability — enabling a single model to perform various tasks, including those unforeseen at the time of its design.
The integration of SAM into composable systems, enhanced by prompt engineering, paves the way for diverse applications across AR/VR, content creation, scientific research, and general AI systems. Researchers foresee a closer integration between pixel-level image and higher-level semantic understanding, unlocking even more powerful AI capabilities.
Applications of SAM
- Image and Video Editing: Simplifying object selection and manipulation in photo and video editing software.
- Augmented Reality: Enhancing AR experiences by accurately identifying and interacting with real-world objects.
- Medical Imaging: Assisting in analyzing medical scans by precisely outlining organs, tumors, or other structures.
- Autonomous Vehicles: Improving object detection and scene understanding for self-driving cars.
- Robotics: Enhancing robots’ ability to identify and interact with objects in their environment.
- Content Moderation: Automating identifying and flagging inappropriate content in images and videos.
- E-commerce: Streamlining product cataloging and visual search capabilities.
Implications and Challenges
- Democratization of AI: SAM’s versatility could make advanced computer vision capabilities more accessible to a wider range of users and applications.
- Ethical Considerations: As with any powerful AI tool, there are concerns about potential misuse, such as in surveillance or deepfake creation.
- Data Privacy: The model’s ability to identify and segment objects raises questions about personal privacy in images and videos.
- Integration Challenges: Incorporating SAM into existing workflows and systems may require significant adaptation and training.
Future Developments Meta AI continues to refine and expand SAM’s capabilities. Future developments may include:
- Improved real-time performance for video applications
- Enhanced multimodal capabilities, incorporating audio and text understanding
- More sophisticated zero-shot learning abilities
- Integration with other AI models for more complex tasks
Conclusion
SAM represents a significant advancement in computer vision and AI technology. Its ability to segment anything in images and videos with high accuracy and flexibility opens up numerous possibilities across various industries. As technology evolves, we can expect increasingly sophisticated applications that leverage SAM’s capabilities to solve complex visual understanding problems.
While challenges remain, particularly regarding ethical use and integration, SAM’s potential to transform how we interact with and analyze visual data is undeniable. As researchers, developers, and industries continue exploring its capabilities, SAM will likely play a crucial role in shaping the future of AI-powered visual understanding.
Frequently Asked Questions
Q1. What is the Segment Anything Model (SAM)?
Ans. SAM is a foundation model for image segmentation developed by Meta AI. It’s designed to segment any object in an image based on various types of prompts, such as points, boxes, or text descriptions.
Q2. How does SAM differ from traditional segmentation methods?
Ans. Unlike traditional methods that are often task-specific, SAM is a versatile model that can segment virtually any object without retraining. It uses a prompt-based interface and can generalize to unseen objects and scenarios.
Q3. What types of inputs can SAM work with?
Ans. SAM can work with different types of prompts:
A. Point prompts (clicking on an object)
B. Box prompts (drawing a bounding box around an object)
C. Text prompts (describing the object to be segmented)
Q4. What are the potential applications of SAM?
Ans. SAM has a wide range of potential applications, including:
A. Medical imaging for organ or anomaly segmentation
B. Autonomous vehicle systems for object detection
C. Augmented reality for accurate object integration
D. Content creation and editing in photography and videography
E. Scientific research for analyzing complex visual data
With 4 years of experience in model development and deployment, I excel in optimizing machine learning operations. I specialize in containerization with Docker and Kubernetes, enhancing inference through techniques like quantization and pruning. I am proficient in scalable model deployment, leveraging monitoring tools such as Prometheus, Grafana, and the ELK stack for performance tracking and anomaly detection.
My skills include setting up robust data pipelines using Apache Airflow and ensuring data quality with stringent validation checks. I am experienced in establishing CI/CD pipelines with Jenkins and GitHub Actions, and I manage model versioning using MLflow and DVC.
Committed to data security and compliance, I ensure adherence to regulations like GDPR and CCPA. My expertise extends to performance tuning, optimizing hardware utilization for GPUs and TPUs. I actively engage with the LLMOps community, staying abreast of the latest advancements to continually improve large language model deployments. My goal is to drive operational efficiency and scalability in AI systems.




