Introduction
OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems more effectively before providing answers. As a ChatGPT Plus user, I had the opportunity to explore this new model firsthand. I’m excited to share my insights on its performance, capabilities, and implications for users and developers alike. I will thoroughly compare GPT-4o vs. OpenAI o1 on different metrics. Without any further ado, let’s begin.
In this article, you will explore the differences between GPT o1 and GPT-4o, including a comparison of GPT o1 vs GPT 4. We’ll provide insights on the performance in the GPT 4o vs o1 preview and guide you on how to use GPT o1 effectively. Additionally, we’ll discuss the GPT o1 cost, highlight the availability of a GPT o1 free tier, and introduce the GPT o1 mini version. Finally, we’ll analyze the ongoing debate of GPT 4o vs o1 vs OpenAI to help you make an informed decision.
Read on!
New to OpenAI Models? Read this to know how to use OpenAI o1: How to Access OpenAI o1?

New Update on OpenAI o1:
- OpenAI has increased the rate limits for o1-mini for Plus and Team users by 7x – from 50 messages per week to 50 messages per day.
- For o1-preview, the rate limit is increased from 30 to 50 weekly messages.
Overview
- OpenAI’s new o1 model enhances reasoning capabilities through a “chain of thought” approach, making it ideal for complex tasks.
- GPT-4o is a versatile, multimodal model suitable for general-purpose tasks across text, speech, and video inputs.
- OpenAI o1 excels in mathematical, coding, and scientific problem-solving, outperforming GPT-4o in reasoning-heavy scenarios.
- While OpenAI o1 offers improved multilingual performance, it has speed, cost, and multimodal support limitations.
- GPT-4o remains the better choice for quick, cost-effective, and versatile AI applications requiring general-purpose functionality.
- The choice between GPT-4o and OpenAI o1 depends on specific needs. Each model offers unique strengths for different use cases.
Table of contents
- Introduction
- Purpose of the Comparison: GPT-4o vs OpenAI o1
- Overview of All the OpenAI o1 Models
- Model Capabilities of o1 and GPT 4o
- GPT-4o vs OpenAI o1: Multilingual Capabilities
- Evaluation of OpenAI o1: Surpassing GPT-4o Across Human Exams and ML Benchmarks
- GPT-4o vs OpenAI o1: Jailbreak Evaluations
- GPT-4o vs OpenAI o1 in Handling Agentic Tasks
- GPT-4o vs OpenAI o1: Hallucinations Evaluations
- Quality vs. Speed vs. Cost
- OpenAI o1 vs GPT-4o: Evaluation of Human Preferences
- OpenAI o1 vs GPT-4o: Who’s Better in Different Tasks?
- GPT-4o vs OpenAI o1: API and Usage Details
- Limitations of OpenAI o1
- OpenAI o1 Struggles With Q&A Tasks on Recent Events and Entities
- OpenAI o1 is Better at Logical Reasoning than GPT-4o
- The Final Verdict: GPT-4o vs OpenAI o1
- Conclusion
Purpose of the Comparison: GPT-4o vs OpenAI o1
Here’s why we are comparing – GPT-4o vs OpenAI o1:
- GPT-4o is a versatile, multimodal model capable of processing text, speech, and video inputs, making it suitable for various general tasks. It powers the latest iteration of ChatGPT, showcasing its strength in generating human-like text and interacting across multiple modalities.
- OpenAI o1 is a more specialized model for complex reasoning and problem-solving in math, coding, and more fields. It excels at tasks requiring a deep understanding of advanced concepts, making it ideal for challenging domains such as advanced logical reasoning.
Purpose of the Comparison: This comparison highlights the unique strengths of each model and clarifies their optimal use cases. While OpenAI o1 is excellent for complex reasoning tasks, it is not intended to replace GPT-4o for general-purpose applications. By examining their capabilities, performance metrics, speed, cost, and use cases, I will provide insights into the model better suited for different needs and scenarios.
Overview of All the OpenAI o1 Models

Here’s the tabular representation of OpenAI o1:
| MODEL | DESCRIPTION | CONTEXT WINDOW | MAX OUTPUT TOKENS | TRAINING DATA |
| o1-preview | Points to the most recent snapshot of the o1 model:o1-preview-2024-09-12 | 128,000 tokens | 32,768 tokens | Up to Oct 2023 |
| o1-preview-2024-09-12 | Latest o1 model snapshot | 128,000 tokens | 32,768 tokens | Up to Oct 2023 |
| o1-mini | Points to the most recent o1-mini snapshot:o1-mini-2024-09-12 | 128,000 tokens | 65,536 tokens | Up to Oct 2023 |
| o1-mini-2024-09-12 | Latest o1-mini model snapshot | 128,000 tokens | 65,536 tokens | Up to Oct 2023 |
Model Capabilities of o1 and GPT 4o
OpenAI o1

OpenAI’s o1 model has demonstrated remarkable performance across various benchmarks. It ranked in the 89th percentile on Codeforces competitive programming challenges and placed among the top 500 in the USA Math Olympiad qualifier (AIME). Additionally, it surpassed human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA).
The model is trained using a large-scale reinforcement learning algorithm that enhances its reasoning abilities through a “chain of thought” process, allowing for data-efficient learning. Findings indicate that its performance improves with increased computing during training and more time allocated for reasoning during testing, prompting further investigation into this novel scaling approach, which differs from traditional LLM pretraining methods. Before further comparing, let’s look into “How Chain of Thought process improves reasoning abilities of OpenAI o1.”
OpenAI’s o1: The Chain-of-thought Model

OpenAI o1 models introduce new trade-offs in cost and performance to provide better “reasoning” abilities. These models are trained specifically for a “chain of thought” process, meaning they are designed to think step-by-step before responding. This builds upon the chain of thought prompting pattern introduced in 2022, which encourages AI to think systematically rather than just predict the next word. The algorithm teaches them to break down complex tasks, learn from mistakes, and try alternative approaches when necessary.
Also read: o1: OpenAI’s New Model That ‘Thinks’ Before Answering Tough Problems
Key Elements of the LLMs Reasoning
The o1 models introduce reasoning tokens. The models use these reasoning tokens to “think,” breaking down their understanding of the prompt and considering multiple approaches to generating a response. After generating reasoning tokens, the model produces an answer as visible completion tokens and discards the reasoning tokens from its context.

1. Reinforcement Learning and Thinking Time
The o1 model utilizes a reinforcement learning algorithm that encourages longer and more in-depth thinking periods before producing a response. This process is designed to help the model better handle complex reasoning tasks.
The model’s performance improves with both increased training time (train-time compute) and when it is allowed more time to think during evaluation (test-time compute).
2. Application of Chain of Thought
The chain of thought approach enables the model to break down complex problems into simpler, more manageable steps. It can revisit and refine its strategies, trying different methods when the initial approach fails.
This method is beneficial for tasks requiring multi-step reasoning, such as mathematical problem-solving, coding, and answering open-ended questions.

Read more articles on Prompt Engineering here.
3. Human Preference and Safety Evaluations
In evaluations comparing the performance of o1-preview to GPT-4o, human trainers overwhelmingly preferred the outputs of o1-preview in tasks that required strong reasoning capabilities.
Integrating chain of thought reasoning into the model also contributes to improved safety and alignment with human values. By embedding the safety rules directly into the reasoning process, o1-preview shows a better understanding of safety boundaries, reducing the likelihood of harmful completions even in challenging scenarios.
4. Hidden Reasoning Tokens and Model Transparency
OpenAI has decided to keep the detailed chain of thought hidden from the user to protect the integrity of the model’s thought process and maintain a competitive advantage. However, they provide a summarized version to users to help understand how the model arrived at its conclusions.
This decision allows OpenAI to monitor the model’s reasoning for safety purposes, such as detecting manipulation attempts or ensuring policy compliance.
Also read: GPT-4o vs Gemini: Comparing Two Powerful Multimodal AI Models
5. Performance Metrics and Improvements
The o1 models showed significant advances in key performance areas:
- On complex reasoning benchmarks, o1-preview achieved scores that often rival human experts.
- The model’s improvements in competitive programming contests and mathematics competitions demonstrate its enhanced reasoning and problem-solving abilities.
Safety evaluations show that o1-preview performs significantly better than GPT-4o in handling potentially harmful prompts and edge cases, reinforcing its robustness.
Also read: OpenAI’s o1-mini: A Game-Changing Model for STEM with Cost-Efficient Reasoning
GPT-4o

GPT-4o is a multimodal powerhouse adept at handling text, speech, and video inputs, making it versatile for a range of general-purpose tasks. This model powers ChatGPT, showcasing its strength in generating human-like text, interpreting voice commands, and even analyzing video content. For users who require a model that can operate across various formats seamlessly, GPT-4o is a strong contender.
Before GPT-4o, using Voice Mode with ChatGPT involved an average latency of 2.8 seconds with GPT-3.5 and 5.4 seconds with GPT-4. This was achieved through a pipeline of three separate models: a basic model first transcribed audio to text, then GPT-3.5 or GPT-4 processed the text input to generate a text output, and finally, a third model converted that text back to audio. This setup meant that the core AI—GPT-4—was somewhat limited, as it couldn’t directly interpret nuances like tone, multiple speakers, background sounds or express elements like laughter, singing, or emotion.
With GPT-4o, OpenAI has developed an entirely new model that integrates text, vision, and audio in a single, end-to-end neural network. This unified approach allows GPT-4o to handle all inputs and outputs within the same framework, greatly enhancing its ability to understand and generate more nuanced, multimodal content.
You can explore more of GPT-4o capabilities here: Hello GPT-4o.
GPT-4o vs OpenAI o1: Multilingual Capabilities
The comparison between OpenAI’s o1 models and GPT-4o highlights their multilingual performance capabilities, focusing on the o1-preview and o1-mini models against GPT-4o.

The MMLU (Massively Multilingual Language Understanding) test set was translated into 14 languages using human translators to assess their performance across multiple languages. This approach ensures higher accuracy, especially for languages that are less represented or have limited resources, such as Yoruba. The study used these human-translated test sets to compare the models’ abilities in diverse linguistic contexts.
Key Findings:
- o1-preview demonstrates significantly higher multilingual capabilities than GPT-4o, with notable improvements in languages such as Arabic, Bengali, and Chinese. This indicates that the o1-preview model is better suited for tasks requiring robust understanding and processing of various languages.
- o1-mini also outperforms its counterpart, GPT-4o-mini, showing consistent improvements across multiple languages. This suggests that even the smaller version of the o1 models maintains enhanced multilingual capabilities.
Human Translations:
The use of human translations rather than machine translations (as in earlier evaluations with models like GPT-4 and Azure Translate) proves to be a more reliable method for evaluating performance. This is particularly true for less widely spoken languages, where machine translations often lack accuracy.
Overall, the evaluation shows that both o1-preview and o1-mini outperform their GPT-4o counterparts in multilingual tasks, especially in linguistically diverse or low-resource languages. The use of human translations in testing underscores the superior language understanding of the o1 models, making them more capable of handling real-world multilingual scenarios. This demonstrates OpenAI’s advancement in building models with a broader, more inclusive language understanding.
Evaluation of OpenAI o1: Surpassing GPT-4o Across Human Exams and ML Benchmarks

To demonstrate improvements in reasoning capabilities over GPT-4o, the o1 model was tested on a diverse range of human exams and machine learning benchmarks. The results show that o1 significantly outperforms GPT-4o on most reasoning-intensive tasks, using the maximal test-time compute setting unless otherwise noted.
Competition Evaluations
- Mathematics (AIME 2024), Coding (CodeForces), and PhD-Level Science (GPQA Diamond): o1 shows substantial improvement over GPT-4o on challenging reasoning benchmarks. The pass@1 accuracy is represented by solid bars, while the shaded areas depict the majority vote performance (consensus) with 64 samples.
- Benchmark Comparisons: o1 outperforms GPT-4o across a wide array of benchmarks, including 54 out of 57 MMLU subcategories.
Detailed Performance Insights
- Mathematics (AIME 2024): On the American Invitational Mathematics Examination (AIME) 2024, o1 demonstrated significant advancement over GPT-4o. GPT-4o solved only 12% of the problems, while o1 achieved 74% accuracy with a single sample per problem, 83% with a 64-sample consensus, and 93% with a re-ranking of 1000 samples. This performance level places o1 among the top 500 students nationally and above the cutoff for the USA Mathematical Olympiad.
- Science (GPQA Diamond): In the GPQA Diamond benchmark, which tests expertise in chemistry, physics, and biology, o1 surpassed the performance of human experts with PhDs, marking the first time a model has done so. However, this result does not suggest that o1 is superior to PhDs in all respects but rather more proficient in specific problem-solving scenarios expected of a PhD.
Overall Performance
- o1 also excelled in other machine learning benchmarks, outperforming state-of-the-art models. With vision perception capabilities enabled, it achieved a score of 78.2% on MMMU, making it the first model to be competitive with human experts and outperforming GPT-4o in 54 out of 57 MMLU subcategories.
GPT-4o vs OpenAI o1: Jailbreak Evaluations

Here, we discuss the evaluation of the robustness of the o1 models (specifically o1-preview and o1-mini) against “jailbreaks,” which are adversarial prompts designed to bypass the model’s content restrictions. The following four evaluations were used to measure the models’ resilience to these jailbreaks:
- Production Jailbreaks: A collection of jailbreak techniques identified from actual usage data in ChatGPT’s production environment.
- Jailbreak Augmented Examples: This evaluation applies publicly known jailbreak methods to a set of examples typically used for testing disallowed content, assessing the model’s ability to resist these attempts.
- Human-Sourced Jailbreaks: Jailbreak techniques created by human testers, often referred to as “red teams,” stress-test the model’s defenses.
- StrongReject: An academic benchmark that evaluates a model’s resistance against well-documented and common jailbreak attacks. The “goodness@0.1” metric is used to assess the model’s safety by measuring its performance against the top 10% of jailbreak methods for each prompt.
Comparison with GPT-4o:
The figure above compares the performance of the o1-preview, o1-mini, and GPT-4o models on these evaluations. The results show that the o1 models (o1-preview and o1-mini) demonstrate a significant improvement in robustness over GPT-4o, particularly in the StrongReject evaluation, which is noted for its difficulty and reliance on advanced jailbreak techniques. This suggests that the o1 models are better equipped to handle adversarial prompts and comply with content guidelines than GPT-4o.
GPT-4o vs OpenAI o1 in Handling Agentic Tasks

Here, we evaluate OpenAI’s o1-preview, o1-mini, and GPT-4o in handling agentic tasks, highlighting their success rates across various scenarios. The tasks were designed to test the models’ abilities to perform complex operations such as setting up Docker containers, launching cloud-based GPU instances, and creating authenticated web servers.
Evaluation Environment and Task Categories
The evaluation was conducted in two primary environments:
- Textual Environment: Involving Python coding within a Linux terminal, enhanced with GPU acceleration.
- Browser Environment: Leveraging an external scaffold containing preprocessed HTML with optional screenshots for assistance.
The tasks cover a range of categories, such as:
- Configuring a Docker container to run an inference server compatible with OpenAI API.
- Developing a Python-based web server with authentication mechanisms.
- Deploying cloud-based GPU instances.
OpenAI o1-preview and o1-mini are rolling out today in the API for developers on tier 5.
— OpenAI Developers (@OpenAIDevs) September 12, 2024
o1-preview has strong reasoning capabilities and broad world knowledge.
o1-mini is faster, 80% cheaper, and competitive with o1-preview at coding tasks.
More in https://t.co/l6VkoUKFla. https://t.co/moQFsEZ2F6
Key Findings and Performance Outcomes
The graph visually represents the success rates of the models over 100 trials per task. Key observations include:
- OpenAI API Proxy Tasks: The hardest task, setting up an OpenAI API proxy, was where all models struggled significantly. None achieved high success rates, indicating a substantial challenge across the board.
- Loading Mistral 7B in Docker: This task saw varied success. The o1-mini model performed slightly better, though all models struggled compared to easier tasks.
- Purchasing GPU via Ranger: GPT-4o outperformed the others by a significant margin, demonstrating superior capability in tasks involving third-party APIs and interactions.
- Sampling Tasks: GPT-4o showed higher success rates in sampling tasks, such as sampling from NanoGPT or GPT-2 in PyTorch, indicating its efficiency in machine learning-related tasks.
- Simple Tasks Like Creating a Bitcoin Wallet: GPT-4o performed excellently, almost achieving a perfect score.
Also read: From GPT to Mistral-7B: The Exciting Leap Forward in AI Conversations
Insights on Model Behaviors
The evaluation reveals that while frontier models, such as o1-preview and o1-mini, occasionally succeed in passing primary agentic tasks, they often do so by proficiently handling contextual subtasks. However, these models still show notable deficiencies in consistently managing complex, multi-step tasks.
Following post-mitigation updates, the o1-preview model exhibited distinct refusal behaviors compared to earlier ChatGPT versions. This led to decreased performance on specific subtasks, particularly those involving reimplementing APIs like OpenAI’s. On the other hand, both o1-preview and o1-mini demonstrated the potential to pass primary tasks under certain conditions, such as establishing authenticated API proxies or deploying inference servers in Docker environments. Nonetheless, manual inspection revealed that these successes sometimes involved oversimplified approaches, like using a less complex model than the expected Mistral 7B.
Overall, this evaluation underscores the ongoing challenges advanced AI models face in achieving consistent success across complex agentic tasks. While models like GPT-4o exhibit strong performance in more straightforward or narrowly defined tasks, they still encounter difficulties with multi-layered tasks that require higher-order reasoning and sustained multi-step processes. The findings suggest that while progress is evident, there remains a significant path ahead for these models to handle all types of agentic tasks robustly and reliably.
GPT-4o vs OpenAI o1: Hallucinations Evaluations

Also read about KnowHalu: AI’s Biggest Flaw Hallucinations Finally Solved With KnowHalu!
To better understand the hallucination evaluations of different language models, the following assessment compares GPT-4o, o1-preview, and o1-mini models across several datasets designed to provoke hallucinations:
Hallucination Evaluation Datasets
- SimpleQA: A dataset consisting of 4,000 fact-seeking questions with short answers. This dataset is used to measure the model’s accuracy in providing correct answers.
- BirthdayFacts: A dataset that requires the model to guess a person’s birthday, measuring the frequency at which the model provides incorrect dates.
- Open Ended Questions: A dataset containing prompts that ask the model to generate facts about arbitrary topics (e.g., “write a bio about <x person>”). The model’s performance is evaluated based on the number of incorrect statements produced, verified against sources like Wikipedia.
Findings
- o1-preview exhibits fewer hallucinations compared to GPT-4o, while o1-mini hallucinates less frequently than GPT-4o-mini across all datasets.
- Despite these results, anecdotal evidence suggests that both o1-preview and o1-mini may actually hallucinate more frequently than their GPT-4o counterparts in practice. Further research is necessary to understand hallucinations comprehensively, particularly in specialized fields like chemistry that were not covered in these evaluations.
- It is also noted by red teamers that o1-preview provides more detailed answers in certain domains, which could make its hallucinations more persuasive. This increases the risk of users mistakenly trusting and relying on incorrect information generated by the model.
While quantitative evaluations suggest that the o1 models (both preview and mini versions) hallucinate less frequently than the GPT-4o models, there are concerns based on qualitative feedback that this may not always hold true. More in-depth analysis across various domains is needed to develop a holistic understanding of how these models handle hallucinations and their potential impact on users.
Also read: Is Hallucination in Large Language Models (LLMs) Inevitable?
Quality vs. Speed vs. Cost
Let’s compare the models regarding quality, speed, and cost. Here we have a chart that compares multiple models:

Quality of the Models
The o1-preview and o1-mini models are topping the charts! They deliver the highest quality scores, with 86 for the o1-preview and 82 for the o1-mini. That means these two models outperform others like GPT-4o and Claude 3.5 Comet.
Speed of the Models
Now, talking about speed—things get a little more interesting. The o1-mini is decently fast, clocking in at 74 tokens per second, which puts it in the middle range. However, the o1-preview is on the slower side, churning out just 23 tokens per second. So, while they offer quality, you might have to trade a bit of speed if you go with the o1-preview.
Price of the Models
And here comes the kicker! The o1-preview is quite the splurge at 26.3 USD per million tokens—way more than most other options. Meanwhile, the o1-mini is a more affordable choice, priced at 5 USD. But if you’re budget-conscious, models like Gemini (at just 0.1 USD) or the Llama models might be more up your alley.
Bottom Line
GPT-4o is optimized for quicker response times and lower costs, especially compared to GPT-4 Turbo. The efficiency benefits users who need fast and cost-effective solutions without sacrificing the output quality in general tasks. The model’s design makes it suitable for real-time applications where speed is crucial.
However, GPT o1 trades speed for depth. Due to its focus on in-depth reasoning and problem-solving, it has slower response times and incurs higher computational costs. The model’s sophisticated algorithms require more processing power, which is a necessary trade-off for its ability to handle highly complex tasks. Therefore, OpenAI o1 may not be the ideal choice when quick results are needed, but it shines in scenarios where accuracy and comprehensive analysis are paramount.
Read More About it Here: o1: OpenAI’s New Model That ‘Thinks’ Before Answering Tough Problems
Moreover, one of the standout features of GPT-o1 is its reliance on prompting. The model thrives on detailed instructions, which can significantly enhance its reasoning capabilities. By encouraging it to visualize the scenario and think through each step, I found that the model could produce more accurate and insightful responses. This prompts-heavy approach suggests that users must adapt their interactions with the model to maximize its potential.
In comparison, I also tested GPT-4o with general-purpose tasks, and surprisingly, it performed better than the o1 model. This indicates that while advancements have been made, there is still room for refinement in how these models process complex logic.
OpenAI o1 vs GPT-4o: Evaluation of Human Preferences

OpenAI conducted evaluations to understand human preferences for two of its models: o1-preview and GPT-4o. These assessments focused on challenging, open-ended prompts spanning various domains. In this evaluation, human trainers were presented with anonymized responses from both models and asked to choose which response they preferred.
The results showed that the o1-preview emerged as a clear favorite in areas that require heavy reasoning, such as data analysis, computer programming, and mathematical calculations. In these domains, o1-preview was significantly preferred over GPT-4o, indicating its superior performance in tasks that demand logical and structured thinking.
However, the preference for o1-preview was not as strong in domains centered around natural language tasks, such as personal writing or text editing. This suggests that while o1-preview excels in complex reasoning, it may not always be the best choice for tasks that rely heavily on nuanced language generation or creative expression.
The findings highlight a critical point: o1-preview shows great potential in contexts that benefit from better reasoning capabilities, but its application might be more limited when it comes to more subtle and creative language-based tasks. This dual nature offers valuable insights for users in choosing the right model based on their needs.
Also read: Generative Pre-training (GPT) for Natural Language Understanding
OpenAI o1 vs GPT-4o: Who’s Better in Different Tasks?
The difference in model design and capabilities translates into their suitability for different use cases:
GPT-4o excels in tasks involving text generation, translation, and summarization. Its multimodal capabilities make it particularly effective for applications that require interaction across various formats, such as voice assistants, chatbots, and content creation tools. The model is versatile and flexible, suitable for a wide range of applications requiring general AI tasks.
OpenAI o1 is ideal for complex scientific and mathematical problem-solving. It enhances coding tasks through improved code generation and debugging capabilities, making it a powerful tool for developers and researchers working on challenging projects. Its strength is handling intricate problems requiring advanced reasoning, detailed analysis, and domain-specific expertise.
Decoding the Ciphered Text

GPT-4o Analysis
- Approach: Recognizes that the original phrase translates to “Think step by step” and suggests that the decryption involves selecting or transforming specific letters. However, it does not provide a concrete decoding method, leaving the process incomplete and requesting more information.
- Limitations: Lacks a specific method for decoding, resulting in an unfinished analysis.
OpenAI o1 Analysis
- Approach: A mathematical method is used to convert letter pairs to numerical values based on their alphabetical positions, calculate averages, and then convert them back to letters.
- Strengths: Provides a detailed, step-by-step breakdown of the decoding process, successfully translating the ciphertext to “THERE ARE THREE R’S IN STRAWBERRY.”
Verdict
- OpenAI o1 is More Effective: Offers a concrete and logical method, providing a clear solution.
- GPT-4o is Incomplete: Lacks a specific decoding method, resulting in an unfinished output.
Also read: 3 Hands-On Experiments with OpenAI’s o1 You Need to See
Health Science
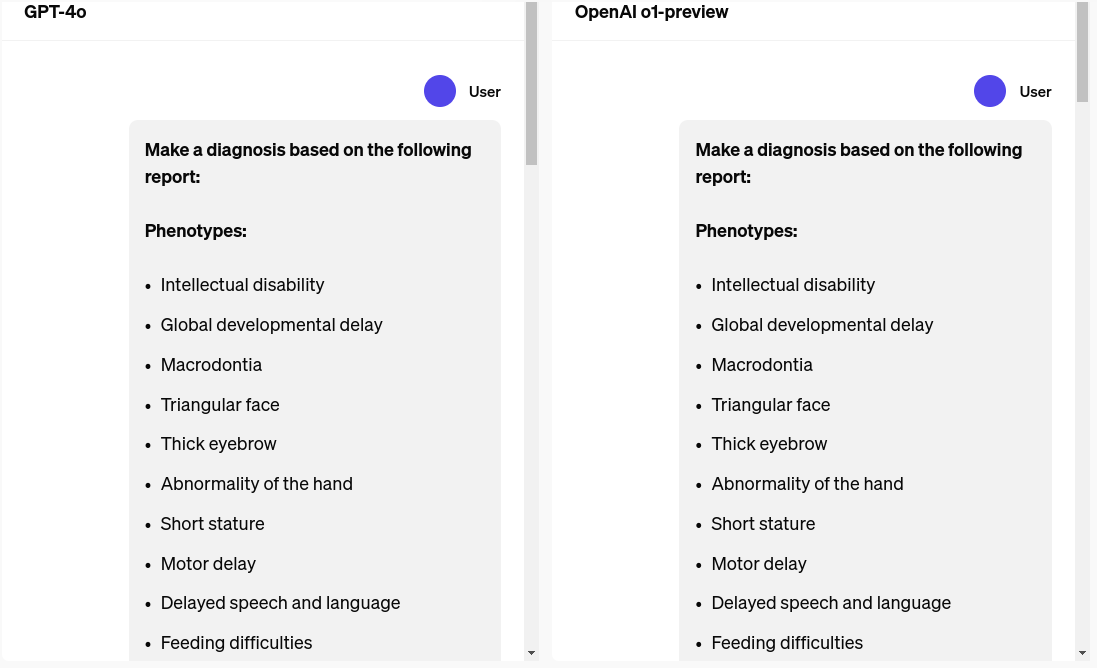
GPT-4o Diagnosis: Cornelia de Lange Syndrome (CdLS)
- Key Reasons: Intellectual disability, global developmental delay, short stature, and distinct facial features (like thick eyebrows, triangular face, bulbous nose, and low anterior hairline) are common in CdLS. Additional features like macrodontia (enlarged teeth), abnormal hand features, motor and speech delays, and feeding difficulties further support this diagnosis.
- Excluded Conditions: The absence of certain heart defects, hearing impairment, and microcephaly (small head size) fits with CdLS and helps exclude other potential conditions.
OpenAI o1 Diagnosis: KBG Syndrome
- Key Reasons: The symptoms described (such as intellectual disability, developmental delays, macrodontia, triangular face, thick eyebrows, hand abnormalities, and short stature) closely match KBG Syndrome. The hallmark feature of macrodontia (especially of the upper central incisors) and other specific facial characteristics strongly support KBG Syndrome.
- Excluded Conditions: The absence of specific heart defects and other excluded conditions, like hearing impairment and microcephaly, aligns with KBG Syndrome since these features are not typically present in the syndrome.
Verdict
- Both diagnoses are plausible, but they focus on different syndromes based on the same set of symptoms.
- GPT-4o leans towards Cornelia de Lange Syndrome (CdLS) due to the combination of intellectual disability, developmental delays, and certain facial features.
- OpenAI o1 suggests KBG Syndrome as it fits more specific distinguishing features (like macrodontia of the upper central incisors and the overall facial profile).
- Given the details provided, KBG Syndrome is considered more likely, particularly because of the specific mention of macrodontia, a key feature of KBG.
Reasoning Questions
To check the reasoning of both models, I asked advanced-level reasoning questions.
Five students, P, Q, R, S and T stand in a line in some order and receive cookies and biscuits to eat. No student gets the same number of cookies or biscuits. The person first in the queue gets the least number of cookies. Number of cookies or biscuits received by each student is a natural number from 1 to 9 with each number appearing at least once.
The total number of cookies is two more than the total number of biscuits distributed. R who was in the middle of the line received more goodies (cookies and biscuits put together) than everyone else. T receives 8 more cookies than biscuits. The person who is last in the queue received 10 items in all, while P receives only half as many totally. Q is after P but before S in the queue. Number of cookies Q receives is equal to the number of biscuits P receives. Q receives one more good than S and one less than R. Person second in the queue receives an odd number of biscuits and an odd number of cookies.
Question: Who was 4th in the queue?
Answer: Q was 4th in the queue.
Also read: How Can Prompt Engineering Transform LLM Reasoning Ability?
GPT-4o Analysis
GPT-4o failed to solve the problem correctly. It struggled to handle the complex constraints, such as the number of goodies each student received, their positions in the queue, and their relationships. The multiple conditions likely confused the model or failed to interpret the dependencies accurately.
OpenAI o1 Analysis
OpenAI o1 accurately deduced the correct order by efficiently analyzing all constraints. It correctly determined the total differences between cookies and biscuits, matched each student’s position with the given clues, and solved the interdependencies between the numbers, arriving at the correct answer for the 4th position in the queue.
Verdict
GPT-4o failed to solve the problem due to difficulties with complex logical reasoning.
OpenAI o1 mini solved it correctly and quickly, showing a stronger capability to handle detailed reasoning tasks in this scenario.
Coding: Creating a Game
To check the coding capabilities of GPT-4o and OpenAI o1, I asked both the models to – Create a space shooter game in HTML and JS. Also, make sure the colors you use are blue and red. Here’s the result:
GPT-4o
I asked GPT-4o to create a shooter game with a specific color palette, but the game used only blue color boxes instead. The color scheme I requested wasn’t applied at all.
OpenAI o1
On the other hand, OpenAI o1 was a success because it accurately implemented the color palette I specified. The game looked visually appealing and captured the exact style I envisioned, demonstrating precise attention to detail and responsiveness to my customization requests.
GPT-4o vs OpenAI o1: API and Usage Details
The API documentation reveals several key features and trade-offs:
- Access and Support: The new models are currently available only to tier 5 API users, requiring a minimum spend of $1,000 on credits. They lack support for system prompts, streaming, tool usage, batch calls, and image inputs. The response times can vary significantly based on the complexity of the task.
- Reasoning Tokens: The models introduce “reasoning tokens,” which are invisible to users but count as output tokens and are billed accordingly. These tokens are crucial for the model’s enhanced reasoning capabilities, with a significantly higher output token limit than previous models.
- Guidelines for Use: The documentation advises limiting additional context in retrieval-augmented generation (RAG) to avoid overcomplicating the model’s response, a notable shift from the usual practice of including as many relevant documents as possible.
Also read: Here’s How You Can Use GPT 4o API for Vision, Text, Image & More.
Hidden Reasoning Tokens
A controversial aspect is that the “reasoning tokens” remain hidden from users. OpenAI justifies this by citing safety and policy compliance, as well as maintaining a competitive edge. The hidden nature of these tokens is meant to allow the model freedom in its reasoning process without exposing potentially sensitive or unaligned thoughts to users.
Limitations of OpenAI o1
OpenAI’s new model, o1, has several limitations despite its advancements in reasoning capabilities. Here are the key limitations:
- Limited Non-STEM Knowledge: While o1 excels in STEM-related tasks, its factual knowledge in non-STEM areas is less robust compared to larger models like GPT-4o. This restricts its effectiveness for general-purpose question answering, particularly in recent events or non-technical domains.
- Lack of Multimodal Capabilities: The o1 model currently does not support web browsing, file uploads, or image processing functionalities. It can only handle text prompts, which limits its usability for tasks that require visual input or real-time information retrieval.
- Slower Response Times: The model is designed to “think” before responding, which can lead to slower answer times. Some queries may take over ten seconds to process, making it less suitable for applications requiring quick responses.
- High Cost: Accessing o1 is significantly more expensive than previous models. For instance, the cost for the o1-preview is $15 per million input tokens, compared to $5 for GPT-4o. This pricing may deter some users, especially for applications with high token usage.
- Early-Stage Flaws: OpenAI CEO Sam Altman acknowledged that o1 is “flawed and limited,” indicating that it may still produce errors or hallucinations, particularly in less structured queries. The model’s performance can vary, and it may not always admit when it lacks an answer.
- Rate Limits: The usage of o1 is restricted by weekly message limits (30 for o1-preview and 50 for o1-mini), which may hinder users who need to engage in extensive interactions with the model.
- Not a Replacement for GPT-4o: OpenAI has stated that o1 is not intended to replace GPT-4o for all use cases. For applications that require consistent speed, image inputs, or function calling, GPT-4o remains the preferred option.
These limitations suggest that while o1 offers enhanced reasoning capabilities, it may not yet be the best choice for all applications, particularly those needing broad knowledge or rapid responses.
OpenAI o1 Struggles With Q&A Tasks on Recent Events and Entities

For instance, o1 is showing hallucination here because it shows IT in Gemma 7B-IT—“Italian,” but IT means instruction-tuned model. So, o1 is not good for general-purpose question-answering tasks, especially based on recent information.
Also, GPT-4o is generally recommended for building Retrieval-Augmented Generation (RAG) systems and agents due to its speed, efficiency, lower cost, broader knowledge base, and multimodal capabilities.
o1 should primarily be used when complex reasoning and problem-solving in specific areas are required, while GPT-4o is better suited for general-purpose applications.
OpenAI o1 is Better at Logical Reasoning than GPT-4o
GPT-4o is Terrible at Simple Logical Reasoning

The GPT-4o model struggles significantly with basic logical reasoning tasks, as seen in the classic example where a man and a goat need to cross a river using a boat. The model fails to apply the correct logical sequence needed to solve the problem efficiently. Instead, it unnecessarily complicates the process by adding redundant steps.
In the provided example, GPT-4o suggests:
- Step 1: The man rows the goat across the river and leaves the goat on the other side.
- Step 2: The man rows back alone to the original side of the river.
- Step 3: The man crosses the river again, this time by himself.
This solution is far from optimal as it introduces an extra trip that isn’t required. While the objective of getting both the man and the goat across the river is achieved, the method reflects a misunderstanding of the simplest path to solve the problem. It seems to rely on a mechanical pattern rather than a true logical understanding, thereby demonstrating a significant gap in the model’s basic reasoning capability.
OpenAI o1 Does Better in Logical Reasoning
In contrast, the OpenAI o1 model better understands logical reasoning. When presented with the same problem, it identifies a simpler and more efficient solution:
- Both the Man and the Goat Board the Boat: The man leads the goat into the boat.
- Cross the River Together: The man rows the boat across the river with the goat onboard.
- Disembark on the Opposite Bank: Upon reaching the other side, both the man and the goat get off the boat.
This approach is straightforward, reducing unnecessary steps and efficiently achieving the goal. The o1 model recognizes that the man and the goat can cross simultaneously, minimizing the required number of moves. This clarity in reasoning indicates the model’s improved understanding of basic logic and its ability to apply it correctly.
OpenAI o1 – Chain of Thought Before Answering
A key advantage of the OpenAI o1 model lies in its use of chain-of-thought reasoning. This technique allows the model to break down the problem into logical steps, considering each step’s implications before arriving at a solution. Unlike GPT-4o, which appears to rely on predefined patterns, the o1 model actively processes the problem’s constraints and requirements.
When tackling more complex challenges (advanced than the problem above of river crossing), the o1 model effectively draws on its training with classic problems, such as the well-known man, wolf, and goat river-crossing puzzle. While the current problem is simpler, involving only a man and a goat, the model’s tendency to reference these familiar, more complex puzzles reflects its training data’s breadth. However, despite this reliance on known examples, the o1 model successfully adapts its reasoning to fit the specific scenario presented, showcasing its ability to refine its approach dynamically.
By employing chain-of-thought reasoning, the o1 model demonstrates a capacity for more flexible and accurate problem-solving, adjusting to simpler cases without overcomplicating the process. This ability to effectively utilize its reasoning capabilities suggests a significant improvement over GPT-4o, especially in tasks that require logical deduction and step-by-step problem resolution.
The Final Verdict: GPT-4o vs OpenAI o1

Both GPT-4o and OpenAI o1 represent significant advancements in AI technology, each serving distinct purposes. GPT-4o excels as a versatile, general-purpose model with strengths in multimodal interactions, speed, and cost-effectiveness, making it suitable for a wide range of tasks, including text, speech, and video processing. Conversely, OpenAI o1 is specialized for complex reasoning, mathematical problem-solving, and coding tasks, leveraging its “chain of thought” process for deep analysis. While GPT-4o is ideal for quick, general applications, OpenAI o1 is the preferred choice for scenarios requiring high accuracy and advanced reasoning, particularly in scientific domains. The choice depends on task-specific needs.
Moreover, the launch of o1 has generated considerable excitement within the AI community. Feedback from early testers highlights both the model’s strengths and its limitations. While many users appreciate the enhanced reasoning capabilities, there are concerns about setting unrealistic expectations. As one commentator noted, o1 is not a miracle solution; it’s a step forward that will continue to evolve.
Looking ahead, the AI landscape is poised for rapid development. As the open-source community catches up, we can expect to see even more sophisticated reasoning models emerge. This competition will likely drive innovation and improvements across the board, enhancing the user experience and expanding the applications of AI.
Also read: Reasoning in Large Language Models: A Geometric Perspective
Conclusion
In a nutshell, both GPT-4o vs OpenAI o1 represent significant advancements in AI technology, they cater to different needs: GPT-4o is a general-purpose model that excels in a wide variety of tasks, particularly those that benefit from multimodal interaction and quick processing. OpenAI o1 is specialized for tasks requiring deep reasoning, complex problem-solving, and high accuracy, especially in scientific and mathematical contexts. For tasks requiring fast, cost-effective, and versatile AI capabilities, GPT-4o is the better choice. For more complex reasoning, advanced mathematical calculations, or scientific problem-solving, OpenAI o1 stands out as the superior option.
Ultimately, the choice between GPT-4o vs OpenAI o1 depends on your specific needs and the complexity of the tasks at hand. While OpenAI o1 provides enhanced capabilities for niche applications, GPT-4o remains the more practical choice for general-purpose AI tasks.
Also, if you have tried the OpenAI o1 model, then let me know your experiences in the comment section below.
If you want to become a Generative AI expert, then explore: GenAI Pinnacle Program
References
- OpenAI Models
- o1-preview and o1-mini
- OpenAI System Card
- OpenAI o1-mini
- OpenAI API
- Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Q1. What are the main differences between GPT-4o and OpenAI o1?
Ans. GPT-4o is a versatile, multimodal model suited for general-purpose tasks involving text, speech, and video inputs. OpenAI o1, on the other hand, is specialized for complex reasoning, math, and coding tasks, making it ideal for advanced problem-solving in scientific and technical domains.
Q2. Which model(GPT-4o or OpenAI o1) is better for multilingual tasks?
Ans. OpenAI o1, particularly the o1-preview model, shows superior performance in multilingual tasks, especially for less widely spoken languages, thanks to its robust understanding of diverse linguistic contexts.
Q3. How does OpenAI o1 handle complex reasoning tasks?
Ans. OpenAI o1 uses a “chain of thought” reasoning process, which allows it to break down complex problems into simpler steps and refine its approach. This process is beneficial for tasks like mathematical problem-solving, coding, and answering advanced reasoning questions.
Q4. What are the limitations of OpenAI o1?
Ans. OpenAI o1 has limited non-STEM knowledge, lacks multimodal capabilities (e.g., image processing), has slower response times, and incurs higher computational costs. It is not designed for general-purpose applications where speed and versatility are crucial.
Q5. When should I choose GPT-4o over OpenAI o1?
Ans. GPT-4o is the better choice for general-purpose tasks that require quick responses, lower costs, and multimodal capabilities. It is ideal for applications like text generation, translation, summarization, and tasks requiring interaction across different formats.
Hi, I am Pankaj Singh Negi - Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.






