Introduction
In language models, where the quest for efficiency and precision is paramount, Llama 3.1 Storm 8B emerges as a notable achievement. This fine-tuned version of Meta’s Llama 3.1 8B Instruct represents a leap forward in enhancing conversational and function-calling capabilities within the 8B parameter model class. The journey to this advancement is rooted in a meticulous approach centered around data curation, where high-quality training samples were carefully selected to maximize the model’s potential.
The fine-tuning process didn’t stop there; it progressed through spectrum-based targeted fine-tuning, culminating in strategic model merging. This article discusses the innovative techniques that propelled Llama 3.1 Storm 8B to outperform its predecessors, setting a new benchmark in small language models.
In this article, you will understand the differences between Llama 3.1 and Llama 3.1 Storm 8B, including features of Hermes Llama 3.1 and the advancements of Llama 3.1 8B GGUF.

Table of contents
What is Llama-3.1-Storm-8B?
Llama-3.1-Storm-8B builds on the strengths of Llama-3.1-8B-Instruct, enhancing conversational and function-calling capabilities within the 8B parameter model class. This upgrade demonstrates notable improvements across multiple benchmarks, including instruction-following, knowledge-driven QA, reasoning, reducing hallucinations, and function-calling. These advancements benefit AI developers and enthusiasts working with limited computational resources.
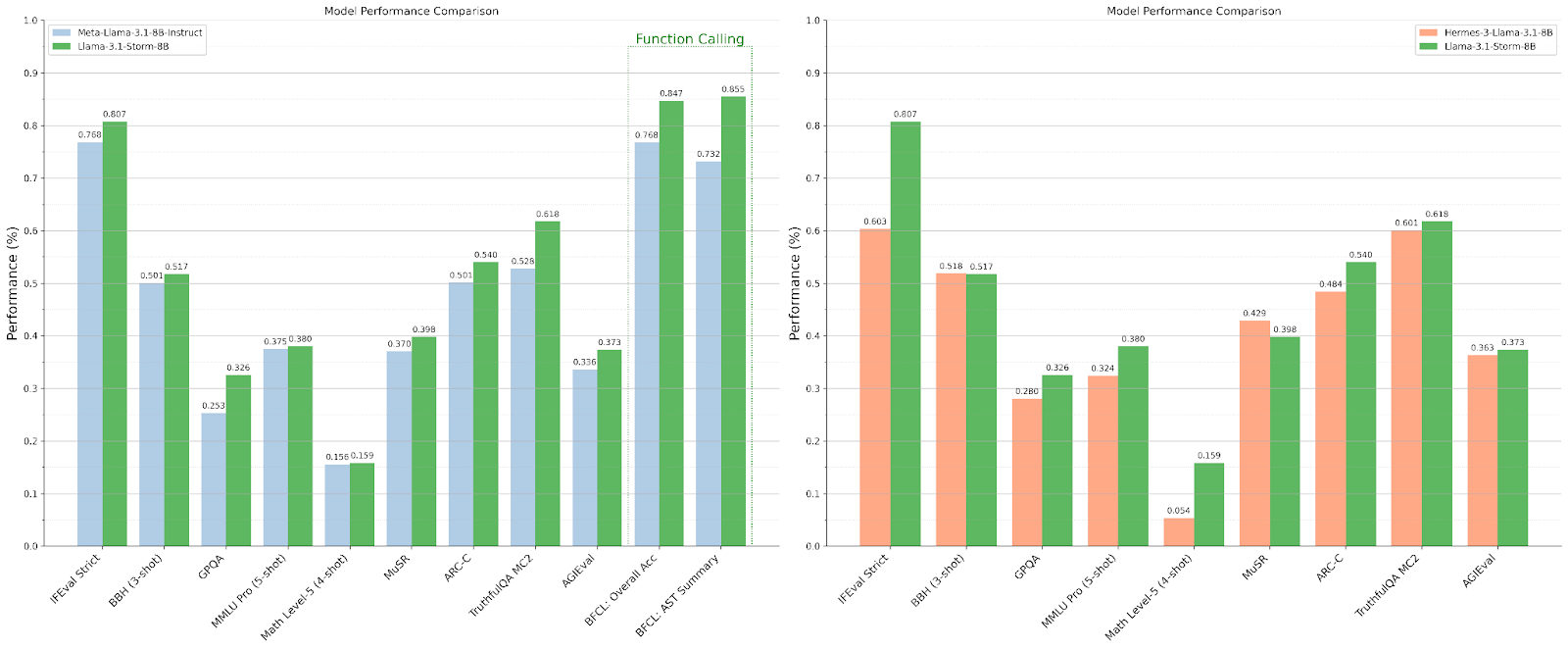
Compared to the recent Hermes-3-Llama-3.1-8B model, Llama-3.1-Storm-8B outperforms 7 out of 9 benchmarks. Hermes-3 leads only in the MuSR benchmark, and both models perform similarly on the BBH benchmark.
Llama 3.1 Storm 8B Strengths
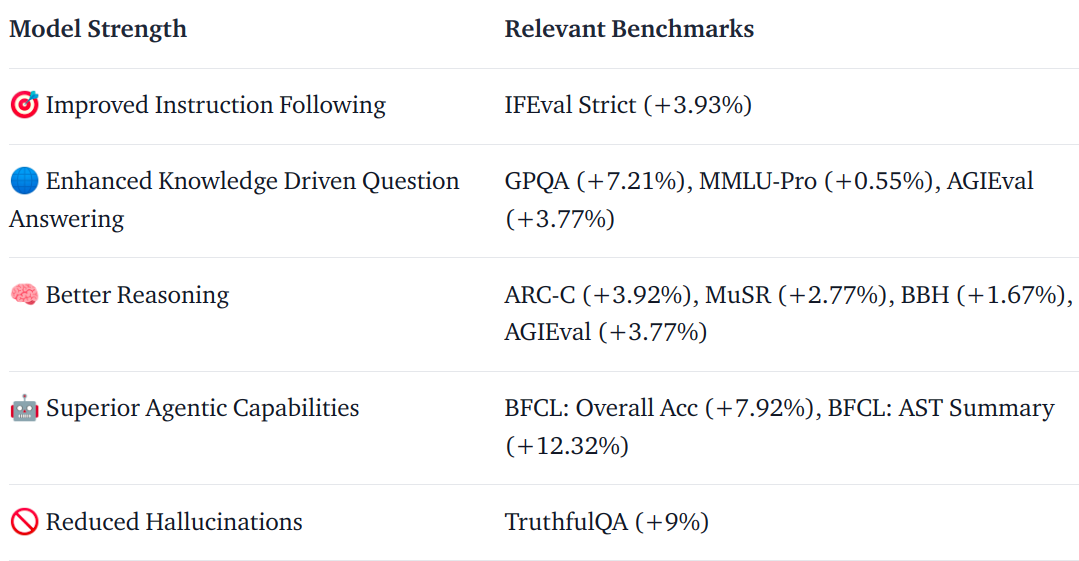
The above image represents improvements (absolute gains) over the Llama 3.1 8B Instruct.
Llama 3.1 Storm 8B Models
Here are Llama 3.1 Storm 8B Models:
- Llama 3.1 Storm 8B: This is the primary fine-tuned model.
- Llama 3.1 Storm 8B FP8 Dynamic: This script quantises the weights and activations of Llama-3.1-Storm-8B to FP8 data type, resulting in a model that is ready for vLLM inference. By lowering the number of bits per parameter from 16 to 8, this optimization saves roughly 50% on GPU memory requirements and disc space.
The linear operators’ weights and activations are the only quantized elements in transformer blocks. The FP8 representations of these quantized weights and activations are mapped using a single linear scaling technique known as symmetric per-tensor quantization. 512 UltraChat sequences are quantized using the LLM Compressor. - Llama 3.1 Storm 8B GGUF: This is the GGUF quantized version of Llama-3.1-Storm-8B, for use with llama.cpp. GGUF is a file format for storing models for inference with GGML and executors based on GGML. GGUF is a binary format that is designed for fast loading and saving of models and for ease of reading. Models are traditionally developed using PyTorch or another framework and then converted to GGUF for use in GGML. It is a successor file format to GGML, GGMF, and GGJT and is designed to be unambiguous by containing all the information needed to load a model. It is also designed to be extensible so that new information can be added to models without breaking compatibility.
Also read: Meta Llama 3.1: Latest Open-Source AI Model Takes on GPT-4o mini
The Approach Followed
The performance comparison plot shows Llama 3.1 Storm 8B significantly outperforms Meta AI’s Llama 3.1 8B Instruct and Hermes 3 Llama 3.1 8B models across diverse benchmarks.
Their approach consists of 3 Major steps:
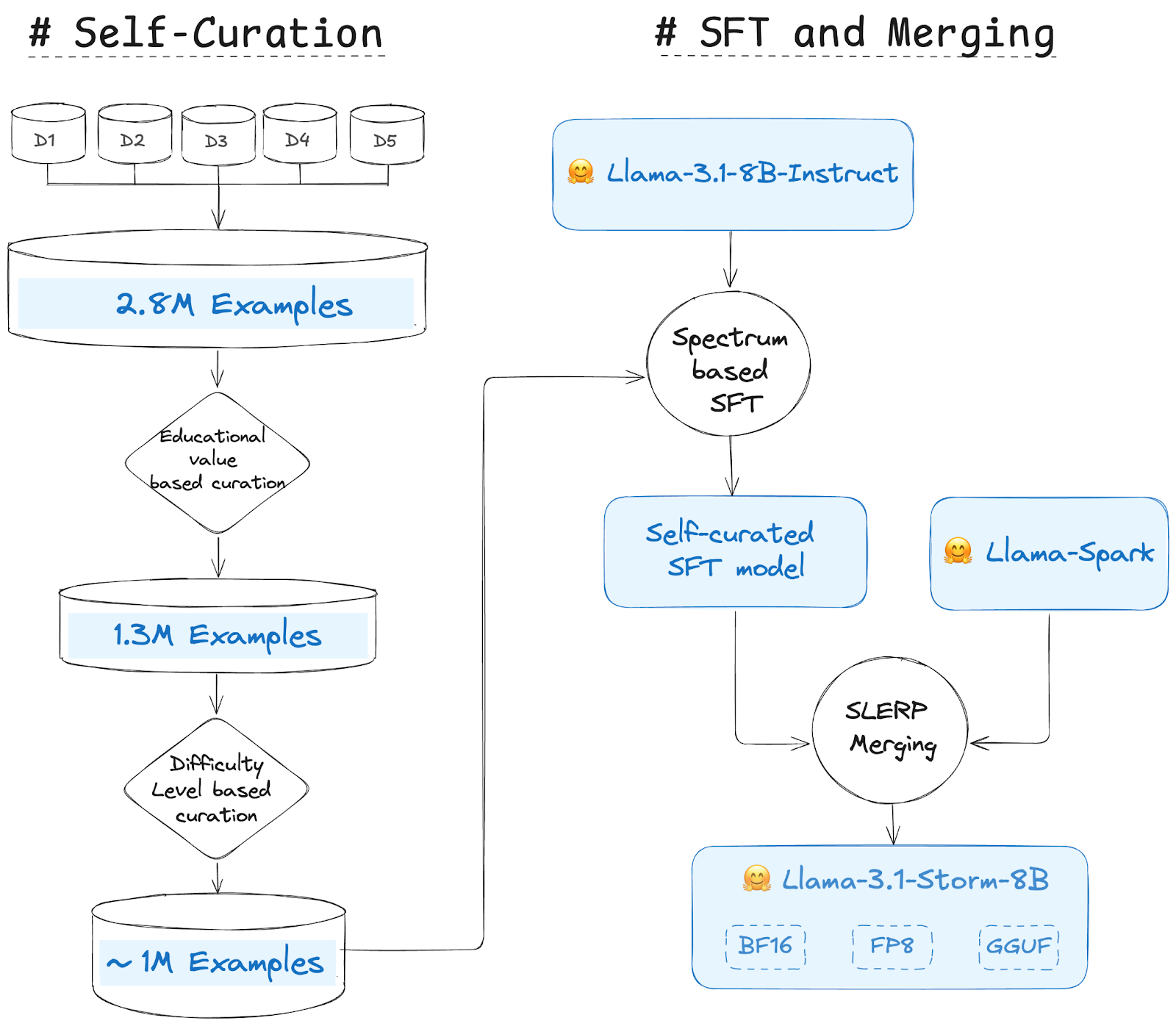
Self Curation
The Source Datasets used for Llama 3.1 Storm 8B are these 5 open-source datasets (The-Tome, agent-data, Magpie-Llama-3.1-Pro-300K-Filtered, openhermes_200k_unfiltered, Llama-3-Magpie-PO-100K-SML). The combined datasets contain a total of ~2.8M examples. Each example in data curation is given a value or values, and selection judgements are then made depending on the value or values assigned to each sample. To assign such value(s), LLM or machine learning models are typically utilized. Using LLM, numerous approaches exist to put a value on an example. Education value and difficulty level are two of the most often used metrics for evaluating the examples.
The worth or informativeness of the example (instruction + answer) is determined by its education value and the degree of difficulty by its difficulty level. The education value is between 1 and 5, where 1 is the least educational and 5 is the most instructive. There are 3 difficulty levels – Easy, Medium, and Hard. The objective is to enhance SLM within the context of self-curation; hence, we concentrated on applying the same model – Use Llama-3.1-8B-Instruct rather than Llama-3.1-70B-Instruct, Llama-3.1-405B-Instruct, and other bigger LLMs.
Self Curation Steps:
- Step 1: Education Value-based Curation—They used Llama 3.1 Instruct 8B to assign an education value (1-5) to all the examples(~2.8M). Then, they selected the samples with a score greater than 3. They followed the approach of the FineWeb-Edu dataset. This step reduced the total examples to 1.3M from 2.8 M.
- Step 2: Difficulty level based Curation – We follow the similar approach and use Llama 3.1 Instruct 8B to assign a difficulty level (Easy, Medium and Hard) to 1.3M examples from before step. After some experiments they selected Medium and Hard level examples. This strategy is similar to the data pruning described in the Llama-3.1 technical report. There were ~650K and ~325K examples of medium and hard difficulty-level respectively.
The Final Curated Dataset contained ~975K examples. Then, 960K and 15K were split for training and validation, respectively.
Targeted Supervised Instruction Fine-Tuning
The Self Curation model, fine-tuned on the Llama-3.1-8B-Instruct model with ~960K examples over 4 epochs, employs Spectrum, a method that accelerates LLM training by selectively targeting layer modules based on their signal-to-noise ratio (SNR) while freezing the rest. Spectrum effectively matches full fine-tuning performance with reduced GPU memory usage by prioritizing layers with high SNR and freezing 50% of layers with low SNR. Comparisons with methods like QLoRA demonstrate Spectrum’s superior model quality and VRAM efficiency in distributed environments.
Model Merging
Since Model merging has led to some state-of-the-art models, they have decided to merge the self-curated fine, fine-tuned model with the Llama Spark model, which is a derivative of Llama 3.1 8B Instruct. They used the SLERP method to merge the two models, creating a blended model that captures the essence of both parents through smooth interpolation. Spherical Linear Interpolation (SLERP) ensures a constant rate of change while preserving the geometric properties of the spherical space, allowing the resultant model to maintain key characteristics from both parent models. We can see the benchmarks that the Self-Curation SFT Model performs better than the Llama-Spark model on average. However, the merged model performs even better than either of the two models.
Impact of Self-Curation and Model Merging
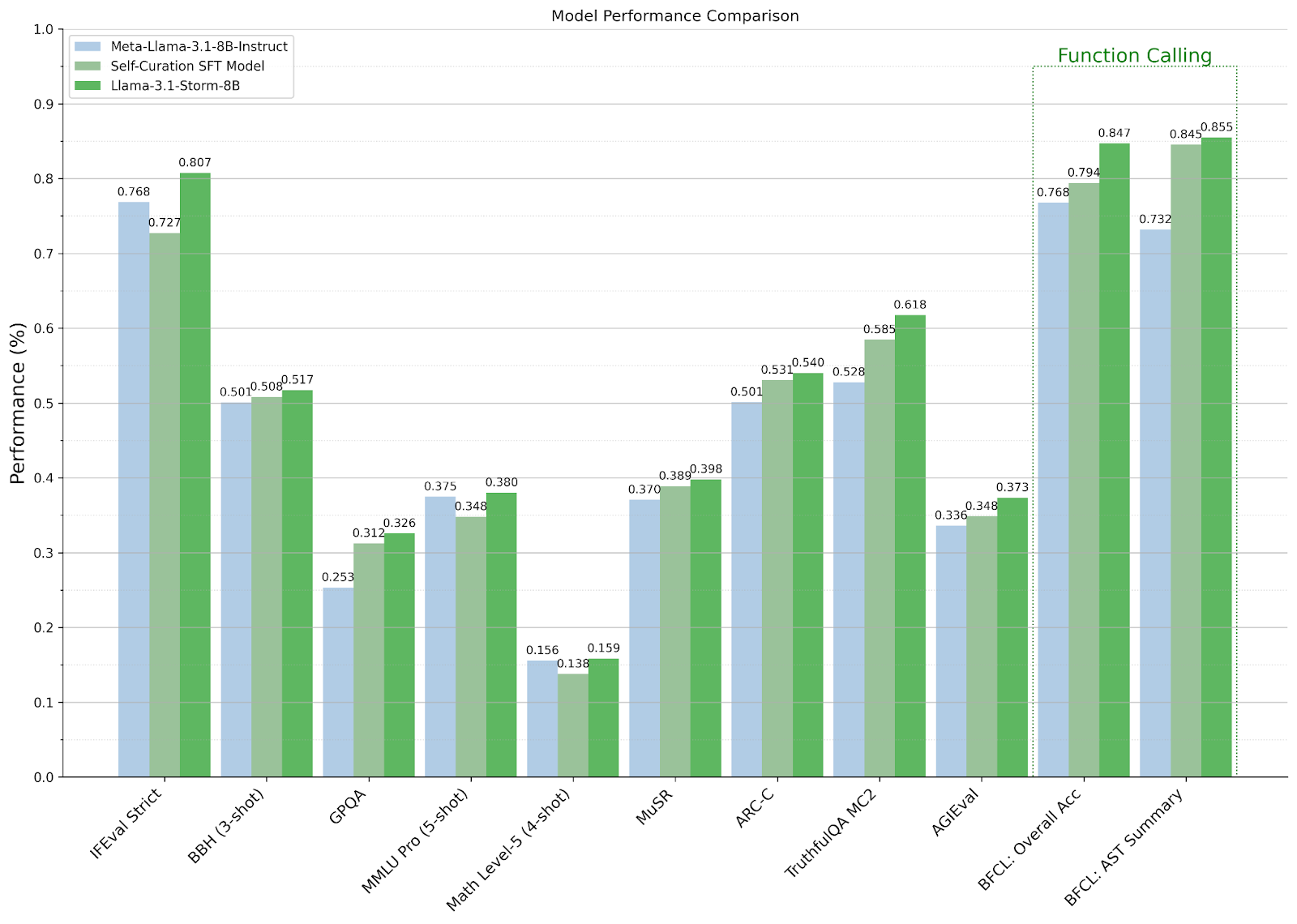
As the figure above shows, the self-curation-based SFT strategy surpasses Llama-3.1-8B-Instruct on 7 out of 10 benchmarks, highlighting the importance of selecting high-quality examples. These results also suggest that choosing the right combined model can improve performance even more among the assessed benchmarks.
How to use Llama 3.1 Storm 8B Model
We will use the transformers library from Hugging Face to use the Llama 3.1 Storm 8B Model. By default, transformers load the model in bfloat16, which is the type used when fine-tuning. It is recommended that you use it.
Method 1: Use Transformers Pipeline
1st Step: Installation of required libraries
!pip install --upgrade "transformers>=4.43.2" torch==2.3.1 accelerate flash-attn==2.6.32nd Step: Load the Llama 3.1 Storm 8B Model
import transformers
import torch
model_id = "akjindal53244/Llama-3.1-Storm-8B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)3rd Step: Create a utility method to create the model input
def prepare_conversation(user_prompt):
# Llama-3.1-Storm-8B chat template
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_prompt}
]
return conversation4th Step: Get the output
# User query
user_prompt = "What is the capital of Spain?"
conversation = prepare_conversation(user_prompt)
outputs = pipeline(conversation, max_new_tokens=128, do_sample=True, temperature=0.01, top_k=100, top_p=0.95)
response = outputs[0]['generated_text'][-1]['content']
print(f"Llama-3.1-Storm-8B Output: {response}")
Method 2: Using Model, tokenizer, and model.generate API
1st Step: Load Llama 3.1 Storm 8B model and tokenizer
import torch
from transformers import AutoTokenizer, LlamaForCausalLM
model_id = 'akjindal53244/Llama-3.1-Storm-8B'
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=False,
use_flash_attention_2=False # Colab Free T4 GPU is an old generation GPU and does not support FlashAttention. Enable if using Ampere GPUs or newer such as RTX3090, RTX4090, A100, etc.
)2nd Step: Apply Llama-3.1-Storm-8B chat-template
def format_prompt(user_query):
template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"""
return template.format(user_query)3rd Step: Get the output from the model
# Build final input prompt after applying chat-template
prompt = format_prompt("What is the capital of France?")
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=128, temperature=0.01, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True)
print(f"Llama-3.1-Storm-8B Output: {response}")
Conclusion
Llama 3.1 Storm 8B represents a significant step forward in developing efficient and powerful language models. It demonstrates that smaller models can achieve impressive performance through innovative training and merging techniques, opening up new possibilities for AI research and application development. As the field continues to evolve, we expect to see further refinements and applications of these techniques, potentially democratizing access to advanced AI capabilities.
Dive into the future of AI with GenAI Pinnacle. Empower your projects with cutting-edge capabilities, from training bespoke models to tackling real-world challenges like PII masking. Start Exploring.
I hope you find this article on Llama 3.1 Storm 8B and Hermes Llama 3.1 informative. It provides insights into how Llama 3.1 compares to Llama 3.1 8B GGUF, highlighting improvements in instruction-following and reasoning capabilities. Enjoy reading! Let me know if you need any further adjustments!
Q1. What is Llama 3.1 Storm 8B?
Ans. Llama 3.1 Storm 8B is an improved small language model (SLM) with 8 billion parameters, built upon Meta AI’s Llama 3.1 8B Instruct model using self-curation, targeted fine-tuning, and model merging techniques.
Q2. How does Llama 3.1 Storm 8B compare to other models?
Ans. It outperforms both Meta’s Llama 3.1 8B Instruct and Hermes-3-Llama-3.1-8B across various benchmarks, showing significant improvements in areas like instruction following, knowledge-driven QA, reasoning, and function calling.
Q3. What techniques were used to create Llama 3.1 Storm 8B?
Ans. The model was created using a three-step process: self-curation of training data, targeted fine-tuning using the Spectrum method, and model merging with Llama-Spark using the SLERP technique.
Q4. How can developers use Llama 3.1 Storm 8B?
Ans. Developers can easily integrate the model into their projects using popular libraries like Transformers and vLLM. It’s available in multiple formats (BF16, FP8, GGUF) and can be used for various tasks, including conversational AI and function calling.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.







