Introduction
Retrieval Augmented Generation (RAG) pipelines are improving how AI systems interact with custom data, but two critical components we will focus on here: memory and hybrid search. In this article, we will explore how integrating these powerful features can transform your RAG system from a simple question-answering tool into a context-aware, intelligent conversational agent.
Memory in RAG allows your system to maintain and leverage conversation history, creating more coherent and contextually relevant interactions. Meanwhile, hybrid search combines the semantic understanding of vector search with the precision of keyword-based approaches, significantly enhancing the retrieval accuracy of your RAG pipeline.
In this article, we will be using LlamaIndex to implement both memory and hybrid search using Qdrant as the vector store and Google’s Gemini as our Large Language model.
Learning Objectives
- Gain an implementation understanding of the role of memory in RAG systems and its impact on generating contextually accurate responses.
- Learn to integrate Google’s Gemini LLM and Qdrant Fast Embeddings within the LlamaIndex framework, this is useful as OpenAI is the default LLM and Embed model used in LlamaIndex.
- Develop the implementation of hybrid search techniques using Qdrant Vector store, combining vector and keyword search to enhance retrieval precision in RAG applications.
- Explore the capabilities of Qdrant as a vector store, focusing on its built-in hybrid search functionality and fast embedding features.
This article was published as a part of the Data Science Blogathon.
Table of contents
Hybrid Search in Qdrant
Imagine you’re building a chatbot for a massive e-commerce site. A user asks, “Show me the latest iPhone model.” With traditional vector search, you might get semantically similar results, but you could miss the exact match. Keyword search, on the other hand, might be too rigid. Hybrid search gives you the best of both worlds:
- Vector search captures semantic meaning and context
- Keyword search ensures precision for specific terms
Qdrant is our vector store of choice for this article, and good reason:
- Qdrant makes implementing hybrid search easy by just enabling hybrid parameters when defined.
- It comes with optimized embedding models using Fastembed where the model is loaded in onnx format.
- Qdrant implementation prioritizes protecting sensitive information, offers versatile deployment options, minimizes response times, and reduces operational expenses.
Memory and Hybrid Search using LlamaIndex
We’ll dive into the practical implementation of memory and hybrid search within the LlamaIndex framework, showcasing how these features enhance the capabilities of Retrieval Augmented Generation (RAG) systems. By integrating these components, we can create a more intelligent and context-aware conversational agent that effectively utilizes both historical data and advanced search techniques.
Step 1: Installation Requirements
Alright, let’s break this down step-by-step. We’ll be using LlamaIndex, Qdrant vector store, Fastembed from Qdrant, and the Gemini model from Google. Make sure you have these libraries installed:
!pip install llama-index llama-index-llms-gemini llama-index-vector-stores-qdrant fastembed
!pip install llama-index-embeddings-fastembedStep 2: Define LLM and Embedding Model
First, let’s import our dependencies and set up our API key:
import os
from getpass import getpass
from llama_index.llms.gemini import Gemini
from llama_index.embeddings.fastembed import FastEmbedEmbedding
GOOGLE_API_KEY = getpass("Enter your Gemini API:")
os.environ["GOOGLE_API_KEY"] = GOOGLE_API_KEY
llm = Gemini() # gemini 1.5 flash
embed_model = FastEmbedEmbedding() Now let’s test if the API is currently defined by running that LLM on a sample user query.
llm_response = llm.complete("when was One Piece started?").text
print(llm_response)In LlamaIndex, OpenAI is the default LLM and Embedding model, to override that we need to define Settings from LlamaIndex Core. Here we need to override both LLM and Embed model.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model Step 3: Loading Your Data
For this example, let’s assume we have a PDF in a data folder, we can load the data folder using SimpleDirectory Reader in LlamaIndex.
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data/").load_data()Step 4: Setting Up Qdrant with Hybrid Search
We need to define a QdrantVectorStore instance and set it up in memory for this example. We can also define the qdrant client with its cloud service or localhost, but in our article in memory, a definition with a collection name should do.
Make sure the enable_hybrid=True as this allows us to use Qdrant’s hybrid search capabilities. Our collection name is `paper`, as the data folder contains a PDF on a Research paper on Agents.
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(
location=":memory:",
)
vector_store = QdrantVectorStore(
collection_name = "paper",
client=client,
enable_hybrid=True, # Hybrid Search will take place
batch_size=20,
)Step 5: Indexing your document
By implementing memory and hybrid search in our RAG system, we’ve created a more intelligent and context-a
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
)
Step 6: Querying the Index Query Engine
Indexing is the part where we are defining the retriever and generator chain in LlamaIndex. It processes each document in our document collection and generates embeddings for the content of each document. Then It stores these embeddings in our Qdrant vector store. It creates an index structure that allows for efficient retrieval. While defining the query engine, make sure to query mode in hybrid.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid"
)
response1 = query_engine.query("what is the meaning of life?")
print(response1)
response2 = query_engine.query("give the abstract within 2 sentence")
print(response2)In the above query engine, we run two queries one that is within the context and the other outside the context. Here is the output we got:
Output
#response-1
The provided text focuses on the use of Large Language Models (LLMs) for planning in autonomous agents.
It does not discuss the meaning of life.
#response-2
This document explores the use of large language models (LLMs) as agents for solving complex tasks.
It focuses on two main approaches:
decomposition-first methods,
where the task is broken down into sub-tasks before execution, and
interleaved decomposition methods, which dynamically adjust the decomposition based on feedback. Step 7: Define Memory
While our chatbot is performing well and providing improved responses, it still lacks contextual awareness across multiple interactions. This is where memory comes into the picture.
from llama_index.core.memory import ChatMemoryBuffer
memory = ChatMemoryBuffer.from_defaults(token_limit=3000)Step 8: Creating a Chat Engine with Memory
We’ll create a chat engine that uses both hybrid search and memory. In LlamaIndex for rag-based applications when we have outside or external data make sure the chat mode is context.
chat_engine = index.as_chat_engine(
chat_mode="context",
memory=memory,
system_prompt=(
"You are an AI assistant who answers the user questions"
),
)Step 9: Testing Memory
Let’s run few queries and check if the memory is working as expected or not.
from IPython.display import Markdown, display
check1 = chat_engine.chat("give the abstract within 2 sentence")
check2 = chat_engine.chat("continue the abstract, add one more sentence to the previous two sentence")
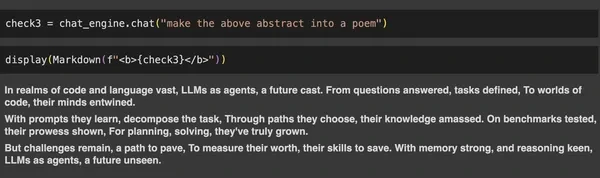
check3 = chat_engine.chat("make the above abstract into a poem")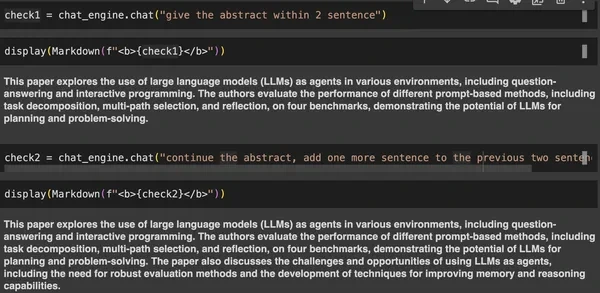
Conclusion
We explored how integrating memory and hybrid search into Retrieval Augmented Generation (RAG) systems significantly enhances their capabilities. By using LlamaIndex with Qdrant as the vector store and Google’s Gemini as the Large Language Model, we demonstrated how hybrid search can combine the strengths of vector and keyword-based retrieval to deliver more precise results. The addition of memory further improved contextual understanding, allowing the chatbot to provide coherent responses across multiple interactions. Together, these features create a more intelligent and context-aware system, making RAG pipelines more effective for complex AI applications.
Key Takeaways
- Implementation of a memory component in the RAG pipeline significantly enhances the chatbot’s contextual awareness and ability to maintain coherent conversations across multiple interactions.
- Integration of hybrid search using Qdrant as the vector store, combining the strengths of both vector and keyword search to improve retrieval accuracy and relevance in the RAG system that minimizes the risk of Hallucination. Disclaimer, it does not completely remove the Hallucination rather reduces the risk.
- Utilization of LlamaIndex’s ChatMemoryBuffer for efficient management of conversation history, with configurable token limits to balance context retention and computational resources.
- Incorporation of Google’s Gemini model as the LLM and embedding provider within the LlamaIndex framework showcases the flexibility of LlamaIndex in accommodating different AI models and embedding techniques.
Frequently Asked Questions
Q1. What is hybrid search, and why is it important in RAG?
A. Hybrid search combines vector search for semantic understanding and keyword search for precision. It improves the accuracy of results by allowing the system to consider both context and exact terms, leading to better retrieval outcomes, especially in complex datasets.
Q2. Why use Qdrant for hybrid search in RAG?
A. Qdrant supports hybrid search out of the box, is optimized for fast embeddings, and is scalable. This makes it a reliable choice for implementing both vector and keyword-based search in RAG systems, ensuring performance at scale.
Q3. How does memory improve RAG systems?
A. Memory in RAG systems enables the retention of conversation history, allowing the chatbot to provide more coherent and contextually accurate responses across interactions, significantly enhancing the user experience.
Q4. Can I use local models instead of cloud-based APIs for RAG applications?
A. Yes, you can run a local LLM (such as Ollama or HuggingFace) instead of using cloud-based APIs like OpenAI. This allows you to maintain full control of your data without uploading it to external servers, which is a common concern for privacy-sensitive applications.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist at AI Planet || YouTube- AIWithTarun || Google Developer Expert in ML || Won 5 AI hackathons || Co-organizer of TensorFlow User Group Bangalore || Pie & AI Ambassador at DeepLearningAI


