Introduction
Who says only lawyers have to deal with challenging cases and solve them? For sure, they’ve never talked to a data enthusiast — whether a data analyst, data scientist, or any other role in the vast realm of data (be sure that the data realm is too vast to have only a few roles of superheroes).
However, don’t try that at home! Discussing data with a data lover means diving into a conversation that might never end.
In the world of data, we have our own CASEs to deal with and logic to implement, to give, in the end, Caesar what belongs to Caesar (aka our client). Unlike lawyers, we don’t have piles of papers to read and interpret to save our client’s skin, but we have an important mission too…to ensure the system operates flawlessly and delivers the most accurate information whenever the client asks.
It’s the same in some ways — we both save our clients, but from different challenges, right?

Table of contents
The Importance of CASE Statements
Imagine the far-reaching consequences of making a mistake, particularly within the banking sector. An error could result in substantial financial losses for either the bank or the client simply due to incorrect logic in a CASE statement.
The CASE statement is a must-have tool in our survival toolkit, especially in complex conditions. Its versatility makes it invaluable for handling missing values, creating calculated fields, and managing nested conditions.
As data enthusiasts, we always look forward to making sense of the darker chaos within datasets and extracting the most valuable insights. It’s like solving a complex puzzle with thousands of pieces, often involving twisted logic brought by our clients.
Let’s delve deeper into this CASE of ours. We’ll explore everything from the syntax to real-world applications, providing practical examples and best practices. By the end of this article, you will be well-equipped to master this essential tool, making your data work more effective and insightful.
Understanding CASE Statements
Another way to ask how? Yes, with CASE
In some SQL environments, the IF statements aren’t as free to use as in other programming languages. Because it’s almost impossible not to have any criteria presented by the client (though life would be a lot easier in this situation), the solution comes in the form of CASE.
After a short search on Google, we see that:
CASE statements in SQL are similar to the IF-ELSE logic from other programming languages, allowing the developer to implement different logic based on specific conditions.
Syntax
Any statement in SQL has its way of telling the IDE that something is going to be done so that the IDE can recognize and prepare to interpret the expression or function we will use.
The syntax of a CASE statement in SQL is pretty simple and similar to an IF-ELSE statement.
SELECT
CASE expression
WHEN value1 THEN result1
COUNT(CASE WHEN OrderStatus = 'Pending' THEN 1 END) AS PendingOrders,
COUNT(CASE WHEN OrderStatus = 'Cancelled' THEN 1 END) AS CancelledOrders
FROM Orders;Conditional Formatting in Reports — when generating reports, CASE statements can be used to apply conditional formatting, such as flagging important records or highlighting anomalies.
SELECT
CASE
WHEN Salary > 70000 THEN 'Executive'
WHEN Salary BETWEEN 50000 AND 70000 THEN 'Professional'
ELSE 'Entry-Level'
END AS SalaryCategory
FROM Employees;Performance Considerations with CASE Statements
Like any other statement, we need to know that understanding their impact on query
WHEN value2 THEN result2
WHEN value3 THEN result3
....
ELSE resultN
END AS your_alias
FROM your_table_nameNow, let’s shed some light on the code above:
- CASE — marks the starting point of the whole syntax. Here we specify the expression that the system is going to evaluate.
- WHEN value1 THEN result1— in each WHEN … THEN branch, we compare the ‘expression’ to a specific value. If the ‘expression’ matches ‘value1′, then the ‘result1′ is returned; If not, it moves on and compares the expression with ‘value2’, and so on. You can have multiple WHEN … THEN branches based on your needs.
- ELSE — this clause is optional, but it’s highly recommended to be included. It returns a default ‘resultN’ if no one of the comparisons in the WHEN clauses hasn’t been met.
- END — indicates that the CASE statement logic ends.
This type of statement allows you to map or transform values based on the ‘surprises’ (requirements/rules) each client comes with, providing an easier and more readable way to handle different scenarios in your data.
Two types of CASE statements: Simple and Searched
I was surprised when I heard that CASE comes in two flavors: simple and searched. It’s most likely to use one or another without knowing that the magic you have written already has a name (don’t worry it happens to me a lot, and it’s normal to not know everything).
To help you get a clearer picture, let’s dive into each type and see how they work.
Simple CASE statement
As the name suggests, this is the most used type of CASE. It allows you to compare an expression to a set of possible values to determine the correct value for each scenario. It’s straightforward and really helpful when you need to evaluate a single expression against multiple values.
The syntax of a simple CASE statement is as follows:
SELECT
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
WHEN value3 THEN result3
....
ELSE resultN
END AS your_alias
FROM your_table_nameExample:
Let’s assume we have the ‘Orders’ table with the following structure and data:
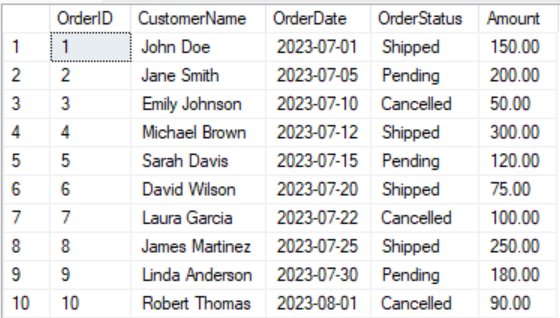
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerName VARCHAR(100),
OrderDate DATE,
OrderStatus VARCHAR(50),
Amount DECIMAL(10, 2)
);
INSERT INTO Orders (OrderID, CustomerName, OrderDate, OrderStatus, Amount) VALUES
(1, 'John Doe', '2023-07-01', 'Shipped', 150.00),
(2, 'Jane Smith', '2023-07-05', 'Pending', 200.00),
(3, 'Emily Johnson', '2023-07-10', 'Cancelled', 50.00),
(4, 'Michael Brown', '2023-07-12', 'Shipped', 300.00),
(5, 'Sarah Davis', '2023-07-15', 'Pending', 120.00),
(6, 'David Wilson', '2023-07-20', 'Shipped', 75.00),
(7, 'Laura Garcia', '2023-07-22', 'Cancelled', 100.00),
(8, 'James Martinez', '2023-07-25', 'Shipped', 250.00),
(9, 'Linda Anderson', '2023-07-30', 'Pending', 180.00),
(10, 'Robert Thomas', '2023-08-01', 'Cancelled', 90.00);We aim to categorize all order statuses into 3 main categories: Pending, Processed, and Others.
How to solve it?
To do that, we use a simple CASE statement that looks like this:
SELECT
OrderID,
CustomerName,
OrderDate,
OrderStatus AS FormerStatus,
CASE OrderStatus
WHEN 'Shipped' THEN 'Processed'
WHEN 'Pending' THEN 'Pending'
ELSE 'Others'
END AS NewStatus
FROM Orders;Result:
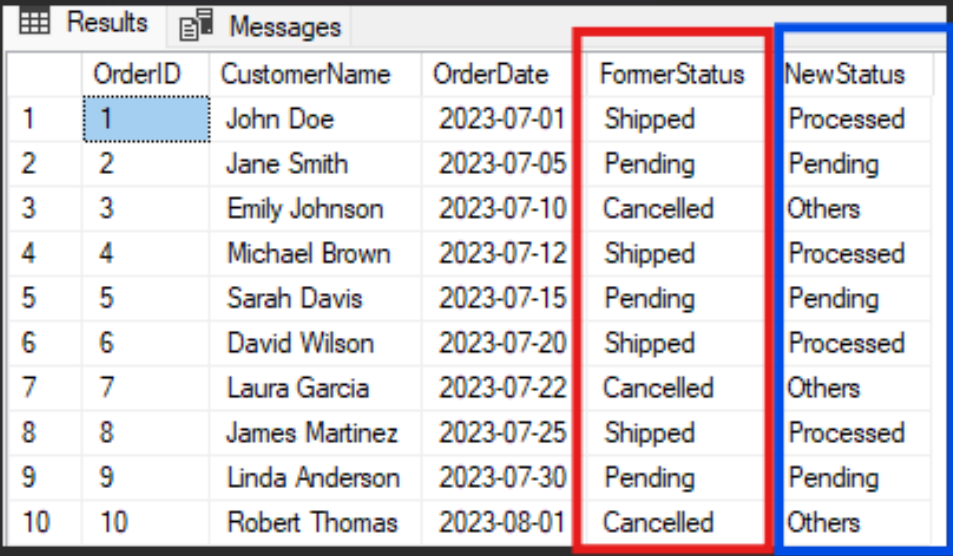
To better understand the effects of using CASE in this example, I also kept the ‘OrderStatus’ column but gave it the alias ‘FormerStatus’. In the new column, the one we created using the CASE statement, called ‘NewStatus’, we see the 3 statuses: Processed for the orders that have been Shipped and Pending for those that are still in Pending status.
I included the ELSE clause to ensure that values that do not fit into any of the categories specified in the WHEN clauses are classified as “Other”. This approach helps avoid NULL values, which can affect further analysis.
Searched CASE statement
On the other hand, a search CASE statement deals with multiple comparisons by evaluating a set of boolean expressions to determine the result.
Comparative with the simple CASE, it provides more flexibility and power, allowing you to perform complex condition checks.
The syntax of a searched CASE statement is as follows:
SELECT
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN condition3 THEN result3
...
ELSE resultN
END AS your_alias
FROM your_table_name;Now, let’s shed some light on the code above:
- CASE — again, it marks the starting point of the whole syntax. Notice that in this case the expression that will be evaluated is not written here.
- WHEN condition 1 THENresult1— in each WHEN branch, we specify the condition we want to evaluate. The evaluation is now represented by a boolean expression that will be checked for each row. If the condition is considered True, the query will return ‘result1’; the same logic applies to each WHEN … THEN branch.
- ELSE — not mandatory, but it’s recommended to be used. It provides a default result when no condition from WHEN … THEN branch hasn’t been seen as True.
- END — marks the end of the CASE statement.
Example:
In our workplace, salary raises are determined based on the current salary. Employees are categorized into three salary levels:
- Executive: For salaries above 70,000
- Professional: For salaries between 50,000 and 70,000
- Entry-Level: For salaries below 50,000
Based on these categories, the salary raise is applied as follows:
- Executive: 2% raise for salaries above 70,000
- Professional: 5% raise for salaries between 50,000 and 70,000
- Entry-Level: 10% raise for salaries below 50,000
We have the ‘Employees’ table with the below structure. We need to create an SQL query to calculate the new salary after the raise and categorize the salaries into the specified levels.
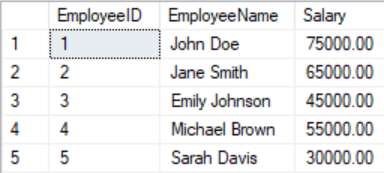
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
EmployeeName VARCHAR(100),
Salary DECIMAL(10, 2)
);
INSERT INTO Employees (EmployeeID, EmployeeName, Salary) VALUES
(1, 'John Doe', 75000.00),
(2, 'Jane Smith', 65000.00),
(3, 'Emily Johnson', 45000.00),
(4, 'Michael Brown', 55000.00),
(5, 'Sarah Davis', 30000.00);How to solve it?
To have both the raise calculation and the salary categorization in the same query we need to implement 2 CASE statements: one for salary categorization, and one for the new salary after the raise.
SELECT
EmployeeID,
EmployeeName,
Salary AS CurrentSalary,
CASE
WHEN Salary > 70000 THEN Salary * 1.02
WHEN Salary BETWEEN 50000 AND 70000 THEN Salary * 1.05
ELSE Salary * 1.10
END AS NewSalary,
CASE
WHEN Salary > 70000 THEN 'Executive'
WHEN Salary BETWEEN 50000 AND 70000 THEN 'Professional'
ELSE 'Entry-Level'
END AS SalaryCategory
FROM Employees;Result:
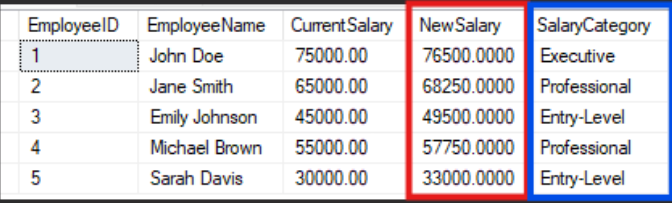
What we did was:
- SELECT statement — we initialized the beginning of a new query and kept the needed information, such as: ‘EmployeeID’, ‘EmployeeName’, ‘CurrentSalary’
- Calculate the ‘NewSalary’ column—we used a CASE statement to determine the value of the salary after the specific raise, based on the conditions: when the actual salary is bigger than 70000, the raise will be 2%, when it is between 50000 and 70000, the company will apply a 5% raise, and for those whose actual salary is below 50000, there will be a 10% raise.
- Calculate the ‘SalaryCategory’ — done through the second CASE statement, where we categorize the salaries based on the same ranges we used when we established the values for the ‘NewSalary’; so in this column, we will find 3 main categories of salaries: Executive, Professional, and Entry-Level
Difference Between Simple and Searched CASE Statements
Simple CASE statements in SQL are used to determine the result value by evaluating an expression against a set of specified values. The corresponding result is returned when the expression matches a specified value.
On the other hand, Searched CASE statements determine the result value by evaluating a set of Boolean expressions. Each Boolean expression is evaluated sequentially, and the corresponding result is returned when a true condition is found. This allows for more complex conditional logic to be applied in SQL queries.
Nested Case for Complex Logic
Now that you have become more comfortable with CASE statements, let me introduce you to NESTED CASE. In some projects, you might encounter situations when a single CASE , regardless of its type, won’t be enough to handle your complex logic.
Well, these are the scenarios when a Nested Case comes and sets the stage by allowing you to have a CASE statement embedded within another, deal with intricate decision-making processes, and can help simplify complex conditional logic by breaking it down into smaller and more manageable parts.
Example:
Sometimes, the bank creates customized loans for the oldest client of their bank. To determine which type of loan can be offered to each client, it must check its credit score and the years it’s been with the bank. So the logic might look like this:
Credit Score:
- Above 750: Excellent
- 600 to 750: Good
- Below 600: Poor
Years with the bank:
- More than 5 years: Long-term customer
- 1 to 5 years: Medium-term customer
- Less than 1 year: New customer
Based on these, the bank established the following types of loans:
- Excellent Credit Score and Long-term customer: Premium Loan
- Excellent Credit Score and Medium-term customer: Standard Loan
- Good Credit Score and Long-term customer: Standard Loan
- Good Credit Score and Medium-term customer: Basic Loan
- Any other combination: Basic Loan
To find the needed answer we use a nested CASE :
SELECT
CustomerID,
CustomerName,
CreditScore,
YearsWithBank,
CASE
WHEN CreditScore > 750 THEN
CASE
WHEN YearsWithBank > 5 THEN 'Premium Loan'
WHEN YearsWithBank BETWEEN 1 AND 5 THEN 'Standard Loan'
ELSE 'Basic Loan'
END
WHEN CreditScore BETWEEN 600 AND 750 THEN
CASE
WHEN YearsWithBank > 5 THEN 'Standard Loan'
ELSE 'Basic Loan'
END
ELSE 'Basic Loan'
END AS LoanType
FROM Customers;Result:
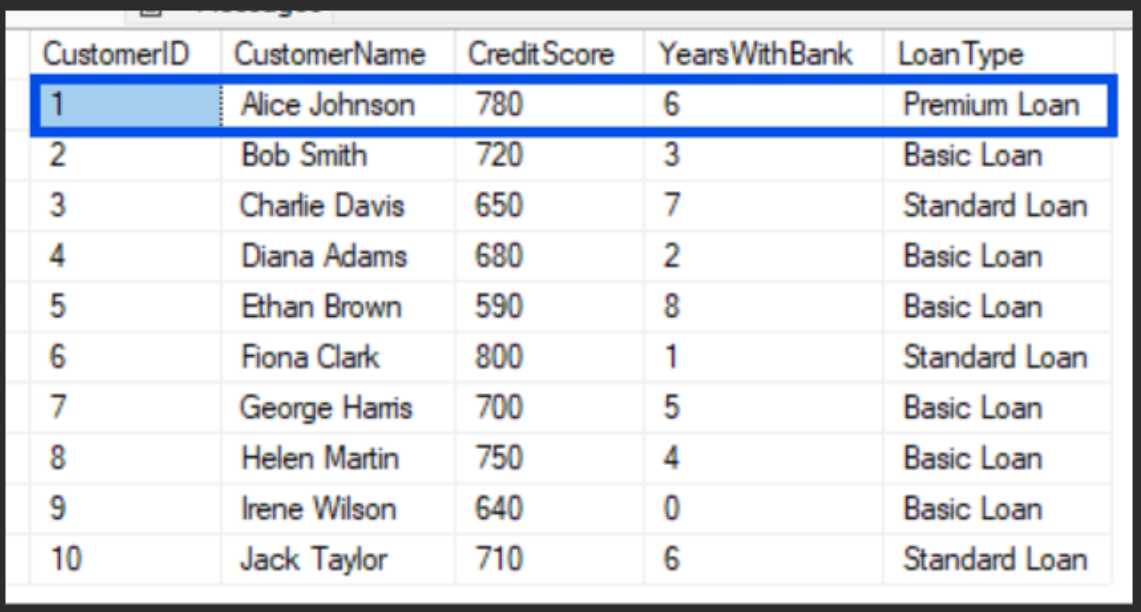
Based on the conditions, only Alice Johnson received a Premium Loan offer because her credit score is higher than 750, and she’s been a bank client for about six years already.
Also read: SQL For Data Science: A Beginner Guide!
Most use cases for CASE statements
We have already seen that the CASE statement is a powerful tool for implementing conditional logic directly in your queries. Below are some of the most common use cases where CASE statements saved the situation:
- Data transformation and Categorization — There aren’t a few situations when we need to transform or categorize the data based on certain conditions. The CASE helps us to convert numerical codes to text or group numerical ranges into categories, such as categorizing orders.
SELECT
Name,
Age,
CASE
WHEN Age < 18 THEN 'Minor'
WHEN Age BETWEEN 18 AND 64 THEN 'Adult'
ELSE 'Senior'
END AS AgeGroup
FROM Employees;- Conditional Aggregations — you can use CASE statements within aggregate functions to perform conditional aggregations, such as counting only certain types of records or summing values that meet specific criteria.
SELECT
COUNT(CASE WHEN OrderStatus = 'Shipped' THEN 1 END) AS ShippedOrders,
COUNT(CASE WHEN OrderStatus = 'Pending' THEN 1 END) AS PendingOrders,
COUNT(CASE WHEN OrderStatus = 'Cancelled' THEN 1 END) AS CancelledOrders
FROM Orders;- Conditional Formatting in Reports — when generating reports, CASE statements can be used to apply conditional formatting, such as flagging important records or highlighting anomalies.
SELECT
CASE
WHEN Salary > 70000 THEN 'Executive'
WHEN Salary BETWEEN 50000 AND 70000 THEN 'Professional'
ELSE 'Entry-Level'
END AS SalaryCategory
FROM Employees;Performance considerations with CASE statements
Like any other statement, we need to know that understanding their impact on query performance is crucial. Here are some key points to consider when including the CASE statement within your queries:
- Complexity of conditions — Be mindful of your conditions as their quantity and complexity can significantly impact the speed of your query execution.
- Indexing and Execution Plans — The CASE statements cannot be indexed, but the columns used within them can be. Effective indexing is essential for the database engine to locate and evaluate rows, significantly boosting overall performance swiftly.
- Use of Functions and Expressions — When incorporating functions or intricate expressions within statements, it is important to be aware that performance might be negatively impacted, particularly when these functions require evaluation on a row-by-row basis.
Also Read: SQL: A Full Fledged Guide from Basics to Advance Level
Conclusion
The CASE statement in SQL is an essential tool for data enthusiasts. It provides a powerful and flexible way to handle complex conditional logic within queries. Similar to how lawyers solve challenging cases, data professionals use the CASE statement to ensure the accuracy and reliability of their analyses and reports. This tool is indispensable for transforming and categorizing data, performing conditional aggregations, and applying conditional formatting in reports, which makes data insights more meaningful and actionable.
In this article, we have explored both the syntax and practical applications of simple and searched CASE statements, demonstrated their use in real-world scenarios, and highlighted best practices for optimizing their performance. By mastering the CASE statement, data analysts and scientists can enhance the effectiveness of their SQL queries, ensuring they deliver precise and insightful results to their clients.





