Have you ever found it difficult to understand a large, messy codebase? Or wondered how tools that analyze and explore code actually work? In this article, we’ll solve these problems by building a powerful codebase exploration tool from scratch. Using static code analysis and the Gemini model, we’ll create an easy-to-use system that helps developers query, understand, and gain useful insights from their code. Ready to change the way you navigate code? Let’s begin!
Learning Objectives
- Complex software development using Object Oriented Programming.
- How to parse and analyze the Python Codebase using AST or Abstract Syntax Tree.
- Understanding how to integrate Google’s Gemini LLM API with the Python application of code analysis.
- Typer Command line-based query system for codebase exploration.
This article was published as a part of the Data Science Blogathon.
Table of contents
The Need for Smarter Code Exploration
First of all, building such an application gives you a learning boost in software development, it will help you learn how to implement complex software using Object Oriented Programming paradigm and also help you to master the art of handling large projects (although it is not that large)
Second, today’s software projects consist of thousands of lines of code written across many files and folders. Traditional approaches to code exploration, such as Grep or IDE search function. This type of system will fall short when developers need to understand the higher-level concepts or relationships within the codebase. Our AI-powered tools can make a significant stride in this realm. Our application allows developers to ask questions about their codebase in plain English and receive detailed, contextual responses.
Architecture Overview
The tool consists of four main components
- Code Parser: It is the foundation of our system, which is responsible for analyzing Python files and extracting their structure using Python’s Abstract Syntax Tree (AST) module. It identifies classes, methods, functions, and imports. It will create a comprehensive map of the codebase.
- Gemini Client: A wrapper around Google’s Gemini API that handles communication with the LLM model. These components manage API authentication and provide a clean interface for sending queries and receiving responses.
- Query Processor: It is the main engine of the tool which is responsible for formatting the codebase context and queries in a way that Gemini can understand and process effectively. It maintains a persistent index of the codebase structure and manages the interaction between the parser and the LLM.
- CLI interface: A user-friendly command-line interface built with Typer, providing commands for indexing codebase, querying code structure, and analyzing stack traces.
Starting Hands-on Project
This section will guide you through the initial steps to build and implement your project, ensuring a smooth start and effective learning experience.
Project Folder Structure
The project folder structure will be similar to these
|--codebase_explorer/
|src/
├──| __init__.py
├──| indexer/
│ ├── __init__.py
│ └── code_parser.py
├──| query_engine/
│ ├── __init__.py
│ ├── query_processor.py
│ └── gemini_client.py
|
├── main.py
└── .env
Setup Project Environment
Setup project environment in the following step:
#create a new conda env
conda create -n cb_explorer python=3.11
conda activate cb_explorerInstall all the necessary libraries:
pip install google-generativeai google-ai-generativelanguage
pip install python-dotenv typer llama-indexImplementing the Code
We will start with understanding and implementing the codebase parsing system. It has two important functions
- parse_codebase()
- extract_definitions()
Extracting definitions from the Abstract Syntax Tree:
import ast
import os
from typing import Dict, Any
def extract_definitions(tree: ast.AST) -> Dict[str, list]:
"""Extract class and function definitions from AST."""
definitions = {
"classes": [],
"functions": [],
"imports": []
}
for node in ast.walk(tree):
if isinstance(node, ast.ClassDef):
definitions["classes"].append({
"name": node.name,
"lineno": node.lineno
})
elif isinstance(node, ast.FunctionDef):
definitions["functions"].append({
"name": node.name,
"lineno": node.lineno
})
elif isinstance(node, ast.Import):
for name in node.names:
definitions["imports"].append(name.name)
return definitionsThis is a helper function for parse_codebase(). It will take an abstract syntax tree(AST) of a Python file. The function initiates a dictionary with empty lists for classes, functions, and imports. Now, ast.walk() iterates through all nodes in the AST tree. The AST module will identify all the Classes, Functions, Imports, and line numbers. Then append all the definitions to the definitions dictionary.
Parsing CodeBase
This function scans a directory for Python files, reads their content, and extracts their structure.
import ast
import os
from typing import Dict, Any
def parse_codebase(directory: str) -> Dict[str, Any]:
"""Parse Python files in the directory and extract code structure."""
code_structure = {}
for root, _, files in os.walk(directory):
for file in files:
if file.endswith(".py"):
file_path = os.path.join(root, file)
with open(file_path, "r", encoding="utf-8") as f:
try:
content = f.read()
tree = ast.parse(content)
code_structure[file_path] = {
"definitions": extract_definitions(tree),
"content": content
}
except Exception as e:
print(f"Error parsing {file_path}: {e}")
return code_structureThe functions initiate with the directory path as a string. It outputs a dictionary of code’s structures. The dictionary stores the extracted data for each Python file.
It loops through all subdirectories and the files in the given directory. os.walk() provided a recursive way to explore the entire directory tree. It will process files ending the .py extensions.
Using the Python ast module to parse the file’s content into an abstract syntax tree (AST), which represents the file’s structure. The extracted tree is then passed to the extract_definitions(tree). If parsing fails, it prints an error message but continues processing other files.
Query Processing Engine
In the query engine directory create two files named gemini_client.py and query_processor.py
Gemini Client
This file will use <GOOGLE_API_KEY> to authenticate the Gemini model API from Google. In the root of the project, create a .env file and put your GEMINI API KEY in it. Get your API_KEY here.
import os
from typing import Optional
from google import generativeai as genai
from dotenv import load_dotenv
load_dotenv()
class GeminiClient:
def __init__(self):
self.api_key = os.getenv("GOOGLE_API_KEY")
if not self.api_key:
raise ValueError("GOOGLE_API_KEY environment variable is not set")
genai.configure(api_key=self.api_key)
self.model = genai.GenerativeModel("gemini-1.5-flash")
def query(self, prompt: str) -> Optional[str]:
"""Query Gemini with the given prompt."""
try:
response = self.model.generate_content(prompt)
return response.text
except Exception as e:
print(f"Error querying Gemini: {e}")
return NoneHere, we define a GeminiClient class to interact with Google’s Gemini AI model. It will authenticate the model using GOOGLE_API_KEY from your .env file. After configuring the model API, it provides a query method to generate a response on a given prompt.
Query Handling System
In this section, we will implement the QueryProcessor class to manage the codebase context and enable querying with Gemini.
import os
import json
from llama_index.embeddings.gemini import GeminiEmbedding
from dotenv import load_dotenv
from typing import Dict, Any, Optional
from .gemini_client import GeminiClient
load_dotenv()
gemini_api_key = os.getenv("GOOGLE_API_KEY")
model_name = "models/embeddings-001"
embed_model = GeminiEmbedding(model_name=model_name, api_key=gemini_api_key)
class QueryProcessor:
def __init__(self):
self.gemini_client = GeminiClient()
self.codebase_context: Optional[Dict[str, Any]] = None
self.index_file = "./indexes/codebase_index.json"
def load_context(self):
"""Load the codebase context from disk if it exists."""
if os.path.exists(self.index_file):
try:
with open(self.index_file, "r", encoding="utf-8") as f:
self.codebase_context = json.load(f)
except Exception as e:
print(f"Error loading index: {e}")
self.codebase_context = None
def save_context(self):
"""Save the codebase context to disk."""
if self.codebase_context:
try:
with open(self.index_file, "w", encoding="utf-8") as f:
json.dump(self.codebase_context, f, indent=2)
except Exception as e:
print(f"Error saving index: {e}")
def set_context(self, context: Dict[str, Any]):
"""Set the codebase context for queries."""
self.codebase_context = context
self.save_context()
def format_context(self) -> str:
"""Format the codebase context for Gemini."""
if not self.codebase_context:
return ""
context_parts = []
for file_path, details in self.codebase_context.items():
defs = details["definitions"]
context_parts.append(
f"File: {file_path}\n"
f"Classes: {[c['name'] for c in defs['classes']]}\n"
f"Functions: {[f['name'] for f in defs['functions']]}\n"
f"Imports: {defs['imports']}\n"
)
return "\n\n".join(context_parts)
def query(self, query: str) -> Optional[str]:
"""Process a query about the codebase."""
if not self.codebase_context:
return (
"Error: No codebase context available. Please index the codebase first."
)
prompt = f"""
Given the following codebase structure:
{self.format_context()}
Query: {query}
Please provide a detailed and accurate answer based on the codebase structure above.
"""
return self.gemini_client.query(prompt)After loading the necessary libraries, load_dotenv() loads environment variables from the .env file which contains our GOOGLE_API_KEY for the Gemini API key.
- GeminiEmbedding class initializes the embedding-001 models from the Google server.
- QueryProcessor class is designed to handle the codebase context and interact with the GeminiClient. Loading_context method loads codebase information from a JSON file it exists.
- The saving_context method saves the current codebase context into the JSON file for persistence. save_context method updates the codebase context and immediately saves it using save_context and the format_context method converts the codebase data into a human-readable string format, summarizing file paths, classes, functions, and imports for queries.
- Querying Gemini is the most important method which will construct a prompt using the codebase context and the user’s query. It sends this prompt to the Gemini model through GeminiClient and gets back the response.
Command Line App Implementation(CLI)
Create a main.py file in the src folder of the project and follow the steps
Step 1: Import Libraries
import os
import json
import typer
from pathlib import Path
from typing import Optional
from indexer.code_parser import parse_codebase
from query_engine.query_processor import QueryProcessorStep 2: Initialize typer and query processor
Let’s create a typer and query processor object from the classes.
app = typer.Typer()
query_processor = QueryProcessor()Step 3: Indexing the Python Project Directory
Here, the index method will be used as a command in the terminal, and the function will index the Python codebase in the specified directory for future querying and analysis.
@app.command()
def index(directory: str):
"""Index a Python codebase for querying and analysis."""
dir_path = Path(directory)
if not dir_path.exists():
typer.echo(f"Error: Directory '{directory}' does not exist")
raise typer.Exit(1)
typer.echo("Indexing codebase...")
try:
code_structure = parse_codebase(directory)
query_processor.set_context(code_structure)
typer.echo(f"Successfully indexed {len(code_structure)} Python files")
except Exception as e:
typer.echo(f"Error indexing codebase: {e}")
raise typer.Exit(1)It will first check if the directory exists and then use the parse_codebase function to extract the structure of Python files in the directory.
After parsing it will save the parsed codebase structure in query_processor. All the processes are in the try and except block so that exceptions can be handled with care during parsing. It will prepare the codebase for efficient querying using the Gemini model.
Step 4: Querying the codebase
After indexing we can query the codebase for understanding or getting information about any functions in the codebase.
@app.command()
def query(query_text: str):
"""Query the indexed codebase using natural language."""
if not query_processor.codebase_context:
query_processor.load_context()
response = query_processor.query(query_text)
if response:
typer.echo(response)
else:
typer.echo("Error: Failed to process query")
raise typer.Exit(1)First, check whether the query_processor has loaded a codebase context or not and try to load the context from the computer’s hard disk. and then uses the query_processor’s query method to process the query.
And the last, it will print the response from the LLM to the terminal using typer.echo() method.
Step 5: Run the Application
if __name__ == "__main__":
app()Test the Application
To test your hard work follow the below steps:
- Create a folder name indexes in your project root where we will put all our index files.
- Create a codebase_index.json and put it in the previously (indexes) created folder.
- Then create a project_test folder in the root where we will store our Python files for testing
- Create a find_palidrome.py file in the project_test folder and put the below code in the file.
Code Implementation
def find_palindromes(s: str) -> list:
"""
Find all distinct palindromic substrings in the given string.
Args:
s (str): Input string to search for palindromes.
Returns:
list: A list of all distinct palindromic substrings.
"""
def is_palindrome(substring: str) -> bool:
return substring == substring[::-1]
n = len(s)
palindromes = set()
for i in range(n):
# Odd-length palindromes (centered at i)
l, r = i, i
while l >= 0 and r < n and s[l] == s[r]:
palindromes.add(s[l : r + 1])
l -= 1
r += 1
# Even-length palindromes (centered between i and i+1)
l, r = i, i + 1
while l >= 0 and r < n and s[l] == s[r]:
palindromes.add(s[l : r + 1])
l -= 1
r += 1
return sorted(palindromes)
# Example usage:
input_string = "ababa"
print(find_palindromes(input_string))This file will find the palindrome from a given string. we will index this file query from terminal using the CLI application.
Now, open your terminal, paste the code and see the magic.
Indexing the project
$ python .\src\main.py index .\project_test\Output:

You may show Successfully indexed 1 Python file. and the JSON data looks like
{
".\\project_test\\find_palindrome.py": {
"definitions": {
"classes": [],
"functions": [
{
"name": "find_palindromes",
"lineno": 1
},
{
"name": "is_palindrome",
"lineno": 12
}
],
"imports": []
},
"content": "def find_palindromes(s: str) -> list:\n \"\"\"\n Find all distinct palindromic substrings in the given string.\n\n Args:\n s (str): Input string to search for palindromes.\n\n Returns:\n
list: A list of all distinct palindromic substrings.\n \"\"\"\n\n def is_palindrome(substring: str) -> bool:\n return substring == substring[::-1]\n\n n = len(s)\n palindromes = set()\n\n for i in range(n):\n
# Odd-length palindromes (centered at i)\n l, r = i, i\n while l >= 0 and r < n and s[l] == s[r]:\n palindromes.add(s[l : r + 1])\n l -= 1\n r += 1\n\n
# Even-length palindromes (centered between i and i+1)\n
l, r = i, i + 1\n while l >= 0 and r < n and s[l] == s[r]:\n palindromes.add(s[l : r + 1])\n l -= 1\n r += 1\n\n return sorted(palindromes)\n\n\n#
Example usage:\ninput_string = \"ababa\"\nprint(find_palindromes(input_string))\n"
},
}Querying the project
$ python ./src/main.py query "Explain is_palindrome function in 30 words?"Output:
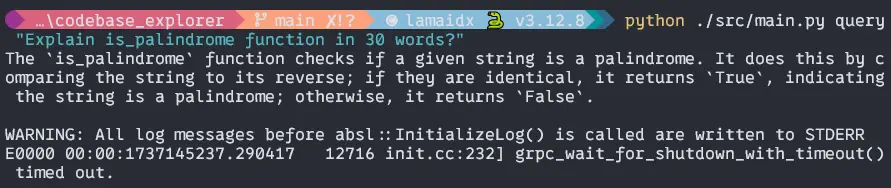
$ python ./src/main.py query "Explain find_palindrome function in 30 words?Output:
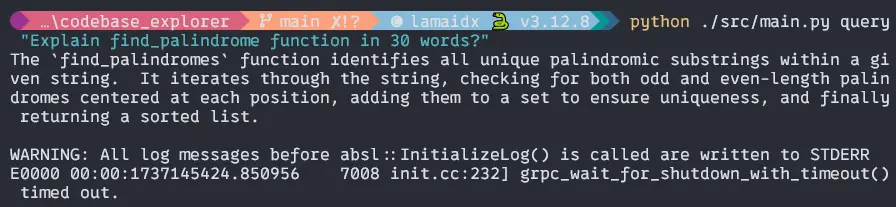
If everything is done properly you will get these outputs in your terminal. You can try it with your Python code files and tell me in the comment section what is your output. THANK YOU for staying with me.
Future Development
This is a prototype of the foundation system that can be extended with many interesting features, such as
- You can integrate with IDE plugins for seamless code exploration.
- AI-driven automated debugging system (I am working on that).
- Adding support for many popular languages such as Javascript, Java, Typescripts, Rust.
- Real-time code analysis and LLM powered suggestions for improvements.
- Automated documentation using Gemini or LLama3.
- Local LLM integration for on-device code exploration , features addition.
Conclusion
The Codebase Explorer helps you understand the practical application of AI in software development tools. By combining traditional static analysis with modern AI capabilities, we have created a tool that makes codebase exploration more intuitive and efficient. This approach shows how AI can augment developer workflows without replacing existing tools, providing a new layer of understanding and accessibility to complex codebases.
All the code used in this article is here.
Key Takeaways
- Structure code parsing is the most imortant technique for the code analysis.
- CodeBase Explorer simplifies code navigation, allowing developers to quickly understand and manage complex code structures.
- CodeBase Explorer enhances debugging efficiency, offering tools to analyze dependencies and identify issues faster.
- Gemini can significantly enhance code understanding when combined with traditional static analysis.
- CLI tools can provide a powerful interface for LLM assisted code exploration.
Frequently Asked Questions
Q1. How does the tool handle large codebase?
A. The tool uses a persistent indexing system that parses and stores the codebase structure, allowing for efficient queries without nedding to reanalyze the code each time. The index is updated only when the codebase changes.
Q2. Can the tool work offline?
A. The code parsing and index management can work offline, but the querying the codebase using Gemini API need internet connection to communicate with the external servers. We can integrated Ollama with the tools which will possible to use on-device LLM or SLM model such as LLama3 or Phi-3 for querying the codebase.
Q3. How accurate are the LLM generated responses?
A. The accuracy depends on both the quality of the parsed code context and the capabilities of the Gemini model. The tools provides structured code information to the AI model, with helps improve response accuracy, but users should still verify critical information through traditional means.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A self-taught, project-driven learner, love to work on complex projects on deep learning, Computer vision, and NLP. I always try to get a deep understanding of the topic which may be in any field such as Deep learning, Machine learning, or Physics. Love to create content on my learning. Try to share my understanding with the worlds.


