The wait is over – OpenAI o3-mini is finally here! OpenAI has just launched its latest reasoning model, o3-mini, promising faster and more accurate responses compared to its predecessors. The model is now available on the ChatGPT interface and its API services. In this article we will cover the key features of o3-mini and see how it performs against o1-mini, DeepSeek-R1, and other models. We will also learn how to access the model and try out some hands-on applications. So let’s begin!
Table of contents
What is OpenAI o3-mini?
The o3-mini is a streamlined version of OpenAI’s most advanced AI model, o3, which focuses on efficiency and speed. Despite its compact design, it offers advanced reasoning capabilities, enabling it to break down complex problems and provide effective solutions. This model is particularly adept at coding and reasoning tasks, outperforming its predecessor, o1-mini.
The model is currently available to all users of ChatGPT, although free-tier users have access with certain limitations. Meanwhile, ChatGPT Plus, Team, and Pro users can use o3-mini for up to 150 messages per day. Additionally, OpenAI has made the model available through its API services as well. The o3-mini is also accessible via the Microsoft Azure OpenAI Service and GitHub Copilot.
Key Features of OpenAI o3-mini
- Enhanced Reasoning: The model excels in tasks requiring logical reasoning and problem-solving, making it suitable for complex queries.
- Improved Coding Capabilities: Benchmark tests indicate that o3-mini performs admirably in coding tasks, offering higher accuracy and efficiency.
- Faster Response Times: Users experience quicker interactions, enhancing the overall user experience.
OpenAI o3-mini BenchMark Comparisons
Now let’s see how OpenAI’s o3-mini performs in comparison to DeepSeek-R1, o1, o3-mini, and other prominent models.
OpenAI o3-mini vs o1 vs o1-mini
First, let’s see where o3-mini stands in comparison with its predecessors.
1. Graduate-Level Google-Proof Q&A (GPQA) Benchmark
The o3-mini (high) does show some improvement over its predecessors when it comes to English language question-answering. It currently shows to be the best OpenAI model in natural language understanding.

2. American Invitational Mathematics Examination (AIME) Benchmark
In the AIME benchmark, the o3-mini (medium) performs almost as good as the o1 model. Meanwhile, the o3-mini (high) shows significant improvement compared to o1. With an accuracy of 87.3%, it stands as the best performing in mathematical reasoning as well.

3. Codeforces Elo Score
The o1-mini shows great advancement in coding tasks. In the Codeforces benchmark test, the o3-mini (low) outperformed the o1-mini, while giving the o1 model a tough competition. Meanwhile, its medium and high versions performed much better than the previous models, making OpenAI’s o3-mini their best coding model yet.

4. SWE-bench Verified Benchmark
Even on the SWE benchmark, o3-mini proves to be the best OpenAI model in coding, scoring 49.3% accuracy with its high version.

5. FrontierMath
Once again, the o3-mini (high) model has proven it’s dominance in mathematical problem-solving in the FrontierMath benchmark test. The results show that o3-mini (high) is almost twice as good as its predecessors at math.
| Pass@1 | Pass@4 | Pass@8 | |
|---|---|---|---|
| o3-mini (high) | 9.2% | 16.6% | 20.0% |
| o1-mini | 5.8% | 9.9% | 12.8% |
| o1 | 5.5% | 10% | 12.8% |
6. LiveBench Coding
In this coding challenge, all the three versions of o3-mini have proven to outperform OpenAI’s o1 model in LCB generation. The high version performed better than o1 in code completion as well.
| Model | Reasoning Level | Average | LCB Generation | Code Completion |
|---|---|---|---|---|
| o3-mini | low | 0.618 | 0.756 | 0.48 |
| o3-mini | medium | 0.723 | 0.846 | 0.60 |
| o3-mini | high | 0.846 | 0.820 | 0.833 |
| o1 | high | 0.674 | 0.628 | 0.72 |
7. General Knowledge
Testing OpenAI models across various general knowledge benchmark test, shows that o3-mini, especially its high version, is a superior model. While it may only show a slight improvement over o1-mini in math, science, and other topics, its basic question-answering and reasoning capabilities are almost twice as good as o1-mini.
| Category | Eval | o1-mini | o3-mini (low) | o3-mini (medium) | o3-mini (high) |
|---|---|---|---|---|---|
| General | MMLU(pass@t) | 85.2 | 84.9 | 85.9 | 86.9 |
| Math(pass@t) | 90.0 | 95.8 | 97.3 | 97.9 | |
| Math | MGSM(pass@t) | 89.9 | 55.1 | 90.8 | 92.0 |
| Factuality | SimpleQA | 7.6 | 13.0 | 13.4 | 13.8 |
OpenAI o3-mini vs DeepSeek-R1 and Other Models
Now let’s compare it with the currently leading models such as Claude 3.5, DeepSeek-R1, and DeepSeek-V3.
1. Graduate-Level Google-Proof Q&A (GPQA) Benchmark
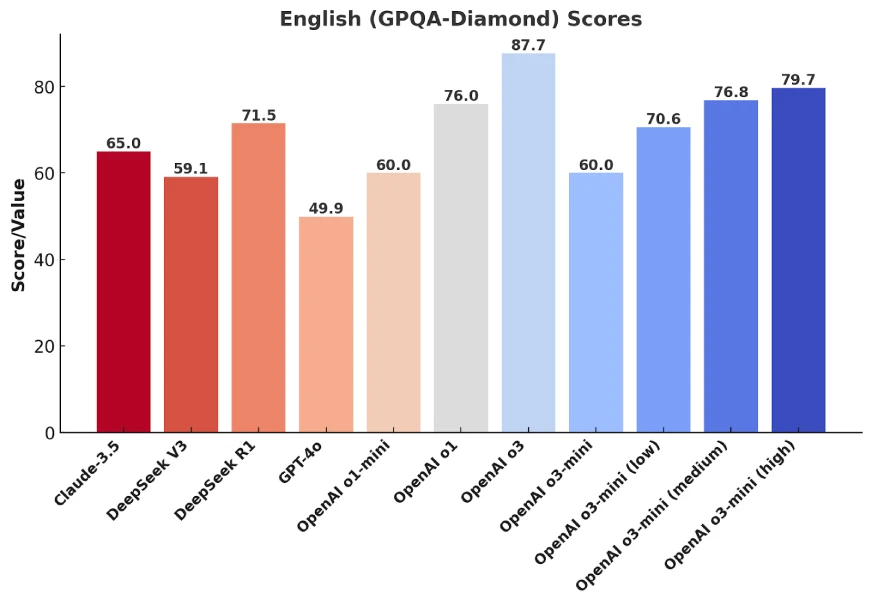
Both o3-mini (medium) and o3-mini (high) prove to be better than DeepSeek-R1 and Claude-3.5 in detailed & factual question-answering tasks.
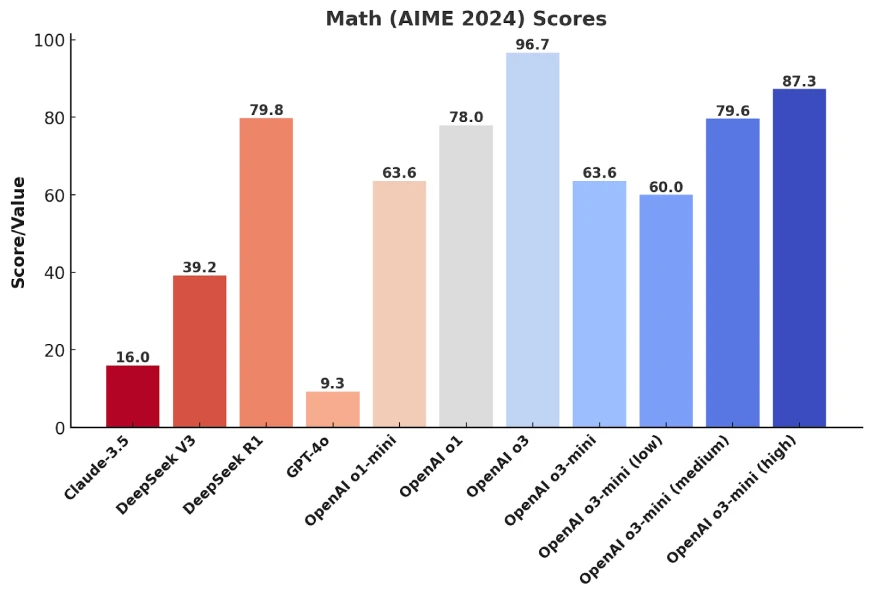
2. American Invitational Mathematics Examination (AIME) Benchmark
While o3-mini (medium) gives a close competition to DeepSeek-R1 in math, the o3-mini (high) outperforms it by over 10%, proving its dominance in the subject.
3. Codeforces Elo Score
When it comes to coding, both the medium and high versions of o3-mini outperform DeepSeek-R1 and the other models. The Elo score of o3-mini (high) is the current highest amongst all the models available today.

4. SWE-bench Verified Benchmark
When it comes to handling real-world software engineering problems, Claude 3.5 still stands as the best performing model. However, o3-mini (high) gives it a close competition, marginally overtaking DeepSeek-R1.
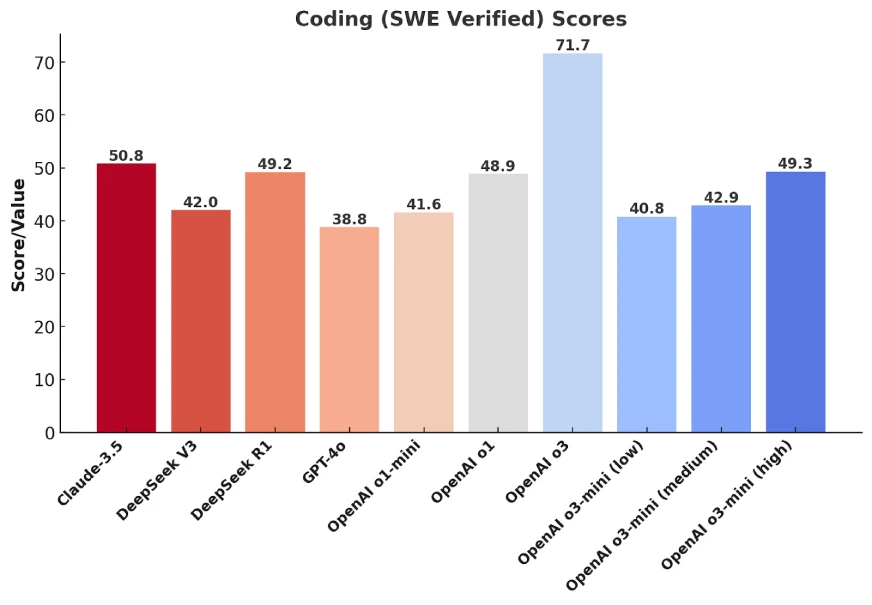
In all of these comparisons, we see the yet to come o3 model outperform others.
Sources:
- OpenAI: https://openai.com/index/openai-o3-mini/
- o3 and o3-mini—12 Days of OpenAI
- DeepSeek: https://github.com/deepseek-ai/DeepSeek-R1
How to Access OpenAI’s o3-mini?
There are 2 ways to access o3-mini. The first is through their chatbot interface, using ChatGPT. The second is via API. We will guide you through both options in the next section.
Accessing OpenAI o3-mini via ChatGPT
Free-tier users of ChatGPT can experience the potential of o3-mini by selecting ‘Reason’ below the message box.
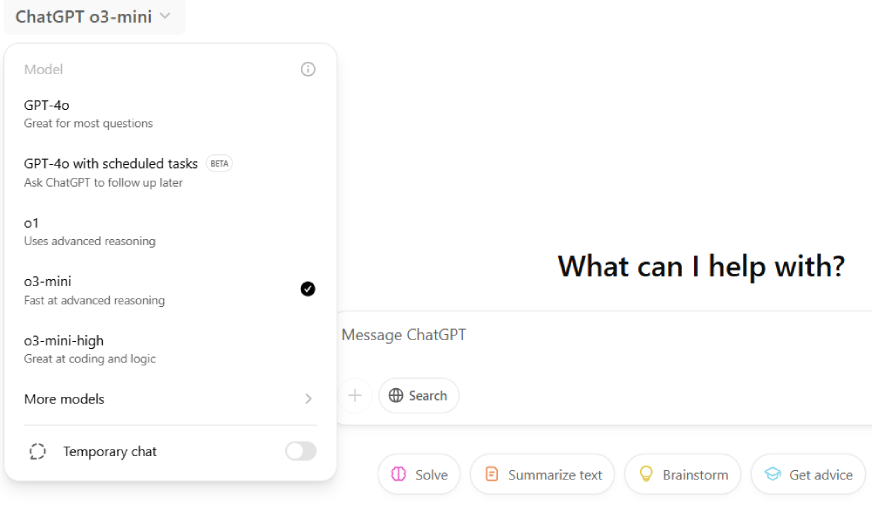
ChatGPT Plus, Team, and Pro users can directly select “o3-mini” or “o3-mini-high” from the model picker drop down list at the top, and start using it.
How to Access OpenAI’s o3-mini via API?
Here’s how you can access OpenAI’s o3-mini using their API.
Step 1: Sign up for API Access
If you are not already part of the OpenAI beta program, you’ll need to request access by visiting OpenAI’s API page. Once you sign up, you may need to wait for approval to access the o3-mini models.
Step 2: Generate an API Key
Once you have access, log in to the OpenAI API platform and generate an API key. This key is necessary for making API requests. To generate the key, go to API Keys and click on “Create New Secret Key”. Once generated, make sure to copy the key and save it securely.
Step 3: Install the OpenAI Python SDK
To interact with the o1 API, you will need to install the OpenAI Python SDK. You can do this using the following command:
!pip install openaiThis package allows you to make API requests to OpenAI from your Python code.
Step 4: Initialize the OpenAI Client
After installing the OpenAI SDK, you need to initialize the client by setting up the API key:
import os
os.environ["OPENAI_API_KEY"] = "Enter_api_key"Step 5: Execute and Verify the Output
Now that we have set up the OpenAI client, let’s try using the o3-mini model to solve this problem on LeetCode.
completion = client.chat.completions.create(
model="o3-mini",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": """ You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
Example 1:
Input: l1 = [2,4,3], l2 = [5,6,4]
Output: [7,0,8]
Explanation: 342 + 465 = 807.
Example 2:
Input: l1 = [0], l2 = [0]
Output: [0]
Example 3:
Input: l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
Output: [8,9,9,9,0,0,0,1]
Constraints:
The number of nodes in each linked list is in the range [1, 100].
0 <= Node.val <= 9
It is guaranteed that the list represents a number that does not have leading zeros.
Output code in python as below:
class Solution(object):
def addTwoNumbers(self, l1, l2):
#:type l1: Optional[ListNode]
#:type l2: Optional[ListNode]
#:rtype: Optional[ListNode]
"""
}
]
)
print(completion.choices[0].message.content)Output:

Hands-on Applications of o3-mini
Now let’s try out the o3-mini and test its logical reasoning, mathematical reasoning, and coding skills.
Task 1: Logical Reasoning
Prompt: “You have eight balls, one of which is slightly heavier than the others. You have a balance scale but can only use it twice. How do you determine which ball is the heaviest?”
Output:
“To find the heaviest ball among the eight using a balance scale only twice, follow this optimal weighing strategy:
Step 1: First Weighing
- Divide the 8 balls into 3 groups:
- Group A: 3 balls
- Group B: 3 balls
- Group C: 2 balls (set aside)
- Place Group A on the left pan and Group B on the right pan of the balance.
Step 2: Analyze the First Weighing Outcome
- If one side is heavier:
- The heavier side contains the heaviest ball.
- Now, you have 3 balls left to test in the next step.
- If the scale is balanced:
- The heaviest ball is among the 2 balls in Group C.
- Move to Step 3.
Step 3: Second Weighing
- If the heaviest ball is in a set of 3 balls (from Step 2):
- Pick two balls from this set and place one on each pan.
- If one side is heavier → that’s the heaviest ball.
- If the scale is balanced → the third ball (not weighed) is the heaviest.
- If the heaviest ball is in Group C (2 balls):
- Weigh the two balls against each other.
- The heavier one is the answer.
Conclusion
This method guarantees that you will identify the heaviest ball in exactly two weighings.”
Task 2: Mathematical Reasoning
Prompt: “If I invest Rs 1 lakh in a bank account that offers a 5% annual interest rate, compounded yearly. How much will I have in the account after 10 years? Provide a step-by-step calculation.”
Output:


Task 3: Coding
Prompt: “You are given a dataset with 1 million rows and need to clean and preprocess it efficiently. Write a Python script using Dask or multiprocessing to handle missing values, normalize numerical features, and apply one-hot encoding to categorical columns. Explain why your approach is more efficient than using pandas alone”
import dask.dataframe as dd
from dask_ml.preprocessing import StandardScaler
import pandas as pd
import dask.multiprocessing
def preprocess_data(file_path):
"""
Efficiently preprocesses a large dataset using Dask.
Steps:
- Load data in parallel
- Handle missing values
- Normalize numerical features
- One-hot encode categorical columns
"""
# Load dataset using Dask
df = dd.read_csv(file_path)
# Fill missing values
df = df.fillna(df.mean())
# Identify numerical and categorical columns
numerical_cols = df.select_dtypes(include=['float64', 'int64']).columns
categorical_cols = df.select_dtypes(include=['object']).columns
# Normalize numerical features
scaler = StandardScaler()
df[numerical_cols] = scaler.fit_transform(df[numerical_cols])
# One-hot encode categorical columns
df = dd.get_dummies(df, columns=categorical_cols)
# Compute the final result in parallel
df = df.compute(scheduler='multiprocessing')
return df
# Example usage
# processed_df = preprocess_data("large_dataset.csv")
# processed_df.to_csv("cleaned_data.csv", index=False)
"""
Why this approach is efficient:
1. **Dask for Parallel Processing:** Unlike pandas, which loads data into memory, Dask processes large datasets in parallel using task scheduling, making it memory efficient.
2. **Lazy Evaluation:** Dask loads only the required chunks of data, preventing memory overload.
3. **Multiprocessing Scheduler:** Utilizes multiple cores to speed up computation, outperforming pandas in large-scale data operations.
"""Also Read: DeepSeek R1 vs OpenAI o1 vs Sonnet 3.5: Battle of the Best LLMs
Conclusion
Breaking all benchmarks, OpenAI’s o3-mini surely represents a significant advancement in AI model development. It seems to offer a good balance between performance and efficiency. Its enhanced reasoning and coding capabilities, coupled with faster response times, make it one of the best and most efficient models we currently have. The broad accessibility of o3-mini to all users and also through the API ensures that a wide range of users can leverage its capabilities.
So go ahead, try it out, and let us know in the comments how good you think it is!
Unlock the power of AI! Enroll in Getting Started with OpenAI o3-mini and build your foundation in AI-driven solutions. Start learning today!
Frequently Asked Questions
Q1. Is OpenAI o3-mini better than o1-mini?
A. A. OpenAI o3-mini is a streamlined version of OpenAI’s latest reasoning model, o3. It is designed for faster and more efficient performance, particularly in logical reasoning and coding tasks. Compared to o1-mini, o3-mini offers improved accuracy, better problem-solving capabilities, and higher benchmark scores.
Q2. Is OpenAI o3-mini available for free?
A. Yes, free-tier users of ChatGPT can access o3-mini under the “Reason” mode, but with limitations. For extended usage, ChatGPT Plus, Team, and Pro users get access to up to 150 messages per day.
Q3. How does o3-mini perform in mathematical and logical reasoning?
A. o3-mini (high) achieves 87.3% accuracy on the AIME benchmark, making it OpenAI’s best-performing model in mathematical reasoning. It also outperforms DeepSeek-R1 in logical reasoning tests, showing significant improvements over previous models.
Q4. How well does o3-mini handle coding tasks?
A. The model has top scores in coding benchmarks like Codeforces Elo and SWE-bench. The high version of o3-mini is OpenAI’s best coding model yet, surpassing o1 and o1-mini in real-world programming challenges.
Q5. How does o3-mini compare to DeepSeek-R1?
A. OpenAI’s o3-mini outperforms DeepSeek-R1 in multiple areas, particularly in reasoning, coding, and mathematical problem-solving. While both models are optimized for efficiency, o3-mini achieves higher scores on all key benchmarks.
Q6. How can developers use o3-mini via API?
A. Developers can access o3-mini through OpenAI’s API and Microsoft Azure OpenAI Service. To use it, you need to generate an API key, install the OpenAI Python SDK, and make API calls using the “o3-mini” model identifier.
Q7. What’s next after o3-mini?
A. OpenAI is expected to release o3, a more powerful version with further improvements in reasoning, coding, and real-world application handling. Based on current benchmarks, o3-mini’s strong performance hints at an even more capable upcoming model.
Sabreena is a GenAI enthusiast and tech editor who's passionate about documenting the latest advancements that shape the world. She's currently exploring the world of AI and Data Science as the Manager of Content & Growth at Analytics Vidhya.





