Introduction
We have already discussed that Python is the most powerful programming language, especially in data science and Gen-AI. When working with voluminous data, it is really important to understand how to manipulate (store, manage, and access) it efficiently.
We’ve also explored numbers and strings and how they are stored in memory before, which you can find here. In this part, we’ll dive deep into the versatility of Python’s Built-in Data Structures and understand the difference between Mutable and Immutable Objects.

Overview
- Python’s Power: Python is a versatile programming language, especially for data science and Gen-AI.
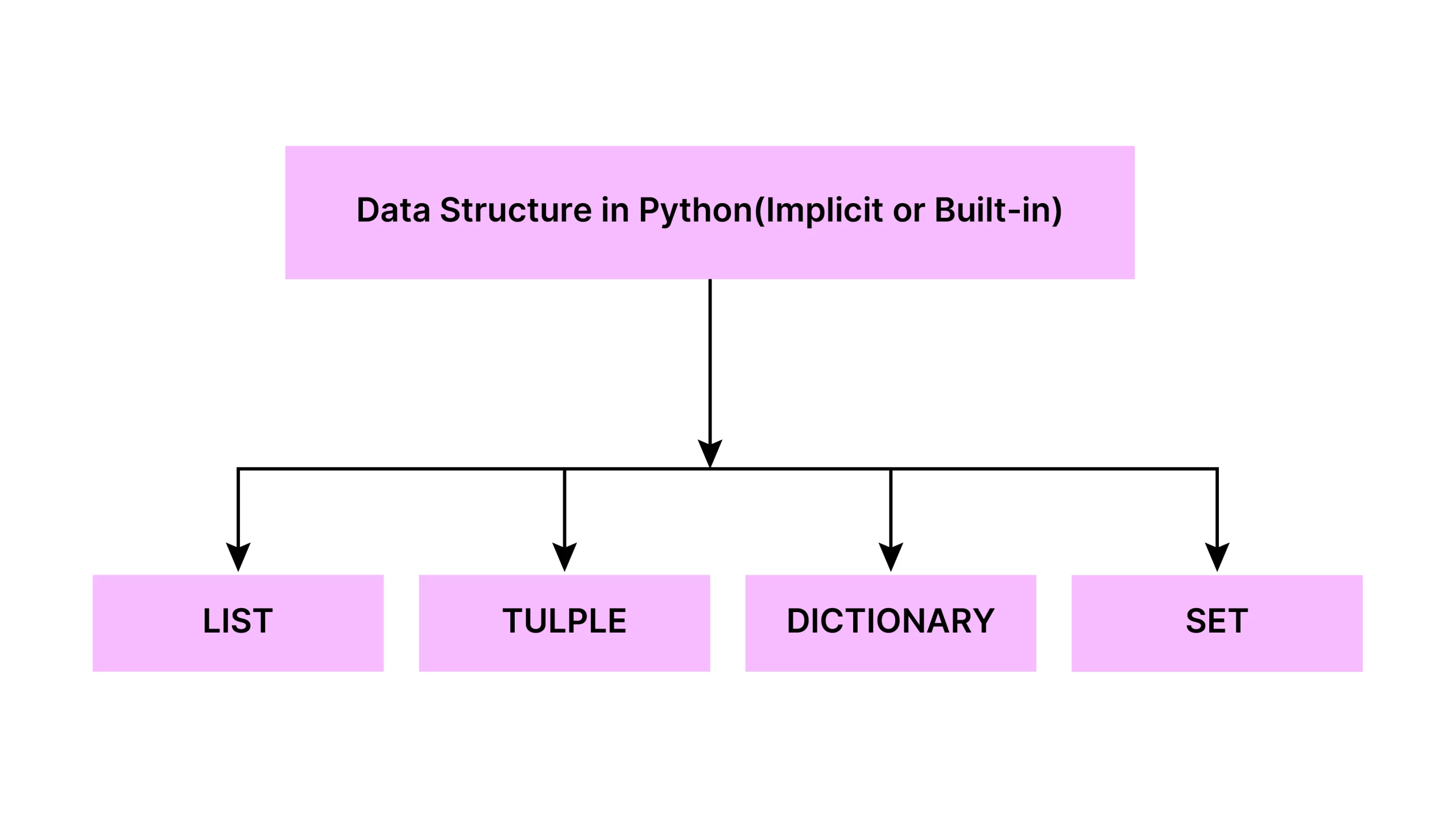
- Data Structures Overview: This section discusses built-in data structures, such as lists, arrays, tuples, dictionaries, sets, and frozen sets.
- Lists: Mutable, dynamic arrays; heterogeneous items; various manipulation techniques.
- Arrays vs. Lists: Arrays are homogeneous and memory-efficient; lists are flexible and support various data types.
- Tuples: Immutable collections; faster and consumes less memory than lists; suitable for fixed collections.
- Dictionaries: Key-value pairs; mutable and versatile; used for counting, reversing, memoization, and sorting complex data.
Table of contents
- What are the Python Built-in Data Structures?
- A. Working with List
- List literal
- Creating List
- Array in Python
- Array Vs. List (Dynamic Array)
- Reverse a List with Slicing
- Methods to Traverse a List
- The list can contain/store any objects in Python
- Reverse a List using the reverse() method
- List “reversed” function
- in-place methods
- Replacing “list” vs. Replacing list’s “content”
- Copying a List using “Slicing”
- Copying a List using “copy()” method
- Copying a List using “deepcopy()”
- Concatenating lists using “+” Operator
- Use range to generate lists
- Create a List using Comprehension
- Nested-if with List Comprehension
- “flatten” a list of nested lists
- Space-separated numbers to integer list
- Combine two lists as a list of lists
- Convert a list of tuples to list of lists
- B. Working with Tuple
- C. Working with Dictionary
- Dictionary Literal
- 2D Dictionary is JSON
- Adding a new key-value pair to the nested dictionary
- Removing key-value pair from nested dictionary
- Dictionary as Collection of Counters
- Inverting the Dictionary
- Memoized Fibonacci
- Sort complex iterables with sorted()
- Define default values in Dictionaries with .get() and .setdefault()
- Merging two dictionaries using **
- Using the zip() function to create a dictionary
- Create a Dictionary using Comprehension
- Creating new dic using existing dict
- D. Working with Set
- Frequently Asked Questions
What are the Python Built-in Data Structures?
A data structure is a container that stores data in an organized way that can be accessed and manipulated whenever necessary. This article will discuss the Python built-in Data Structures: lists, Arrays, Tuples, Dictionaries, Sets, and Frozen Sets.
Additionally, here’s the Python notebook, which you can use as a quick syntax reference.
Also read: A Complete Python Tutorial to Learn Data Science from Scratch
A. Working with List
List literal
The list is a Python built-in datatype used to store items of different datatypes in one variable.
Technically, python lists are like dynamic arrays, meaning they are mutable as they’re more flexible to changes.
Note: The values held by the list are separated by commas (,) and enclosed within square brackets([]).
Creating List
# 1D List -- Homogeneous List
numbers = [1,7,8,9]
print(numbers)
# Heterogenous List
list1 = list(1, True, 20.24, 5+8j, "Python")
print("Heterogenous list: ", list1)Output
[1, 7, 8, 9]
[1, True, 20.24, 5+8j, "Python"]
Array in Python
In Python, an array is a data structure that stores multiple values of the same data type.
Note: Python arrays are not a built-in data type like lists offered by Java or CPP, though they provide an `array` module for efficient storage of homogeneous data, such as integers or floats.
from array import array
arr = array('i', [1, 2, 3])
print(arr)Output
array('i', [1, 2, 3])
Array Vs. List (Dynamic Array)
| Feature | Array (Using array module) | List (Dynamic Array in Python) |
|---|---|---|
| Data Type | Homogeneous (same data type) | Heterogeneous (different data types) |
| Syntax | array(‘i’, [1, 2, 3]) | [1, 2, 3] |
| Memory Efficiency | More memory efficient | Less memory efficient |
| Speed | Faster for numerical operations | Slower for numerical operations |
| Flexibility | Less flexible (limited to specific data types) | More flexible (can store any data type) |
| Methods | Limited built-in methods | Rich set of built-in methods |
| Module Required | Yes, from array import array | No module required |
| Mutable | Yes | Yes |
| Indexing and Slicing | Supports indexing and slicing | Supports indexing and slicing |
| Use Case | Preferred for large arrays of numbers | General-purpose storage of elements |
Reverse a List with Slicing
data = [1, 2, 3, 4, 5]
print("Reversed of the string : ", data[::-1])Output
Reversed of the string : [5, 4, 3, 2, 1]
Methods to Traverse a List
- item-wise loop: We can iterate item-wise over a loop using the range(len()) function.
# item-wise
l1 = ["a", "b", "c"]
for i in range(len(l1)):
print(l1[i])Output
a
b
c
- index-wise loop: Using range(0, len()) function we can iterate index-wise over a loop.
# index-wise
l1 = ["a", "b", "c"]
for i in range(0, len(l1)):
print(l1[i])Output
0
1
2
The list can contain/store any objects in Python
l = [1, 3.5, "hi", [1, 2, 3], type, print, input]
print(l)Output
[1, 3.5, 'hi', [1, 2, 3], <class 'type'>, <built-in function print>, <bound
method Kernel.raw_input of <google.colab._kernel.Kernel object at
0x7bfd7eef5db0>>]
keyboard_arrow_down
Reverse a List using the reverse() method
reverse(): Permanently reverses the elements of the list in place.
data = [1, 2, 3, 4, 5]
data.reverse()
print("Reversed of the string : ", data)Output
Reversed of the string : [5, 4, 3, 2, 1]
List “reversed” function
reversed(sequence): Returns the reversed iterator object of a given sequence. Note that this is not a permanent change to a list.
fruits = ['apple', 'banana', 'orange', 'grape', 'kiwi', 'apple']
for fruit in reversed(fruits):
print(fruit, end=" ")Output
apple kiwi grape orange banana apple
in-place methods
Python operates “IN PLACE”, like [].sort and [].reverse. The algorithm does not use extra space to manipulate the input but may require a small, non-constant extra space for its operation.
sort_data = [3, 2, 1]
print("Address of original list is: ", id(sort_data))
sort_data.sort()
print("Sorted list is: ", sort_data)
print("Address of Sorted list is: ", id(sort_data))
sort_data.reverse()
print("Reversed list is: ", sort_data)
print("Address of Reversed list is: ", id(sort_data))Output
Address of original list is: 2615849898048
Sorted list is: [1, 2, 3]
Address of Sorted list is: 2615849898048
Reversed list is: [3, 2, 1]
Address of Reversed list is: 2615849898048
Hence, all three addresses are the same.
Replacing “list” vs. Replacing list’s “content”
# Modifies argument pass in (Replace the list with new list)
def replace_list(data):
"""
The function `replace_list(data)` is creating a new local variable `data` and assigning it the value `['Programming Languages']`.
This does not modify the original list `programming_languages` that was passed as an argument.
"""
data = ['Programming Languages']
# Doesn't Modifies argument pass in (Change the data of the list)
def replace_list_content(data):
"""
The function `replace_list_content` is modifying the content of the list passed as an argument.
It uses the slice assignment `data[:]` to replace all the elements in the list with the new list `['Programming Languages']`.
This means that the original list `programming_languages` will be modified and will now contain only the element `'Programming Languages'`.
"""
data[:] = ['Programming Languages']
# If you need to keep same id just use slicing
programming_languages = ['C', 'C++', 'JavaScript', 'Python']
print("Original list of languages is:", programming_languages)
# When function modifies the passed-in argument:
replace_list(programming_languages)
print("Modified list of languages is:", programming_languages)
# When function modifies the content of the passed-in argument:
replace_list_content(programming_languages)
print("Unmodified list of languages is:", programming_languages) Output
Original list of languages is: ['C', 'C++', 'JavaScript', 'Python']
Modified list of languages is: ['C', 'C++', 'JavaScript', 'Python']
Unmodified list of languages is: ['Programming Languages']
Copying a List using “Slicing”
# Do not point to same exact list address in the memory even if it is copied
programming_languages = ['C', 'C++', 'JavaScript', 'Python']
learning_programming_lamnguages = programming_languages[:]
print("Id of 'programming_languages' is :", id(programming_languages), "\n" "Id of 'learning_programming_languages' is :", id(learning_programming_lamnguages))Output
Id of 'programming_languages' is : 1899836578560
Id of 'learning_programming_languages' is : 1899836579328
Copying a List using “copy()” method
copy(): Return a shallow copy of ‘programming_language.’ If there are any Nested objects, just the reference to those objects is what is copied (address), and the data object itself is not copied.
programming_languages = ['C', 'C++', 'JavaScript', 'Python']
learning_programming_languages = programming_languages.copy()
print("Id of 'programming_languages' is :", id(programming_languages), "\n" "Id of 'learning_programming_languages' is :", id(learning_programming_languages))Output
Id of 'programming_languages' is : 1899836614272
Id of 'learning_programming_languages' is : 1899836577536
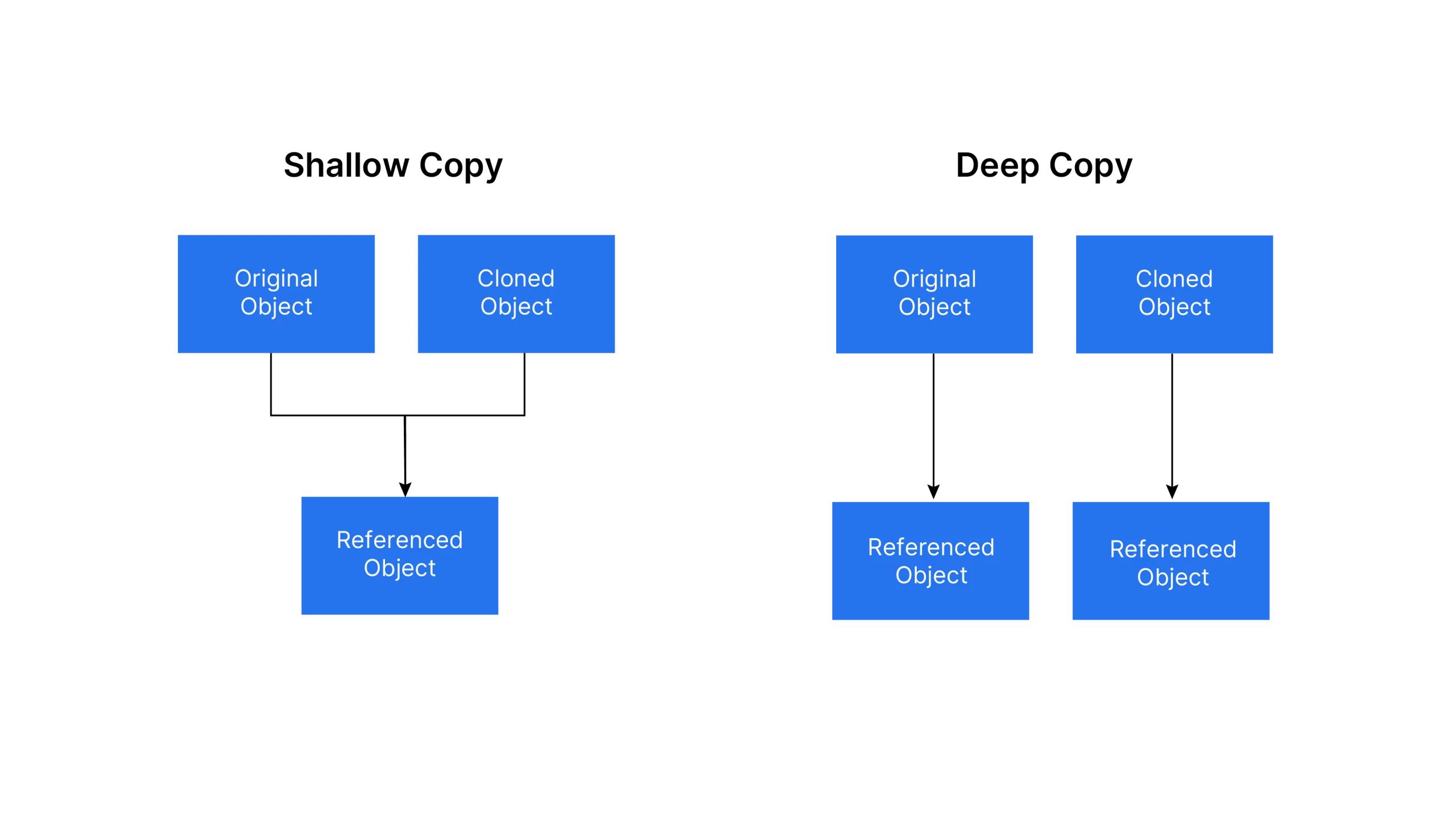
Copying a List using “deepcopy()”
Deepcopy(): Creates a new compound object and then recursively inserts copies of the objects found in the original into it.
import copy
original_list = [1, [2, 3], [4, 5]]
shallow_copied_list = copy.copy(original_list)
deep_copied_list = copy.deepcopy(original_list) # To use 'deepcopy' : from copy import deepcopy
# Modify the original list
original_list[1][0] = 'X'
print("Original List:", original_list)
print("Shallow Copied List:", shallow_copied_list)
print("Deep Copied List:", deep_copied_list)Output
Original List: [1, ['X', 3], [4, 5]]
Shallow Copied List: [1, ['X', 3], [4, 5]]
Deep Copied List: [1, [2, 3], [4, 5]]
Concatenating lists using “+” Operator
x = [1, 2, 3]
y = [4, 5, 6]
z = [7, 8, 9]
print("The concatenated list is:", x + y + z)Output
The concatenated list is: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Use range to generate lists
print(list(range(0, 10, 3)))
print(type(range(0, 10, 3))) # python 3Output
[0, 3, 6, 9]
<class 'range'>
Create a List using Comprehension
Here, in this example, we can remove certain elements from a list instead of using “for row” loops.
fruits = ['apple', 'banana', 'orange', 'grape', 'kiwi', 'apple']
removing_fruits = [fruit for fruit in fruits if fruit not in ["kiwi", "apple"]]
print("Fruits are: ", removing_fruits)Output
Fruits are: ['banana', 'orange', 'grape']
Nested-if with List Comprehension
startswith(): Checks if the string starts with the specified prefix.
fruits = ["apple", "orange", "avacado", "kiwi", "banana"]
basket = ["apple", "avacado", "apricot", "kiwi"]
[i for i in fruits if i in basket if i.startswith("a")]Output
['apple', 'avacado']
“flatten” a list of nested lists
nested_list = [[1, 2, 3], [4, 5], [6, 7, 8]]
# Method 1: Using Nested Loop:
flattened_list = []
for sublist in nested_list:
for item in sublist:
flattened_list.append(item)
print("Flattened List (using nested loop):", flattened_list)
# Method 2: Using List Comprehension:
flattened_list = [item for sublist in nested_list for item in sublist]
print("Flattened List (using list comprehension):", flattened_list)
# Method 3 : Using Recursive Function:
def flatten_list(nested_list):
flattened_list = []
for item in nested_list:
if isinstance(item, list):
flattened_list.extend(flatten_list(item))
else:
flattened_list.append(item)
return flattened_list
nested_list = [[1, 2, 3], [4, 5], [6, 7, [8, 9]]]
flattened_list_recursive = flatten_list(nested_list)
print("Flattened List (using recursive function):", flattened_list_recursive)Output
Flattened List (using nested loop): [1, 2, 3, 4, 5, 6, 7, 8]
Flattened List (using list comprehension): [1, 2, 3, 4, 5, 6, 7, 8]
Flattened List (using recursive function): [1, 2, 3, 4, 5, 6, 7, 8, 9]
Space-separated numbers to integer list
map(): Runs the specific function for every element in the iterable.
user_input = "1 2 3 4 5"
new_list = list(map(int, user_input.split()))
print("The list: ", new_list)Output
The list: [1, 2, 3, 4, 5]
Combine two lists as a list of lists
zip(): Returns an aggregated tuple iterable of multiple iterables.
# Different set of names and points
names = ['Alice', 'Bob', 'Eva', 'David']
points = [80, 300, 50, 450]
zipped = list(zip(names, points))
print(zipped)Output
[('Alice', 80), ('Bob', 300), ('Eva', 50), ('David', 450)]
Convert a list of tuples to list of lists
# Different set of names and points
names = ['Alice', 'Bob', 'Eva', 'David']
points = [80, 300, 50, 450]
zipped = list(zip(names, points))
data = [list(item) for item in zipped]
print(data)Output
[['Alice', 80], ['Bob', 300], ['Eva', 50], ['David', 450]]
B. Working with Tuple
Tuple literal
A Python tuple is an immutable collection of different data types. The values are enclosed with comma-separated (,) inside the parentheses or small brackets ‘()‘.
even_number = (2, 4, 6, 8)
print(even_number)
odd_number = (1, 3, 5, 7)
print(odd_number)Output
(2, 4, 6, 8)
(1, 3, 5, 7)
Difference between Lists and Tuples
They are both different based on below the following:
| Feature | Lists | Tuples |
|---|---|---|
| Syntax | list_variable = [1, 2, 3] | tuple_variable = (1, 2, 3) |
| Mutability | Mutable (can be changed) | Immutable (cannot be changed) |
| Speed | Slower due to dynamic nature | Faster due to immutability |
| Memory | Consumes more memory | Consumes less memory |
| Built-in Functionality | Extensive built-in functions and methods (e.g., append, extend, remove) | Limited built-in functions (e.g., count, index) |
| Error Prone | More error-prone due to mutability | Less error-prone due to immutability |
| Usability | Suitable for collections of items that may change over time | Suitable for collections of items that are fixed and shouldn’t change |
Speed
- Lists: The Python list is slower due to its dynamic nature because of mutability.
- Tuples: Python tuples are faster because of their immutable nature.
import time
# Create a large list and tuple
sample_list = list(range(100000))
sample_tuple = tuple(range(100000))
start = time.time()
# Define a function to iterate over a list
for element in sample_list:
element * 100
print(f"List iteration time: {time.time()-start} seconds")
start = time.time()
# Define a function to iterate over a tuple
for element in sample_tuple:
element * 100
print(f"Tuple iteration time: {time.time()-start} seconds")
Output
List iteration time: 0.009648799896240234 seconds
Tuple iteration time: 0.008893728256225586 seconds
Memory
- Lists: Due to their mutability and dynamic nature, lists require more memory to hold updated elements.
- Tuples: Tuples are immutable; hence, they have a fixed size in the memory.
import sys
list_ = list(range(1000))
tuple_ = tuple(range(1000))
print('List size',sys.getsizeof(list_))
print('Tuple size',sys.getsizeof(tuple_))Output
List size 8056
Tuple size 8040
Error Prone
- Lists: Mark this! Python lists are prone to errors due to their mutable nature, which can occur due to unintended changes.
a = [1, 3, 4]
b = a
print(a)
print(b)
print(id(a))
print(id(b))
a.append(2)
print(a)
print(b)
print(id(a))
print(id(b))
Output
[1, 3, 4]
[1, 3, 4]
134330236712192
134330236712192
[1, 3, 4, 2]
[1, 3, 4, 2]
134330236712192
134330236712192
- Tuples: Python tuples are less prone to errors than lists because they don’t allow changes and provide a fixed structure.
a = (1,2,3)
b = a
print(a)
print(b)
print(id(a))
print(id(b))
a = a + (4,)
print(a)
print(b)
print(id(a))
print(id(b))Output
(1, 2, 3)
(1, 2, 3)
134330252598848
134330252598848
(1, 2, 3, 4)
(1, 2, 3)
134330236763520
134330252598848
Returning multiple values and Assigning to multiple variables
def returning_position():
#get from user or something
return 5, 10, 15, 20
print("A tuple", returning_position())
x, y, z, a = returning_position()
print("Assigning to multiple variables: ", "x is", x, "y is", y,"z is", z,"a is", a)Output
A tuple (5, 10, 15, 20)
Assigning to multiple variables: x is 5 y is 10 z is 15 a is 20
Create a Tuple Using Generators
There is no such thing as Tuple Comprehension. But you can use Generator Expressions, which is a memory-efficient alternative.
# Generator expression converted to a tuple
tuple(i**2 for i in range(10))Output
(0, 1, 4, 9, 16, 25, 36, 49, 64, 81)
Tuple zip() function
t1 = ["a", "b", "c"]
t2 = [1, 2, 3]
tuple(zip(t1, t2))Output
(('a', 1), ('b', 2), ('c', 3))
Also read: Everything You Should Know About Data Structures in Python
C. Working with Dictionary
Dictionary Literal
The dictionary is the mutable datatype that stores the data in the key-value pair, enclosed by curly braces ‘{}‘.
alphabets = {'a': 'apple', 'b': 'ball', 'c': 'cat'}
print(alphabets)
information = {'id': 20, 'name': 'amit', 'salary': 20000.00, }
print(information)Output
{'a': 'apple', 'b': 'ball', 'c': 'cat'}
{'id': 20, 'name': 'amit', 'salary': 20000.00,}
2D Dictionary is JSON
The 2D or nested dictionary is also known as a JSON File. If you want to count how many times each letter appears in a given string, you can use a dictionary for this.
j = {
'name':'Nikita',
'college':'NSIT',
'sem': 8,
'subjects':{
'dsa':80,
'maths':97,
'english':94
}
}
print("JSON format: ", j)Output
JSON format: {'name': 'Nikita', 'college': 'NSIT', 'sem': 8, 'subjects':
{'dsa': 80, 'maths': 97, 'english': 94}}
Adding a new key-value pair to the nested dictionary
j['subjects']['python'] = 90
print("Updated JSON format: ", j)Updated JSON format: {‘name’: ‘Nikita’, ‘college’: ‘NSIT’, ‘sem’: 8, ‘subjects’: {‘dsa’: 80, ‘maths’: 97, ‘english’: 94, ‘python’: 90}}
Removing key-value pair from nested dictionary
del j['subjects']['maths']
print("Updated JSON format: ", j)Updated JSON format: {‘name’: ‘Nikita’, ‘college’: ‘NSIT’, ‘sem’: 8, ‘subjects’: {‘dsa’: 80, ‘english’: 94, ‘python’: 90}}
Dictionary as Collection of Counters
We can also use a dictionary as a collection of counters. For example:
def value_counts(string):
counter = {}
for letter in string:
if letter not in counter:
counter[letter] = 1
else:
counter[letter] += 1
return counter
counter = value_counts('AnalyticalNikita')
counterOutput
{'A' : 1, 'n' : 1, 'a' : 3, 'l' : 2, 'y' : 1, 't' : 2, 'c' : 1, 'N': 1, 'i' : 2, 'k' :1}
This is fine, but what if we want to reverse the dictionary, i.e., key to values and values to key? Let’s do it,
Inverting the Dictionary
The following function takes a dictionary and returns its inverse as a new dictionary:
def invert_dict(d):
new = {}
for key, value in d.items():
if value not in new:
new[value] = [key]
else:
new[value].append(key)
return new
invert_dict({'A' : 1, 'n' : 1, 'a' : 3, 'l' : 2, 'y' : 1, 't' : 2,
'c' : 1, 'N': 1, 'i' : 2, 'k' :1} )Output
{1: ['A', 'n', 'y', 'c', 'N', 'k'], 2: ['l', 't', 'i'], 3: ['l'] }
This dictionary maps integers to the words that appear that number of times as “key” to represent data better.
Memoized Fibonacci
If you have ever run a Fibonacci function, you may have noticed that the bigger the argument you provide, the longer it takes to run.
One solution is to use dynamic programming to keep track of already computed values by storing them in a dictionary. The process of storing previously computed values for later use is called memoization.
Here is a “memoized” version of, The Rabbit Problem-Fibonacci Series:
def memo_fibonacci(month, dictionary):
if month in dictionary:
return dictionary[month]
else:
dictionary[month] = memo_fibonacci(month-1, dictionary) + memo_fibonacci(month-2, dictionary)
return dictionary[month]
dictionary = {0:1, 1:1}
memo_fibonacci(48,dictionary)Output
7778742049
Sort complex iterables with sorted()
sorted(): Returns a specific iterable’s sorted list (by default in ascending order).
dictionary_data = [{"name": "Max", "age": 6},
{"name": "Max", "age": 61},
{"name": "Max", "age": 36},
]
sorted_data = sorted(dictionary_data, key=lambda x : x["age"])
print("Sorted data: ", sorted_data)Output
Sorted data: [{'name': 'Max', 'age': 6}, {'name': 'Max', 'age': 36}, {'name': 'Max', 'age': 61}]
Define default values in Dictionaries with .get() and .setdefault()
get(): Returns the value of the dictionary for a specified key. Returns None if the value is not present.
setdefault(): Returns the value of the dictionary for a specified key that isn’t present in the iterable with some default value.
my_dict = {"name": "Max", "age": 6}
count = my_dict.get("count")
print("Count is there or not:", count)
# Setting default value if count is none
count = my_dict.setdefault("count", 9)
print("Count is there or not:", count)
print("Updated my_dict:", my_dict)Output
Count is there or not: None
Count is there or not: 9
Updated my_dict: {'name': 'Max', 'age': 6, 'count': 9}
Merging two dictionaries using **
d1 = {"name": "Max", "age": 6}
d2 = {"name": "Max", "city": "NY"}
merged_dict = {**d1, **d2}
print("Here is merged dictionary: ", merged_dict)Output
Here is merged dictionary: {'name': 'Max', 'age': 6, 'city': 'NY'}
Using the zip() function to create a dictionary
days = ["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"]
temp_C = [30.5, 32.6, 31.8, 33.4, 29.8, 30.2, 29.9]
print({i: j for (i, j) in zip(days, temp_C)})Output
{'Sunday': 30.5, 'Monday': 32.6, 'Tuesday': 31.8, 'Wednesday': 33.4, 'Thursday': 29.8, 'Friday': 30.2, 'Saturday': 29.9}
Create a Dictionary using Comprehension
# Creating dictionary with squares of first 10 numbers
print({i: i**2 for i in range(1, 11)})Output
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}
Creating new dic using existing dict
# Converting currency from USD to INR
prices_usd = {'apple': 1.2, 'banana': 0.5, 'cherry': 2.5}
# New Dictionary: Convert Prices to INR
conversion_rate = 85
prices_inr = {item: price * conversion_rate for item, price in prices_usd.items()}
print(prices_inr)Output
{'apple': 102.0, 'banana': 42.5, 'cherry': 212.5}
D. Working with Set
Set Literal
Python Set is the collection of unordered data. It is enclosed by the `{}` with comma (,) separated elements.
vowels = {'a', 'e', 'i', 'o', 'u'}
numbers = {1,2,2,2,2,2,29,29,11}
print(vowels)
print(numbers)Output
{'i', 'u', 'o', 'a', 'e'}
{1, 2, 11, 29}
Remove list duplicates using “set”
fruits = ['apple', 'banana', 'banana', 'banana', 'kiwi', 'apple']
unique_fruits = list(set(fruits))
print("Unique fruits are: ", unique_fruits)Output
Unique fruits are: ['apple', 'kiwi', 'banana']Set Operations
Python offers the junior school set operations such as:
- Union using `|`
- Intersection using `&`
- Minus/Difference using `–`
- Symmetric Difference using `^`
# Two example sets
s1 = {1,2,3,4,5}
s2 = {4,5,6,7,8}
# Union: Combines all unique elements from both sets.
print("Union: ", s1 | s2)
# Intersection: Finds common elements in both sets.
print("Intersection: ", s1 & s2)
# Minus/Difference: Elements in s1 but not in s2, and vice versa.
print("S1 items that are not present in S2 - Difference: ", s1 - s2)
print("S2 items that are not present in S1 - Difference: ", s2 - s1)
# Symmetric Difference (^): Elements in either set, but not in both.
print("Symmetric Difference: ", s1 ^ s2)Output
Union: {1, 2, 3, 4, 5, 6, 7, 8}
Intersection: {4, 5}
S1 items that are not present in S2 - Difference: {1, 2, 3}
S2 items that are not present in S1 - Difference: {8, 6, 7}
Symmetric Difference: {1, 2, 3, 6, 7, 8}
Besides these, Python offers additional set functionality, including disjoint, subset, and superset.
isdisjoint()/issubset()/issuperset()
# Two example sets
s1 = {1, 2, 3, 4}
s2 = {7, 8, 5, 6}
# isdisjoint(): Checks if two sets have a null intersection. (Mathematically: No common items)
print(s1.isdisjoint(s2))
# issubset(): Checks if all elements of one set are present in another set.
print(s1.issubset(s2))
# issuperset(): Checks if all elements of one set are present in another set.
print(s1.issuperset(s2))Output
True
False
False
Create a Set using Comprehension.
# Creating a set using set comprehension with conditional
print({i**2 for i in range(1, 11) if i > 5})Output
{64, 36, 100, 49, 81}
Sets Operations on FrozenSets
Similar to Sets, FrozenSets also have the same operational functionality, such as:
- Union
- Intersection
- Minus/Difference
- Symmetric Difference
# Two example frozensets
fs1 = frozenset([1, 2, 3])
fs2 = frozenset([3, 4, 5])
print("Union: ", fs1 | fs2)
print("Intersection: ", fs1 & fs2)
print("Differencing: ", fs1 - fs2)
print("Symmetric Differencing: ", fs1 ^ fs2)Output
Union: frozenset({1, 2, 3, 4, 5})
Intersection: frozenset({3})
Differencing: frozenset({1, 2})
Symmetric Differencing: frozenset({1, 2, 4, 5})
Conclusion
So, if you have made it this far, congratulations; you now know how powerful Python Data structures are!
We have seen many examples of writing good production-level codes and exploring lists, sets, tuples, and dictionaries to the best of our ability. However, this is the first step, and we have much more to cover. Stay tuned for the next article!!
Frequently Asked Questions
Q1. Why to use comprehensions over traditional loops?
Ans. The comprehensions are an optimized and concise way of writing a loop. They are also faster than traditional loops. However, it is not recommended for too complex logic or when readability is compromised. In such cases, traditional loops might be an appropriate alternative.
Q2. Why are immutable objects considered to be more efficient than mutable objects?
Ans. Immutable objects have a fixed-size data structure upon its creation. This makes them more memory-efficient than mutable objects because there’s no overhead for resizing memory to accommodate changes in those objects.
Q3. When to use a frozenset?
Ans. A Frozen Set is used when working with an immutable set, such as a set used as a key in a dictionary. This helps retain the efficiency of set operations while ensuring the set’s contents cannot be altered, maintaining data integrity.
Q4. What is the difference between `copy()` and `deepcopy()`?
Ans. For mutable objects, copy() also known as shallow copy creates a new object with the same reference as the original object, whereas deepcopy() not only duplicates the original object to a new object but also clones its reference as a new cloned reference object in the memory.
Hi-ya!!! 👋
I'm Nikita Prasad
Data Analyst | Machine Learning and Data Science Practitioner
↪️ Checkout my Projects- GitHub: https://github.com/nikitaprasad21
Know thy Author:
👩🏻💻 As an analyst, I am eager to gain a deeper understanding of the data lifecycle with a range of tools and techniques, distilling down data for actionable takeaways using Data Analytics, ETL, Machine Learning, NLP, Sentence Transformers, Time-series Forecasting and Attention to Details to make recommendations across different business groups.
Happy Learning! 🚀🌟






