In the fast-paced digital landscape, businesses often face the challenge of promptly responding to customer emails while maintaining accuracy and relevance. Leveraging advanced tools like LangGraph, Llama 3, and Groq, we can streamline email workflows by automating tasks such as categorization, contextual research, and drafting thoughtful replies. This guide demonstrates how to build an automated system to handle these tasks effectively, including integration with search engines and APIs for seamless operations.

Learning Objectives
- Learn how to define, manage, and execute multi-step workflows using LangGraph, including the use of nodes, edges, and conditional routing.
- Explore the process of incorporating external API like GROQ and web search tools into LangGraph workflows to enhance functionality and streamline operations.
- Gain insights into managing shared states across workflow steps, including passing inputs, tracking intermediate results, and ensuring consistent outputs.
- Understand the importance of intermediate analysis , feedback loops, and refinement in generating high-quality outputs using large language models(LLMs).
- Learn how to implement conditional logic for routing tasks, handling errors, and adapting workflows dynamically based on intermediate results.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Getting Started: Setup and Installation
- Implementing an Advanced Email Reply System
- Designing a Research Router
- Integrating the Prompt with Groq’s LLM
- Generating Search Keywords
- Writing the Draft Email
- Rewrite Router
- Draft Email Analysis
- Tool Setup
- State Setup
- Categorize Email
- Research Info Search
- Draft Email Writer (draft_email_writer)
- Draft Email Analyzer (analyze_draft_email)
- Conclusion
- Frequently Asked Questions
Getting Started: Setup and Installation
Start by installing the necessary Python libraries for this project. These tools will allow us to create a highly functional and intelligent email reply system.
!pip -q install langchain-groq duckduckgo-search
!pip -q install -U langchain_community tiktoken langchainhub
!pip -q install -U langchain langgraph tavily-python
You can confirm the successful installation of langgraph by running:
!pip show langgraph
Goal
The system aims to automate email replies using a step-by-step process:
- Retrieve the incoming email.
- Categorize the email into one of the following types:
- Sales
- Custom Inquiry
- Off-topic
- Customer Complaint
- Generate keywords for relevant research based on the email category and content.
- Draft a reply using researched information.
- Validate the draft reply.
- Rewrite the reply if necessary.
This structured approach ensures the email response is tailored, accurate, and professional.
Setting Up the Environment
To proceed, set up the environment with the required API keys:
import os
from google.colab import userdata
from pprint import pprint
os.environ["GROQ_API_KEY"] = userdata.get('GROQ_API_KEY')
os.environ["TAVILY_API_KEY"] = userdata.get('TAVILY_API_KEY')Implementing an Advanced Email Reply System
To power the email processing pipeline, we use Groq’s Llama3-70b-8192 model. This model is highly capable of handling complex tasks like natural language understanding and generation.
from langchain_groq import ChatGroq
GROQ_LLM = ChatGroq(
model="llama3-70b-8192",
)The Groq-powered LLM acts as the backbone for categorizing emails, generating research keywords, and drafting polished replies.
Building Prompt Templates
Using LangChain’s ChatPromptTemplate and output parsers, we define templates for generating and interpreting results. These templates ensure that the model’s output aligns with our system’s requirements.
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.output_parsers import JsonOutputParser
These tools provide the flexibility needed to handle both free-form text and structured data, making them ideal for multi-step processes.
Utilities: Saving Outputs
As part of the system, it’s useful to log outputs for debugging or documentation purposes. The following utility function saves content into markdown files:
def write_markdown_file(content, filename):
"""Writes the given content as a markdown file to the local directory.
Args:
content: The string content to write to the file.
filename: The filename to save the file as.
"""
with open(f"{filename}.md", "w") as f:
f.write(content)This utility helps preserve drafts, research results, or analysis reports for further review or sharing.
Designing the Basic Chains
Our system consists of a series of logical chains, each addressing a specific aspect of the email reply process. Here’s a brief overview:
- Categorize Email : Identify the type of email(e.g., sales,custom inquiry,etc.)
- Research Router : Direct the email’s context to the appropriate search method.
- Search Keywords : Extract relevant keywords for gathering additional information.
- Write Draft Email : Use the research and email context to generate a thoughtful reply.
- Rewrite Router : Determine if the draft requires rewriting or further improvement.
- Draft Email Analysis : Evaluate the draft’s coherence, relevance, and tone.
- Rewrite Email : Finalize the email by refining its tone and content.
Categorizing Emails
The first step in our pipeline is categorizing the incoming email. Using a custom prompt template, we guide the Llama3 model to analyze the email and assign it to one of the predefined categories:
- price_enquiry : Questions related to pricing.
- customer_complaint: Issues or grievances.
- product_enquiry: Questions about features, benefits , or services(excluding pricing).
- customer_feedback : General feedback about a product or service.
- off_topic : Emails that don’t it any other category.
Defining the Prompt Template
We create a structured prompt to help the model focus on the categorization task:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an Email Categorizer Agent. You are a master at understanding what a customer wants when they write an email and are able to categorize it in a useful way.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Conduct a comprehensive analysis of the email provided and categorize it into one of the following categories:
price_enquiry - used when someone is asking for information about pricing \
customer_complaint - used when someone is complaining about something \
product_enquiry - used when someone is asking for information about a product feature, benefit, or service but not about pricing \
customer_feedback - used when someone is giving feedback about a product \
off_topic - when it doesn’t relate to any other category.
Output a single category only from the types ('price_enquiry', 'customer_complaint', 'product_enquiry', 'customer_feedback', 'off_topic') \
e.g.:
'price_enquiry' \
EMAIL CONTENT:\n\n {initial_email} \n\n
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["initial_email"],
)
Connecting the Prompt with Groq’s LLM
To process the prompt, we link it to the GROQ_LLM model and parse the result as a string.
from langchain_core.output_parsers import StrOutputParser
email_category_generator = prompt | GROQ_LLM | StrOutputParser()Testing the Email Categorization
Let’s test the categorization with an example email:
EMAIL = """HI there, \n
I am emailing to say that I had a wonderful stay at your resort last week. \n
I really appreciate what your staff did.
Thanks,
Paul
"""
result = email_category_generator.invoke({"initial_email": EMAIL})
print(result)Output
The system analyzes the content and categorizes the email as:
"customer_feedback"This categorization is accurate based on the email content, showcasing the model’s ability to understand nuanced customer inputs.
Designing a Research Router
Not all emails require external research. The system directly answers some emails based on their content and category, while it gathers additional information to draft comprehensive replies for others. The Research Router determines the appropriate action—whether to perform a search for supplementary information or proceed directly to drafting the email.
Defining the Research Router Prompt
The Research Router Prompt evaluates the initial email and its assigned category to decide between two actions:
- draft_email : For simple responses that don’t require additional research.
- research_info : For cases requiring additional context or data.
This decision is encoded in a JSON format to ensure clear and structured output.
research_router_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an expert at reading the initial email and routing web search
or directly to a draft email.
Use the following criteria to decide how to route the email:
If the initial email only requires a simple response:
- Choose 'draft_email' for questions you can easily answer,
including prompt engineering and adversarial attacks.
- If the email is just saying thank you, etc., choose 'draft_email.'
Otherwise, use 'research_info.'
Give a binary choice 'research_info' or 'draft_email' based on the question.
Return a JSON with a single key 'router_decision' and no preamble or explanation.
Use both the initial email and the email category to make your decision.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Email to route INITIAL_EMAIL: {initial_email}
EMAIL_CATEGORY: {email_category}
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["initial_email", "email_category"],
)
Integrating the Prompt with Groq’s LLM
Similar to the categorization step, we connect the prompt to GROQ_LLM and parse the result using the JsonOutputParser.
from langchain_core.output_parsers import JsonOutputParser
research_router = research_router_prompt | GROQ_LLM | JsonOutputParser()Testing the Research Router
We use the following email and category as input:
EMAIL = """HI there, \n
I am emailing to say that I had a wonderful stay at your resort last week. \n
I really appreciate what your staff did.
Thanks,
Paul
"""
email_category = "customer_feedback"
result = research_router.invoke({"initial_email": EMAIL, "email_category": email_category})
print(result)Output
The Research Router produces the following JSON output:
{'router_decision': 'draft_email'}This indicates that the email does not require additional research, and we can proceed directly to drafting the reply.
Generating Search Keywords
In cases where external research is required, identifying precise search keywords is critical. This step uses the email content and its assigned category to generate the most effective keywords for retrieving relevant information.
Defining the Search Keywords Prompt
The Search Keywords Prompt helps the model extract up to three key terms that will guide a focused and efficient web search. This ensures the research phase is both accurate and relevant.
search_keyword_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a master at working out the best keywords for a web search
to find the most relevant information for the customer.
Given the INITIAL_EMAIL and EMAIL_CATEGORY, work out the best
keywords that will find the most relevant information to help write
the final email.
Return a JSON with a single key 'keywords' containing no more than
3 keywords, and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
INITIAL_EMAIL: {initial_email}
EMAIL_CATEGORY: {email_category}
<|eot_id|><|start_header_id|>assistant<|end_header_id>
""",
input_variables=["initial_email", "email_category"],
)Building the Search Keyword Chain
We connect the search_keyword_prompt to the GROQ_LLM model and parse the results as JSON for structured output.
search_keyword_chain = search_keyword_prompt | GROQ_LLM | JsonOutputParser()Testing the Search Keywords Generation
Using the same email and category from earlier:
EMAIL = """HI there, \n
I am emailing to say that I had a wonderful stay at your resort last week. \n
I really appreciate what your staff did.
Thanks,
Paul
"""
email_category = "customer_feedback"
result = search_keyword_chain.invoke({"initial_email": EMAIL, "email_category": email_category})
print(result)Output
The system generates a JSON response with up to three keywords:
{'keywords': ['hotel customer feedback', 'resort appreciation email', 'positive travel review']}These keywords reflect the essence of the email and will help retrieve targeted and useful information for crafting the final response.
By generating precise search keywords, the system streamlines the research phase, making it easier to gather relevant data for email replies. Next, we’ll explore how to draft the email based on research and context. Let me know if you’d like to move on!
Writing the Draft Email
With the research complete (if needed) and the email categorized, the next step is to draft a thoughtful and professional response. This step ensures that the response aligns with the customer’s intent and maintains a friendly tone.
Defining the Draft Writer Prompt
The Draft Writer Prompt takes into account the initial email, its category, and any supplementary research information to craft a personalized reply. The template includes specific instructions based on the email category to ensure appropriate responses:
- off_topic : Ask clarifying questions.
- customer_complaint : Reassure the customer and address their concerns.
- customer_feedback: Acknowledge the feedback and express gratitude.
- product_enquiry : Provide concise and friendly information based on the research.
- price_enquiry : Deliver the requested pricing information.
The draft is returned as a JSON object with the key email_draft.
draft_writer_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are the Email Writer Agent. Take the INITIAL_EMAIL below from a human that has emailed our company email address, the email_category \
that the categorizer agent gave it, and the research from the research agent, and \
write a helpful email in a thoughtful and friendly way.
If the customer email is 'off_topic' then ask them questions to get more information.
If the customer email is 'customer_complaint' then try to assure we value them and that we are addressing their issues.
If the customer email is 'customer_feedback' then thank them and acknowledge their feedback positively.
If the customer email is 'product_enquiry' then try to give them the info the researcher provided in a succinct and friendly way.
If the customer email is 'price_enquiry' then try to give the pricing info they requested.
You never make up information that hasn't been provided by the research_info or in the initial_email.
Always sign off the emails in an appropriate manner and from Sarah, the Resident Manager.
Return the email as a JSON with a single key 'email_draft' and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
INITIAL_EMAIL: {initial_email} \n
EMAIL_CATEGORY: {email_category} \n
RESEARCH_INFO: {research_info} \n
<|eot_id|><|start_header_id|>assistant<|end_header_id>""",
input_variables=["initial_email", "email_category", "research_info"],
)
Building the Draft Email Chain
The prompt is connected to the GROQ_LLM model, and the output is parsed as structured JSON.
draft_writer_chain = draft_writer_prompt | GROQ_LLM | JsonOutputParser()Testing the Draft Email Writer
We provide the system with the email, category, and research information. For this test, no additional research is required:
email_category = "customer_feedback"
research_info = None
result = draft_writer_chain.invoke({
"initial_email": EMAIL,
"email_category": email_category,
"research_info": research_info,
})
print(result)
Output:
{
"email_draft": "Dear Paul,\n\nThank you so much for your
kind words and feedback about your recent stay at our
resort. We’re thrilled to hear that you had a wonderful
experience and that our staff made your stay special.
It truly means a lot to us.\n\nYour satisfaction is our
top priority, and we’re always here to ensure every
visit is memorable.\n\nLooking forward to welcoming
you back in the future!\n\nWarm regards,\nSarah\n
Resident Manager"
}Output:
{'email_draft': "Dear Paul,\n\nThank you so much for taking the time to share your wonderful experience at our resort! We are thrilled to hear that our staff made a positive impact onThis response reflects the system’s ability to create a thoughtful and appropriate reply while adhering to the provided context.
With the draft email generated, the pipeline is almost complete. In the next step, we’ll analyze and, if necessary, refine the draft for optimal quality. Let me know if you’d like to continue!
Rewrite Router
Not all draft emails are perfect on the first attempt. The Rewrite Router evaluates the draft email to determine if it adequately addresses the customer’s concerns or requires rewriting for better clarity, tone, or completeness.
Defining the Rewrite Router Prompt
The Rewrite Router Prompt evaluates the draft email against the following criteria:
- No Rewrite Required (
- The draft email provides a simple response matching the requirements.
- The draft email addresses all concerns from the initial email.
- Rewrite Required (
- The draft email lacks information needed to address the customer’s concerns.
- The draft email’s tone or content is inappropriate.
- The response is returned in JSON format with a single key, router_decision.
rewrite_router_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an expert at evaluating emails that are draft emails for the customer and deciding if they
need to be rewritten to be better. \n
Use the following criteria to decide if the DRAFT_EMAIL needs to be rewritten: \n\n
If the INITIAL_EMAIL only requires a simple response which the DRAFT_EMAIL contains, then it doesn't need to be rewritten.
If the DRAFT_EMAIL addresses all the concerns of the INITIAL_EMAIL, then it doesn't need to be rewritten.
If the DRAFT_EMAIL is missing information that the INITIAL_EMAIL requires, then it needs to be rewritten.
Give a binary choice 'rewrite' (for needs to be rewritten) or 'no_rewrite' (for doesn't need to be rewritten) based on the DRAFT_EMAIL and the criteria.
Return a JSON with a single key 'router_decision' and no preamble or explanation. \
<|eot_id|><|start_header_id|>user<|end_header_id|>
INITIAL_EMAIL: {initial_email} \n
EMAIL_CATEGORY: {email_category} \n
DRAFT_EMAIL: {draft_email} \n
<|eot_id|><|start_header_id|>assistant<|end_header_id>""",
input_variables=["initial_email", "email_category", "draft_email"],
)
Building the Rewrite Router Chain
This chain combines the prompt with the GROQ_LLM model to evaluate the draft email and determine if further refinement is necessary.
rewrite_router = rewrite_router_prompt | GROQ_LLM | JsonOutputParser()Testing the Rewrite Router
For testing, let’s evaluate a draft email that clearly falls short of expectations:
email_category = "customer_feedback"
draft_email = "Yo we can't help you, best regards Sarah"
result = rewrite_router.invoke({
"initial_email": EMAIL,
"email_category": email_category,
"draft_email": draft_email
})
print(result)
Output
The system identifies the need for rewriting:
{'router_decision': 'rewrite'}This ensures that inappropriate or incomplete drafts do not reach the customer.
By implementing the Rewrite Router, the system ensures that every email response meets a high standard of quality and relevance.
Draft Email Analysis
The Draft Email Analysis step evaluates the quality of the draft email, ensuring that it effectively addresses the customer’s issues and provides actionable feedback for improvement.
Defining the Draft Analysis Prompt
The Draft Analysis Prompt inspects the draft email using the following criteria:
- Does the draft email adequately address the customer’s concerns based on the email category?
- Does it align with the context and tone of the initial email?
- Are there any specific areas where the draft can be improved (e.g., tone, clarity, completeness)?
The output is structured as a JSON object containing a single key, draft_analysis, with feedback and suggestions.
draft_analysis_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are the Quality Control Agent. Read the INITIAL_EMAIL below from a human that has emailed \
our company email address, the email_category that the categorizer agent gave it, and the \
research from the research agent, and write an analysis of the email.
Check if the DRAFT_EMAIL addresses the customer's issues based on the email category and the \
content of the initial email.\n
Give feedback on how the email can be improved and what specific things can be added or changed \
to make the email more effective at addressing the customer's issues.
You never make up or add information that hasn't been provided by the research_info or in the initial_email.
Return the analysis as a JSON with a single key 'draft_analysis' and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
INITIAL_EMAIL: {initial_email} \n\n
EMAIL_CATEGORY: {email_category} \n\n
RESEARCH_INFO: {research_info} \n\n
DRAFT_EMAIL: {draft_email} \n\n
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["initial_email", "email_category", "research_info", "draft_email"],
)
Building the Draft Analysis Chain
This chain pairs the prompt with the GROQ_LLM model and parses the output.
draft_analysis_chain = draft_analysis_prompt | GROQ_LLM | JsonOutputParser()Testing the Draft Analysis Chain
We test the chain with a deliberately poor draft email to observe the system’s feedback:
email_category = "customer_feedback"
research_info = None
draft_email = "Yo we can't help you, best regards Sarah"
email_analysis = draft_analysis_chain.invoke({
"initial_email": EMAIL,
"email_category": email_category,
"research_info": research_info,
"draft_email": draft_email
})
pprint(email_analysis)Output
The system provides constructive analysis:
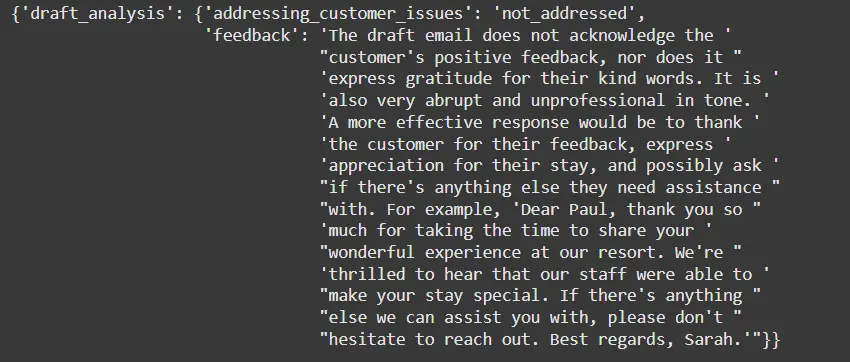
Analysis
The feedback emphasizes the need for professionalism, alignment with customer sentiment, and proper acknowledgment of their message. It also provides a concrete example of how the draft email can be improved.
With the Draft Analysis in place, the system ensures continuous improvement and higher quality in customer communication.
The Rewrite Email with Analysis step refines the draft email using the feedback provided in the Draft Email Analysis. This final step ensures that the email is polished and appropriate for sending to the customer.
Defining the Rewrite Email Prompt
The Rewrite Email Prompt combines the draft email with the feedback from the Draft Email Analysis. The goal is to apply the suggested changes and improve the tone, clarity, and effectiveness of the response without introducing any new information.
The output is a JSON containing a single key, final_email, which contains the refined version of the draft email.
rewrite_email_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are the Final Email Agent. Read the email analysis below from the QC Agent \
and use it to rewrite and improve the draft_email to create a final email.
You never make up or add information that hasn't been provided by the research_info or in the initial_email.
Return the final email as JSON with a single key 'final_email' which is a string and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
EMAIL_CATEGORY: {email_category} \n\n
RESEARCH_INFO: {research_info} \n\n
DRAFT_EMAIL: {draft_email} \n\n
DRAFT_EMAIL_FEEDBACK: {email_analysis} \n\n
<|eot_id|>"""
input_variables=["initial_email", "email_category", "research_info", "email_analysis", "draft_email"],
)
Building the Rewrite Chain
This chain combines the prompt with GROQ_LLM to generate the final version of the email based on the analysis.
rewrite_chain = rewrite_email_prompt | GROQ_LLM | JsonOutputParser()Testing the Rewrite Email Chain
To test, we use the customer_feedback category and a draft email that requires substantial revision.
email_category = 'customer_feedback'
research_info = None
draft_email = "Yo we can't help you, best regards Sarah"
final_email = rewrite_chain.invoke({
"initial_email": EMAIL,
"email_category": email_category,
"research_info": research_info,
"draft_email": draft_email,
"email_analysis": email_analysis
})
print(final_email['final_email'])Example Output
'Dear Paul, thank you so much for taking the time to share your wonderful experience at our resort. We're thrilled to hear that our staff were able to make your stay special. If ther e's anything else we can assist you with, please don't hesitate to reach out. Best regards, Sarah'By implementing the Rewrite Email with Analysis step, the system delivers a polished final draft that effectively addresses the customer’s feedback and maintains a professional tone.
The Tool Setup section configures the tools needed for the entire process. Here, the search tool is initialized and the state of the graph is defined. These tools allow for interaction with external data sources and ensure the email generation process follows a structured flow.
Tool Setup
The TavilySearchResults tool is set up to handle web searches and retrieve relevant results.
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=1)The k=1 parameter ensures that only one result is fetched per search.
State Setup
The GraphState class, defined as a TypedDict, represents the state of the process. It tracks the necessary data across the different stages of email processing.
from langchain.schema import Document
from langgraph.graph import END, StateGraph
from typing_extensions import TypedDict
from typing import List
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
initial_email: email
email_category: email category
draft_email: LLM generation
final_email: LLM generation
research_info: list of documents
info_needed: whether to add search info
num_steps: number of steps
"""
initial_email: str
email_category: str
draft_email: str
final_email: str
research_info: List[str]
info_needed: bool
num_steps: int
draft_email_feedback: dict
- initial_email : The content of the customer’s email.
- email_category : The category assigned to the email(e.g., sales, complaint, feedback).
- draft_email : The email generated by the system in response to the customer’s message.
- final_email : The final version of the email after revisions based on analysis.
- research_info: A list of relevant documents gathered during the research phase.
- info_needed : A boolean flag indicating if additional information is required for the email response.
- num_steps : A counter for the number of steps completed.
- draft_email_feedback : Feedback from the draft analysis stage.
This state setup helps in tracking the process, ensuring that all necessary information is available and up-to-date as the email response evolves.
The Nodes section defines the key steps in the email handling process. These nodes correspond to different actions in the pipeline, from categorizing the email to researching and drafting the response. Each function manipulates the GraphState, performs an action, and then updates the state.
Categorize Email
The categorize_email node categorizes the incoming email based on its content.
def categorize_email(state):
"""Take the initial email and categorize it"""
print("---CATEGORIZING INITIAL EMAIL---")
initial_email = state['initial_email']
num_steps = int(state['num_steps'])
num_steps += 1
# Categorize the email
email_category = email_category_generator.invoke({"initial_email": initial_email})
print(email_category)
# Save category to local disk
write_markdown_file(email_category, "email_category")
return {"email_category": email_category, "num_steps": num_steps}
- This function calls the email_category_generator to categorize the email based on its content.
- The category is saved to a file for record-keeping.
- It returns the updated state with the email_category and an incremented num_steps.
Research Info Search
The research_info_search node performs a web search based on keywords derived from the initial email and its category.
def research_info_search(state):
print("---RESEARCH INFO SEARCHING---")
initial_email = state["initial_email"]
email_category = state["email_category"]
research_info = state["research_info"]
num_steps = state['num_steps']
num_steps += 1
# Web search for keywords
keywords = search_keyword_chain.invoke({"initial_email": initial_email,
"email_category": email_category })
keywords = keywords['keywords']
full_searches = []
for keyword in keywords[:1]: # Only taking the first keyword
print(keyword)
temp_docs = web_search_tool.invoke({"query": keyword})
web_results = "\n".join([d["content"] for d in temp_docs])
web_results = Document(page_content=web_results)
if full_searches is not None:
full_searches.append(web_results)
else:
full_searches = [web_results]
print(full_searches)
print(type(full_searches))
return {"research_info": full_searches, "num_steps": num_steps}
- The function generates a list of keywords based on the initial_email and email_category using search_keyword_chain.
- It then performs a web search for each keyword using TravilySearchResults.
- The results are gathered into a list of Document objects and saved to the state as research_info.
Next Steps in the Process
To complete the email pipeline, we need to define additional nodes that handle drafting, analyzing, and rewriting the email. For instance:
- Draft Email Writer: Uses the categorized email, research info, and LLMs to generate the first draft of the email.
- Analyze Draft Email: Reviews the draft email and provides feedback for improvements.
- Rewrite Email: Uses the feedback to rewrite the draft email into a final version.
- No Rewrite: If no rewrite is necessary, this node would pass the draft to the next stage without modifications.
- State Printer: Prints or logs the current state for debugging purposes.
Example of Further Steps
def draft_email_writer(state):
print("---WRITING DRAFT EMAIL---")
# Implement logic to generate draft email based on research and category.
return {"draft_email": draft_email_content, "num_steps": state['num_steps']}
def analyze_draft_email(state):
print("---ANALYZING DRAFT EMAIL---")
# Implement logic to analyze draft email, providing feedback.
return {"draft_email_feedback": draft_feedback, "num_steps": state['num_steps']}
def rewrite_email(state):
print("---REWRITING EMAIL---")
# Use feedback to rewrite the email.
return {"final_email": final_email_content, "num_steps": state['num_steps']}
def state_printer(state):
print("---STATE---")
print(state)
return state
These additional nodes would ensure a smooth transition through the entire email processing pipeline.
functions draft_email_writer and analyze_draft_email are set up to generate and evaluate email drafts based on the current state, which includes the initial email, its category, research information, and the current step in the process. Here’s a quick analysis of the two functions:
Draft Email Writer (draft_email_writer)
This function creates a draft email based on the initial email, email category, and research info.
def draft_email_writer(state):
print("---DRAFT EMAIL WRITER---")
## Get the state
initial_email = state["initial_email"]
email_category = state["email_category"]
research_info = state["research_info"]
num_steps = state['num_steps']
num_steps += 1
# Generate draft email using the draft_writer_chain
draft_email = draft_writer_chain.invoke({"initial_email": initial_email,
"email_category": email_category,
"research_info": research_info})
print(draft_email)
email_draft = draft_email['email_draft'] # Extract the email draft from response
write_markdown_file(email_draft, "draft_email") # Save draft to a markdown file
return {"draft_email": email_draft, "num_steps": num_steps}
- The function first extracts necessary details from the state (initial_email, email_category, research_info).
- It then calls the draft_writer_chain to generate a draft email.
- The draft email is printed and saved to a markdown file for review.
- The updated state with the generated draft email and incremented num_steps is returned.
Draft Email Analyzer (analyze_draft_email)
This function analyzes the draft email and provides feedback on how to improve it.
def analyze_draft_email(state):
print("---DRAFT EMAIL ANALYZER---")
## Get the state
initial_email = state["initial_email"]
email_category = state["email_category"]
draft_email = state["draft_email"]
research_info = state["research_info"]
num_steps = state['num_steps']
num_steps += 1
# Generate draft email feedback using the draft_analysis_chain
draft_email_feedback = draft_analysis_chain.invoke({"initial_email": initial_email,
"email_category": email_category,
"research_info": research_info,
"draft_email": draft_email})
# Save feedback to a markdown file for later review
write_markdown_file(str(draft_email_feedback), "draft_email_feedback")
return {"draft_email_feedback": draft_email_feedback, "num_steps": num_steps}
- The function takes the state and retrieves necessary information like draft email, research info, and email category.
- It then invokes the draft_analysis_chain to analyze the draft email, providing feedback on its quality and effectiveness.
- The feedback is saved as a markdown file for reference, and the updated state (with feedback and incremented num_steps) is returned.
rewrite_email function is designed to take the draft email and its associated feedback, then use that to generate a final email that incorporates the necessary changes and improvements.
Here’s a breakdown of the function:
def rewrite_email(state):
print("---REWRITE EMAIL ---")
# Extract necessary state variables
initial_email = state["initial_email"]
email_category = state["email_category"]
draft_email = state["draft_email"]
research_info = state["research_info"]
draft_email_feedback = state["draft_email_feedback"]
num_steps = state['num_steps']
# Increment the step count
num_steps += 1
# Generate the final email using the rewrite_chain
final_email = rewrite_chain.invoke({
"initial_email": initial_email,
"email_category": email_category,
"research_info": research_info,
"draft_email": draft_email,
"email_analysis": draft_email_feedback
})
# Save the final email to a markdown file for review
write_markdown_file(str(final_email), "final_email")
# Return updated state with the final email and incremented steps
return {"final_email": final_email['final_email'], "num_steps": num_steps}
Key Points
- Extract State Variables: It starts by extracting the required state variables such as initial_email, email_category, draft_email, research_info, and draft_email_feedback.
- Increment Step Count: The num_steps counter is incremented to reflect that this is a new step in the process (i.e., generating the final email).
- Generate Final Email: The rewrite_chain is used to generate the final email based on the initial email, email category, research info, draft email, and feedback (from the previous step, i.e., the draft_email_feedback).
This step improves the draft email based on the analysis feedback.
- Write Final Email to Disk: The final email is saved to a markdown file (for transparency and review).
- Return Updated State: The function returns the final email and updated num_steps to update the overall state for subsequent steps.
Explanation of the New Functions
- no_rewrite: This function is used when the draft email doesn’t require any further changes and is ready to be sent as the final email.
- Inputs: It takes in the state, specifically focusing on the draft email.
- Process:
- The draft_email is considered final, so it’s saved as the final email.
- The num_steps counter is incremented to track the progress.
- Output: It returns the state with the final_email set to the draft email, and an updated num_steps.
def no_rewrite(state):
print("---NO REWRITE EMAIL ---")
## Get the state
draft_email = state["draft_email"]
num_steps = state['num_steps']
num_steps += 1
# Save the draft email as final email
write_markdown_file(str(draft_email), "final_email")
return {"final_email": draft_email, "num_steps": num_steps}
- state_printer: This function prints out the current state of the process, giving a detailed overview of the variables and their values. This can be useful for debugging or tracking the progress in your email generation pipeline.
- Inputs: It takes the full state as input.
- Process: It prints the values of the initial email, email category, draft email, final email, research info, info needed, and num_steps.
- Output: This function doesn’t return anything but helps in debugging or logging.
def state_printer(state):
"""print the state"""
print("---STATE PRINTER---")
print(f"Initial Email: {state['initial_email']} \n" )
print(f"Email Category: {state['email_category']} \n")
print(f"Draft Email: {state['draft_email']} \n" )
print(f"Final Email: {state['final_email']} \n" )
print(f"Research Info: {state['research_info']} \n")
print(f"Num Steps: {state['num_steps']} \n")
# Check if 'info_needed' exists in the state
info_needed = state.get('info_needed', 'N/A')
print(f"Info Needed: {info_needed} \n")
returnHow These Fit Into the Workflow
- The no_rewrite function is typically called if the system determines that the draft email doesn’t need changes, meaning it’s ready for final delivery.
- The state_printer function is useful during debugging or to check the entire process step-by-step.
Example Flow
- If the rewrite_router or another process determines that no changes are needed, the no_rewrite function is called.
- The state_printer can be invoked at any point in the workflow (typically after completing the email generation) to inspect the final state of the system.
Explanation of route_to_research Function
This function determines the next step in the process flow based on the routing decision made by the research_router. The decision depends on the content of the email and its categorization. Here’s how it works:
- Inputs: The state dictionary, which contains the current state of the email processing workflow, including the initial email and email category.
- Process: The function invokes the research_router to decide whether the email requires additional research (web search) or if it can directly proceed to drafting a response.
The research_router returns a router_decision indicating whether to proceed with research (‘research_info’) or go straight to drafting the email (‘draft_email’).
- Outputs: The function returns the name of the next node to call in the workflow: “research_info” (if the email needs further research) or “draft_email” (if the email can be drafted directly).
- Logging: There are print statements to display the decision made and the reasoning behind it. This is useful for debugging and ensuring that the routing logic works as intended.
Code Implementation
def route_to_research(state):
"""
Route email to web search or not.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE TO RESEARCH---")
initial_email = state["initial_email"]
email_category = state["email_category"]
# Route decision based on the email category and content
router = research_router.invoke({"initial_email": initial_email, "email_category": email_category})
print(router)
# Retrieve the router's decision
print(router['router_decision'])
# Routing logic
if router['router_decision'] == 'research_info':
print("---ROUTE EMAIL TO RESEARCH INFO---")
return "research_info"
elif router['router_decision'] == 'draft_email':
print("---ROUTE EMAIL TO DRAFT EMAIL---")
return "draft_email"
How It Fits into the Graph
- Routing Decision: Based on the result from research_router, this function routes the process to either:
- research_info: If the email requires research to answer a customer query.
- draft_email: If the email can be answered directly without further research.
- Conditional Edge: This function is typically part of a decision-making step (conditional edge) in your state graph, helping steer the workflow.
Example Workflow
- Initial Email is received.
- Email Categorization happens to classify the email into one of the defined categories (e.g., customer feedback).
- Route Decision: Based on the email’s category and content, the route_to_research function decides if further research is required or if a draft email can be created.
- If research is needed, it routes to research_info. Otherwise, it proceeds to draft_email.
Explanation of route_to_rewrite Function
This function determines the next step in the process flow based on the evaluation of the draft email. Specifically, it decides whether the draft email needs to be rewritten or if it can be sent as is. Here’s how it works:
Inputs
The state dictionary, which contains:
- initial_email: The original email from the customer.
- email_category: The category assigned to the email (e.g., customer feedback, product inquiry, etc.).
- draft_email: The email draft generated earlier.
- research_info: Any relevant information retrieved from the research step, although it isn’t used directly here.
Process
The function invokes the rewrite_router to assess whether the draft email needs rewriting based on the initial_email, email_category, and draft_email.
The rewrite_router returns a router_decision, which can be either:
- rewrite: Indicates the draft email needs to be improved and sent for analysis.
- no_rewrite: Indicates the draft email is sufficient and can proceed to the final stage.
Outputs
- If the decision is rewrite, the function routes to the rewrite step to revise the draft.
- If the decision is no_rewrite, the function proceeds to finalize the email.
Logging
There are print statements to log the decision and track the workflow progress.
Code Implementation
def route_to_rewrite(state):
"""
Route email to rewrite or not, based on the draft email quality.
Args:
state (dict): The current graph state
Returns:
str: Next node to call (rewrite or no_rewrite)
"""
print("---ROUTE TO REWRITE---")
initial_email = state["initial_email"]
email_category = state["email_category"]
draft_email = state["draft_email"]
research_info = state["research_info"]
# Invoke the rewrite router to evaluate the draft email
router = rewrite_router.invoke({"initial_email": initial_email,
"email_category": email_category,
"draft_email": draft_email})
print(router)
# Retrieve the router's decision
print(router['router_decision'])
# Routing logic based on the evaluation
if router['router_decision'] == 'rewrite':
print("---ROUTE TO ANALYSIS - REWRITE---")
return "rewrite"
elif router['router_decision'] == 'no_rewrite':
print("---ROUTE EMAIL TO FINAL EMAIL---")
return "no_rewrite"
How It Fits into the Graph
- This function is typically invoked after the draft email has been generated.
- It evaluates the quality of the draft email and decides if it needs further revision or if it can be finalized immediately.
- Based on the decision, it either routes to the rewrite step (where the email is revised) or the no_rewrite step (where the draft is finalized).
Example Workflow
- Initial Email: The customer sends an email.
- Email Categorization: The email is categorized based on its content.
- Draft Email Creation: A draft email is generated.
- Rewrite Decision: The route_to_rewrite function evaluates if the draft needs to be rewritten:
- If rewrite is needed, the draft goes to the rewrite step.
- If no_rewrite is selected, the draft moves to the final email stage.
This code defines the structure of the workflow for processing customer emails using a state graph, where each step of the process is handled by different nodes. Let’s break down the workflow and explain how it works:
Workflow Overview
- StateGraph: This is a directed graph where nodes represent tasks (like categorizing emails, drafting replies, etc.), and edges define the flow of the process from one task to the next.
- Nodes: Each node corresponds to a function or action that will be performed during the workflow (e.g., categorizing the email, generating a draft reply, analyzing the draft).
- Edges: These define the transitions between nodes. Conditional edges allow routing based on decisions (e.g., whether to search for research information or draft the email).
Key Parts of the Graph
- Entry Point: The process starts at the categorize_email node.
- Categorizing the Email:
- The first task is to categorize the incoming email into a predefined category (like “customer feedback”, “product inquiry”, etc.). This is done in the categorize_email node.
- Once categorized, a decision is made whether to search for research info or directly draft a response based on the category.
- Conditional Routing
From categorize_email:
If research info is needed (based on the email category), the workflow moves to research_info_search. Otherwise, it goes to draft_email_writer to directly generate a response draft.
From draft_email_writer: After the draft is created:
- The system evaluates the draft and decides whether it requires rewriting.
- If rewriting is necessary, it sends the draft to analyze_draft_email for review and improvement.
- If no rewrite is needed, the system forwards the draft directly to state_printer for final output.
Finalization
After analyzing and rewriting the draft email or accepting it as-is, the system sends the email to state_printer, which prints the final state of the email along with all relevant information.
End Point: The process concludes when state_printer has finished printing the final email and state information.
# Define the workflow (state graph)
workflow = StateGraph(GraphState)
# Add nodes to the workflow graph
workflow.add_node("categorize_email", categorize_email) # Categorize the email
workflow.add_node("research_info_search", research_info_search) # Perform web search for info
workflow.add_node("state_printer", state_printer) # Print the final state
workflow.add_node("draft_email_writer", draft_email_writer) # Generate draft email
workflow.add_node("analyze_draft_email", analyze_draft_email) # Analyze the draft
workflow.add_node("rewrite_email", rewrite_email) # Rewrite the email if necessary
workflow.add_node("no_rewrite", no_rewrite) # No rewrite needed, just finalize
# Set the entry point to the "categorize_email" node
workflow.set_entry_point("categorize_email")
# Add conditional edges based on the outcome of the categorization
workflow.add_conditional_edges(
"categorize_email",
route_to_research,
{
"research_info": "research_info_search", # If research info needed, go to research
"draft_email": "draft_email_writer", # If no research needed, go to draft email generation
},
)
# Add edges between nodes
workflow.add_edge("research_info_search", "draft_email_writer") # After research, go to drafting
# Add conditional edges based on whether the draft email needs rewriting or not
workflow.add_conditional_edges(
"draft_email_writer",
route_to_rewrite,
{
"rewrite": "analyze_draft_email", # If rewrite needed, go to analyze draft
"no_rewrite": "no_rewrite", # If no rewrite needed, go to final email
},
)
# Add edges to finalize the email or send for rewriting
workflow.add_edge("analyze_draft_email", "rewrite_email") # After analyzing, rewrite the email
workflow.add_edge("no_rewrite", "state_printer") # No rewrite, finalize the email
workflow.add_edge("rewrite_email", "state_printer") # After rewriting, finalize the email
# Finally, add the end node
workflow.add_edge("state_printer", END)
# Compile the workflow into an executable application
app = workflow.compile()
Workflow Execution
- The process begins with categorizing the email.
- Depending on the email category, it either searches for relevant information or moves directly to drafting a response.
- Once the draft is ready, it is evaluated for any necessary revisions.
- The process ends when the final email (either rewritten or not) is printed.
This setup creates a flexible and automated process for handling customer emails, allowing for personalized responses based on their needs.
EMAIL = """HI there, \n
I am emailing to say that I had a wonderful stay at your resort last week. \n
I really appreaciate what your staff did
Thanks,
Paul
"""
EMAIL = """HI there, \n
I am emailing to say that the resort weather was way to cloudy and overcast. \n
I wanted to write a song called 'Here comes the sun but it never came'
What should be the weather in Arizona in April?
I really hope you fix this next time.
Thanks,
George
"""
# run the agent
inputs = {
"initial_email": EMAIL,
"research_info": None,
"num_steps": 0,
"info_needed": False # Ensure this key is added
}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")Output:
---CATEGORIZING INITIAL EMAIL---
'customer_complaint'
---ROUTE TO RESEARCH---
{'router_decision': 'research_info'} research_info
---ROUTE EMAIL TO RESEARCH INFO---
'Finished running: categorize_email:'
---RESEARCH INFO SEARCHING--- Arizona weather April
[Document(metadata={}, page_content="{'location': {'name': 'Arizona', 'region': 'Atlantida', 'country': 'Honduras', 'lat: 15.6333, 'lon': -87.3167, 'tz_id': 'America/Tegucigalpa', 'localtime_epoch: 1731842866, 'localtime': '2824-11-17 05:27'), 'current': {'last_updated_epoch: 1731842100, 'last_updated': '2824-11-17 85:15', 'temp_c": 23.4, 'temp_f': 74.1, 'is_day': 0, 'cond:
<class 'list'>
'Finished running: research_info_search:
---DRAFT EMAIL WRITER---
{"email_draft": "Hi George, \n\nThank you for reaching out to us about the weather conditions during your recent resort stay. Sorry to hear that it was cloudy and overcast, and I can understand why you'd want to write a song about it!\n\nRegarding your question about the weather in Arizona in April, I can provide you with some information. Typically, Arizona's weather in April ---ROUTE TO REWRITE--- {'router_decision': 'no_rewrite"}
no_rewrite
---ROUTE EMAIL TO FINAL EMAIL---
'Finished running: draft_email_writer:"
---NO REWRITE EMAIL ---
'Finished running: no_rewrite:'
---STATE PRINTER---
Initial Email: HI there,
I am emailing to say that the resort weather was way to cloudy and overcast.
I wanted to write a song called 'Here comes the sun but it never came'
What should be the weather in Arizona in April?
I really hope you fix this next time.
Thanks, George
Email Category: 'customer_complaint'
Draft Email: Hi George,
Thank you for reaching out to us about the weather conditions during your recent resort stay. Sorry to hear that it was cloudy and overcast, and I can understand why you'd want to write a song about it!
Regarding your question about the weather in Arizona in April, I can provide you with some information. Typically, Arizona's weather in April is quite comfortable, with low temperatures around 64°F and highs up to 84°F. You can expect a few rainy days, but overall, the weather is usually pleasant during this time.
I want to assure you that we value your feedback and would like to make things right. Unfortunately, we can't control the weather, but we'll do our best to ensure that your next stay with us is more to your liking.
Thank you for your feedback, and I hope you get to write that song someday!
Best regards,
Sarah, Resident Manager
Final Email: Hi George,
Thank you for reaching out to us about the weather conditions during your recent resort stay. Sorry to hear that it was cloudy and overcast, and I can understand why you'd want to write a song about it!
Regarding your question about the weather in Arizona in April, I can provide you with some information. Typically, Arizona's weather in April is quite comfortable, with low temperatures around 64°F and highs up to 84°F. You can expect a few rainy days, but overall, the weather is usually pleasant during this time.output = app.invoke(inputs)
print(output['final_email'])Output:
---CATEGORIZING INITIAL EMAIL---
'customer_complaint'
---ROUTE TO RESEARCH---
{'router_decision': 'research_info"} research info
---ROUTE EMAIL TO RESEARCH INFO---
---RESEARCH INFO SEARCHING---
Arizona weather April
[Document(metadata={}, page_content="{'location': {'name': 'Arizona', 'region': 'Atlantida', 'country': 'Honduras', 'lat: 15.6333, 'lon': -87.3167, 'tz_id': 'America/Tegucigalpa', 'localtime_epoch: 1731842866, 'localtime': '2824-11-17 85:27"}, 'current': {'last_updated_epoch': 1731842188, 'last_updated': '2824-11-17 85:15', 'temp_c": 23.4, 'temp_f': 74.1, 'is_day': 0, 'cone <class 'list'>
---DRAFT EMAIL WRITER---
---ROUTE TO REWRITE---
{"email_draft": "Hi George, \n\nI'm so sorry to hear that the weather didn't quite live up to your expectations during your recent stay at our resort. I can understand how frustrating it must be to experience cloudy and overcast weather, and I appreciate your sense of humor in wanting to write a song titled 'Here comes the sun but it never came'!\n\nRegarding your question ab {'router_decision': 'no_rewrite"}
no_rewrite
---ROUTE EMAIL TO FINAL EMAIL---
---NO REWRITE EMAIL ---
---STATE PRINTER---
Initial Email: HI there,
I am emailing to say that the resort weather was way to cloudy and overcast.
I wanted to write a song called 'Here comes the sun but it never came'
What should be the weather in Arizona in April?
I really hope you fix this next time.
Thanks, George
Email Category: 'customer_complaint"
Draft Email: Hi George,
I'm so sorry to hear that the weather didn't quite live up to your expectations during your recent stay at our resort. I can understand how frustrating it must be to experience cloudy and overcast weather, and I appreciate your sense of humor in wanting to write a song titled 'Here comes the sun but it never came'!
Regarding your question about the weather in Arizona in April, I'd be happy to help. According to our research, April is a great time to visit Arizona, with comfortable temperatures ranging from 64°F to 84°F. While it's not uncommon to experience some rainy days during the month, the weather is generally pleasant and comfortable. If you're planning a trip to Arizona in April, Once again, I apologize for any inconvenience the weather may have caused during your stay, and I hope you'll give us another chance to provide you with a more enjoyable experience in the future.
Thank you for reaching out to us, and I wish you all the best.
Best regards,
Sarah
Resident Manager
Final Email: Hi George,
I'm so sorry to hear that the weather didn't quite live up to your expectations during your recent stay at our resort. I can understand how frustrating it must be to experience cloudy and overcast weather, and I appreciate your sense of humor in wanting to write a song titled 'Here comes the sun but it never came'!
Regarding your question about the weather in Arizona in April, I'd be happy to help. According to our research, April is a great time to visit Arizona, with comfortable temperatures ranging from 64°F to 84°F. While it's not uncommon to experience some rainy days during the month, the weather is generally pleasant and comfortable. If you're planning a trip to Arizona in April, Once again, I apologize for any inconvenience the weather may have caused during your stay, and I hope you'll give us another chance to provide you with a more enjoyable experience in the future.
Thank you for reaching out to us, and I wish you all the best.
Best regards,
Sarah
Resident Manager
Research Info: [Document(metadata={}, page_content="{"location": {'name': 'Arizona', 'region': 'Atlantida', 'country': 'Honduras', 'lat': 15.6333, 'lon': -87.3167, 'tz_id": 'America/Tegucigalpa', 'localtime_epoch": 1731842866, 'localtime': '2824-11-17 85:27'), 'current': {'last_updated_epoch": 1731842180, "last_updated': '2824-11-17 05:15', 'temp_c": 23.4, 'temp_f': 74.1, 'is Info Needed: False
Num Steps: 4
Hi George,
I'm so sorry to hear that the weather didn't quite live up to your expectations during your recent stay at our resort. I can understand how frustrating it must be to experience cloudy and overcast weather, and I appreciate your sense of humor in wanting to write a song titled 'Here comes the sun but it never came'!
Regarding your question about the weather in Arizona in April, I'd be happy to help. According to our research, April is a great time to visit Arizona, with comfortable temperatures ranging from 64°F to 84°F. While it's not uncommon to experience some rainy days during the month, the weather is generally pleasant and comfortable. If you're planning a trip to Arizona in April, Once again, I apologize for any inconvenience the weather may have caused during your stay, and I hope you'll give us another chance to provide you with a more enjoyable experience in the future.
Thank you for reaching out to us, and I wish you all the best.
Best regards,
Sarah
Resident ManagerThe system efficiently categorized the email as a ‘customer_complaint’ and routed it to research the weather information for Arizona in April. The research module gathered detailed data about expected weather patterns, including average temperatures and rainfall. Using this information, a polite and informative draft email was generated, directly addressing the concerns raised by the customer.
As the draft met quality expectations, it bypassed the rewrite process, finalizing with a well-crafted response that provided relevant weather insights and reassured the customer. The process concluded in just 4 steps, showcasing the system’s ability to deliver contextually accurate, customer-focused communication with minimal intervention.
Conclusion
Incorporating LangGraph and GROQ’s LLM into your email workflow provides a robust, scalable, and efficient solution for handling customer communications. By leveraging LangGraph’s flexible state management and GROQ’s advanced natural language processing capabilities, this workflow automates tasks like email categorization, research integration, and response drafting while ensuring quality control and customer satisfaction.
This approach not only saves time and resources but also enhances the accuracy and professionalism of your responses, fostering better relationships with your customers. Whether you’re handling simple inquiries or complex complaints, this workflow is adaptable, reliable, and future-proof, making it an invaluable tool for modern customer service operations.
As businesses continue to prioritize efficiency and customer experience, implementing such intelligent workflows is a step toward maintaining a competitive edge in today’s dynamic environment.
Key Takeaways
- LangGraph automates complex processes with modular, adaptable workflows.
- Steps like analysis and rewriting improve LLM output quality.
- Proper state tracking ensures smooth transitions and consistent results.
- Conditional routing tailors processes to input needs.
- Integrating research augments LLM outputs with relevant, informed content.
Frequently Asked Questions
Q1. What is LangGraph?
A. LangGraph is a state management library designed for orchestrating and structuring workflows involving large language models (LLMs). It provides tools for building and managing complex workflows while keeping track of the state of each process step.
Q2. What is GROQ API?
A. GROQ API provides access to GROQ-powered LLMs, offering high-performance natural language processing capabilities. It is used for tasks like text generation, summarization, classification, and more, making it an essential tool for AI-driven applications.
Q3. How do LangGraph and GROQ API work together?
A. LangGraph provides the structure and control flow for workflows, while GROQ API delivers the LLM capabilities for processing tasks within those workflows. For example, LangGraph can define a workflow where GROQ’s LLM is used to categorize emails, draft responses, or perform analysis.
Q4. Can LangGraph manage workflows with multiple conditional paths?
A. Yes, LangGraph allows you to define workflows with conditional paths based on intermediate outputs. This is useful for applications like routing customer inquiries based on their content.
Q5. What input types does the GROQ API support?
A. GROQ API supports text-based inputs for tasks like text classification, generation, and summarization. It can also handle structured data when appropriately formatted.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi! I am a keen Data Science student who loves to explore new things. My passion for data science stems from a deep curiosity about how data can be transformed into actionable insights. I enjoy diving into various datasets, uncovering patterns, and applying machine learning algorithms to solve real-world problems. Each project I undertake is an opportunity to enhance my skills and learn about new tools and techniques in the ever-evolving field of data science.





