Introduction
You know how we’re always hearing about “diverse” datasets in machine learning? Well, it turns out there’s been a problem with that. But don’t worry – a brilliant team of researchers has just dropped a game-changing paper that’s got the whole ML community buzzing. In the paper that recently won the ICML 2024 Best Paper Award, researchers Dora Zhao, Jerone T. A. Andrews, Orestis Papakyriakopoulos, and Alice Xiang tackle a critical issue in machine learning (ML) – the often vague and unsubstantiated claims of “diversity” in datasets. Their work, titled “Measure Dataset Diversity, Don’t Just Claim It,” proposes a structured approach to conceptualizing, operationalizing, and evaluating diversity in ML datasets using principles from measurement theory.

Now, I know what you’re thinking. “Another paper about dataset diversity? Haven’t we heard this before?” But trust me, this one’s different. These researchers have taken a hard look at how we use terms like “diversity,” “quality,” and “bias” without really backing them up. We’ve been playing fast and loose with these concepts, and they’re calling us out on it.
But here’s the best part—they’re not just pointing out the problem. They’ve developed a solid framework to help us measure and validate diversity claims. They’re handing us a toolbox to fix this messy situation.
So, buckle up because I’m about to take you on a deep dive into this groundbreaking research. We will explore how we can move beyond claiming diversity to measuring it. Trust me, by the end of this, you’ll never look at an ML dataset the same way again!
Table of contents
The Problem with Diversity Claims
The authors highlight a pervasive issue in the Machine learning community: dataset curators frequently employ terms like “diversity,” “bias,” and “quality” without clear definitions or validation methods. This lack of precision hampers reproducibility and perpetuates the misconception that datasets are neutral entities rather than value-laden artifacts shaped by their creators’ perspectives and societal contexts.
A Framework for Measuring Diversity
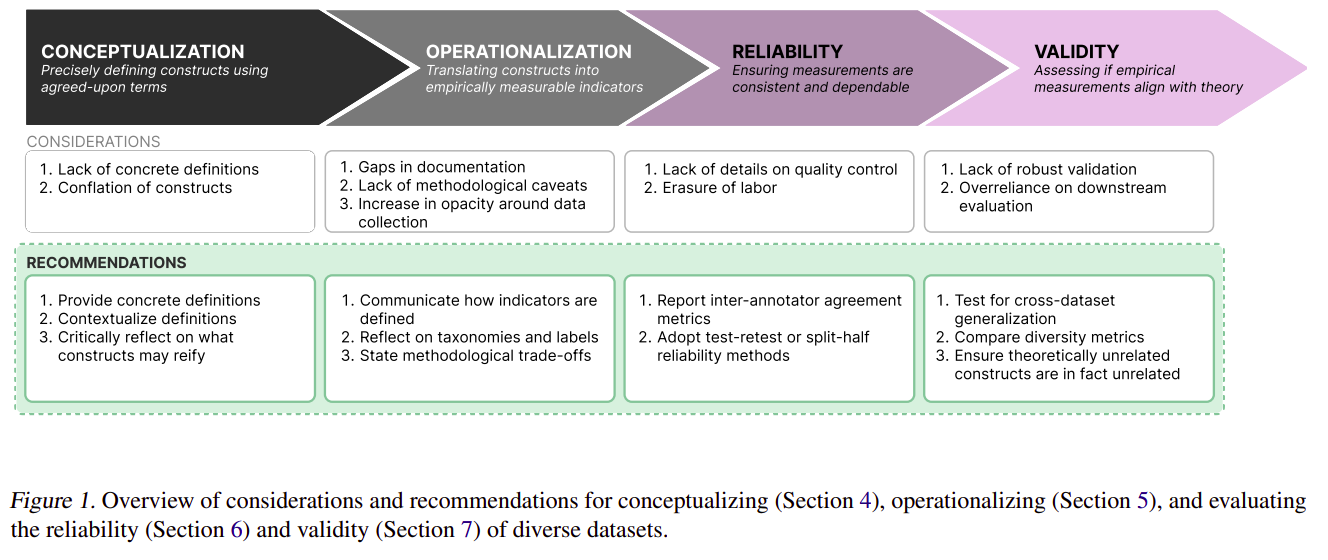
Drawing from social sciences, particularly measurement theory, the researchers present a framework for transforming abstract notions of diversity into measurable constructs. This approach involves three key steps:
- Conceptualization: Clearly defining what “diversity” means in the context of a specific dataset.
- Operationalization: Developing concrete methods to measure the defined aspects of diversity.
- Evaluation: Assessing the reliability and validity of the diversity measurements.
In summary, this position paper advocates for clearer definitions and stronger validation methods in creating diverse datasets, proposing measurement theory as a scaffolding framework for this process.
Key Findings and Recommendations
Through an analysis of 135 image and text datasets, the authors uncovered several important insights:
- Lack of Clear Definitions: Only 52.9% of datasets explicitly justified the need for diverse data. The paper emphasizes the importance of providing concrete, contextualized definitions of diversity.
- Documentation Gaps: Many papers introducing datasets fail to provide detailed information about collection strategies or methodological choices. The authors advocate for increased transparency in dataset documentation.
- Reliability Concerns: Only 56.3% of datasets covered quality control processes. The paper recommends using inter-annotator agreement and test-retest reliability to assess dataset consistency.
- Validity Challenges: Diversity claims often lack robust validation. The authors suggest using techniques from construct validity, such as convergent and discriminant validity, to evaluate whether datasets truly capture the intended diversity of constructs.
Practical Application: The Segment Anything Dataset
To illustrate their framework, the paper includes a case study of the Segment Anything dataset (SA-1B). While praising certain aspects of SA-1B’s approach to diversity, the authors also identify areas for improvement, such as enhancing transparency around the data collection process and providing stronger validation for geographic diversity claims.
Broader Implications
This research has significant implications for the ML community:
- Challenging “Scale Thinking”: The paper argues against the notion that diversity automatically emerges with larger datasets, emphasizing the need for intentional curation.
- Documentation Burden: While advocating for increased transparency, the authors acknowledge the substantial effort required and call for systemic changes in how data work is valued in ML research.
- Temporal Considerations: The paper highlights the need to account for how diversity constructs may change over time, affecting dataset relevance and interpretation.
You can read the paper here: Position: Measure DatasetOkay Diversity, Don’t Just Claim It
Conclusion
This ICML 2024 Best Paper offers a path toward more rigorous, transparent, and reproducible research by applying measurement theory principles to ML dataset creation. As the field grapples with issues of bias and representation, the framework presented here provides valuable tools for ensuring that claims of diversity in ML datasets are not just rhetoric but measurable and meaningful contributions to developing fair and robust AI systems.
This groundbreaking work serves as a call to action for the ML community to elevate the standards of dataset curation and documentation, ultimately leading to more reliable and equitable machine learning models.
I’ve got to admit, when I first saw the authors’ recommendations for documenting and validating datasets, a part of me thought, “Ugh, that sounds like a lot of work.” And yeah, it is. But you know what? It’s work that needs to be done. We can’t keep building AI systems on shaky foundations and just hope for the best. But here’s what got me fired up: this paper isn’t just about improving our datasets. It’s about making our entire field more rigorous, transparent, and trustworthy. In a world where AI is becoming increasingly influential, that’s huge.
So, what do you think? Are you ready to roll up your sleeves and start measuring dataset diversity? Let’s chat in the comments – I’d love to hear your thoughts on this game-changing research!
You can read other ICML 2024 Best Paper‘s here: ICML 2024 Top Papers: What’s New in Machine Learning.
Frequently Asked Questions
Q1. Why is measuring dataset diversity important in machine learning?
Ans. Measuring dataset diversity is crucial because it ensures that the datasets used to train machine learning models represent various demographics and scenarios. This helps reduce biases, improve models’ generalizability, and promote fairness and equity in AI systems.
Q2. How does dataset diversity impact the performance of ML models?
Ans. Diverse datasets can improve the performance of ML models by exposing them to a wide range of scenarios and reducing overfitting to any particular group or scenario. This leads to more robust and accurate models that perform well across different populations and conditions.
Q3. What are some common challenges in measuring dataset diversity?
Ans. Common challenges include defining what constitutes diversity, operationalizing these definitions into measurable constructs, and validating the diversity claims. Additionally, ensuring transparency and reproducibility in documenting the diversity of datasets can be labor-intensive and complex.
Q4. What are the practical steps for improving dataset diversity in ML projects?
Ans. Practical steps include:
a. Clearly defining diversity goals and criteria specific to the project.
b. Collecting data from various sources to cover different demographics and scenarios.
c. Using standardized methods to measure and document diversity in datasets.
d. Continuously evaluate and update datasets to maintain diversity over time.
e.Implementing robust validation techniques to ensure the datasets genuinely reflect the intended diversity.
Hi, I am Pankaj Singh Negi - Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.





