Introduction
You’ve probably interacted with AI models like ChatGPT, Claude, and Gemini for various tasks – answering questions, generating creative content, or assisting with research. But did you know these are examples of large language models (LLMs)? These powerful AI systems are trained on enormous text datasets, enabling them to understand and produce text that feels remarkably human.
If you asked about my understanding of large language models (LLMs), I’d say I’m just scratching the surface. So, to learn more about it, I have been reading a lot about LLMs lately to get more clarity on how they work and make our lives easier.
On this quest, I came across this research paper: Hallucination is Inevitable: An Innate Limitation of Large Language Models by Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli.
This paper discusses Hallucinations in LLMs and says that despite countless efforts to address the issue, it’s impossible to eliminate them completely. These hallucinations occur when a seemingly reliable AI confidently delivers information that, although plausible-sounding, is entirely fabricated. This persistent flaw reveals a significant weakness in the technology behind today’s most advanced AI systems.
In this article, I will tell you everything about the research that formalizes the concept of hallucination in LLMs and delivers a sobering conclusion: hallucination is not just a glitch but an inherent feature of these models.

Overview
- Learn what hallucinations are in Large Language Models and why they occur.
- Discover how hallucinations in LLMs are categorized and what they reveal about AI limitations.
- Explore the root causes of hallucinations, from data issues to training flaws.
- Examine current strategies to reduce hallucinations in LLMs and their effectiveness.
- Delve into research that proves hallucinations are an inherent and unavoidable aspect of LLMs.
- Understand the need for safety measures and ongoing research to address the persistent challenge of hallucinations in AI.
Table of contents
- What are Hallucinations in LLMs?
- Foundational Concepts: Alphabets, Strings, and Language Models
- Hallucination is Inevitable for LLMs
- Empirical Validation: LLMs Struggle with Simple String Enumeration Tasks Despite Large Context Windows and Parameters
- Mitigating hallucinations in Large Language Models (LLMs)
- Frequently Asked Questions
What are Hallucinations in LLMs?
Large language models (LLMs) have significantly advanced artificial intelligence, particularly in natural language processing. However, they face the challenge of “hallucination,” where they generate plausible but incorrect or nonsensical information. This issue raises concerns about safety and ethics as LLMs are increasingly applied in various fields.
Research has identified multiple sources of hallucination, including data collection, training processes, and model inference. Various methods have been proposed to reduce hallucination, such as using factual-centered metrics, retrieval-based methods, and prompting models to reason or verify their outputs.
Despite these efforts, hallucination remains a largely empirical issue. The paper argues that hallucination is inevitable for any computable LLM, regardless of the model’s design or training. The study provides theoretical and empirical evidence to support this claim, offering insights into how LLMs should be designed and deployed in practice to minimize the impact of hallucination.
Classification of Hallucination
Hallucinations in language models can be classified based on outcomes or underlying processes. A common framework is the intrinsic-extrinsic dichotomy: Intrinsic hallucination occurs when the output contradicts the given input, while extrinsic hallucination involves outputs that the input information cannot verify. Huang et al. introduced “faithfulness hallucination,” focusing on inconsistencies in user instructions, context, and logic. Rawte et al. further divided hallucinations into “factual mirage” and “silver lining,” with each category containing intrinsic and extrinsic types.
Causes of Hallucination
Hallucinations typically stem from data, training, and inference issues. Data-related causes include poor quality, misinformation, bias, and outdated knowledge. Training-related causes involve architectural and strategic deficiencies, such as exposure bias from inconsistencies between training and inference. The attention mechanism in transformer models can also contribute to hallucination, especially over long sequences. Inference-stage factors like sampling randomness and softmax bottlenecks further exacerbate the issue.
Checkout DataHour: Reducing ChatGPT Hallucinations by 80%
Mitigating Hallucination
Addressing hallucination involves tackling its root causes. Creating fact-focused datasets and using automatic data-cleaning techniques are crucial for data-related issues. Retrieval augmentation, which integrates external documents, can reduce knowledge gaps and decrease hallucinations. Prompting techniques, like Chain-of-Thought, have enhanced knowledge recall and reasoning. Architectural improvements, such as sharpening softmax functions and using factuality-enhanced training objectives, help mitigate hallucination during training. New decoding methods, like factual-nucleus sampling and Chain-of-Verification, aim to improve the factual accuracy of model outputs during inference.
Also Read: Top 7 Strategies to Mitigate Hallucinations in LLMs
Foundational Concepts: Alphabets, Strings, and Language Models
1. Alphabet and Strings
An alphabet is a finite set of tokens, and a string is a sequence created by concatenating these tokens. This forms the basic building blocks for language models.
2. Large Language Model (LLM)
An LLM function can complete any finite-length input string within a finite time. It’s trained using a set of input-completion pairs, making it a general definition covering various language model types.
3. P-proved LLMs
These are a subset of LLMs with specific properties (like total computability or polynomial-time complexity) that a computable algorithm P can prove. This definition helps categorize LLMs based on their provable characteristics.
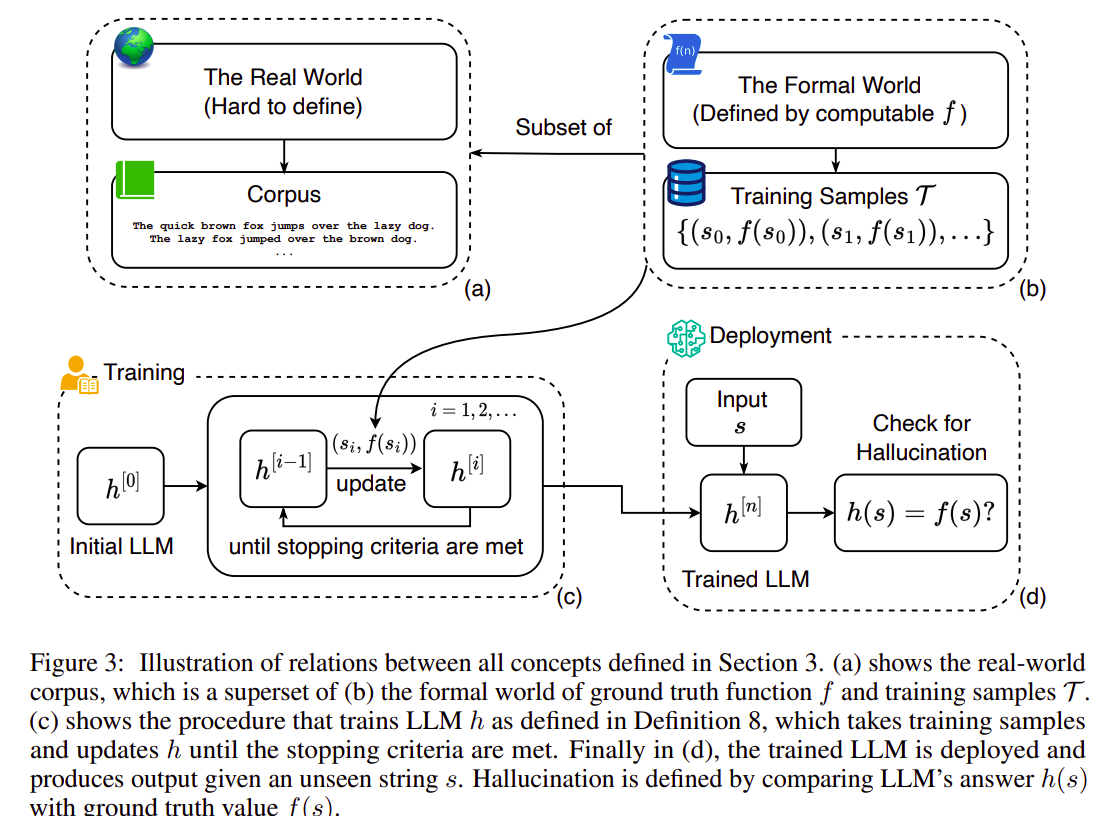
4. Formal World
The formal world is a set of all possible input-output pairs for a given ground truth function f. F (s) is the only correct completion for any input string s. This provides a framework for discussing correctness and hallucination.
5. Training Samples
Training samples are defined as input-output pairs derived from the formal world. They represent how the ground truth function f answers or completes input strings, forming the basis for training LLMs.
6. Hallucination
Hallucination is any instance where an LLM’s output differs from the ground truth function’s output for a given input. This definition simplifies the concept of hallucination to a measurable inconsistency between the LLM and the ground truth.
7. Training and Deploying an LLM
This is an iterative procedure where an LLM is repeatedly updated using training samples. The process continues until certain stopping criteria are met, resulting in a final trained model ready for deployment. This definition generalizes the training process across different types of LLMs and training methodologies.
To this point, the author established all the necessary concepts for further discussion: the nature of LLMs, the phenomenon of hallucination within a formal context, and a generalized training process that abstracts away the specific learning intricacies. The figure above illustrates the relationships between these definitions. It’s important to note that the definition applies not only to transformer-based LLMs but also to all computable LLMs and common learning frameworks. Additionally, LLMs trained using the method described in Definition 7 exhibit significantly greater power and flexibility than their real-world counterparts. Consequently, if hallucination is unavoidable for our LLMs in the relatively straightforward formal world, it is even more inevitable in the more complex real world.
Hallucination is Inevitable for LLMs

The section progresses from specific to general, beginning with discussing simpler large language models (LLMs) that resemble real-world examples and then expanding to encompass any computable LLMs. Initially, it is shown that all LLMs within a countable set of P-provable LLMs will experience hallucinations on certain inputs (Theorem 1). Although the provability requirement limits LLMs’ complexity, it allows for exploring concrete instances where hallucination occurs. The analysis then removes the provability constraint, establishing that all LLMs in a computably enumerable set will hallucinate on infinitely many inputs (Theorem 2). Finally, hallucination is proven unavoidable for all computable LLMs (Theorem 3), addressing the key question posed in Definition 7.
The paper section argues that hallucination in large language models (LLMs) is inevitable due to fundamental limitations in computability. Using diagonalization and computability theory, the authors show that all LLMs, even those that are P-proved to be totally computable, will hallucinate when encountering certain problems. This is because some functions or tasks cannot be computed within polynomial time, causing LLMs to produce incorrect outputs (hallucinations).

Let’s look at some factors that make hallucination a fundamental and unavoidable aspect of LLMs:
Hallucination in P-Proved Total Computable LLMs
- P-Provability Assumption: Assuming that LLMs are P-proved, total computable means they will output an answer for any finite input in finite time.
- Diagonalization Argument: By re-enumerating the states of LLMs, the paper demonstrates that if a ground truth function f is not in the enumeration, then all LLMs will hallucinate with respect to f.
- Key Theorem: A computable ground truth function exists such that all P-proved total computable LLMs will inevitably hallucinate.
Polynomial-Time Constraint
If you design an LLM to output results in polynomial time, it will hallucinate on tasks that it cannot compute within that time frame. Examples of Hallucination-Prone Tasks:
- Combinatorial List: Requires O(2^m) time.
- Presburger Arithmetic: Requires O(22^Π(m)) time.
- NP-Complete Problems: Tasks like Subset Sum and Boolean Satisfiability (SAT) are particularly prone to hallucination in LLMs restricted to polynomial time.
Polynomial-Time Constraint
If you design an LLM to output results in polynomial time, it will hallucinate on tasks that it cannot compute within that time frame.
Generalized Hallucination in Computably Enumerable LLMs:
- Theorem 2: Even when removing the P-provability constraint, all LLMs in a computably enumerable set will hallucinate on infinitely many inputs. This shows that hallucination is a broader phenomenon, not just limited to specific types of LLMs.
Inevitability of Hallucination in Any Computable LLM:
- Theorem 3: Extending the previous results, the paper proves that every computable LLM will hallucinate on infinitely many inputs, regardless of its architecture, training, or any other implementation detail.
- Corollary: Even with advanced techniques like prompt-based methods, LLMs cannot completely eliminate hallucinations.
Examples of Hallucination-Prone Tasks:
- Combinatorial List: Requires O(2^m) time.
- Presburger Arithmetic: Requires O(22^Π(m)) time.
- NP-Complete Problems: Tasks like Subset Sum and Boolean Satisfiability (SAT) are particularly prone to hallucination in LLMs restricted to polynomial time.
The paper extends this argument to prove that any computable LLM, regardless of its design or training, will hallucinate on infinitely many inputs. This inevitability implies that no technique, including advanced prompt-based methods, can eliminate hallucinations in LLMs. Thus, hallucination is a fundamental and unavoidable aspect of LLMs in theoretical and real-world contexts.
Also read about KnowHalu: AI’s Biggest Flaw Hallucinations Finally Solved With KnowHalu!
Empirical Validation: LLMs Struggle with Simple String Enumeration Tasks Despite Large Context Windows and Parameters
This study investigates the ability of large language models (LLMs), specifically Llama 2 and GPT models, to list all possible strings of a fixed length using a specified alphabet. Despite their significant parameters and large context windows, the models struggled with seemingly simple tasks, particularly as the string length increased. The experiment found that these models consistently failed to generate complete and accurate lists aligning with theoretical predictions even with substantial resources. The study highlights the limitations of current LLMs in handling tasks that require precise and exhaustive output.
Base Prompt
You are a helpful, respectful, and honest assistant. Always answer as helpfully as possible while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive. If you don’t know the answer to a question, please don’t share false information. However, if you know the answer, you should always share it in every detail and as requested. Always answer directly. Do not respond with a script or any approximation.

You can find the results in the research paper.
Mitigating hallucinations in Large Language Models (LLMs)
The section outlines existing and potential strategies for mitigating hallucinations in Large Language Models (LLMs). Key approaches include:
- Larger Models and More Training Data: Researchers believe that increasing model size and training data reduces hallucinations by enhancing the model’s ability to capture complex ground truth functions. However, this approach becomes limited when LLMs fail to capture the ground truth function, regardless of their size.
- Prompting with Chain of Thoughts/Reflections/Verification: This strategy involves providing LLMs with structured prompts to guide them toward more accurate solutions. While effective in some cases, it is not universally applicable and cannot fully eliminate hallucinations.
- Ensemble of LLMs: Combining multiple LLMs to reach a consensus can reduce hallucinations, but the same theoretical bounds as individual LLMs still limit the ensemble.
- Guardrails and Fences: These safety constraints align LLM outputs with human values and ethics, potentially reducing hallucinations in critical areas. However, their scalability remains uncertain.
- LLMs Enhanced by Knowledge: Incorporating external knowledge sources and symbolic reasoning can help LLMs reduce hallucinations, especially in formal tasks. However, the effectiveness of this approach in real-world applications is still unproven.
The practical implications of these strategies highlight the inevitability of hallucinations in LLMs and the necessity of guardrails, human oversight, and further research to ensure these models’ safe and ethical use.
Conclusion
The study concludes that eliminating hallucinations in LLMs is fundamentally impossible, as they are inevitable due to the limitations of computable functions. Existing mitigators can reduce hallucinations in specific contexts but cannot eliminate them. Therefore, rigorous safety studies and appropriate safeguards are essential for the responsible deployment of LLMs in real-world applications.
Let me know what you think about Hallucinations in LLMs – is it inevitable to fix this?
If you have any feedback or queries regarding the blog, comment below and explore our blog section for more articles like this.
Dive into the future of AI with GenAI Pinnacle. Empower your projects with cutting-edge capabilities, from training bespoke models to tackling real-world challenges like PII masking. Start Exploring.
Frequently Asked Questions
Q1. What is a hallucination in large language models (LLMs)?
Ans. Hallucination in LLMs occurs when the model generates information that seems plausible but is incorrect or nonsensical, deviating from the true or expected output.
Q2. Why are hallucinations inevitable in LLMs?
Ans. Hallucinations are inevitable due to the fundamental limitations in computability and the complexity of tasks that LLMs attempt to perform. No matter how advanced, all LLMs will eventually produce incorrect outputs under certain conditions.
Q3. How do hallucinations typically occur in LLMs?
Ans. Hallucinations usually arise from issues during data collection, training, and inference. Factors include poor data quality, biases, outdated knowledge, and architectural limitations in the models.
Q4. What strategies are currently used to mitigate hallucinations in LLMs?
Ans. Mitigation strategies include using larger models, improving training data, employing structured prompts, combining multiple models, and integrating external knowledge sources. However, these methods can only reduce hallucinations, not eliminate them entirely.
Q5. What are the implications of the inevitability of hallucinations in LLMs?
Ans. Since we cannot entirely avoid hallucinations, we must implement safety measures, human oversight, and continuous research to minimize their impact, ensuring the responsible use of LLMs in real-world applications.
Hi, I am Pankaj Singh Negi - Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.



Nice read.