Introduction
While FastAPI is good for implementing RESTful APIs, it wasn’t specifically designed to handle the complex requirements of serving machine learning models. FastAPI’s support for asynchronous calls is primarily at the web level and doesn’t extend deeply into the model prediction layer. This limitation poses challenges because AI model predictions are resource-intensive operations that need to be configured to optimize performance, especially when dealing with modern large language models (LLMs).
Deploying and serving machine learning models at scale can be as challenging as even building the models themselves. This is where LitServe, an open-source, flexible serving engine built on top of FastAPI, comes into play. LitServe simplifies the process of serving AI models by providing powerful features like batching, streaming, GPU acceleration, and autoscaling. In this article, we will introduce LitServe, delve into its functionalities, and how it can be used to build scalable, high-performance AI servers.
Learning Objectives
- Understand how to easily set up and serve AI models using LitServe.
- Learn how to use batching, streaming, and GPU acceleration to better AI model performance.
- Gain hands-on experience with a toy example, building a simple server to serve AI models.
- Explore features to optimize model serving for high throughput and scalability.

Image source: LitServe
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Model Serving?
In machine learning, deploying and serving models effectively helps to make predictions in real-time applications when deployed to production. Model serving refers to the process of taking a trained machine-learning model and making it available for use in production environments. This can involve exposing the model through APIs so that users or applications can make inference and receive predictions.
The importance of model serving affects the responsiveness and scalability of machine learning applications. Several challenges arise during the deployment, like with large language models (LLMs) that demand high computational resources. These challenges include latency in response times, the need for efficient resource management, and ensuring that models can handle varying loads without degradation in performance. Developers need robust solutions that simplify the serving process while maximizing efficiency. This is where specialized tools like LitServe come in with features designed to streamline model serving and performance.
What is LitServe?
LitServe is an open-source model server designed to provide a fast, flexible, and scalable serving of AI models. By handling complex engineering tasks like scaling, batching, and streaming, eliminates the need to rebuild FastAPI servers for each model. You can use LitServe to deploy models on local machines, cloud environments, or high-performance computing with multiple GPUs.
Key Features of LitServe
Let us explore key features of LitServe:
Faster Model Serving: LitServe is optimized for performance, ensuring models serve better than traditional methods and even better.
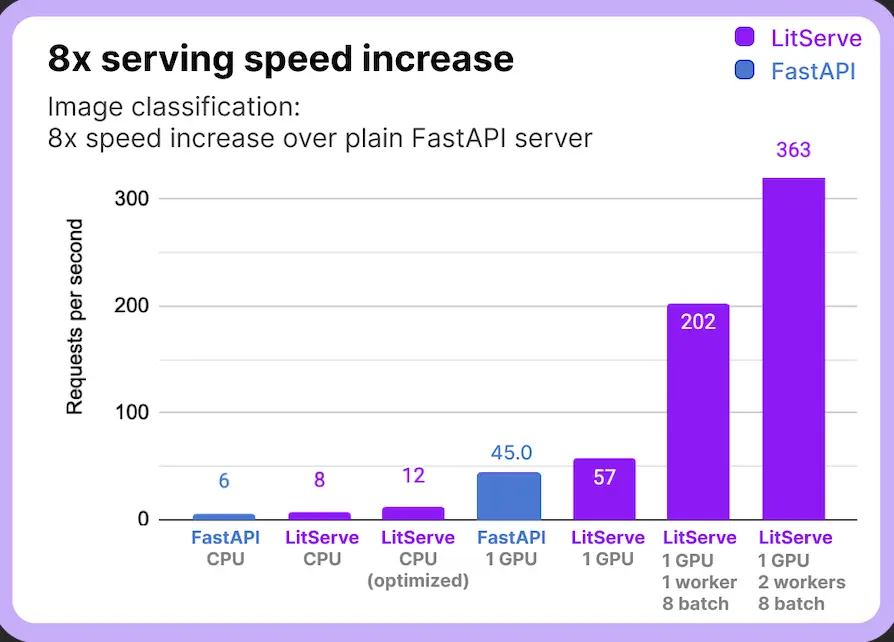
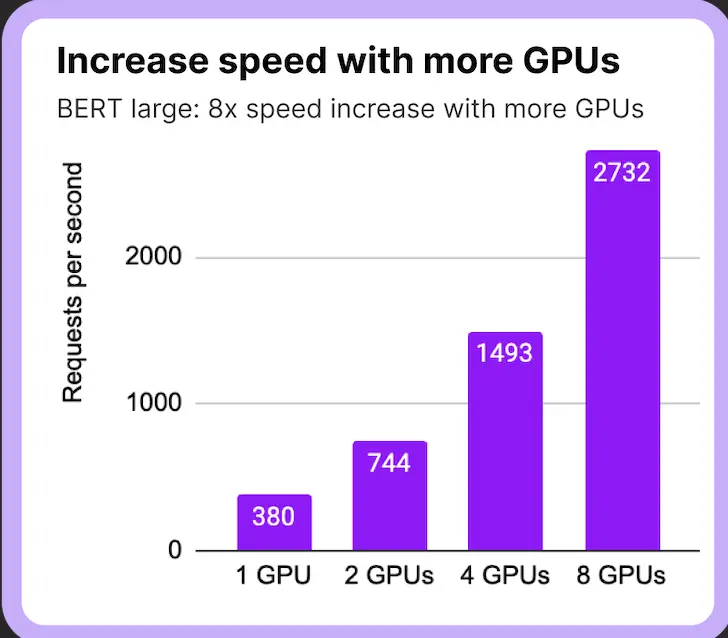
Multi-GPU Support: In cases where the server has multiple GPUS, It leverages the power of multiple GPUs to parallelize model serving, reducing latency.
Batching and Streaming: LitServe can serve multiple calls simultaneously using batching techniques or streaming the response without overloading the server.
LitServe brags about multiple features from authentication to OpenAI specs with features to cater to complex AI workloads.
Getting Started with LitServe
To illustrate how LitServe works, we’ll begin with a simple example and then move on to deploying a more realistic AI server for image captioning using models from Hugging Face. The first step is to install LitServe:
pip install litserveDefining a Simple API with LitServe
LitServe simplifies the process of defining how your model interacts with external calls. The LitAPI class handles incoming calls and returns model predictions. Here’s how you can set up a simple API:
import litserve as ls
class SimpleLitAPI(ls.LitAPI):
def setup(self, device):
self.model1 = lambda x: x**2
self.model2 = lambda x: x**3
def decode_request(self, request):
return request["input"]
def predict(self, x):
squared = self.model1(x)
cubed = self.model2(x)
output = squared + cubed
return {"output": output}
def encode_response(self, output):
return {"output": output}Let’s break down the class:
- setup: Initializes the models or resources your server needs. In this example, we define two simple functions that simulate models.
- decode_request: Converts incoming calls into a format that the model can process. It extracts the input from the request payload.
- predict: Runs the model(s) to make predictions. Here, it calculates the square and cube of the input and sums them.
- encode_response: Converts the model’s output into a response format that can be sent back to the client.
After defining your API, you can run the server by instantiating your API class and passing it to LitServer:
if __name__ == "__main__":
api = SimpleLitAPI()
server = ls.LitServer(api, accelerator="gpu") # accelerator can also be 'auto'
server.run(port=8000)This command will launch the server to handle inferences with GPU acceleration.
Serving a Vision Model with LitServe
To showcase LitServe’s full potential, let’s deploy a realistic AI server that performs image captioning using a model from Hugging Face. This example will show the way LitServe handles more complex tasks and features like GPU acceleration.
Implementing the Image Captioning Server
First, import the necessary libraries and define helper functions:
import requests
import torch
from PIL import Image
from transformers import VisionEncoderDecoderModel, ViTImageProcessor, GPT2TokenizerFast
from tqdm import tqdm
import urllib.parse as parse
import os
# LitServe API Integration
import litserve as ls
# Verify URL function
def check_url(string):
try:
result = parse.urlparse(string)
return all([result.scheme, result.netloc, result.path])
except:
return False
# Load an image from a URL or local path
def load_image(image_path):
if check_url(image_path):
return Image.open(requests.get(image_path, stream=True).raw)
elif os.path.exists(image_path):
return Image.open(image_path)Next, define the LitAPI class for image captioning:
# HuggingFace API class for image captioning
class ImageCaptioningLitAPI(ls.LitAPI):
def setup(self, device):
# Assign available GPU or CPU
self.device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the ViT Encoder-Decoder Model
model_name = "nlpconnect/vit-gpt2-image-captioning"
self.model = VisionEncoderDecoderModel.from_pretrained(model_name).to(self.device)
self.tokenizer = GPT2TokenizerFast.from_pretrained(model_name)
self.image_processor = ViTImageProcessor.from_pretrained(model_name)
# Decode payload to extract image URL or path
def decode_request(self, request):
return request["image_path"]
# Generate image caption
def predict(self, image_path):
image = load_image(image_path)
# Preprocessing the Image
img = self.image_processor(image, return_tensors="pt").to(self.device)
# Generating captions
output = self.model.generate(**img)
# Decode the output to generate the caption
caption = self.tokenizer.batch_decode(output, skip_special_tokens=True)[0]
return caption
# Encode the response back to the client
def encode_response(self, output):
return {"caption": output}For this very use case:
- setup: Loads the pre-trained image captioning model and associated tokenizer and processor, moving them to the device (CPU or GPU).
- decode_request: Extracts the image path from the incoming call.
- predict: Processes the image, generates a caption using the model, and decodes it.
- encode_response: Formats the caption into a JSON response.
# Running the LitServer
if __name__ == "__main__":
api = ImageCaptioningLitAPI()
server = ls.LitServer(api, accelerator="auto", devices=1, workers_per_device=1)
server.run(port=8000)This command will launch the server, automatically detecting available accelerators and configuring devices. Find the entire code here.
Testing the Server
With the server running, you can test it by sending POST requests with an image_path (either a URL or a local file path) in the payload. The server will return a generated caption for the image.
Example: 1
Image:

Generated Caption: “a view from a boat of a beach with a large body of water”
Example 2:
Image:

Generated Caption: “a man in a suit and tie holding a red and white flag”
You can use the Colab notebook provided on GitHub to test the server directly. You can explore as the possibilities are endless.
Enhancing Performance with Advanced Features
LitServe allows you to optimize your server’s performance by utilizing its advanced features:
- Batching: Include max_batch_size=2 in LitServer to process multiple calls simultaneously, improving throughput.
- Streaming: Set stream as True to handle large inputs efficiently without overloading the server.
- Device Management: Specify GPU IDs in devices for control over hardware, especially useful in multi-GPU setups.
For a detailed list of features and configurations, check the official documentation: LitServe Features
Why Choose LitServe?
LitServe effectively tackles the unique challenges of deploying large language models. Unlike traditional model serving methods, it is built for high-performance inference, enabling developers to serve models with minimal latency and maximum throughput. Here’s why you should consider LitServe for your model serving needs:
- Scalability: LitServe is built to scale seamlessly with your application. It can handle multiple calls together, efficiently distributing computational resources based on demand.
- Optimized Performance: It offers features like batching, which allows for processing calls at the same time, reducing the average response time. This is beneficial when serving large language models that need resources.
- Ease of Use: LitServe simplifies the deployment of machine learning models with the setup. Developers can quickly transition from model training to production with faster iterations and deployments.
- Support for Advanced Features: LitServe includes support for GPU acceleration and streaming, allowing for efficient handling of real-time data and complex model architectures. This ensures that your applications can maintain high performance, even under heavy loads.
Conclusion
LitServe provides a powerful, flexible, and efficient way for serving AI models. By abstracting away the complexities of scaling, batching, and hardware, it allows developers to focus on building high-quality AI solutions without worrying about the intricacies of deployment. Whether you’re deploying simple models or complex, multimodal AI systems, LitServe’s robust features and ease of use make it a good choice for both beginners and experienced practitioners.
Key Takeaways
- LitServe streamlines the process of serving AI models, eliminating the need to rebuild servers for each model.
- Features like batching, streaming, and multi-GPU support enhances model serving performance.
- LitServe adapts to environments, from local machines to multi-GPU servers, making it suitable for projects of all sizes.
- LitServe handles complex AI workloads by supporting authentication, compliance standards, and more.
References and Links
- GitHub Link: Image Captioning-ViT
- GitHub: LitServe
- Overview: Serve Models
- Features: LitServe
Frequently Asked Questions
Q1. How does LitServe differ from FastAPI for serving AI models?
A. While FastAPI is great for REST APIs, it is not optimized specifically for resource-heavy AI model serving. LitServe, built on top of FastAPI, enhances model serving by adding features like batching, streaming, GPU acceleration, and autoscaling, which are crucial for large AI models, especially for handling real-time predictions with high throughput.
Q2. Can LitServe be used to serve models on both CPU and GPU?
A. Yes, LitServe supports both CPU and GPU acceleration. You can configure it to automatically detect and use available GPUs or give which GPUs to use. This makes it good for scaling across hardware.
Q3. How does batching improve performance in LitServe?
A. Batching allows LitServe to group multiple incoming calls together, process them in one go, and send the results back. This reduces overhead and increases the efficiency of model inference, especially for workloads requiring parallel processing on GPUs.
Q4. What types of models can I serve with LitServe?
A. LitServe can serve a wide variety of models, including machine learning models, deep learning models, and large language models (LLMs). It supports integration with PyTorch, TensorFlow, and Hugging Face Transformers, making it suitable for serving vision, language, and multimodal models.
Q5. Is it easy to integrate LitServe with existing machine learning pipelines?
A. Yes, LitServe is easy to integrate with existing machine learning pipelines. It uses a familiar API based on FastAPI, and with its customizable LitAPI class, you can quickly adapt your model inference logic, making it seamless to serve models without too much refactoring your pipeline.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an AI Engineer with a deep passion for research, and solving complex problems. I provide AI solutions leveraging Large Language Models (LLMs), GenAI, Transformer Models, and Stable Diffusion.




