Introduction
Large Language Models (LLMs) have demonstrated unparalleled capabilities in natural language processing, yet their substantial size and computational requirements hinder their deployment. Quantization, a technique to reduce model size and computational cost, has emerged as a critical solution. This paper provides a comprehensive overview of LLM quantization, delving into various quantization methods, their impact on model performance, and their practical applications across diverse domains. We further explore the challenges and opportunities in LLM quantization, offering insights into future research directions.

Overview
- A comprehensive examination of how quantization can reduce the computational demands of Large Language Models (LLMs) without significantly compromising their performance.
- Tracing the rapid advancements in LLMs and the consequent challenges posed by their substantial size and resource requirements.
- An exploration of quantization as a technique to discretize continuous values, focusing on its application in reducing LLM complexity.
- A detailed look at different quantization methods, including post-training quantization and quantization-aware training, and their impact on model performance.
- Highlighting the potential of quantized LLMs in various domains like edge computing, mobile applications, and autonomous systems.
- Discussing the trade-offs, hardware considerations, and the need for continued research to enhance the efficiency and applicability of LLM quantization.
Table of contents
Advent of Large Language Model
The advent of LLMs has marked a significant leap in natural language processing, enabling groundbreaking applications in various fields. However, due to their immense size and computational intensity, deploying these models on resource-constrained devices remains a formidable challenge. Quantization, a technique to reduce model complexity while preserving performance, offers a promising avenue to address this limitation.
This paper comprehensively explores LLM quantization, encompassing its theoretical underpinnings, practical implementation, and real-world applications. By delving into the nuances of different quantization methods, their impact on model performance, and the challenges associated with their deployment, we aim to offer a holistic understanding of this critical technique.
LLM Quantization: A Deep Dive
Understanding Quantization
Quantization is a process of mapping continuous values to discrete representations, typically with a lower bit-width. In the context of LLMs, it involves reducing the precision of weights and activations from floating-point to lower-bit integer or fixed-point formats. This reduction leads to smaller model sizes, faster inference speeds, and decreased memory footprint.
Quantization Techniques
- Post-training Quantization:
- Uniform quantization: Maps floating-point values to a fixed number of quantization levels.
- Concept: Maps a continuous range of floating-point values to a fixed set of discrete quantization levels.
Visual Representation
Explanation: Divide the floating-point values into equal-sized bins and map each value to the midpoint of its corresponding bin. The number of bins determines the quantization level (e.g., 8-bit quantization has 256 levels). This method is simple but can lead to quantization errors, especially for distributions with long tails.

continuous number line (floatingpoint values) with evenly spaced quantization levels below it. Arrows indicate the mapping of floatingpoint values to their nearest quantization level.
Explanation:
- The continuous range of floating-point values is divided into equal intervals.
- A single quantization level represents each interval.
- Values within an interval are rounded to the nearest quantization level.
- Dynamic quantization: Adapts quantization parameters during inference based on input statistics.
- Concept: Adapt quantization parameters based on input statistics during inference.

Explanation: Unlike uniform quantization, dynamic quantization adjusts the quantization range based on the actual values encountered during inference. This can improve accuracy but requires additional computational overhead.
- Weight clustering: Groups weights into clusters and represents each cluster with a central value.
- Concept: Groups are weighted into clusters and represent each cluster with a central value.

Explanation: Weights are clustered based on their values. A central value represents each cluster, and the original weights are replaced with their corresponding cluster centers. This reduces the number of unique weights in the model, leading to memory savings and potential computational efficiency gains.
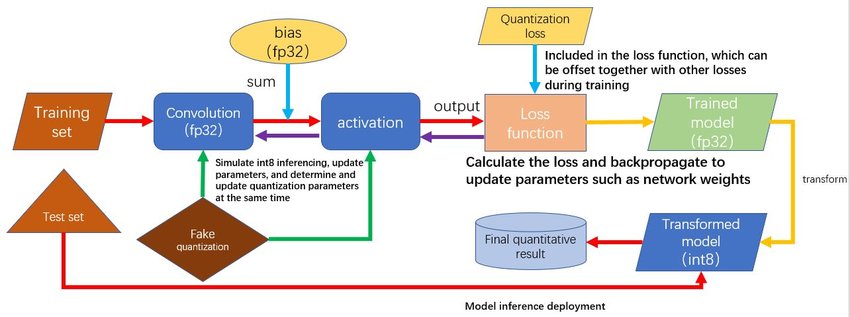
- Quantization-Aware Training (QAT):
- Integrates quantization into the training process, leading to improved performance.
- Techniques include simulated quantization, straight-through estimator (STE), and differentiable quantization.
Also read: What are Large Language Models(LLMs)?
Impact of Quantization on Model Performance
Quantization inevitably introduces some performance degradation. However, the extent of this degradation depends on several factors:
- Model Architecture: Deeper and wider models are generally more resilient to quantization.
- Dataset Size and Complexity: Larger and more complex datasets can mitigate performance loss.
- Quantization Bitwidth: Lower bitwidths result in larger performance drops.
- Quantization Method: The choice of quantization method significantly impacts performance.
Evaluation Metrics
To assess the impact of quantization, various metrics are employed:
- Accuracy: Measures the model’s performance on a given task (e.g., classification accuracy, BLEU score).
- Model Size: Quantifies the reduction in model size.
- Inference Speed: Evaluates the speedup achieved through quantization.
- Energy Consumption: Measures the power efficiency of the quantized model.
Also read: Beginner’s Guide to Build Large Language Models from Scratch
Use Cases of Quantized LLMs
Quantized LLMs have the potential to revolutionize numerous applications:
- Edge Computing: Deploying LLMs on resource-constrained devices for real-time applications.
- Mobile Applications: Enhancing the performance and efficiency of mobile apps.
- Internet of Things (IoT): Enabling intelligent capabilities on IoT devices.
- Autonomous Systems: Reducing computational costs for real-time decision-making.
- Natural Language Understanding (NLU): Accelerating NLU tasks in various domains
Python Code Snippet that leverages PyTorch for reducing computational costs in real-time decision-making for autonomous systems use case:
# PyTorch Model
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms
from torch.utils.data import DataLoader
# Step 1: Define the Model
class AutonomousModel(nn.Module):
def __init__(self, num_classes=10):
super(AutonomousModel, self).__init__()
# Using a pre-trained MobileNetV2 model for efficiency
self.model = models.mobilenet_v2(pretrained=True)
# Replace the last layer with a layer matching the number of classes
self.model.classifier[1] = nn.Linear(self.model.last_channel, num_classes)
def forward(self, x):
return self.model(x)
# Step 2: Define Data Transformation and DataLoader
# Use a simple transformation with normalization and resizing
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# Assuming you have a dataset for autonomous system input (e.g., images from sensors)
# dataset = YourDataset(transform=transform)
# dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Step 3: Initialize Model, Loss Function, and Optimizer
model = AutonomousModel(num_classes=10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Step 4: Quantization Preparation
# This step is crucial for reducing computational costs
model.fuse_model() # Fuse Conv2d + BatchNorm2d + ReLU layers
model.qconfig = torch.quantization.get_default_qconfig('fbgemm') # Select quantization configuration
torch.quantization.prepare(model, inplace=True)
# Step 5: Train or Fine-tune the Model
# Note: For the sake of simplicity, we skip the training loop and assume the model is already trained
# Step 6: Convert the Model to a Quantized Version
torch.quantization.convert(model, inplace=True)
# Step 7: Inference with Quantized Model
# The quantized model is now much faster and lighter for real-time decision-making
model.eval()
with torch.no_grad():
# Example input tensor representing sensor data
example_input = torch.randn(1, 3, 224, 224) # Batch size of 1, 3 channels, 224x224 image
output = model(example_input)
# Make decision based on the output
decision = torch.argmax(output, dim=1)
print(f"Decision: {decision.item()}")
# Save the quantized model for deployment
torch.save(model.state_dict(), 'quantized_autonomous_model.pth')Explanation:
- Model Definition:
- We use a pre-trained MobileNetV2, which is efficient for embedded systems and real-time applications.
- The last layer is replaced to match the number of classes for the specific task.
- Data Transformation:
- Transform the input data into a format suitable for the model, including resizing and normalization.
- Quantization Preparation:
- Model Fusion: Layers like Conv2d, BatchNorm2d, and ReLU are fused to reduce computation.
- Quantization Configuration: We select a quantization configuration (fbgemm) optimized for x86 CPUs.
- Model Conversion:
- After preparing the model, we convert it to its quantized version, significantly reducing its size and improving inference speed.
- Inference:
- The quantized model is used to make real-time decisions. Inference is performed on a sample input, and the output is used for decision-making.
- Saving the Model:
- The quantized model is saved for deployment, ensuring the system can operate efficiently in real time.
Also read: A Survey of Large Language Models (LLMs)
Challenges of LLM Quantization
Despite its potential, LLM quantization faces several challenges:
- Performance-Accuracy Trade-off: Balancing model size reduction with performance degradation.
- Hardware Acceleration: Developing specialized hardware for efficient quantization operations.
- Quantization for Specific Tasks: Tailoring quantization techniques for different tasks and domains.
Future research should focus on:
- Developing novel quantization techniques with minimal performance loss.
- Exploring hardware-software co-design for optimized quantization.
- Investigating the impact of quantization on different LLM architectures.
- Quantifying the environmental benefits of LLM quantization.
Conclusion
LLM quantization is critical for deploying large-scale language models on resource-constrained platforms. By carefully considering quantization methods, evaluation metrics, and application requirements, practitioners can effectively leverage this technique to achieve optimal performance and efficiency. As research in this area progresses, we can anticipate even greater advancements in LLM quantization, unlocking new possibilities for AI applications across various domains.
Frequently Asked Questions
Q1. What is LLM Quantization?
Ans. LLM Quantization reduces the precision of model weights and activations to lower-bit formats, making models smaller, faster, and more memory-efficient.
Q2.What are the main quantization methods?
Ans. The primary methods are Post-Training Quantization (uniform and dynamic) and Quantization-Aware Training (QAT).
Q3. What challenges does LLM Quantization face?
Ans. Challenges include balancing performance and accuracy, the need for specialized hardware, and task-specific quantization techniques.
Q4. How does quantization affect model performance?
Ans. Quantization can degrade performance, but the impact varies with model architecture, dataset complexity, and the bitwidth used.





