Introduction
In today’s data-driven world, Swiggy, a leading player in India’s food delivery industry, is transforming how its team accesses and interprets data with Hermes, a generative AI tool. Recognizing the need for timely and accurate information for informed decision-making, Swiggy developed Hermes to make data retrieval fast and accessible across the organization.
Unlike many AI tools that focus on summarizing text, Hermes is designed to deliver precise numbers and detailed insights crucial for business decisions. Whether it’s assessing the impact of a telco outage on customer notifications or analyzing customer claims within a restaurant cohort, Hermes allows Swiggy’s teams to pose questions in natural language and instantly receive both SQL queries and results within Slack. This innovation empowers users with actionable insights, streamlining data access without requiring extensive technical expertise.

Overview
- Swiggy developed Hermes, an AI-based workflow, to make data access and interpretation faster and more efficient for teams.
- Hermes allows users to pose natural language questions and instantly receive SQL queries and results within Slack.
- The introduction of Hermes V2 refined the system with a compartmentalized approach, improving data flow and query accuracy.
- Hermes V2 utilizes a Knowledge Base and Retrieval-Augmented Generation (RAG) to enhance context and precision in SQL generation.
- Since its launch, Hermes has been widely adopted across Swiggy, significantly reducing the time needed for data-driven decisions.
- Hermes empowers product managers, data scientists, and analysts by streamlining data retrieval and enabling deeper insights with minimal technical expertise.
Table of contents
The Challenge of Swiggy
Swiggy encountered a challenge familiar to many organizations: providing employees from diverse departments with the ability to access crucial data without heavily relying on technical experts. Traditionally, obtaining specific business insights involved navigating through reports, crafting complex SQL queries, or waiting for an analyst to extract the data—tasks that could be both time-consuming and cumbersome. Such inefficiencies delayed decision-making and risked decisions based on incomplete or incorrect data.
Introducing Hermes
To overcome these hurdles, Swiggy developed Hermes, a sophisticated generative AI solution integrated with Slack. This innovative tool allows employees to pose questions in natural language and receive both the SQL queries and their results in real-time. For instance, a product manager might ask, “What was the average rating for orders delivered 5 minutes earlier than promised last week in Bangalore?” and promptly get the SQL query and data needed.
Previously, answering such a query could take minutes to days, depending on its complexity and resource availability. Hermes dramatically shortens this timeframe, enabling Swiggy’s teams to make swifter, data-driven decisions and boost overall productivity.
We have taken reference from this article by Amaresh M: Click Here.
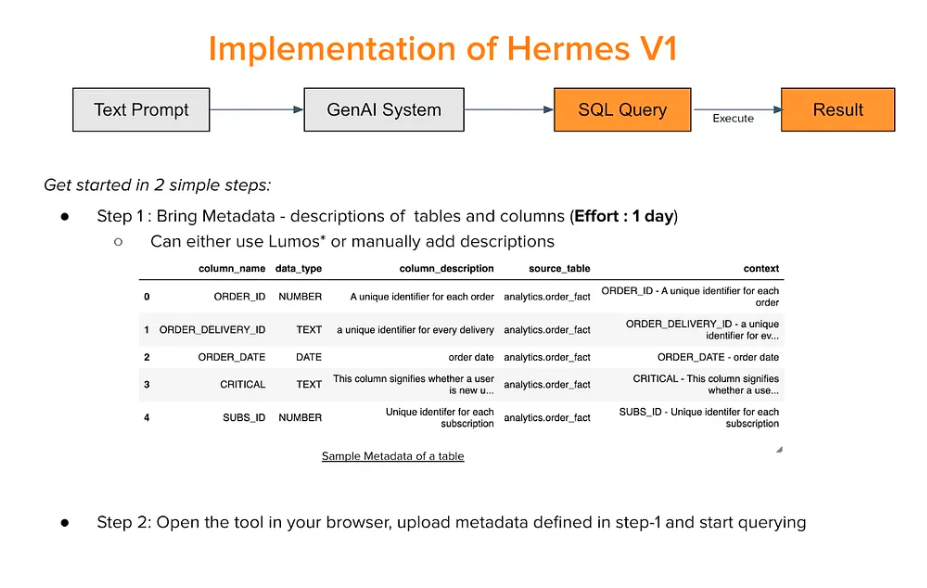
Hermes V1: The Foundation
The first version of Hermes, or Hermes V1, was a straightforward implementation using GPT-3.5 variants. Users could bring their metadata, type a prompt in Slack, and receive a generated SQL query along with the results. Although the results were promising and aligned with industry benchmarks, Swiggy quickly realized the need for a more tailored solution. The complexity of users’ queries and the vast volume of data necessitated a more specialized approach.
Swiggy’s learnings from Hermes V1 led to a critical design decision: Compartmentalizing Hermes into distinct business units or “charters,” each with its own metadata and specific use cases. This approach recognized that tables and metrics related to different Swiggy services, like Food Marketplace and Instamart, while similar, needed to be treated separately to optimize performance.
Hermes V2: A Refined Approach
Building on the insights gained from Hermes V1, Swiggy introduced Hermes V2, featuring an improved data flow and a more robust implementation. The revamped system includes several key components:
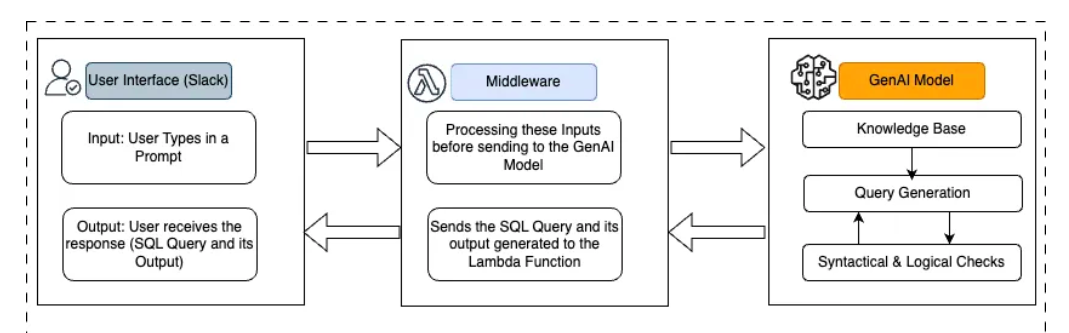
1. User Interface
Slack continues to serve as the entry point, where users type prompts and receive both SQL queries and results.
2. Middleware (AWS Lambda)
This intermediary layer facilitates communication between the user interface and the generative AI model, processing and formatting inputs before sending them to the model.
3. Generative AI Model
Upon receiving a request, a new Databricks job fetches the relevant charter’s generative AI model, generates the SQL query, executes it, and returns both the query and its output.
4. Knowledge Base + RAG Approach
This approach helps the model incorporate Swiggy-specific context, ensuring the correct tables and columns are selected for each query.
Generative AI Model Pipeline
Swiggy’s implementation of a Generative AI model pipeline employs a Knowledge Base combined with a Retrieval-Augmented Generation (RAG) approach. This method is instrumental in embedding Swiggy-specific context, guiding the AI model to accurately identify and select the appropriate tables and columns for each query.
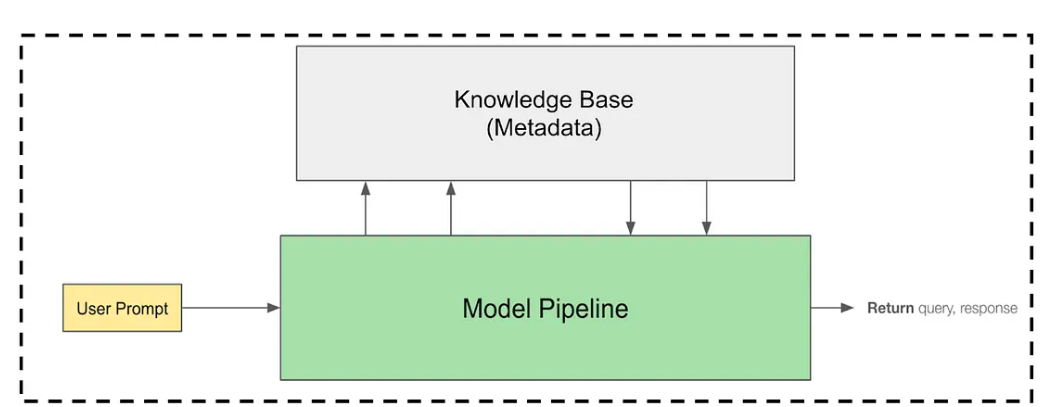
5. Knowledge Base
This pipeline’s core is a comprehensive Knowledge Base, which stores key metadata for each specific business unit or “charter” within Swiggy, such as Swiggy Food or Swiggy Genie. This metadata includes essential information like metrics, tables, columns, and reference SQL queries. The importance of metadata in a Text-to-SQL model cannot be overstated, as it serves several critical functions:
- Contextual Understanding
Metadata provides the model with crucial information about the data structure, such as table names, column names, and descriptions. This context is vital for the model to map natural language queries to the correct database structures accurately.
- Disambiguation
Human language is often ambiguous and context-dependent. Metadata helps clarify terms, ensuring the model generates SQL queries accurately reflecting the user’s intent. For example, it can distinguish whether “sales” refers to a specific table, a column within a table, or another entity.
- Accuracy
Detailed metadata significantly enhances the accuracy of the generated SQL queries. A thorough understanding of the data schema makes the model less likely to produce errors, reducing the need for manual corrections.
- Scalability
A robust and standardized set of metadata allows the Text-to-SQL model to scale effectively across different databases and data sources. This scalability enables the model to adapt to new datasets without requiring extensive reconfiguration, ensuring it meets Swiggy’s evolving data needs.
The Model Pipeline
The improved model pipeline in Hermes V2 is designed to break down the user prompt into several stages, ensuring clean and relevant information is passed for the final query generation.
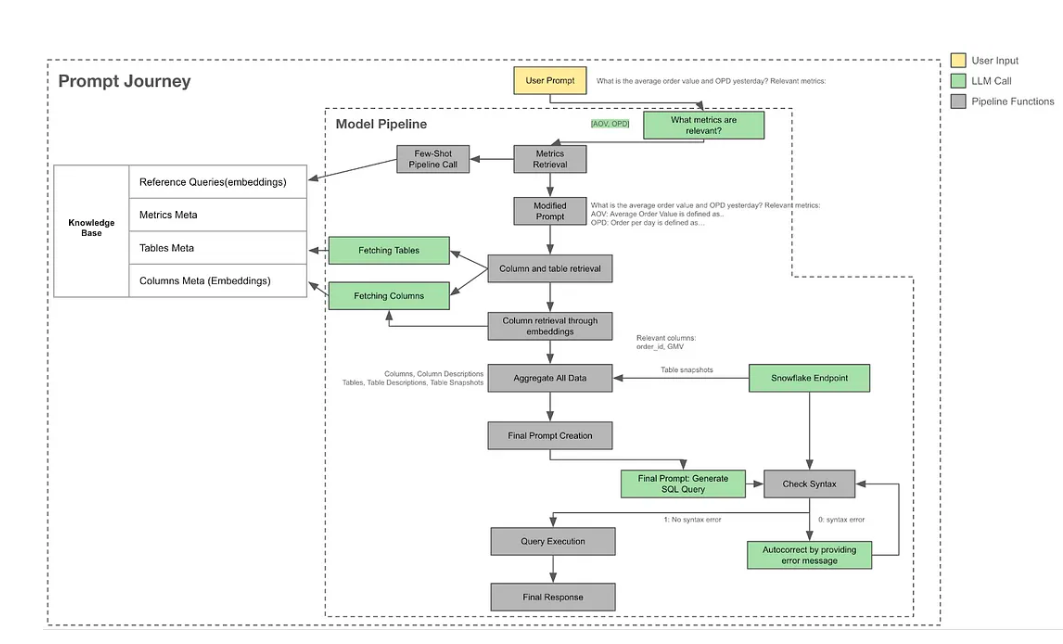
These stages include:
- Metrics Retrieval: The first stage retrieves relevant metrics to understand the user’s question. This involves leveraging the knowledge base to fetch associated queries and historical SQL examples through embedding-based vector lookup.
- Table and Column Retrieval: The next stage uses metadata descriptions to identify the necessary tables and columns. This process combines LLM querying, filtering, and vector-based lookup. For tables with a large number of columns, multiple LLM calls are made to avoid token limits. Additionally, vector search matches column descriptions with user questions and metrics, identifying all relevant columns.
- Few-Shot SQL Retrieval: Swiggy maintains ground-truth, verified, or reference queries for several key metrics. A vector-based few-shot retrieval method fetches relevant reference queries to aid in the generation process.
- Structured Prompt Creation: The system compiles all gathered information into a structured prompt, which includes querying the database and collecting data snapshots. The system then sends this structured prompt to the LLM for SQL generation.
- Query Validation: Swiggy validates the generated SQL query by running it on its database. If errors occur, they relay them to the LLM for correction with a set number of retries. Once they obtain an executable SQL query, they run it and relay the results back to the user. If retries fail, they share the query and modification notes with the user.
Adoption and Impact
Hermes has quickly become a vital tool across Swiggy, with hundreds of users leveraging it to handle thousands of queries in under two minutes on average. Product managers use Hermes for swift metrics checks and post-release validations, while data scientists and analysts depend on it for detailed investigations and trend analyses.
The success of Hermes V2 highlights the critical role of well-defined metadata and a tailored approach in data management. By organizing data by charter and continuously refining its knowledge base, Swiggy has developed a robust tool that democratizes data access and significantly enhances team productivity.
Swiggy Hermes: Looking Forward
Swiggy’s ongoing innovation with Hermes sets a new benchmark for how businesses can harness generative AI to transform data accessibility. With a commitment to continual improvement and incorporating user feedback, Hermes is well-positioned to become a cornerstone of Swiggy’s data-driven decision-making process, ensuring the company remains at the forefront of the rapidly evolving food delivery industry.
Our Opinion
Swiggy’s approach with Hermes exemplifies how generative AI can streamline data processes and empower teams. By addressing specific business needs with a tailored solution, Swiggy has enhanced operational efficiency and set a precedent for leveraging AI in practical, impactful ways. It’s exciting to see how such innovations can shape the future of data accessibility and decision-making in the industry.
Conclusion
Swiggy’s journey with Hermes underscores the importance of making data accessible and actionable for all users. With the successful rollout of Hermes V2, Swiggy has improved its internal processes and set a new standard for how companies can democratize data access across their organizations. As Hermes continues to evolve, it promises further to enhance the speed and accuracy of decision-making at Swiggy, enabling teams to unlock the full potential of their data.
Dive into the future of AI with GenAI Pinnacle. Empower your projects with cutting-edge capabilities, from training bespoke models to tackling real-world challenges like PII masking. Start Exploring.
Frequently Asked Questions
Q1. What is Hermes, and how does it benefit Swiggy’s teams?
Ans. Hermes is Swiggy’s in-house developed generative AI-based workflow designed to allow users to ask data-related questions in natural language and receive both a SQL query and its results directly within Slack. It streamlines data access, enabling faster, more efficient decision-making by reducing the dependency on technical resources and minimizing the time needed to retrieve actionable insights.
Q2. How does Hermes V2 differ from Hermes V1?
Ans. Hermes V2 improves upon the initial version by compartmentalizing the system according to distinct business units (charters) within Swiggy. It incorporates a Knowledge Base and RAG-based approach to generate more accurate and contextually relevant SQL queries. This version also features a more refined model pipeline that breaks down user prompts into specific stages, such as metrics retrieval and query validation, to ensure clean and relevant data for query generation.
Q3. What is the role of the Knowledge Base in Hermes?
Ans. The Knowledge Base in Hermes stores critical metadata for each business unit, including metrics, tables, columns, and reference SQL queries. This metadata provides essential context to the AI model, helping it accurately translate natural language queries into SQL commands. It also assists in disambiguating terms, improving accuracy, and ensuring the system can scale across different data sources.
Q4. Why is metadata so crucial in the Hermes AI model?
Ans. Metadata is crucial because it provides the AI model with the context to accurately map natural language queries to database structures. It helps disambiguate terms, improves the precision of SQL query generation, and supports the model’s scalability across different datasets. Detailed metadata reduces errors and enhances the overall performance of the system.
Q5. How has Hermes been adopted within Swiggy?
Ans. Hermes has seen widespread adoption across Swiggy, with hundreds of users leveraging it to answer thousands of data-related queries. The system is precious for product managers, business teams, data scientists, and analysts, helping them perform tasks such as sizing numbers for initiatives, post-release validations, trend tracking, and in-depth data investigations, all with an average turnaround time of under 2 minutes.
Hi, I am Janvi, a passionate data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.





