Introduction
Large Language Model Operations (LLMOps) is an extension of MLOps, tailored specifically to the unique challenges of managing large-scale language models like GPT, PaLM, and BERT. While MLOps focuses on the lifecycle of machine learning models in general, LLM Ops addresses the complexities introduced by models with billions of parameters, such as handling resource-intensive computations, optimizing inference, reducing latency, and ensuring reliable performance in production environments. Fine-tuning these models, managing scalability, and monitoring them in real-time are all critical to their successful deployment.
This guide explores these complexities and offers practical solutions for managing large language models effectively. Whether you’re scaling models, optimizing performance, or implementing robust monitoring, this guide will walk you through key strategies for efficiently managing large language models in production environments.

Learning Objectives
- Gain insight into the specific challenges and considerations of managing large language models compared to traditional machine learning models.
- Explore advanced methods for scaling LLM inference, including model parallelism, tensor parallelism, and sharding.
- Understand the critical components and best practices for developing and maintaining efficient LLM pipelines.
- Discover optimization techniques such as quantization and mixed-precision inference to improve performance and reduce resource consumption.
- Learn how to integrate monitoring and logging tools to track performance metrics, error rates, and system health for LLM applications.
- Understand how to set up continuous integration and deployment pipelines tailored for LLMs, ensuring efficient model versioning and deployment processes.
This article was published as a part of the Data Science Blogathon.
Table of contents
Setting up a LLM Pipeline
A typical LLM workflow consists of multiple stages, starting with data preparation, followed by model training (or fine-tuning if using pre-trained models), deployment, and continuous monitoring once the model is in production. While training large language models from scratch can be computationally expensive and time-consuming, most use cases rely on fine-tuning existing models like GPT, BERT, or T5 using platforms like Hugging Face.
The core idea behind setting up an LLM pipeline is to enable efficient interaction between users and the model by leveraging REST APIs or other interfaces. After deploying the model, monitoring and optimizing performance becomes crucial to ensure the model is scalable, reliable, and responsive. Below, we’ll walk through a simplified example of deploying a pre-trained LLM for inference using Hugging Face Transformers and FastAPI to create a REST API service.
Building an LLM Inference API with Hugging Face and FastAPI
In this example, we will set up an LLM inference pipeline that loads a pre-trained model, accepts user input (prompts), and returns generated text responses through a REST API.
Step 1: Install Required Dependencies
pip install fastapi uvicorn transformersThese packages are necessary to set up the API and load the pre-trained model. FastAPI is a high-performance web framework, uvicorn is the server to run the API, and transformers is used to load the LLM.
Step 2: Create the FastAPI Application
Here, we build a simple FastAPI application that loads a pre-trained GPT-style model from Hugging Face’s model hub. The API will accept a user prompt, generate a response using the model, and return the response.
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI()
# Load pre-trained model and tokenizer
model_name = "gpt2" # You can replace this with other models like "gpt-neo-1.3B" or "distilgpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
@app.post("/generate/")
async def generate_text(prompt: str):
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output from the model
outputs = model.generate(inputs["input_ids"], max_length=100, num_return_sequences=1)
# Decode the generated tokens back into text
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Return the generated text as the API response
return {"response": generated_text}
# To run the FastAPI app, use: uvicorn.run(app, host="0.0.0.0", port=8000)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)Expected Output: When you run the FastAPI app, you can interact with it using a tool like Postman, cURL, or the Swagger UI provided by FastAPI at http://localhost:8000/docs. Here’s an example of the interaction:
Request (POST to /generate/):
{
"prompt": "Once upon a time, in a distant land,"
}Response (generated by the model):
{
"response": "Once upon a time, in a distant land, the sun was shining,
and the moon was shining, and the stars were shining, and the stars were
shining, and the stars were shining, and the stars were shining, and the stars
were shining, and the stars were shining, and the stars were shining, and the
stars were shining, and the stars were shining, and the stars were shining,
and the stars were shining, and the stars were shining, and the stars were
shining, and"
}Step 3: Run the Application
Once the code is saved, you can run the application locally with the following command:
uvicorn main:app --reloadThis will launch the FastAPI server on http://127.0.0.1:8000/. The –reload flag ensures the server reloads whenever you make code changes.
Expected API Behavior
When running the app, you can access the Swagger UI at http://localhost:8000/docs. Here, you will be able to test the /generate/ endpoint by sending different prompts and receiving text responses generated by the model. The expected behavior is that for each prompt, the LLM will generate coherent text that extends the input prompt.
For example:
Prompt: “The future of AI is”.
Response: “The future of AI is bright, with advancements in machine learning, robotics, and natural language processing driving innovation across industries. AI will revolutionize how we live and work, from healthcare to transportation.”
These are responses for a particular case. Below is the screenshot where you can test out more such responses. However, it would vary from user to case considered.
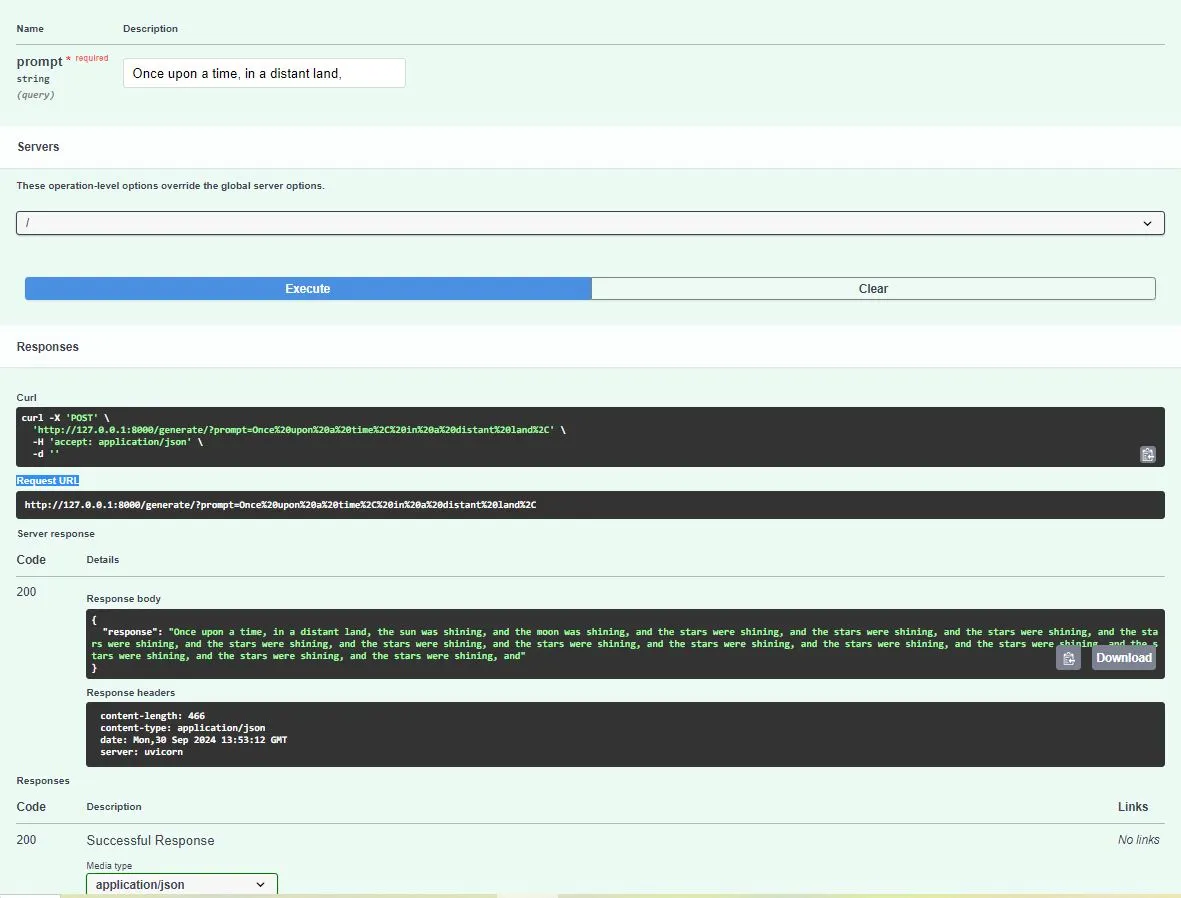
This simple pipeline showcases how to load a pre-trained LLM model, create a REST API for interaction, and deploy it for inference in a production-like setup. It forms the basis of more complex LLM operations, where scalability, optimization, and monitoring will be critical, as we’ll explore further in this blog.
Scaling LLM Inference for Production
Scaling large language models (LLMs) for production is a significant challenge due to their immense computational requirements. LLMs, such as GPT or BERT derivatives, often contain billions of parameters, demanding large amounts of memory and computational resources, which can lead to slow inference times and high operational costs. Inference for such models can be bottlenecked by GPU memory limits, especially when dealing with larger models (e.g., GPT-3 or PaLM) that may not fit entirely into the memory of a single GPU.
Here are some of the main challenges when scaling LLM inference:
- High Memory Requirements: LLMs require large amounts of memory (VRAM) to store parameters and perform computations during inference, often exceeding the memory capacity of a single GPU.
- Slow Inference Times: Due to their size, generating responses from LLMs can take significant time, affecting the user experience. Each token generation may involve thousands of matrix multiplications across millions or billions of parameters.
- Cost: Running large models, especially in production environments where scaling is needed for many concurrent requests, can be very expensive. This includes both hardware costs (e.g., multiple GPUs or specialized accelerators) and energy consumption.
To address these challenges, techniques like model parallelism, tensor parallelism, and sharding are employed. These methods allow the distribution of model parameters and computations across multiple devices or nodes, enabling larger models to be deployed at scale.

Distributed Inference: Model Parallelism, Tensor Parallelism, and Sharding
We will now learn about in detail about distributed inference below:
- Model Parallelism: This technique divides the model itself across multiple GPUs or nodes. Each GPU is responsible for a part of the model’s layers, and data is passed between GPUs as computations progress through the model. This approach allows the inference of very large models that do not fit into the memory of a single device.
- Tensor Parallelism: In this approach, individual layers of the model are split across multiple devices. For instance, the weights of a single layer can be split among several GPUs, allowing parallel computation of that layer’s operations. This method optimizes memory usage by distributing the computation of each layer rather than distributing entire layers.
- Sharding: Sharding involves dividing the model’s parameters across multiple devices and executing computations in parallel. Each shard holds a part of the model, and computation is done on the specific subset of the model that resides on a particular device. Sharding is commonly used with techniques like DeepSpeed and Hugging Face Accelerate to scale LLMs effectively.
Example Code: Implementing Model Parallelism Using DeepSpeed
To demonstrate distributed inference, we’ll use DeepSpeed, a framework designed to optimize large-scale models through techniques like model parallelism and mixed-precision training/inference. DeepSpeed also handles memory and compute optimizations, enabling the deployment of large models across multiple GPUs.
Here’s how to use DeepSpeed for model parallelism with a Hugging Face model.
#Step 1: Install Required Dependencies
pip install deepspeed transformers
#Step 2: Model Parallelism with DeepSpeed
import deepspeed
from transformers import AutoModelForCausalLM, AutoTokenizer
# Initialize DeepSpeed configurations
ds_config = {
"train_micro_batch_size_per_gpu": 1,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 1e-5,
"betas": [0.9, 0.999],
"eps": 1e-8,
"weight_decay": 0.01
}
},
"fp16": {
"enabled": True # Enable mixed-precision (FP16) to reduce memory footprint
}
}
# Load model and tokenizer
model_name = "gpt-neo-1.3B" # You can choose larger models like GPT-3
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Prepare the model for DeepSpeed
model, optimizer, _, _ = deepspeed.initialize(model=model, config=ds_config)
# Function to generate text using the model
def generate_text(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs["input_ids"], max_length=100)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example prompt
prompt = "The future of AI is"
print(generate_text(prompt))
In this code, DeepSpeed’s configuration enables mixed-precision inference to optimize memory usage and performance. The model and tokenizer are loaded using Hugging Face’s API, and DeepSpeed initializes the model to distribute it across GPUs. The generate_text function tokenizes the input prompt, runs it through the model, and decodes the generated output into human-readable text.
Expected Output: Running the above code will generate text based on the prompt using the distributed inference setup with DeepSpeed. Here’s an example of the interaction:
Multi-GPU Model Parallelism
To run the model across multiple GPUs, you’ll need to launch the script with DeepSpeed’s command-line utility. For example, if you have two GPUs available, you can run the model using both with the following command:
deepspeed --num_gpus=2 your_script.pyThis will distribute the model across the available GPUs, allowing you to handle larger models that would not otherwise fit into a single GPU’s memory.
Expected Behavior in Production: Using DeepSpeed for model parallelism allows LLMs to scale across multiple GPUs, making it feasible to deploy models that exceed the memory capacity of a single device. The expected outcome is faster inference with lower memory usage per GPU and, in the case of larger models like GPT-3, the ability to even run them on commodity hardware. Depending on the GPU architecture and model size, this can also lead to reduced inference latency, improving the user experience in production environments.
Optimizing LLM Performance
Quantization is a model optimization technique that reduces the precision of a model’s weights and activations. This allows for faster inference and lower memory usage without significantly impacting accuracy. By converting 32-bit floating-point numbers (FP32) into 8-bit integers (INT8), quantization drastically reduces the model size and speeds up computations, making it ideal for deployment on resource-constrained environments or for improving performance in production.
Tools like ONNX Runtime and Hugging Face Optimum make it easy to apply quantization to transformer models and ensure compatibility with a wide range of hardware accelerators.
Example Code: Quantization with Hugging Face Optimum
The following code demonstrates applying dynamic quantization to a pre-trained model using Hugging Face Optimum.
pip install optimum[onnxruntime] transformers
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from optimum.onnxruntime import ORTModelForSequenceClassification
from optimum.onnxruntime.configuration import AutoQuantizationConfig
# Load the pre-trained model and tokenizer
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Apply dynamic quantization
quantization_config = AutoQuantizationConfig.arm64() # Specify quantization config (e.g., INT8)
ort_model = ORTModelForSequenceClassification.from_transformers(
model, quantization_config=quantization_config
)
# Inference with quantized model
def classify_text(text):
inputs = tokenizer(text, return_tensors="pt")
outputs = ort_model(**inputs)
return outputs.logits.argmax(dim=-1).item()
# Example usage
print(classify_text("The movie was fantastic!"))
Explanation: In this code, we use Hugging Face Optimum to apply dynamic quantization to a BERT model for sequence classification. The model is loaded using the AutoModelForSequenceClassification API, and quantization is applied via ONNX Runtime. This reduces the model size and increases inference speed, making it more suitable for real-time applications.
Monitoring and Logging in LLM Ops
Monitoring is crucial for ensuring optimal performance and reliability in LLM-based applications. It allows for real-time tracking of metrics such as inference latency, token usage, and memory consumption. Effective monitoring helps identify performance bottlenecks, detects anomalies, and facilitates debugging through error logging. By maintaining visibility into the system, developers can proactively address issues and optimize user experience.
Tools for Monitoring
You can leverage several tools to monitor LLM applications effectively. The following discussion details a few relevant tools, followed by an overarching idea presented in the subsequent image.
- Prometheus: A powerful monitoring system and time-series database designed for reliability and scalability. It collects and stores metrics as time-series data, making it easy to query and analyze performance.
- Grafana: A visualization tool that integrates with Prometheus, allowing users to create dynamic dashboards for visualizing metrics and understanding system performance in real time.
- OpenTelemetry: A comprehensive set of APIs, libraries, and agents for collecting observability data, including metrics, logs, and traces. It enables unified monitoring across distributed systems.
- LangSmith: A tool specifically designed for LLM operations, offering features for monitoring and logging LLM performance. It focuses on tracking prompt effectiveness, model behavior, and response accuracy.
- Neptune.ai: A metadata store for MLOps that provides monitoring and logging capabilities tailored for machine learning workflows, enabling teams to track experiments, monitor model performance, and manage datasets efficiently.
These tools collectively enhance the ability to monitor LLM applications, ensuring optimal performance and reliability in production environments.
Continuous Integration and Deployment (CI/CD) in LLM Ops
Continuous Integration (CI) and Continuous Deployment (CD) pipelines are essential for maintaining the reliability and performance of machine learning models, but they require different considerations when applied to large language models (LLMs). Unlike traditional machine learning models, LLMs often involve complex architectures and substantial datasets, which can significantly increase the time and resources required for training and deployment.
In LLM pipelines, CI focuses on validating changes to the model or data, ensuring that any modifications do not negatively affect performance. This can include running automated tests on model accuracy, performance benchmarks, and compliance with data quality standards. CD for LLMs involves automating the deployment process, including the model’s packaging, versioning, and integration into applications, while also accommodating the unique challenges of scaling and performance monitoring. Carefully manage specialized hardware required for LLMs due to their size throughout the deployment process.
Version Control for LLM Models
Version control for LLMs is crucial for tracking changes and managing different iterations of models. This can be achieved using tools such as:
- DVC (Data Version Control): A version control system for data and machine learning projects that allows teams to track changes in datasets, models, and pipelines. DVC integrates with Git, enabling seamless version control of both code and data artifacts.
- Hugging Face Model Hub: A platform specifically designed for sharing and versioning machine learning models, particularly transformers. It allows users to easily upload, download, and track model versions, facilitating collaboration and deployment.
These tools help teams manage model updates efficiently while maintaining a clear history of changes, making it easier to revert to previous versions if needed.
Using GitHub Actions and Hugging Face Hub for Automatic Deployment
Here’s a simplified example of how to set up a CI/CD pipeline using GitHub Actions to automatically deploy a model to Hugging Face Hub.
Step1: Create a GitHub Actions Workflow File
Create a file named .github/workflows/deploy.yml in your repository.
name: Deploy Model
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install Dependencies
run: |
pip install transformers huggingface_hub
- name: Deploy to Hugging Face Hub
run: |
python deploy.py # A script to handle the deployment logic
env:
HUGGINGFACE_HUB_TOKEN: ${{ secrets.HUGGINGFACE_HUB_TOKEN }}Step2: Deployment Script (deploy.py)
This script can upload the model to Hugging Face Hub.
from huggingface_hub import HfApi, HfFolder, Repository
# Load your model and tokenizer
model_name = "your_model_directory"
repository_id = "your_username/your_model_name"
api = HfApi()
# Create a repo if it doesn't exist
api.create_repo(repo_id=repository_id, exist_ok=True)
# Push the model to the Hugging Face Hub
repo = Repository(local_dir=model_name, clone_from=repository_id)
repo.git_pull()
repo.push_to_hub()Explanation: In this setup, the GitHub Actions workflow is triggered whenever changes are pushed to the main branch. It checks the code, sets up the Python environment, and installs necessary dependencies. The deployment script (deploy.py) handles the logic for pushing the model to Hugging Face Hub, creating a repository if it doesn’t already exist. This CI/CD pipeline streamlines the deployment process for LLMs, enabling faster iteration and collaboration within teams.

Conclusion
Managing large language models (LLMs) in production involves a comprehensive understanding of various operational aspects, including scaling, optimizing, monitoring, and deploying these complex models. As LLMs continue to evolve and become integral to many applications, the methodologies and tools for effectively handling them will also advance. By implementing robust CI/CD pipelines, effective version control, and monitoring systems, organizations can ensure that their LLMs perform optimally and deliver valuable insights.
Looking ahead, future trends in LLM Ops may include better prompt monitoring for understanding model behavior. More efficient inference methods will help reduce latency and costs. Increased automation tools will streamline the entire LLM lifecycle.
Key Takeaways
- LLMs face challenges like high memory use and slow inference, requiring techniques like model parallelism and sharding.
- Implementing strategies like quantization can significantly reduce model size and enhance inference speed without sacrificing accuracy.
- Effective monitoring is essential for identifying performance issues, ensuring reliability, and facilitating debugging through error logging.
- Tailor continuous integration and deployment pipelines to address the complexities of LLMs, including their architecture and resource needs.
- Tools like DVC and Hugging Face Model Hub enable effective version control for LLMs, facilitating collaboration and efficient model update management.
Frequently Asked Questions
Q1. What are the primary differences between LLM Ops and traditional MLOps?
A. LLM Ops tackles the unique challenges of large language models, like their size, high inference costs, and complex architectures. Traditional MLOps, on the other hand, covers a broader range of machine learning models and doesn’t usually need the same level of resource management or scaling as LLMs.
Q2. How can I optimize the inference speed of large language models?
A. Optimize inference speed by applying techniques like quantization, model parallelism, and using optimized runtime libraries such as ONNX Runtime or Hugging Face Optimum. These methods help reduce the computational load and memory usage during inference.
Q3. What tools are recommended for monitoring LLM performance in production?
A. Effective tools for monitoring LLMs include Prometheus for collecting metrics and Grafana for visualizing data. OpenTelemetry provides comprehensive observability. LangSmith offers specialized monitoring for LLMs, while Neptune.ai helps track experiments and performance.
Q4. How can I implement version control for my LLM models?
A. Version control for LLMs can use tools like DVC (Data Version Control) to manage data and models in Git repositories. The Hugging Face Model Hub is another option, allowing easy model sharing and version tracking, especially for transformer models.
Q5. What are the future trends in LLM Ops?
A. Future trends in LLM Ops may include improvements in prompt monitoring to boost model interpretability. There will likely be more efficient inference methods to reduce costs and latency. Additionally, greater automation in model deployment and management processes is expected. These innovations will help streamline the use of LLMs in various applications.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Advancing language model research by day and writing about my work online by night. I explore AI breakthroughs and transform complex studies into clear, engaging insights that empower professionals and enthusiasts alike.
Thanks for stopping by my profile!




