If you are asked to explain RAG in English to someone who doesn’t understand a single word in that language—it will be challenging for you, right? Now, think about machines(that don’t understand human language) – when they try to make sense of human language, images, or even music. This is where vector embeddings come to the rescue! They provide a powerful way for complex, high-dimensional data (like text or images) to be translated into simple and dense numerical representations, making it much easier for the algorithms to “understand” and operate such data.
In this post, we will discuss the meaning of vector embeddings, the different types of embeddings, and why they are important for generative AI going forward. On top of this, we’ll show you how to use embeddings for yourself on the most common platforms like Cohere and Hugging Face. Excited to unlock the world of embeddings and experience the AI magic embedded within? Let’s dig in!
Overview
- Vector embeddings transform complex data into simplified numerical representations for AI models to process it more easily.
- Embeddings represent data points as vectors, with proximity in vector space indicating semantic similarity.
- Different types of word, sentence, and image embeddings serve specific AI tasks such as search and classification.
- Generative AI relies on embeddings to understand context and generate relevant content across text, images, and more.
- Tools like Cohere and Hugging Face provide easy access to pre-trained models for generating vector embeddings.
Table of contents
- What are Vector Embeddings?
- Why Are Embeddings Important?
- Types of Vector Embeddings
- Relevance of Vector Embeddings in Generative AI
- How to Use Cohere for Vector Embeddings?
- How to Use Hugging Face for Vector Embeddings?
- Vector Embeddings and Cosine Similarity
- Relation between Vector Embeddings and Cosine Similarity
- Conclusion
What are Vector Embeddings?

Vector Embeddings are the mathematical representations of data points in a continuous vector space. Embeddings, simply put, are a way to map data into a fixed-dimensional vector space where similar data are placed close together in this new space.
For example, in text, embeddings transform words, phrases, or entire sentences into dense vectors, where the distance between two vectors signifies their semantic similarity. This numerical representation makes it easier for machine learning models to work with various forms of unstructured data, such as text, images, or even video.
Here’s the pictorial representation:

Here’s the explanation of each step:
Input Data:
- The left side of the diagram shows various types of data like Images, Documents, and Audio.
- These different data types are transformed into embeddings (dense vector representations). The idea is to convert complex data like images or text into numerical vectors that encode their key features or semantic meaning.
Transform into Embedding:
- Each input data type is processed using pre-trained models (e.g., neural networks and transformers) that have been trained on vast amounts of data. These models enable them to generate embeddings—dense numerical vectors where each number captures some aspect of the content.
- For example, sentences from documents or features of images are represented as high-dimensional vectors.
Vector Representation:
- After the transformation, the data is represented as a vector (shown as [ … ]). Each vector is a dense array of numbers.
- These embeddings can be considered points in a high-dimensional space where similar data points are positioned closer while dissimilar ones are farther apart.
Nearest Neighbor Search:
- The key idea of vector search is to find the vectors closest to a query vector using a nearest neighbor algorithm.
- When a new query is received (on the right side of the diagram), it is also transformed into a vector (embedding). The system then compares this query vector with all the stored embeddings to find the nearest ones—i.e., the vectors most similar to the query.
Results:
- Based on this nearest neighbor comparison, the system retrieves the most similar items (images, documents, or audio) and returns them as results.
- These results are typically ranked based on similarity scores.
Why Are Embeddings Important?
- Dimensionality Reduction: Embeddings reduce high-dimensional, sparse data (like words in a large vocabulary) into low-dimensional, dense vectors. This process preserves the semantic relationships while significantly reducing computational complexity.
- Semantic Similarity: The primary purpose of embeddings is to capture the context and meaning of data. Words like “king” and “queen” will be closer to each other in the vector space than unrelated words like “king” and “apple.”
- Model Input: Embeddings are fed into models for tasks like classification, generation, translation, and clustering. They convert raw input into a format that models can efficiently process.
Mathematical Representation
Given a dataset D={x1,x2,…,xn}, embeddings transform each data point xi into a vector vi such that:
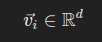
Where d is the dimension of the vector embedding, for instance, for word embeddings, a word www from the dataset is mapped to a vector vw that captures the semantics of the word in the context of the entire dataset.
Types of Vector Embeddings
Various types of embeddings exist depending on the kind of data and the specific task at hand. Let’s explore some of the most common types.
1. Word Embeddings
Word embeddings are representations of individual words. Popular models for generating word embeddings include:
- Word2Vec: Maps words to dense vectors based on their co-occurrence in a local context.
- GloVe: Global Vectors for Word Representation, trained on word co-occurrence counts over a corpus.
- FastText: An extension of Word2Vec that also accounts for subword information.
Use Case: Sentiment analysis, part-of-speech tagging, and machine translation.
2. Sentence Embeddings
Sentence embeddings represent entire sentences, capturing their meaning in a high-dimensional vector space. They are particularly useful when context beyond single words is important.
- BERT (Bidirectional Encoder Representations from Transformers): A pre-trained transformer model that generates contextualized sentence embeddings.
- Sentence-BERT: A modification of BERT that allows for faster and more efficient sentence comparison.
- InferSent: An older method for generating sentence embeddings focusing on natural language inference.
Use Case: Semantic textual similarity, paraphrase detection, and question-answering systems.
3. Document Embeddings
Document embeddings represent entire documents. They aggregate sentence or word embeddings over the document’s length to provide a global understanding of its contents.
- Doc2Vec: An extension of Word2Vec for representing entire documents as vectors.
- Transformer-based models (e.g., BERT, GPT): Typically used to derive document-level embeddings by processing the entire document, utilizing self-attention to generate more contextualized embeddings.
Use Case: Document classification, topic modeling, and summarization.
4. Image and Multimodal Embeddings
Embeddings can represent other data types, such as images, audio, and video, in addition to text. They can be combined with text embeddings for multimodal applications.
- Image embeddings: Tools like CLIP (Contrastive Language-Image Pretraining) map images and text into a shared embedding space, enabling tasks like image captioning and visual search.
Use Case: Multimodal AI, visual search, and content generation.
Relevance of Vector Embeddings in Generative AI
Generative AI models like GPT heavily rely on embeddings to understand and generate content. These embeddings allow generative models to comprehend context, patterns, and relationships within data, which are essential for generating meaningful output.
Embeddings Power Key Aspects of Generative AI:
- Semantic Understanding: Embeddings allow generative models to grasp the semantics of language (or images), meaning we can write or generate coherent and relevant things in context.
- Content Generation: Generative models use embeddings as input to generate new data, be it text, images, or music. For example, GPT models use embeddings to generate human-like text based on a given prompt.
- Multimodal Applications: Embeddings allow models to combine multiple forms of data (like text and images) to generate creative outputs, such as image captions, text-to-image models, and cross-modal retrieval.
How to Use Cohere for Vector Embeddings?
Cohere is a platform that provides pre-trained language models optimized for tasks like text generation and embeddings. It offer API access to powerful embeddings for various downstream tasks, including search, classification, clustering, and recommendation systems.
Using Cohere’s Embedding API
Cohere offers an easy-to-use API to generate embeddings for text. Here’s a quick guide to getting started:
Install the Cohere SDK:
!pip install cohereGenerate Text Embeddings: After getting your API key, you can generate embeddings for text data as follows:
import cohere
co = cohere.Client(‘Your_Api_key’)
response = co.embed(
texts=[‘I HAVE ALWAYS BELIEVED THAT YOU SHOULD NEVER, EVER GIVE UP AND YOU SHOULD ALWAYS KEEP FIGHTING EVEN WHEN THERE’S ONLY A SLIGHTEST CHANCE.'],
model='embed-english-v3.0',
input_type='classification'
)
print(response)OUTPUT

Output Explanation:
- Embedded Vector: This is the core part of the output. It is a list of floating-point numbers (in this case, 1280 floats) that represents the contextual encoding for the input text. Embeddings are basically a dense vector representation of the text. This means that each number in our array is now capturing some key information about the meaning, structure, or sentiment of your text.
How to Use Hugging Face for Vector Embeddings?
Hugging Face provides a massive repository of pre-trained models for NLP and other domains and tools to fine-tune and generate embeddings.
Using Hugging Face for Embeddings with Transformers
Hugging Face’s Transformers library is a popular framework for generating embeddings using pre-trained models like BERT, RoBERTa, DistilBERT, etc.
Install the Transformers Library:
!pip install transformers
!pip install torch # if you don't already have PyTorch installedGenerate Sentence Embeddings: Use a pre-trained model to create embeddings for your text.
from transformers import BertTokenizer, BertModel
import torch
# Load the tokenizer and model from Hugging Face
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# Example text
texts = ["I am from India", "I was born in India"]
# Tokenize the input text
inputs = tokenizer(texts, return_tensors='pt', padding=True, truncation=True)
# Pass inputs through the model
with torch.no_grad():
outputs = model(**inputs)
# Get the hidden states (embeddings)
hidden_states = outputs.last_hidden_state
# For sentence embeddings, you might want to use the pooled output,
# which is a [CLS] token embedding representing the entire sentence
sentence_embeddings = outputs.pooler_output
print(sentence_embeddings)
sentence_embeddings.shapeOUTPUT

Output Explanation
The output tensor has the shape [2, 768]. This indicates there are 2 sentences, each represented by a 768-dimensional vector. Each row corresponds to a different sentence:
- The first row represents the sentence “I am from India.”
- The second row represents the sentence, “I was born in India.”
Each number in the row is a value in the 768-dimensional embedding space. These values represent the features BERT extracted from the sentences, capturing aspects like meaning, context, and relationships between words.
2Refers to the number of sentences (two input sentences).768Refers to the size of the sentence embedding vector, which is standard for thebert-base-uncasedmodel.
Vector Embeddings and Cosine Similarity

Vector Embeddings
Reiterating, in natural language processing, vector embeddings represent words, sentences, or other textual elements as numerical vectors in a high-dimensional space. These vectors encode semantic information about the text, allowing models to capture relationships between words or sentences. Pre-trained models like BERT, RoBERTa, and GPT generate embeddings for text by projecting the input text into this high-dimensional space.
Cosine Similarity
Cosine similarity measures how two vectors are similar in direction rather than magnitude. It is particularly useful when comparing high-dimensional vector embeddings in NLP, as the vectors’ actual length (magnitude) is often less important than their orientation in the vector space.
Cosine similarity is a metric used to measure the angle between two vectors. It is calculated as:
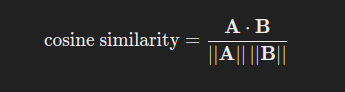
Where:
- A⋅B is the dot product of vectors A and B
- ∥A∥ and ∥B∥ are the magnitudes (lengths) of the vectors.
Relation between Vector Embeddings and Cosine Similarity
Here’s the relation:
- Measuring Similarity: One of the most popular ways of calculating similarity is through cosine similarity for vector embeddings in NLP. That is, if you have two sentence embeddings from BERT — the cosine similarity will give you a score between 0 to 1 that tells you how contextually similar the sentences are.
- Directional Similarity: Since embeddings often reside in a very high-dimensional space, cosine similarity focuses on the angle between the vectors, ignoring their magnitude. This is important because embeddings often encode relative semantic relationships, so two vectors pointing in a similar direction represent similar meanings, even if their magnitudes differ.
- Applications:
- Sentence/Document Similarity: Cosine similarity measures the semantic distance between two sentence embeddings. A value near 1 indicates a very high similarity between two sentences, while a value nearer to 0 or negative means there is less or no similarity between the sentences.
- Clustering: Embeddings with similar cosine similarity can be clustered together in document clustering or for topic modeling.
- Information Retrieval: When searching through a corpus, cosine similarity can help identify documents or sentences most similar to a given query based on their vector representations.
For instance:
Here are two sentences:
- “I love programming.”
- “I enjoy coding.”
These two sentences have different words but are semantically similar. After passing these sentences through a model like BERT, you obtain two different vector embeddings. By computing the cosine similarity between these vectors, you would likely get a value close to 1, indicating strong semantic similarity.
If you compare a sentence like “I love programming” with something unrelated, like “It is raining outside”, the cosine similarity between their embeddings will likely be much lower, closer to 0, indicating little semantic overlap.
Here is the cosine similarity of the text we used earlier:
from sklearn.metrics.pairwise import cosine_similarity
# Convert to numpy arrays for cosine similarity computation
embedding1 = sentence_embeddings[0].numpy().reshape(1, -1)
embedding2 = sentence_embeddings[1].numpy().reshape(1, -1)
# These are the sentences, “Hello, how are you?", "I work in India!”
# Compute cosine similarity
similarity = cosine_similarity(embedding1, embedding2)
print(f"Cosine similarity between the two sentences: {similarity[0][0]}")OUTPUT

Output Explanation:
0.9208 suggests that the two sentences have a very strong similarity in their semantic content, meaning they are likely discussing similar topics or expressing similar ideas.
If this value had been closer to 1, it would indicate near-identical meaning, whereas a value closer to 0 would indicate no semantic similarity between the sentences. Values closer to -1 (though uncommon in this case) would indicate opposing meanings.
In Summary:
- Vector embeddings capture the semantics of words, sentences, or documents as high-dimensional vectors.
- Cosine similarity quantifies how similar two vectors are by looking at the angle between them, making it a useful metric for comparing embeddings.
- The smaller the angle (closer to 1), the more semantically related the embeddings are.
Conclusion
Vector embeddings are foundational in NLP and generative AI. They convert raw data into meaningful numerical representations that models can easily process. Cohere and Hugging Face are two powerful platforms that offer simple and effective ways to generate embeddings for a wide range of applications, from semantic search to clustering and recommendation systems.
Understanding how to leverage these platforms effectively will unlock tremendous potential for building smarter, more context-aware AI systems, particularly in the ever-growing field of generative AI.
Hope you like the article! Vector embeddings are essential in AI, enabling models like Hugging Face and Cohere to represent text numerically. For example, a vector embedding example could illustrate how similar phrases are clustered. These techniques enhance semantic search capabilities, making vector embeddings crucial for modern AI applications.
Also, if you are looking for a Generative AI course online, then explore: the GenAI Pinnacle Program
Q1. What is a vector embedding?
Ans. A vector embedding is a mathematical representation that converts data, like text or images, into dense numerical vectors in a high-dimensional space, preserving their meaning and relationships.
Q2. Why are vector embeddings important in AI?
Ans. Vector embeddings simplify complex data, making it easier for AI models to process and understand unstructured data, like language or images, for tasks like classification, search, and generation.
Q3. How are vector embeddings used in natural language processing (NLP)?
Ans. In NLP, vector embeddings represent words, sentences, or documents as vectors, allowing models to capture semantic similarities and differences between textual elements.
Q4. What’s the role of cosine similarity in vector embeddings?
Ans. Cosine similarity measures the angle between two vectors, helping determine how similar two embeddings are based on their direction in the vector space, commonly used in search and clustering.
Q5. What are some common types of vector embeddings?
Ans. Common types include word embeddings (e.g., Word2Vec, GloVe), sentence embeddings (e.g., BERT), and document embeddings (e.g., Doc2Vec), each designed to capture different levels of semantic information.
Hi, I am Pankaj Singh Negi - Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.





