As large language models (LLMs) continue to grow in scale, so does the need for efficient ways to store, deploy, and run them on low-resource devices. While these models offer powerful capabilities, their size and memory demands can make deployment a challenge, especially on consumer hardware. This is where model quantization and specialized storage formats like GGUF (Generic GPT Unified Format) come into play.
In this guide, we’ll delve into the GGUF format, explore its benefits, and provide a step-by-step tutorial on converting models to GGUF. Along the way, we’ll touch on the history of model quantization and how GGUF evolved to support modern LLMs. By the end, you’ll have a deep understanding of why GGUF matters and how to start using it for your own models.
Learning Objectives
- Comprehend the purpose and structure of the GGUF format and its evolution from GGML.
- Define quantization and describe its significance in reducing model size and improving deployment efficiency.
- Recognize the components of the GGUF naming convention and how they aid in model identification and management.
- Use llama.cpp to quantize models to gguf format.
- Relate the concepts of GGUF and quantization to practical use cases, enabling effective deployment of AI models in resource-constrained environments.
This article was published as a part of the Data Science Blogathon.
Table of contents
Evolution of Model Quantization
The journey toward GGUF begins with understanding the evolution of model quantization. Quantization reduces the precision of model parameters, effectively compressing them to reduce memory and computational demands. Here’s a quick overview:
Early Formats and Challenges
In the early days, deep learning models were stored in the native formats of frameworks like TensorFlow and PyTorch. TensorFlow models used .pb files, while PyTorch used .pt or .pth. These formats worked for smaller models but presented limitations:
- Size: Models were stored in 32-bit floating-point format, making file sizes large.
- Memory Use: Full-precision weights demanded considerable memory, making deployment on devices with limited RAM impractical.
ONNX (Open Neural Network Exchange)
The rise of interoperability across frameworks led to the development of ONNX, which allowed models to move between environments. However, while ONNX provided some optimizations, it was still primarily built around full-precision weights and offered limited quantization support.
Need for Quantization
As models grew larger, researchers turned to quantization, which compresses weights from 32-bit floats (FP32) to 16-bit (FP16) or even lower, like 8-bit integers (INT8). This approach cut memory requirements significantly, making it possible to run models on more hardware types. For example:
# Import necessary libraries
import torch
import torch.nn as nn
import torch.quantization as quant
# Step 1: Define a simple neural network model in PyTorch
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50) # First fully connected layer
self.fc2 = nn.Linear(50, 20) # Second fully connected layer
self.fc3 = nn.Linear(20, 5) # Output layer
def forward(self, x):
x = torch.relu(self.fc1(x)) # ReLU activation after first layer
x = torch.relu(self.fc2(x)) # ReLU activation after second layer
x = self.fc3(x) # Output layer
return x
# Step 2: Initialize the model and switch to evaluation mode
model = SimpleModel()
model.eval()
# Save the model before quantization for reference
torch.save(model, "simple_model.pth")
# Step 3: Apply dynamic quantization to the model
# Here, we quantize only the Linear layers, changing their weights to INT8
quantized_model = quant.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# Save the quantized model
torch.save(quantized_model, "quantized_simple_model.pth")
# Example usage of the quantized model with dummy data
dummy_input = torch.randn(1, 10) # Example input tensor with 10 features
output = quantized_model(dummy_input)
print("Quantized model output:", output)

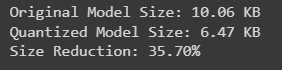
Checking the size of original and quantized model
When working with large language models, understanding the size difference between the original and quantized versions is crucial. This comparison not only highlights the benefits of model compression but also informs deployment strategies for efficient resource usage.
import os
# Paths to the saved models
original_model_path = "simple_model.pth"
quantized_model_path = "quantized_simple_model.pth"
# Function to get file size in KB
def get_file_size(path):
size_bytes = os.path.getsize(path)
size_kb = size_bytes / 1024 # Convert to KB
return size_kb
# Check the sizes of the original and quantized models
original_size = get_file_size(original_model_path)
quantized_size = get_file_size(quantized_model_path)
print(f"Original Model Size: {original_size:.2f} KB")
print(f"Quantized Model Size: {quantized_size:.2f} KB")
print(f"Size Reduction: {((original_size - quantized_size) / original_size) * 100:.2f}%")
However, even 8-bit precision was insufficient for extremely large language models like GPT-3 or LLaMA, which spurred the development of new formats like GGML and, eventually, GGUF.
What is GGUF?
GGUF, or Generic GPT Unified Format, was developed as an extension to GGML to support even larger models. It is a file format for storing models for inference with GGML and executors based on GGML. GGUF is a binary format that is designed for fast loading and saving of models, and for ease of reading. Models are traditionally developed using PyTorch or another framework, and then converted to GGUF for use in GGML.
GGUF is a successor file format to GGML, GGMF and GGJT, and is designed to be unambiguous by containing all the information needed to load a model. It is also designed to be extensible, so that new information can be added to models without breaking compatibility. It was designed with three goals in mind:
- Efficiency: Enables large models to run efficiently on CPUs and consumer-grade hardware.
- Scalability: Supports very large models, often 100GB or more.
- Flexibility: Allows developers to choose between different quantization levels, balancing model size and accuracy.
Why Use GGUF?
The GGUF format shines for developers who need to deploy large, resource-heavy models on limited hardware without sacrificing performance. Here are some core advantages:
- Quantization Support: GGUF supports a range of quantization levels (4-bit, 8-bit), allowing for significant memory savings while maintaining model precision.
- Metadata Storage: GGUF can store detailed metadata, such as model architecture, tokenization schemes, and quantization levels. This metadata makes it easier to load and configure models.
- Inference Optimization: GGUF optimizes memory use, allowing for faster inference on CPU-based systems.
GGUF Format Structure and Naming Conventions
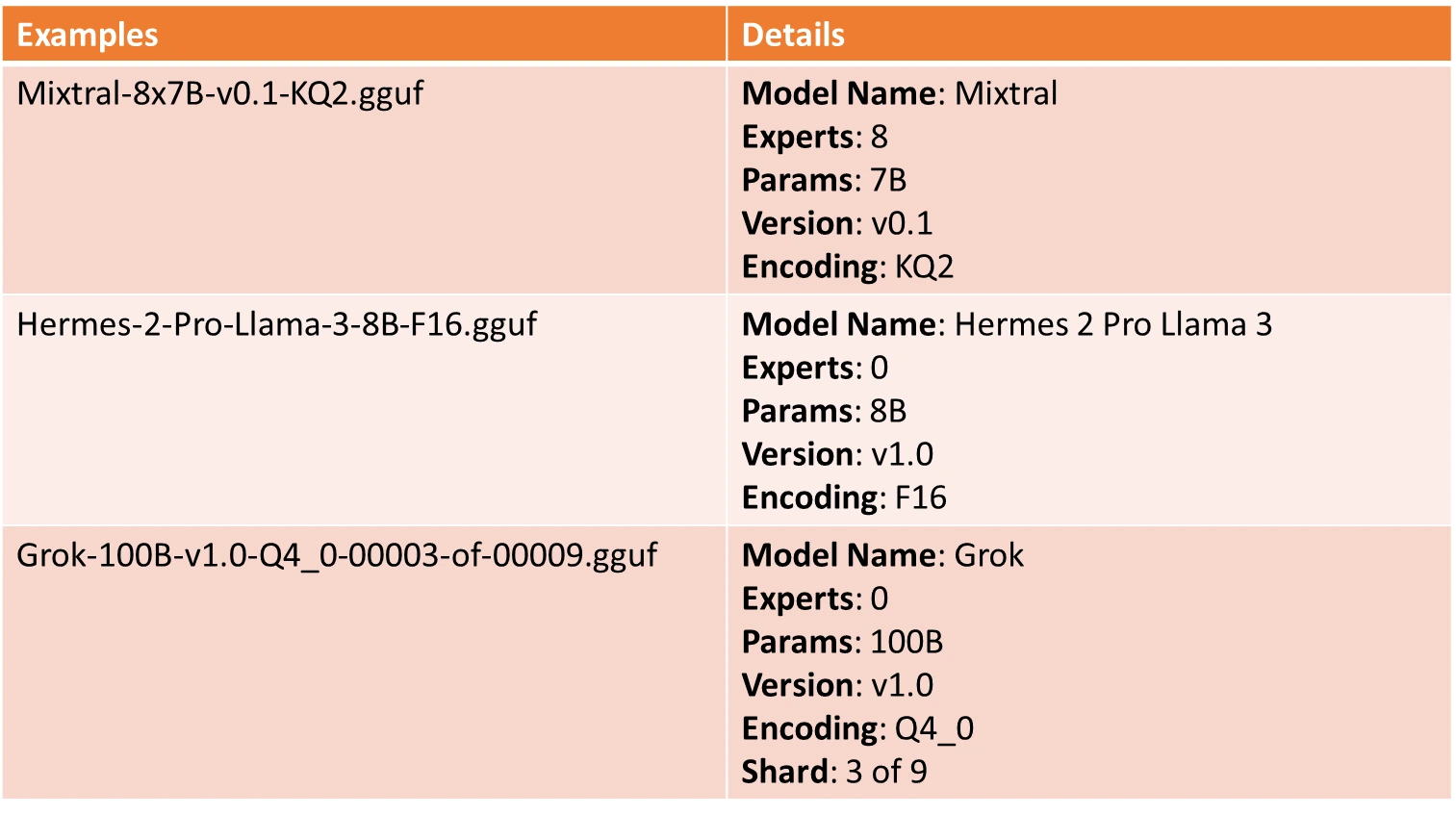
The GGUF format employs a specific naming convention to provide key model information at a glance. This convention helps users identify important model characteristics such as architecture, parameter size, fine-tuning type, version, encoding type, and shard data—making model management and deployment easier.
The GGUF naming convention follows this structure:

Each component in the name provides insight into the model:
- BaseName: Descriptive name for the model base type or architecture, derived from metadata (e.g., LLaMA or Mixtral).
- SizeLabel: Indicates model size, using an x format i.e. <expertCount>: Number of experts (e.g., 8), <count><scale-prefix>: Model parameter scale, like Q for Quadrillion, T for Trillion, B for Billion, M for Million, K for Thousand parameters.
- FineTune: Model fine-tuning goal, such as “Chat” or “Instruct.”
- Version: Model version number in v<Major>.<Minor> format, with v1.0 as default if unspecified.
- Encoding: Weight encoding scheme, customizable per project.
- Type: Indicates GGUF file type, such as LoRA for adapters or vocab for vocabulary data.
- Shard: Denotes a model split into parts, formatted as <ShardNum>-of-<ShardTotal>.
Naming Examples
Setting Up for Conversion to GGUF Format
Before diving into conversion, ensure you have the following prerequisites:
- Python 3.8+ installed on your system.
- Model source file: Typically, a PyTorch or TensorFlow model (e.g., LLaMA, Falcon) or model from hugging face.
- GGUF Conversion Tools: These tools, often based on GGML libraries or specific model-conversion scripts.
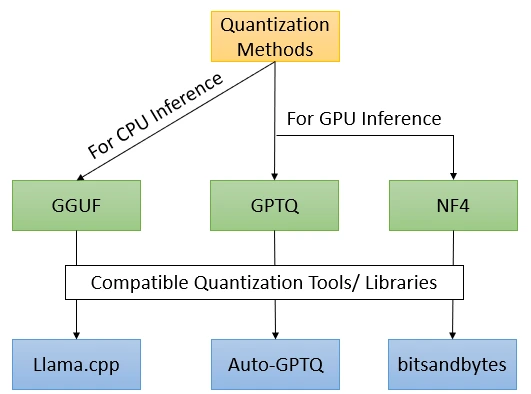
Some Noteworthy Quantization Techniques
Quantization techniques play a pivotal role in optimizing neural networks by reducing their size and computational requirements. By converting high-precision weights and activations to lower bit representations, these methods enable efficient deployment of models without significantly compromising performance.
Converting Models to GGUF
Below is how you could convert your model to GGUF format.
Step 1: Choose the Model to Quantize
In this case, we are choosing Google’s Flan-T5 model to quantize. You could follow the command to directly download the model from Huggingface
!pip install huggingface-hub
from huggingface_hub import snapshot_download
model_id="google/flan-t5-large" # Replace with the ID of the model you want to download
snapshot_download(repo_id=model_id, local_dir="t5")Step 2: Clone the llama.cpp repository
We are using llama.cpp to quantize model to gguf format
!git clone https://github.com/ggerganov/llama.cppStep 3: Install the required dependencies
If in Google Collaboratory, follow the below code, else you could navigate to the requirements directory to install the “requirements-convert_hf_to_gguf.txt”
!pip install -r /content/llama.cpp/requirements/requirements-convert_hf_to_gguf.txtStep 4: Choose the Quantization Level
The quantization level determines the trade-off between model size and accuracy. Lower-bit quantization (like 4-bit) saves memory but may reduce accuracy. For example, if you’re targeting a CPU-only deployment and don’t need maximum precision, INT4 might be a good choice. Here we are choosing “q8_0”.
Step 5: Run the Conversion Script
If in Google Collab, run the below script, else follow the comment.
# !python {path to convert_hf_to_gguf.py} {path to hf_model} --outfile {name_of_outputfile.gguf} --outtype {quantization type}
!python /content/llama.cpp/convert_hf_to_gguf.py /content/t5 --outfile t5.gguf --outtype q8_0- path to hf_model: Path to the model directory.
- name_of_outputfile.gguf: Name of the output file where the GGUF model will be saved. Use gguf naming convention if pushing quantized model back to hugging face.
- quantization type: Specifies the quantization type (in this case, quantized 8-bit integer).
Comparing Size of Original Vs Quantized Model
When deploying machine learning models, understanding the size difference between the original and quantized versions is crucial. This comparison highlights how quantization can significantly reduce model size, leading to improved efficiency and faster inference times without substantial loss of accuracy.
# Check the sizes of the original and quantized models
original_model_path="/content/t5/model.safetensors"
quantized_model_path="t5.gguf"
original_size = get_file_size(original_model_path)
quantized_size = get_file_size(quantized_model_path)
print(f"Original Model Size: {original_size:.2f} KB")
print(f"Quantized Model Size: {quantized_size:.2f} KB")
print(f"Size Reduction: {((original_size - quantized_size) / original_size) * 100:.2f}%")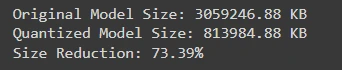
We could see a size reduction of staggering 73.39% using GGUF quantization technique.
Best Practices for GGUF Conversion
To get the best results, keep these tips in mind:
- Experiment with Quantization Levels: Test multiple levels (e.g., 4-bit, 8-bit) to find the best balance between model accuracy and memory efficiency.
- Use Metadata to Your Advantage: GGUF’s extensive metadata storage can simplify model loading and reduce runtime configuration needs.
- Benchmark Inference: Always benchmark the GGUF model on your target hardware to ensure it meets speed and accuracy requirements.
Future of GGUF and Model Storage Formats
As models continue to grow, formats like GGUF will play an increasingly critical role in making large-scale AI accessible. We may soon see more advanced quantization techniques that preserve even more accuracy while further reducing memory requirements. For now, GGUF remains at the forefront, enabling efficient deployment of large language models on CPUs and edge devices.
Conclusion
The GGUF format is a game-changer for deploying large language models efficiently on limited-resource devices. From early efforts in model quantization to the development of GGUF, the landscape of AI model storage has evolved to make powerful models accessible to a wider audience. By following this guide, you can now convert models to GGUF format, making it easier to deploy them for real-world applications.
Quantization will continue to evolve, but GGUF’s ability to support varied precision levels and efficient metadata management ensures it will remain relevant. Try converting your models to GGUF and explore the benefits firsthand!
Key Takeaways
- The Generic GPT Unified Format (GGUF) enables efficient storage and deployment of large language models (LLMs) on low-resource devices, addressing challenges associated with model size and memory demands.
- Quantization significantly reduces model size by compressing parameters, allowing models to run on consumer-grade hardware while maintaining essential performance levels.
- The GGUF format features a structured naming convention that helps identify key model characteristics, facilitating easier management and deployment.
- Using tools like
llama.cpp, users can easily convert models to GGUF format, optimizing them for deployment without sacrificing accuracy. - GGUF supports advanced quantization levels and extensive metadata storage, making it a forward-looking solution for the efficient deployment of increasingly large AI models.
Frequently Asked Questions
Q1. What is GGUF and how does it differ from GGML?
A. GGUF (Generic GPT Unified Format) is an advanced model storage format designed to efficiently store and run quantized large language models. Unlike its predecessor, GGML, which has limited scalability for models exceeding 100GB, GGUF supports extensive 4-bit and 8-bit quantization options and provides a rich metadata storage capability, enhancing model management and deployment.
Q2. How does quantization impact model performance?
A. Quantization reduces the precision of a model’s parameters, significantly decreasing its size and memory usage. While it can lead to a slight drop in accuracy, well-designed quantization techniques (like those in GGUF) can maintain acceptable performance levels, making it feasible to deploy large models on resource-constrained devices.
Q3. What are the main components of the GGUF naming convention?
A. The GGUF naming convention consists of several components, including the BaseName (model architecture), SizeLabel (parameter weight class), FineTune (fine-tuning goal), Version (model version number), Encoding (weight encoding scheme), Type (file purpose), and Shard (for split models). Together, these components provide essential information about the model.
Q4. How can I validate GGUF file names?
A. You can validate GGUF file names using a regular expression that checks for the presence of at least the BaseName, SizeLabel, and Version in the correct order. This ensures the file adheres to the naming convention and contains the necessary information for model identification.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Data Scientist at Syngene International Limited. I have completed my Master's in Data Science from VIT AP and I have a burning passion for Generative AI. My expertise lies in building robust machine learning and NLP models for innovative projects. Currently, I'm putting this knowledge to work in drug discovery research at Syngene, exploring the potential of LLMs. Always eager to learn and delve deeper into the ever-evolving world of data science and AI!


