Introduction
Text-to-image synthesis and image-text contrastive learning are two of the most innovative multimodal learning applications recently gaining popularity. With their innovative applications for creative image creation and manipulation, these models have revolutionized the research community and drawn significant public interest.
In order to do further research, DeepMind introduced Imagen. This text-to-image diffusion model offers unprecedented photorealism and a profound understanding of language in text-to-image synthesis by fusing the strength of transformer language models (LMs) with high-fidelity diffusion models.
This article describes the training and assessment of Google’s newest Imagen model, Imagen 3. Imagen 3 can be configured to output images at 1024 × 1024 resolution by default, with the option to apply 2×, 4×, or 8× upsampling afterward. We outline our analyses and assessments in comparison to other cutting-edge T2I models.
We discovered that Imagen 3 is the best model. It excels at photorealism and following intricate and lengthy user instructions.

Overview
- Revolutionary Text-to-Image Model: Google’s Imagen 3, a text-to-image diffusion model, delivers unmatched photorealism and precision in interpreting detailed user prompts.
- Evaluation and Comparison: Imagen 3 excels in prompt-image alignment and visual appeal, surpassing models like DALL·E 3 and Stable Diffusion in both automated and human evaluations.
- Dataset and Safety Measures: The training dataset undergoes stringent filtering to remove low-quality or harmful content, ensuring safer, more accurate outputs.
- Architectural Brilliance: Using a frozen T5-XXL encoder and multi-step upsampling, Imagen 3 generates highly detailed images up to 1024 × 1024 resolution.
- Real-World Integration: Imagen 3 is accessible via Google Cloud’s Vertex AI, making it easy to integrate into production environments for creative image generation.
- Advanced Features and Speed: With the introduction of Imagen 3 Fast, users can benefit from a 40% reduction in latency without compromising image quality.
Table of contents
- Dataset: Ensuring Quality and Safety in Training
- Architecture of Imagen
- Evaluation of Imagen Models
- Human Evaluation: How Raters Judged Imagen 3’s Output Quality?
- Automated Evaluation: Comparing Models with CLIP, Gecko, and VQAScore
- Qualitative Results: Highlighting Imagen 3’s Attention to Detail
- Inference on Evaluation
- Accessing Imagen 3 via Vertex AI: A Guide to Seamless Integration
- Frequently Asked Questions
Dataset: Ensuring Quality and Safety in Training
The Imagen model is trained using a large dataset that includes text, images, and related annotations. DeepMind used several filtration stages to guarantee quality and safety requirements. First, any images deemed dangerous, violent, or poor quality are removed. Next, DeepMind removed images created by AI to stop the model from picking up biases or artifacts frequently present in these kinds of images. DeepMind also employed down-weighting similar images and deduplication procedures to reduce the possibility of outputs overfitting certain training data points.
Every image in the dataset has a synthetic caption and an original caption derived from alt text, human descriptions, etc. Gemini models produce synthetic captions with different cues. To maximize the language diversity and quality of these synthetic captions, DeepMind used multiple Gemini models and instructions. DeepMind used various filters to eliminate potentially harmful captions and personally identifiable information.
Architecture of Imagen
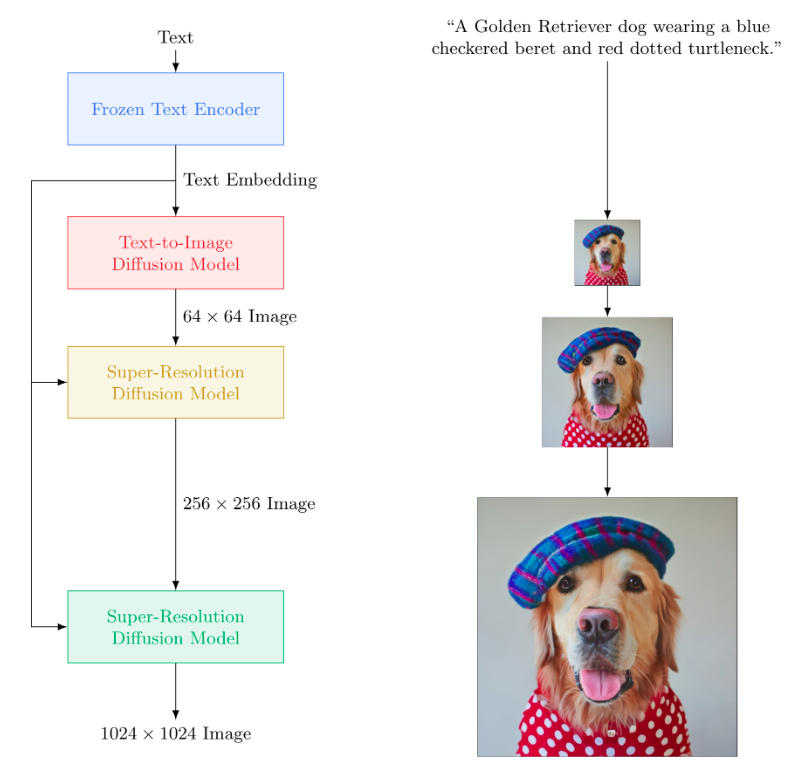
Imagen uses a large frozen T5-XXL encoder to encode the input text into embeddings. A conditional diffusion model maps the text embedding into a 64×64 image. Imagen further utilizes text-conditional super-resolution diffusion models to upsample the image 64×64→256×256 and 256×256→1024×1024.
Evaluation of Imagen Models
DeepMind evaluates the Imagen 3 model, which is the best quality configuration, against the Imagen 2 and the external models DALL·E 3, Midjourney v6, Stable Diffusion 3 Large, and Stable Diffusion XL 1.0. DeepMind found that Imagen 3 sets a new state of the art in text-to-image generation through rigorous evaluations by humans and machines. Qualitative Results and Inference on Evaluation contain qualitative results and a discussion of the overall findings and limitations. Product integrations with Imagen 3 may result in performance that is different from the configuration that was tested.
Also read: How to Use DALL-E 3 API for Image Generation?
Human Evaluation: How Raters Judged Imagen 3’s Output Quality?
The text-to-image generation model is evaluated on five quality aspects: overall preference, prompt-image alignment, visual appeal, detailed prompt-image alignment, and numerical reasoning. These aspects are independently assessed to avoid conflation in raters’ judgments. Side-by-side comparisons are used for quantitative judgment, while numerical reasoning can be evaluated directly by counting how many objects of a given type are depicted in an image.
The complete Elo scoreboard is generated through an exhaustive comparison of every pair of models. Each study consists of 2500 ratings uniformly distributed among the prompts in the prompt set. The models are anonymized in the rater interface, and the sides are randomly shuffled for every rating. Data collection is conducted using Google DeepMind’s best practices on data enrichment, ensuring all data enrichment workers are paid at least a local living wage. The study collected 366,569 ratings in 5943 submissions from 3225 different raters. Each rater participated in at most 10% of the studies and provided approximately 2% of the ratings to avoid biased results to a particular set of raters’ judgments. Raters from 71 different nationalities participated in the studies.
Overall User Preference: Imagen 3 Takes the Lead in Creative Image Generation
The overall preference of users regarding the generated image given a prompt is an open question, with raters deciding which quality aspects are most important. Two images were presented to raters, and if both were equally appealing, “I am indifferent.”
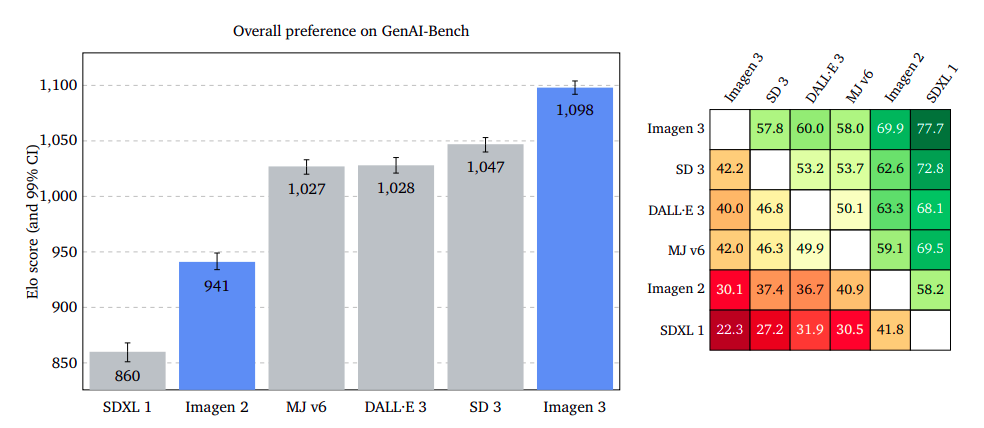
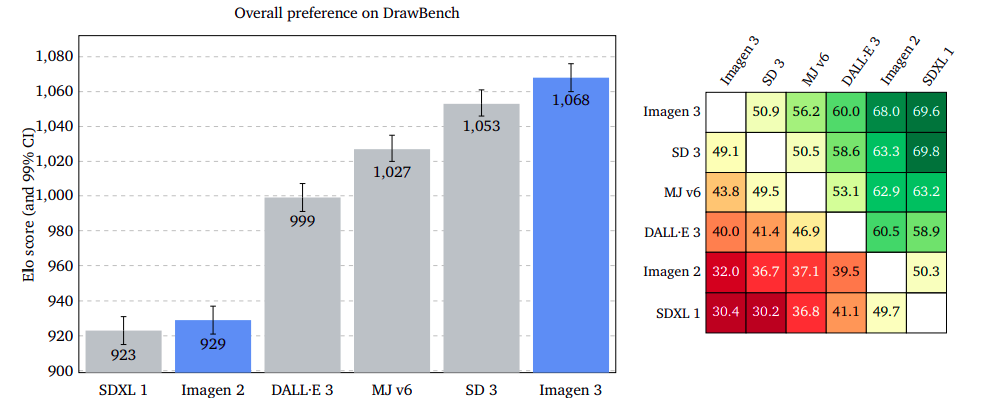
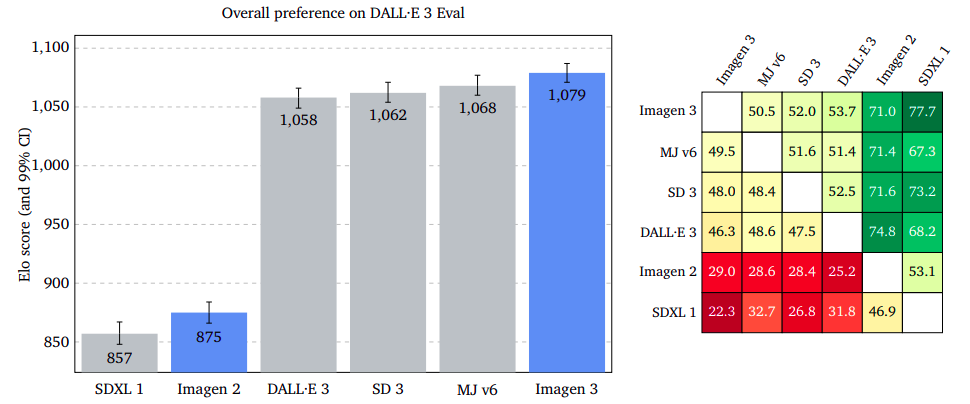
Results showed that Imagen 3 was significantly more preferred on GenAI-Bench, DrawBench, and DALL·E 3 Eval. Imagen 3 led with a smaller margin on DrawBench than Stable Diffusion 3, and it had a slight edge on DALL·E 3 Eval.
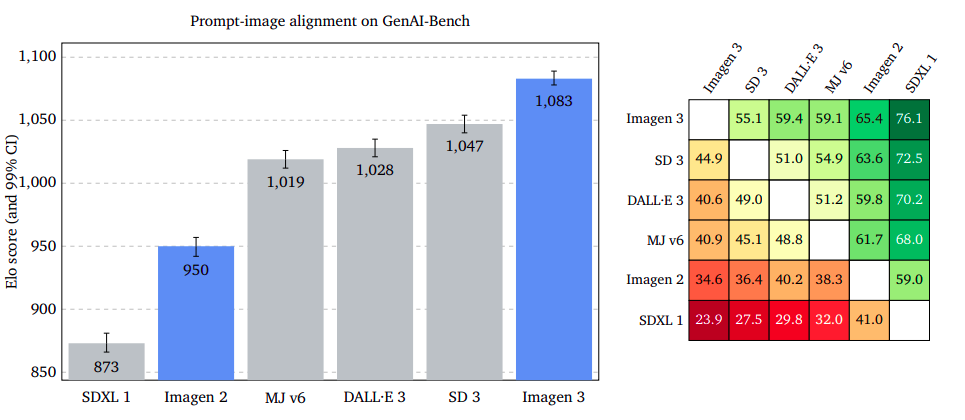
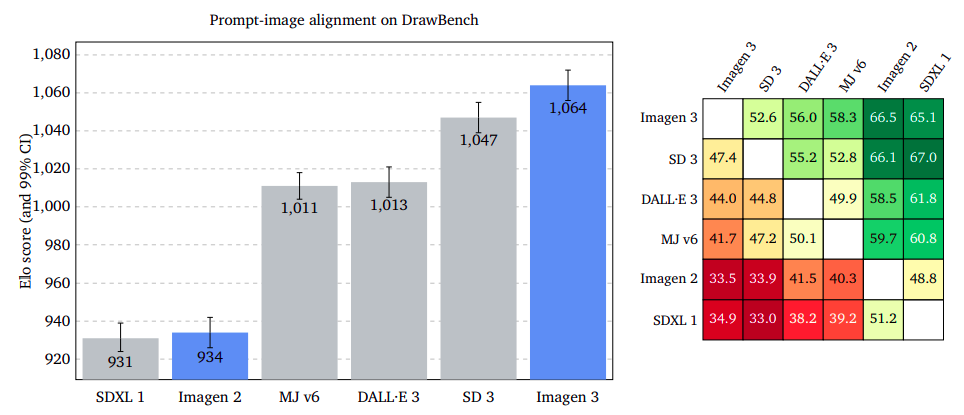
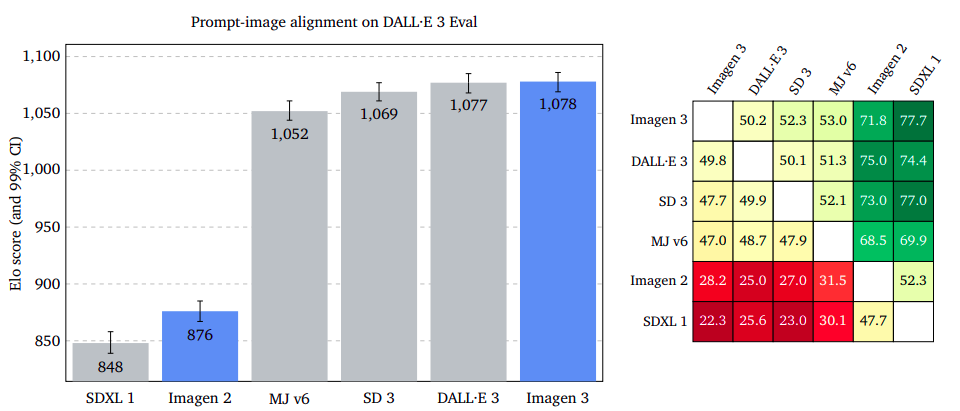
Prompt-Image Alignment: Capturing User Intent with Precision
The study evaluates the representation of an input prompt in an output image content, ignoring potential flaws or aesthetic appeal. Raters were asked to choose an image that better captures the prompt’s intent, disregarding different styles. Results showed Imagen 3 outperforms GenAI-Bench, DrawBench, and DALL·E 3 Eval, with overlapping confidence intervals. The study suggests that ignoring potential defects or bad quality in images can improve the accuracy of prompt-image alignment.
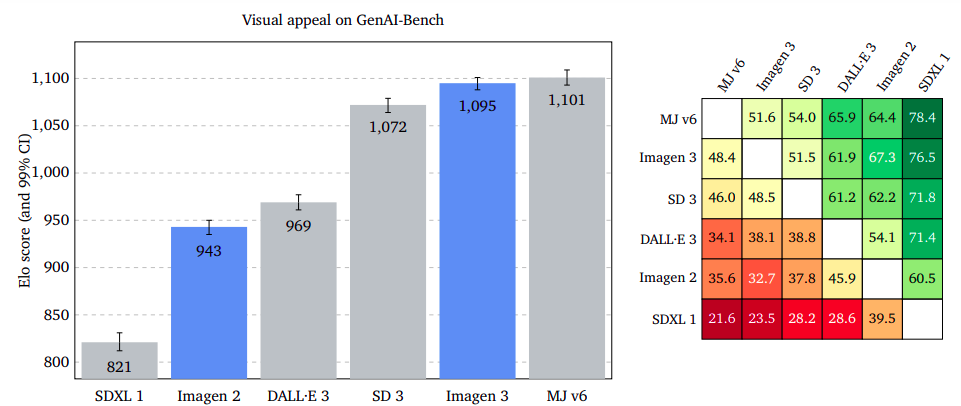
Visual Appeal: Aesthetic Excellence Across Platforms
Visual appeal measures the appeal of generated images, regardless of content. Raters rate two images side by side without prompts. Midjourney v6 leads, with Imagen 3 almost on par on GenAI-Bench, slightly bigger on DrawBench, and a significant advantage on DALL·E 3 Eval.
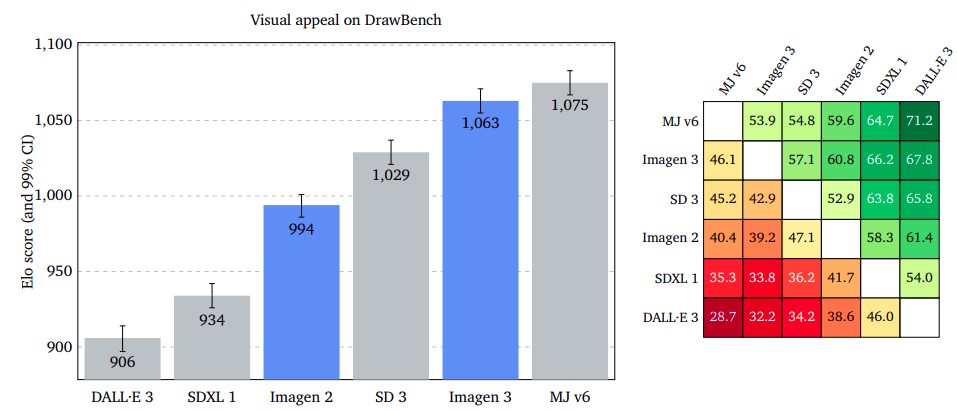
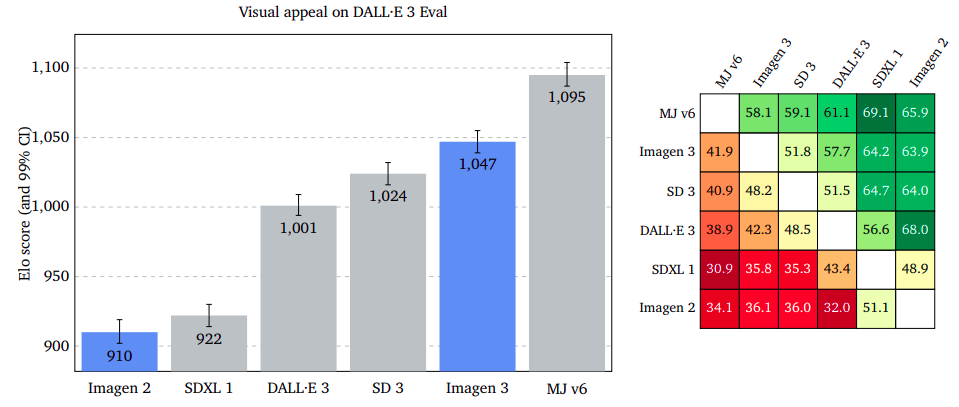
Detailed Prompt-Image Alignment
The study evaluates prompt-image alignment capabilities by generating images from detailed prompts of DOCCI, which are significantly longer than previous prompt sets. The researchers found reading 100+ word prompts too challenging for human raters. Instead, they used high-quality captions of real reference photographs to compare the generated images with benchmark reference images. The raters focused on the semantics of the images, ignoring styles, capturing technique, and quality. The results showed that Imagen 3 had a significant gap of +114 Elo points and a 63% win rate against the second-best model, highlighting its outstanding capabilities in following the detailed contents of input prompts.
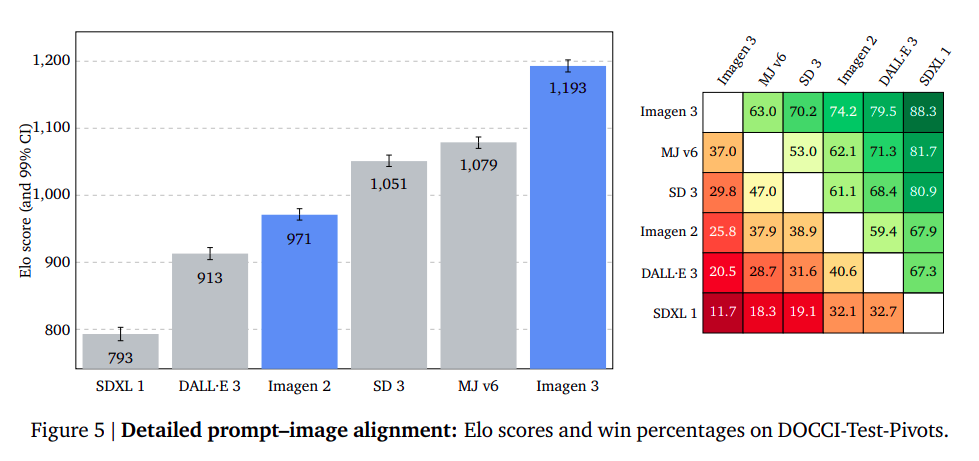
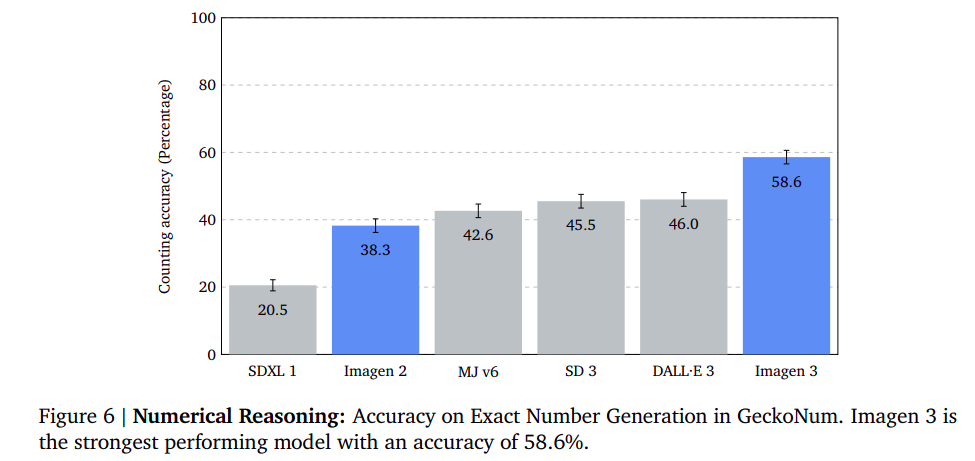
Numerical Reasoning: Outperforming the Competition in Object Count Accuracy
The study evaluates the ability of models to generate an exact number of objects using the GeckoNum benchmark task. The task involves comparing the number of objects in an image to the expected quantity requested in the prompt. The models consider attributes like color and spatial relationships. The results show that Imagen 3 is the strongest model, outperforming DALL·E 3 by 12 percentage points. It also has higher accuracy when generating images containing 2-5 objects and better performance on more complex sentence structures.
Automated Evaluation: Comparing Models with CLIP, Gecko, and VQAScore
In recent years, automatic-evaluation (auto-eval) metrics like CLIP and VQAScore have become more widely used to measure the quality of text-to-image models. This study focuses on auto-eval metrics for prompt image alignment and image quality to complement human evaluations.
Prompt–Image Alignment
The researchers choose three strong auto-eval prompt-image alignment metrics: Contrastive dual encoders (CLIP), VQA-based (Gecko), and an LVLM prompt-based (an implementation of VQAScore2). The results show that CLIP often fails to predict the correct model ordering, while Gecko and VQAScore perform well and agree about 72% of the time. VQAScore has the edge as it matches human ratings 80% of the time, compared to Gecko’s 73.3%. Gecko uses a weaker backbone, PALI, which may account for the difference in performance.
The study evaluates four datasets to investigate model differences under diverse conditions: Gecko-Rel, DOCCI-Test-Pivots, Dall·E 3 Eval, and GenAI-Bench. Results show that Imagen 3 consistently has the highest alignment performance. SDXL 1 and Imagen 2 are consistently less performant than other models.
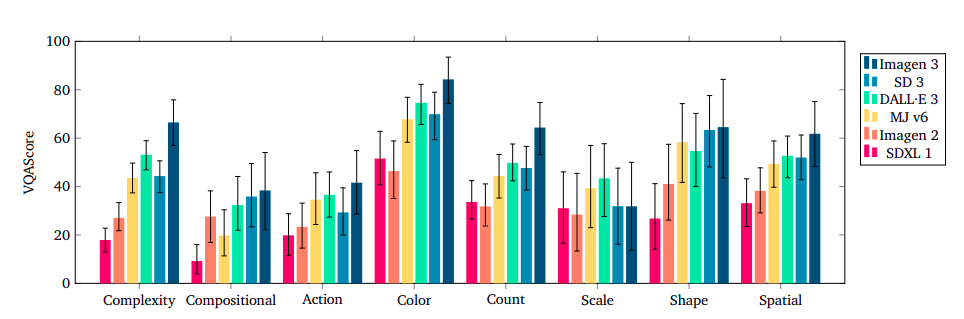
Image Quality
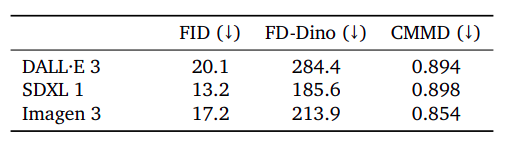
Regarding image quality, the researchers compare the distribution of generated images by Imagen 3, SDXL 1, and DALL·E 3 on 30,000 samples of the MSCOCO-caption validation set using different feature spaces and distance metrics. They observe that minimizing these three metrics is a trade-off, favoring the generation of natural colors and textures but failing to detect distortions on object shapes and parts. Imagen 3 presents the lower CMMD value of the three models, highlighting its strong performance on state-of-the-art feature space metrics.
Qualitative Results: Highlighting Imagen 3’s Attention to Detail
The image below shows 2 images upsampled to 12 megapixels, with crops showing the detail level.

Inference on Evaluation
Imagen 3 is the top model in prompt-image alignment, particularly in detailed prompts and counting abilities. In terms of visual appeal, Midjourney v6 takes the lead, with Imagen 3 coming in second. However, it still has shortcomings in certain capabilities, such as numerical reasoning, scale reasoning, compositional phrases, actions, spatial reasoning, and complex language. These models struggle with tasks that require numerical reasoning, scale reasoning, compositional phrases, and actions. Overall, Imagen 3 is the best choice for high-quality outputs that respect user intent.
Accessing Imagen 3 via Vertex AI: A Guide to Seamless Integration
Using Vertex AI
To get started using Vertex AI, you must have an existing Google Cloud project and enable the Vertex AI API. Learn more about setting up a project and a development environment.
Also, here is the GitHub Link – Refer
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
# TODO(developer): Update your project id from vertex ai console
project_id = "PROJECT_ID"
vertexai.init(project=project_id, location="us-central1")
generation_model = ImageGenerationModel.from_pretrained("imagen-3.0-generate-001")
prompt = """
A photorealistic image of a cookbook laying on a wooden kitchen table, the cover facing forward featuring a smiling family sitting at a similar table, soft overhead lighting illuminating the scene, the cookbook is the main focus of the image.
"""
image = generation_model.generate_images(
prompt=prompt,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
Text rendering
Imagen 3 also opens up new possibilities regarding text rendering inside images. Creating images of posters, cards, and social media posts with captions in different fonts and colours is a great way to experiment with this tool. To use this function, simply write a brief description of what you would like to see in the prompt. Let’s imagine you want to change the cover of a cookbook and add a title.
prompt = """
A photorealistic image of a cookbook laying on a wooden kitchen table, the cover facing forward featuring a smiling family sitting at a similar table, soft overhead lighting illuminating the scene, the cookbook is the main focus of the image.
Add a title to the center of the cookbook cover that reads, "Everyday Recipes" in orange block letters.
"""
image = generation_model.generate_images(
prompt=prompt,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
Reduced latency
DeepMind offers Imagen 3 Fast, a model optimized for generation speed, in addition to Imagen 3, its highest-quality model to date. Imagen 3 Fast is appropriate for producing images with greater contrast and brightness. You can observe a 40% reduction in latency compared to Imagen 2. You can use the same prompt to create two images that illustrate these two models. Let’s create two alternatives for the salad photo that we can include in the previously mentioned cookbook.
generation_model_fast = ImageGenerationModel.from_pretrained(
"imagen-3.0-fast-generate-001"
)
prompt = """
A photorealistic image of a garden salad overflowing with colorful vegetables like bell peppers, cucumbers, tomatoes, and leafy greens, sitting in a wooden bowl in the center of the image on a white marble table. Natural light illuminates the scene, casting soft shadows and highlighting the freshness of the ingredients.
"""
# Imagen 3 Fast image generation
fast_image = generation_model_fast.generate_images(
prompt=prompt,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
prompt = """
A photorealistic image of a garden salad overflowing with colorful vegetables like bell peppers, cucumbers, tomatoes, and leafy greens, sitting in a wooden bowl in the center of the image on a white marble table. Natural light illuminates the scene, casting soft shadows and highlighting the freshness of the ingredients.
"""
# Imagen 3 image generation
image = generation_model.generate_images(
prompt=prompt,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
Using Gemini
Gemini supports using the new Imagen 3, so we are using Gemini to access Imagen 3. In the image below, we can see that Gemini is generating images using Imagen 3.
Prompt – “Generate an image of a lion walking on city roads. Roads have cars, bikes, and a bus. Be sure to make it realistic”
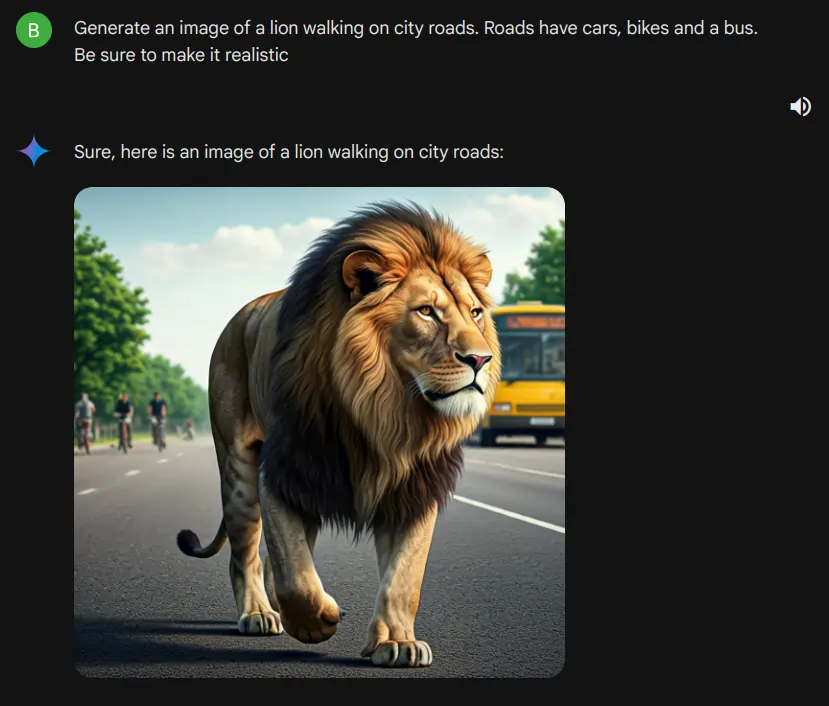
Conclusion
Google’s Imagen 3 sets a new benchmark for text-to-image synthesis, excelling in photorealism and handling complex prompts with exceptional accuracy. Its strong performance across multiple evaluation benchmarks highlights its capabilities in detailed prompt-image alignment and visual appeal, surpassing models like DALL·E 3 and Stable Diffusion. However, it still faces challenges in tasks involving numerical and spatial reasoning. With the addition of Imagen 3 Fast for reduced latency and integration with tools like Vertex AI, Imagen 3 opens up exciting possibilities for creative applications, pushing the boundaries of multimodal AI.
If you are looking for a Generative AI course online, then explore – GenAI Pinnacle Program Today!
Frequently Asked Questions
Q1. What makes Google’s Imagen 3 stand out in text-to-image synthesis?
Ans Imagen 3 excels in photorealism and intricate prompt handling, delivering superior image quality and alignment with user input compared to other models like DALL·E 3 and Stable Diffusion.
Q2. How does Imagen 3 handle complex prompts?
Ans. Imagen 3 is designed to manage detailed and lengthy prompts effectively, demonstrating strong performance in prompt-image alignment and detailed content representation.
Q3. What datasets are used to train Imagen 3?
Ans. The model is trained on a large, diverse dataset with text, images, and annotations, filtered to exclude AI-generated content, harmful images, and poor-quality data.
Q4. How does Imagen 3 Fast differ from the standard version?
Ans. Imagen 3 Fast is optimized for speed, offering a 40% reduction in latency compared to the standard version while maintaining high-quality image generation.
Q5. Can Imagen 3 be integrated into production environments?
Ans. Yes, Imagen 3 can be used with Google Cloud’s Vertex AI, allowing seamless integration into applications for image generation and creative tasks.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.


