Introduction
With the advancement of AI, scientific research has seen a massive transformation. Millions of papers are published annually on different technologies and sectors. But, navigating this ocean of information to retrieve accurate and relevant content is a herculean task. Enter PaperQA, a Retrieval-Augmented Generative (RAG) Agent designed to tackle this exact problem. It is researched and developed by Jakub Lala ´, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G Rodriques, and Andrew D White.
This innovative tool is specifically engineered to assist researchers by retrieving information from full-text scientific papers, synthesizing that data, and generating accurate answers with reliable citations. This article explores PaperQA’s benefits, workings, implementation, and limitations.

Overview
- PaperQA is a Retrieval-Augmented Generative (RAG) tool designed to assist researchers in navigating and extracting information from full-text scientific papers.
- By leveraging Large Language Models (LLMs) and RAG techniques, PaperQA provides accurate, context-rich responses with reliable citations.
- The Agentic RAG Model in PaperQA autonomously retrieves, processes, and synthesizes information, optimizing answers based on complex scientific queries.
- PaperQA performs on par with human experts, achieving similar accuracy rates while being faster and more efficient.
- Despite its strengths, PaperQA relies on the accuracy of retrieved papers and can struggle with ambiguous queries or up-to-date numerical data.
- PaperQA represents a significant step forward in automating scientific research, transforming how researchers retrieve and synthesize complex information.
Table of contents
PaperQA: A Retrieval-Augmented Generative Agent for Scientific Research

As scientific papers continue to multiply exponentially, it’s becoming harder for researchers to sift through the ever-expanding body of literature. In 2022 alone, over five million academic papers were published, adding to the more than 200 million articles currently available. This massive body of research often results in significant findings going unnoticed or taking years to be recognized. Traditional methods, including keyword searches and vector similarity embeddings, only scratch the surface of what’s possible for retrieving pertinent information. These methods are often highly manual, slow, and leave room for oversight.
PaperQA provides a robust solution to this problem by leveraging the potential of Large Language Models (LLMs), combined with Retrieval-Augmented Generation (RAG) techniques. Unlike typical LLMs, which can hallucinate or rely on outdated information, PaperQA uses a dynamic approach to information retrieval, combining the strengths of search engines, evidence gathering, and intelligent answering, all while minimizing errors and improving efficiency. By breaking the standard RAG into modular components, PaperQA adapts to specific research questions and ensures the answers provided are rooted in factual, up-to-date sources.
Also read: A Comprehensive Guide to Building Multimodal RAG Systems
What is Agentic RAG?
The Agentic RAG Model refers to a type of Retrieval-Augmented Generation (RAG) model designed to integrate an agentic approach. In this context, “agentic” implies the model’s capability to act autonomously and decide how to retrieve, process, and generate information. It refers to a system where the model not only retrieves and augments information but also actively manages various tasks or subtasks to optimize for a specific goal.
Break-up of Agentic RAG
- Retrieval-Augmented Generation (RAG): RAG models are designed to combine large language models (LLMs) with a retrieval mechanism. These models generate responses by using internal knowledge (pre-trained data) and dynamically retrieving relevant external documents or information. This improves the model’s ability to respond to queries that require up-to-date or domain-specific information.
- Retrieval: The model retrieves the most relevant documents from a large dataset (such as a corpus of scientific papers).
- Augmented: The generation process is “augmented” by the retrieval step. The retrieval system finds relevant data, which is then used to improve the quality, relevance, and factual accuracy of the generated text. Essentially, external information enhances the model, making it more capable of answering queries beyond its pre-trained knowledge.
- Generation: It generates coherent and contextually relevant answers or text by leveraging both the retrieved documents and its pre-trained knowledge base.
- Agentic: When something is described as “agentic,” it implies that it can autonomously make decisions and perform actions. In the context of an RAG model, an agentic RAG system would have the capability to:
- Autonomously decide which documents or sources to query.
- Prioritize certain documents over others based on the context or user query.
- Break down complex queries into sub-queries and handle them independently.
- Use a strategic approach to select information that best meets the goal of the task at hand.
Also read: Unveiling Retrieval Augmented Generation (RAG)| Where AI Meets Human Knowledge
PaperQA as an Agentic RAG Model
PaperQA is engineered specifically to be an agentic RAG model designed for working with scientific papers. This means it is particularly optimized for tasks like:
- Retrieving specific, highly relevant academic papers or sections of papers.
- Answering detailed scientific queries by parsing and synthesizing information from multiple documents.
- Breaking down complex scientific questions into manageable pieces and autonomously deciding the best retrieval and generation strategy.
Why is PaperQA ideal for working with scientific papers?
- Complex information retrieval: Scientific papers often contain dense, technical information. PaperQA2 can navigate through this complexity by autonomously finding the most relevant sections of a paper or a group of papers.
- Multi-document synthesis: Rather than relying on a single source, it can pull in multiple papers, combine insights, and synthesize a more comprehensive answer.
- Specialization: PaperQA2 is likely trained or optimized for scientific language and contexts, allowing it to excel in this specific domain.
In summary, the Agentic RAG Model is a sophisticated system that retrieves relevant information and generates responses, and autonomously manages tasks to ensure efficiency and relevance. PaperQA2 applies this model to the domain of scientific papers, making it highly effective for academic and research purposes.
Also read: Enhancing RAG with Retrieval Augmented Fine-tuning
PaperQA: Working and Tools
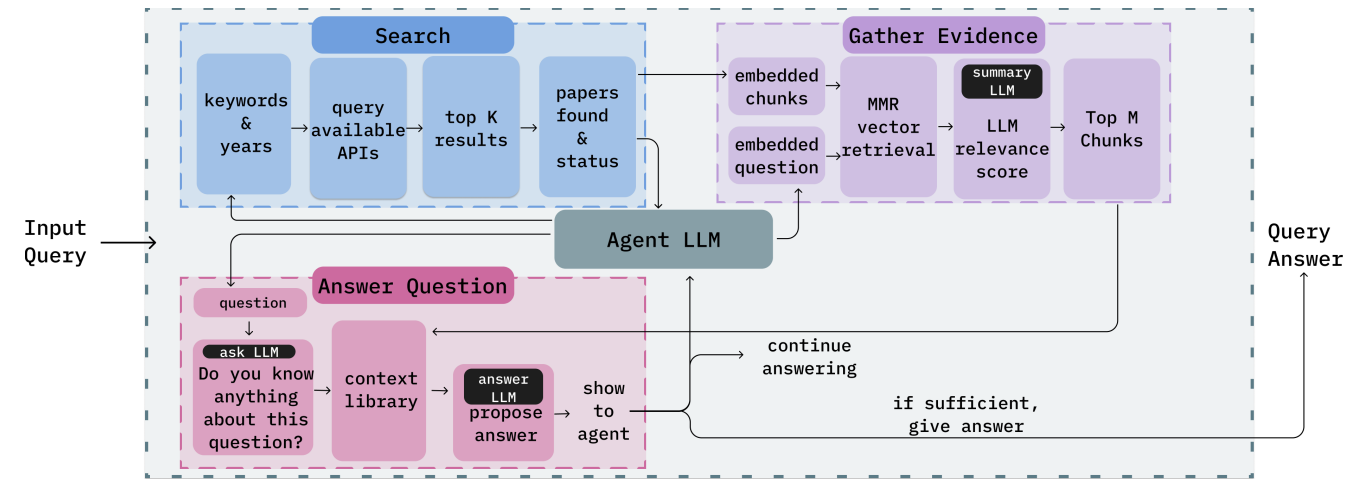
The PaperQA system is composed of:

Input Query
The process begins with an input query that the user enters. This could be a question or a search topic that requires an answer based on scientific papers.
Search Stage
- Keywords & Years: The input query is processed, and keywords or relevant years are extracted.
- Query Available APIs: The system queries various available APIs for scientific papers, possibly from databases like arXiv, PubMed, or other repositories.
- Top K Results: The top K results are retrieved based on the relevance and status of the papers (whether they’re accessible, peer-reviewed, etc.).
Gather Evidence Stage
- Embedded Chunks: The system breaks down the relevant papers into embedded chunks, smaller, manageable text segments.
- MMR Vector Retrieval: The Maximum Marginal Relevance (MMR) technique is used to retrieve the most relevant evidence from the papers.
- Summary LLM: A language model (LLM) summarizes the evidence extracted from the chunks.
- LLM Relevance Score: The LLM scores the relevance of the summarized information to assess its alignment with the input query.
- Top M Chunks: The top M most relevant chunks are selected for further processing.
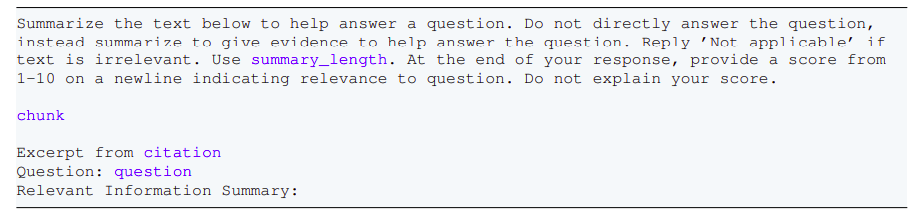
Answer Question Stage
- Question & Context Library: The input query is analyzed, and the system checks its internal context library to see if it has prior knowledge or answers related to the question.
- Ask LLM (Do you know anything about this question?): The system asks the LLM if it has any prior understanding or context to answer the query directly.
- Answer LLM Proposes Answer: The LLM proposes an answer based on the evidence gathered and the context of the question.
- Show to Agent: The proposed answer is shown to an agent (which could be a human reviewer or a higher-level LLM for final verification).
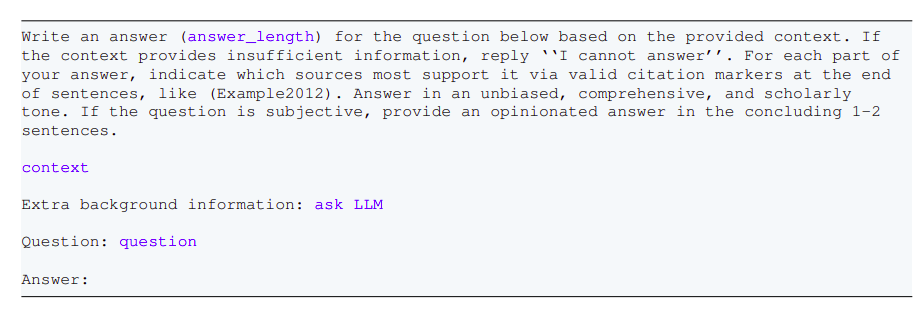
Completion of Answering
- The process is completed if the answer is sufficient and the final Query Answer is provided to the user.
- If the answer is insufficient, the process loops back, and the LLM continues gathering evidence or rephrasing the input query to fetch better results.
This overall structure ensures that PaperQA can effectively search, retrieve, summarize, and synthesize information from large collections of scientific papers to provide a thorough and relevant answer to a user’s query. The key advantage is its ability to break down complex scientific content, apply intelligent retrieval methods, and provide evidence-based answers.
These tools work in harmony, allowing PaperQA to collect multiple pieces of evidence from various sources, ensuring a thorough, evidence-based answer is generated. The entire process is managed by a central LLM agent, which dynamically adjusts its strategy based on the query’s complexity.
The LitQA Dataset
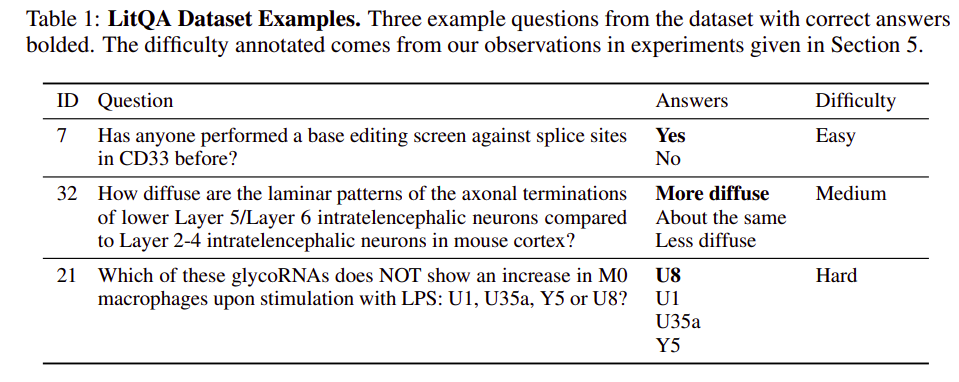
The LitQA dataset was developed to measure PaperQA’s performance. This dataset consists of 50 multiple-choice questions derived from recent scientific literature (post-September 2021). The questions span various domains in biomedical research, requiring PaperQA to retrieve information and synthesize it across multiple documents. LitQA provides a rigorous benchmark that goes beyond typical multiple-choice science QA datasets, requiring PaperQA to engage in full-text retrieval and synthesis, tasks closer to those performed by human researchers.
How Does PaperQA Compare to Expert Humans?
In evaluating PaperQA’s performance on LitQA, the system was found to be highly competitive with expert human researchers. When researchers and PaperQA were given the same set of questions, PaperQA performed on par with humans, showing a similar accuracy rate (69.5% versus 66.8% for humans). Moreover, PaperQA was faster and more cost-effective, answering all questions in 2.4 hours compared to 2.5 hours for human experts. One notable strength of PaperQA is its lower rate of answering incorrectly, as it is calibrated to acknowledge uncertainty when evidence is lacking, further reducing the risk of incorrect conclusions.
PaperQA Implementation
The PaperQA system is built on the LangChain agent framework and utilizes multiple LLMs, including GPT-3.5 and GPT-4, each assigned to different tasks (e.g., summarizing and answering). The system pulls papers from various databases, uses a map-reduce approach to gather and summarize evidence, and generates final answers in a scholarly tone with complete citations. Importantly, PaperQA’s modular design allows it to rephrase questions, adjust search terms, and retry steps, ensuring accuracy and relevance.
How to Use PaperQA via Command Line?
Step 1: Install the required library
Run the following command to install paper-qa:
pip install paper-qaStep 2: Set up your research folder
Create a folder and place your research paper(s) in it. For example, I’ve added the paper titled “Attention is All You Need.”
Step 3: Navigate to your folder
Use the following command to navigate to the folder:
cd folder-nameStep 4: Ask your question
Run the following command to ask about a topic:
pqa ask "What is transformers?"Result:

Source and Citations in the Output
- CrossRef: CrossRef is an official database that provides Digital Object Identifiers (DOIs) for academic papers. However, it looks like the search was not able to connect successfully to CrossRef, likely because the necessary environment variables were not set (
CROSSREF_API_KEYis missing). This means CrossRef couldn’t be used as a data source for this search. - Semantic Scholar: Similarly, it attempted to query Semantic Scholar, a popular academic search engine, but the connection failed due to missing an API key (
SEMANTIC_SCHOLAR_API_KEYis not set). This resulted in a timeout, and no metadata was retrieved. - The system points to specific pages of the paper (e.g., Vaswani2023 pages 2-3) to ensure that the reader can verify or further explore the source material. This could be particularly useful in academic or research settings.
Accessing using Python
Importing Libraries
import os
from dotenv import load_dotenv
from paperqa import Settings, agent_query, QueryRequest- os: A module providing functions to interact with the operating system, such as working with file paths and environment variables.
- dotenv: A module used to load environment variables from a .env file into the environment.
- paperqa: A module from the paperqa library that allows querying scientific papers. It provides classes and functions like Settings, agent_query, and QueryRequest for configuring and running queries.
Loading API Keys
load_dotenv()- This function loads the environment variables from a .env file, typically used to store sensitive information like API keys, file paths, or other configurations.
- Calling load_dotenv() ensures that the environment variables are available for the script to access.
Querying the PaperQA System
answer = await agent_query(
QueryRequest(
query="What is transformers? ",
settings=Settings(temperature=0.5, paper_directory="/home/badrinarayan/paper-qa"),
)
)Here’s an explanation of the code, broken down into a structured and clear format:
Code Breakdown and Explanation
1. Importing Libraries
pip install paper-qaimport os
from dotenv import load_dotenv
from paperqa import Settings, agent_query, QueryRequest
- os: A module providing functions to interact with the operating system, such as working with file paths and environment variables.
- dotenv: A module used to load environment variables from a
.envfile into the environment. - paperqa: A module from the
paperqalibrary that allows querying scientific papers. It provides classes and functions likeSettings,agent_query, andQueryRequestfor configuring and running queries.
2. Loading Environment Variables
load_dotenv()- This function loads the environment variables from a
.envfile, typically used to store sensitive information like API keys, file paths, or other configurations. - By calling
load_dotenv(), it ensures that the environment variables are available to be accessed in the script.
3. Querying the PaperQA System
answer = await agent_query(
QueryRequest(
query="What is transformers? ",
settings=Settings(temperature=0.5, paper_directory="/home/badrinarayan/paper-qa"),
)
)This part of the code queries the PaperQA system using an agent and structured request. It performs the following steps:
agent_query(): This is an asynchronous function used to send a query to the PaperQA system.- It’s expected to be called with the
awaitkeyword since it is anasyncfunction, meaning it runs concurrently with other code while awaiting the result.
- It’s expected to be called with the
QueryRequest: This defines the structure of the query request. It takes the query and settings as parameters. In this case:- query:
"What is transformers?"is the research question being asked of the system. It expects an answer drawn from the papers in the specified directory. - settings: This passes an instance of
Settingsto configure the query, which includes:- temperature: Controls the “creativity” of the answer generated. Lower values like
0.5make the response more deterministic (factual), while higher values generate more varied answers. - paper_directory: Specifies the directory where PaperQA should look for research papers to query, in this case,
"/home/badrinarayan/paper-qa".
- temperature: Controls the “creativity” of the answer generated. Lower values like
- query:
OUTPUT
Question: What is transformers?
The Transformer is a neural network architecture designed for sequence
transduction tasks, such as machine translation, that relies entirely on
attention mechanisms, eliminating the need for recurrence and convolutions.
It features an encoder-decoder structure, where both the encoder and decoder
consist of a stack of six identical layers. Each encoder layer includes a
multi-head self-attention mechanism and a position-wise fully connected
feed-forward network, employing residual connections and layer
normalization. The decoder incorporates an additional sub-layer for multi-
head attention over the encoder's output and uses masking to ensure auto-
regressive generation (Vaswani2023 pages 2-3).
The Transformer improves parallelization and reduces training time compared
to recurrent models, achieving state-of-the-art results in translation
tasks. It set a BLEU score of 28.4 on the WMT 2014 English-to-German task
and 41.8 on the English-to-French task after training for 3.5 days on eight
GPUs (Vaswani2023 pages 1-2). The model's efficiency is further enhanced by
reducing the number of operations needed to relate signals from different
positions to a constant, leveraging Multi-Head Attention to maintain
effective resolution (Vaswani2023 pages 2-2).
In addition to translation, the Transformer has demonstrated strong
performance in tasks like English constituency parsing, achieving high F1
scores in both supervised and semi-supervised settings (Vaswani2023 pages 9-
10).
References
1. (Vaswani2023 pages 2-3): Vaswani, Ashish, et al. "Attention Is All You
Need." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.
2. (Vaswani2023 pages 1-2): Vaswani, Ashish, et al. "Attention Is All You
Need." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.
3. (Vaswani2023 pages 9-10): Vaswani, Ashish, et al. "Attention Is All You
Need." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.
4. (Vaswani2023 pages 2-2): Vaswani, Ashish, et al. "Attention Is All You
Need." arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7. Accessed 2024.
Source and Citations in the Output
The system appears to rely on external databases, such as academic databases or repositories, to answer the question. Based on the references, it’s highly likely that this particular system is querying sources like:
- arXiv.org: A well-known open-access repository for research papers, particularly focused on computer science, artificial intelligence, and machine learning fields. The references to “arXiv, 2 Aug. 2023, arxiv.org/abs/1706.03762v7” point directly to the seminal paper “Attention is All You Need” by Ashish Vaswani et al. (2017), which introduced the Transformer model.
- Other potential sources that could be queried include academic repositories like Semantic Scholar, Google Scholar, or PubMed, depending on the topic. However, for this specific task, it seems like the system primarily relied on arXiv due to the nature of the paper cited.
- The system points to specific pages of the paper (e.g., Vaswani2023 pages 2-3) to ensure that the reader can verify or further explore the source material. This could be particularly useful in academic or research settings.
Limitations of PaperQA
Despite its strengths, PaperQA is not without limitations. First, its reliance on existing research papers means it assumes that the information in the sources is accurate. If faulty papers are retrieved, PaperQA’s answers could be flawed. Moreover, the system can struggle with ambiguous or vague queries that don’t align with the available literature. Finally, while the system effectively synthesizes information from full-text papers, it cannot yet handle real-time calculations or tasks that require up-to-date numerical data.
Conclusion
In conclusion, PaperQA represents a leap forward in the automation of scientific research. By integrating retrieval-augmented generation with intelligent agents, PaperQA transforms the research process, cutting down the time needed to find and synthesize information from complex literature. Its ability to dynamically adjust, retrieve full-text papers, and iterate on answers brings the world of scientific question-answering one step closer to human-level expertise, but with a fraction of the cost and time. As science advances at breakneck speed, tools like PaperQA will play a pivotal role in ensuring researchers can keep up and push the boundaries of innovation.
Also, check out the new course on AI Agent: Introduction to AI Agents
Frequently Asked Questions
Q1. What is PaperQA?
Ans. PaperQA is a Retrieval-Augmented Generative (RAG) tool designed to help researchers navigate and extract relevant information from full-text scientific papers, synthesizing answers with reliable citations.
Q2. How does PaperQA differ from traditional search tools?
Ans. Unlike traditional search tools that rely on keyword searches, PaperQA uses Large Language Models (LLMs) combined with retrieval mechanisms to pull data from multiple documents, generating more accurate and context-rich responses.
Q3. What is the Agentic RAG Model in PaperQA?
Ans. The Agentic RAG Model allows PaperQA to autonomously retrieve, process, and generate information by breaking down queries, managing tasks, and optimizing responses using an agentic approach.
Q4. How does PaperQA perform compared to human experts?
Ans. PaperQA competes well with human researchers, achieving similar accuracy rates (around 69.5%) while answering questions faster and with fewer errors.
Q5. What are the limitations of PaperQA?
Ans. PaperQA’s limitations include potential reliance on faulty sources, difficulty with ambiguous queries, and an inability to perform real-time calculations or handle up-to-date numerical data.
Hi, I am Pankaj Singh Negi - Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.





