Fine-tuning large language models (LLMs) is an essential technique for customizing LLMs for specific needs, such as adopting a particular writing style or focusing on a specific domain. OpenAI and Google AI Studio are two major platforms offering tools for this purpose, each with distinct features and workflows. In this article, we will examine how these platforms perform in fine-tuning tasks, using my previously written articles as training data. We will evaluate the ability of OpenAI Platform and Google AI Studio to fine-tune LLMs to generate content that mirrors my writing style.
Table of Contents
OpenAI Platform
The OpenAI platform offers a comprehensive solution for fine-tuning models, allowing users to customize and optimize them for specific tasks. This platform supports a variety of models, including GPT-4o and GPT-4o-mini. OpenAI also provides guidance for data preparation, model training, and evaluation. By leveraging the OpenAI platform, users can enhance the performance of models in specific domains. This makes them more effective and efficient for targeted applications.
The cost of fine-tuning is as follows:
| Model | Pricing |
|---|---|
| gpt-4o-2024-08-06 | $3.750 / 1M input tokens $15.000 / 1M output tokens $25.000 / 1M training tokens |
| gpt-4o-mini-2024-07-18 | $0.300 / 1M input tokens $1.200 / 1M output tokens $3.000 / 1M training tokens |
The cost of inference for fine-tuned models is double that of pre-existing models.
Data Preparation
LLMs need data to be in a specific format for fine-tuning. Here’s an example format for GPT-4o and GPT-4o-mini models.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}When we fine-tune the model, it will learn to produce responses similar to assistant role content for a given user role content.
Since we want the model to produce content similar to ours, we should use our content in place of assistant content.
Let’s consider this content from one of my articles:
“So, rather than traversing all the nodes using a graph using HNSW, we are localising the search space using dynamic vantage point tree in this algorithm.
This combination of using both tree and graph makes it one of the fastest and most accurate algorithms.”
Since we want the LLM to generate content like the one above, it should be added as the assistant content like this:
{"role": "assistant", "content": "So, rather than traversing all the nodes using a graph using HNSW, we are localising the search space using dynamic vantage point tree in this algorithm.This combination of using both tree and graph makes it one of the fastest and most accurate algorithms."}For the LLM to generate content like this, it needs user content (i.e. prompt). As we don’t have it, we can generate the user content using an LLM. The user content can be as follows:
{"role": "user", "content": "Can you explain how the combination of dynamic vantage point trees and hierarchical navigable small world (HNSW) graphs improves search efficiency and accuracy in algorithms?"}We also include a suitable system prompt the example for our fine-tuning will be as follows
{"messages": [{"role": "system", "content": "You are an assistant who writes in a clear, informative, and engaging style."}, {"role": "user", "content": "Can you explain how the combination of dynamic vantage point trees and hierarchical navigable small world (HNSW) graphs improves search efficiency and accuracy in algorithms?"}, {"role": "assistant", "content": "So, rather than traversing all the nodes using a graph using HNSW, we are localising the search space using dynamic vantage point tree in this algorithm.\n This combination of using both tree and graph makes it one of the fastest and most accurate algorithms."}]}If we use a small size of content, it is possible that the model might miss the context. We need to keep this in mind while data preparation. I am only using 38 examples here, but 100 to 500 would be much better. I have created a ‘my content.csv’ file where each row has the content written by me under the column name ‘content’.
Now let’s go through the code to create the required data in the right format.
Code Implementation
OpenAI version 1.57.0 is used here.
1. Import the libraries.
from dotenv import load_dotenv
load_dotenv('/.env')
import pandas as pd
import tiktoken
from openai import OpenAI
# Initialize the openai client
client = OpenAI()
2. Check token size.
df = pd.read_csv('my content.csv')
encoding = tiktoken.get_encoding('o200k_base')
total_token_count = 0
for i in df['content']:
token_count = len(encoding.encode(i))
total_token_count += token_countCounting tokens will help us to estimate the cost of fine-tuning.
3. Generate user content for the LLM.
def generate_user_content(assistant_response):
# system_message = {"role": "system", "content": "You are a helpful assistant. Your task is to generate user query based on the assistant's response."}
system_message = {"role": "system", "content": """Given the assistant's response, create a user query or
statement that would logically lead to that response.
The user content can be in the form of a question or a request for clarification that prompts the
assistant to give the provided answer"""}
assistant_message = {"role": "assistant", "content": assistant_response}
messages = [system_message, assistant_message]
response = client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
temperature=1
)
user_content = response.choices[0].message.content
return user_contentAs we can see, I have provided the content I wrote as assistant content and asked the LLM to generate user content.
user_contents = []
for i in df['content']:
user_content = generate_user_content(i)
user_contents.append(user_content)
df['user_content'] = user_contentsWe can add the generated user content to the dataframe as a column. The data will look like this:
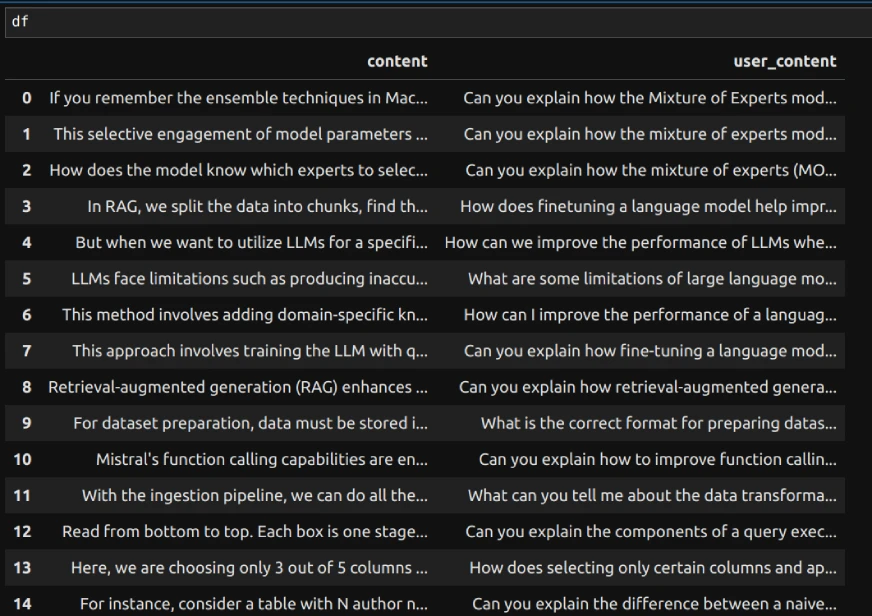
Here, content is written by me and user_content is generated by the LLM to use as a user role content (prompt) while fine-tuning.
We can save the file now.
df.to_csv('user_content.csv', index=False)4. Create Jsonl file.
Now we can use the above csv file to create jsonl file as needed for fine-tuning.
messages = pd.read_csv('user_content.csv')
messages.rename(columns={'content': 'assistant_content'}, inplace=True)
with open('messages_dataset.jsonl', 'w', encoding='utf-8') as jsonl_file:
for _, row in messages.iterrows():
user_content = row['user_content']
assistant_content = row['assistant_content']
jsonl_entry = {
"messages": [
{"role": "system", "content": "You are an assistant who writes in a clear, informative, and engaging style."},
{"role": "user", "content": user_content},
{"role": "assistant", "content": assistant_content}]
}
jsonl_file.write(json.dumps(jsonl_entry) + '\n')
As shown above, we can iterate through the dataframe to create the jsonl file.
Fine-tuning in OpenAI Platform
Now, we can use ‘messages_dataset.jsonl’ to fine-tune OpenAI LLMs.
Go to the website and sign in if not signed in already.
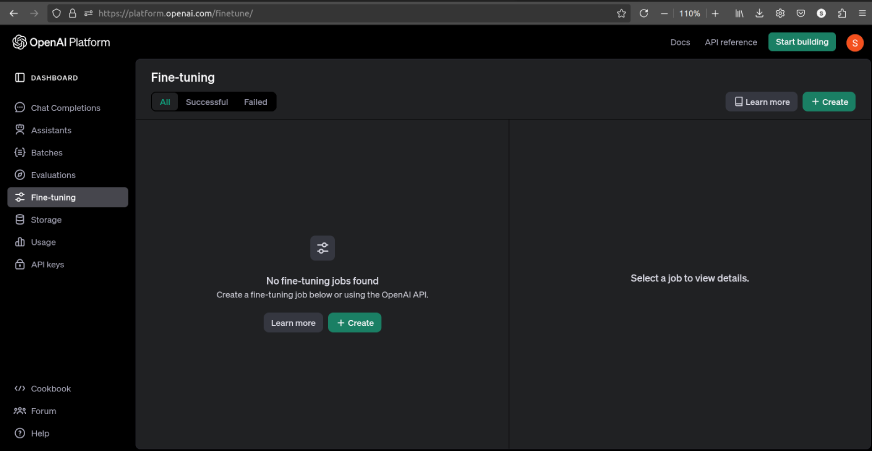
If there aren’t any fine-tuning jobs, the interface will be as follows:
We can click on ‘Learn more’ to learn all the details needed for fine-tuning, including the tuneable hyper-parameters.
Now let’s learn how to fine-tune a model on OpenAI Platform.
- Click on ‘Create’. A small window will open.
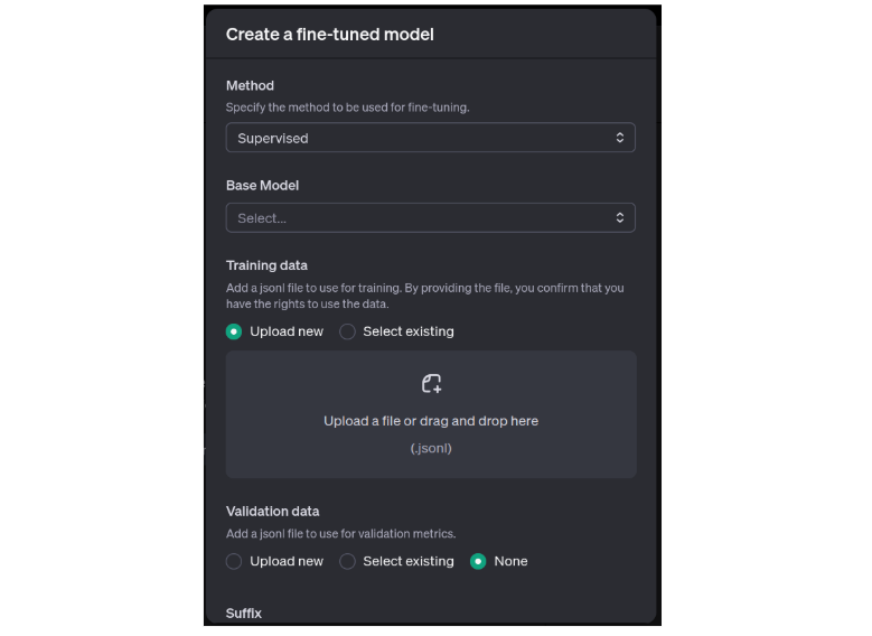
- Select the method as ‘Supervised’
- Select the Base Model as either ‘gpt-4o’ or ‘gpt-4o-mini’. I got an error while using gpt-4o-mini so I have used gpt-4o.
- Upload the jsonl file.
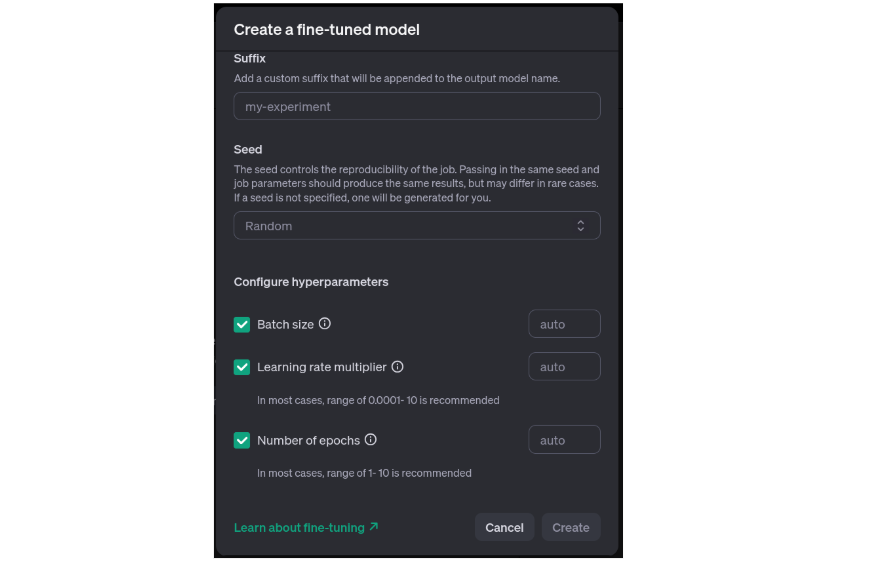
- Add ‘Suffix’ which is relevant to the fine-tuning job
- Use any number as ‘Seed’ for reproducibility.
- Choose the hyper-parameters and leave them to use the default values. Refer to the above-mentioned documentation for guidelines on choosing them.
Now, we can click on ‘Create’ to start the fine-tuning.
Once the fine tuning is completed, it will be displayed as follows:
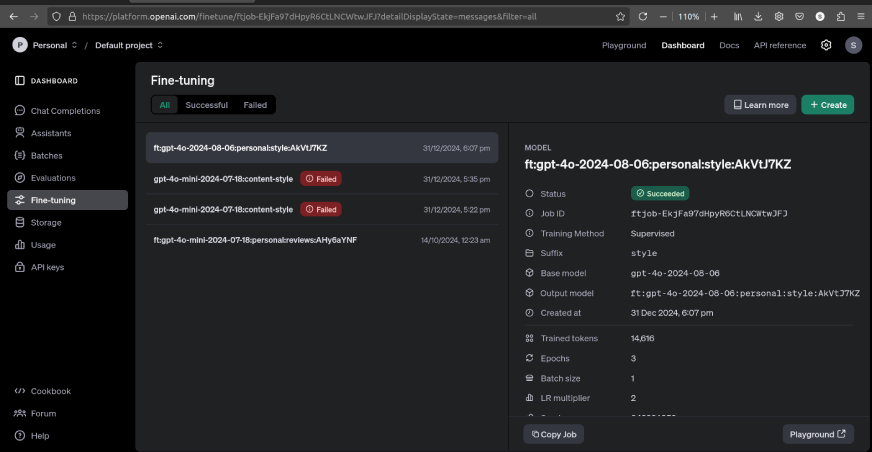
We can compare the fine-tuned model to pre-existing model responses in the playground by clicking the button at the right-bottom corner.
Here’s an example of responses comparing both models:
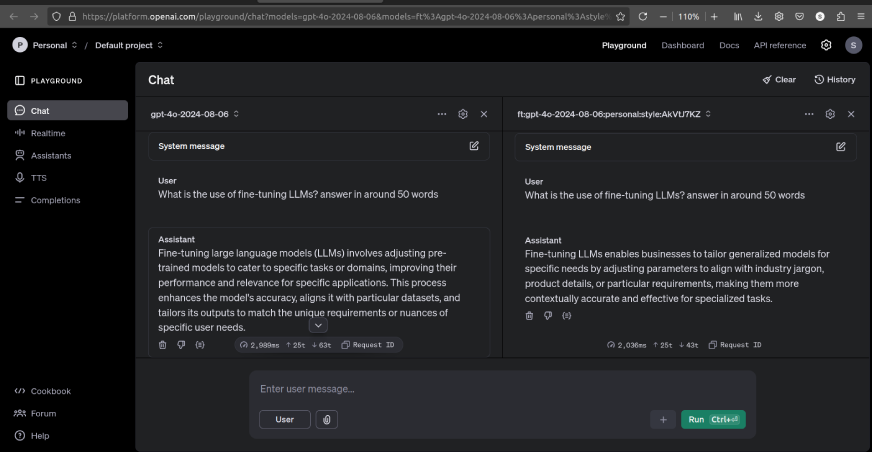
As we can see, there is significant difference between the responses of both models.
If we use more examples, then the results could improve.
Now let’s learn about Google AI Studio.
Google AI Studio
Google AI Studio is a web-based tool for building applications using Gemini LLMs. It also allows users to fine-tune LLMs using their own data. This customization enhances the model’s performance for specific tasks or industries, making it more relevant and effective. Fine-tuning feature for Gemini models is newly launched and currently available for Gemini 1.5 Flash only. The tuning is free of charge as of January 2025 and the cost of inference is the same as pre-existing models.
Learn More: Google’s AI Studio: Your Gateway to Gemini’s Creative Universe!
Data Upload
For Gemini models, the data format should be as follows:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},]
Google AI Studio provides a GUI (Graphical User Interface) to upload the data from a csv file. To do this:
- Open https://aistudio.google.com/prompts/new_data
- Click on ‘Actions’, then ‘Import examples’.
- Then upload the csv file. The screen will look like this:
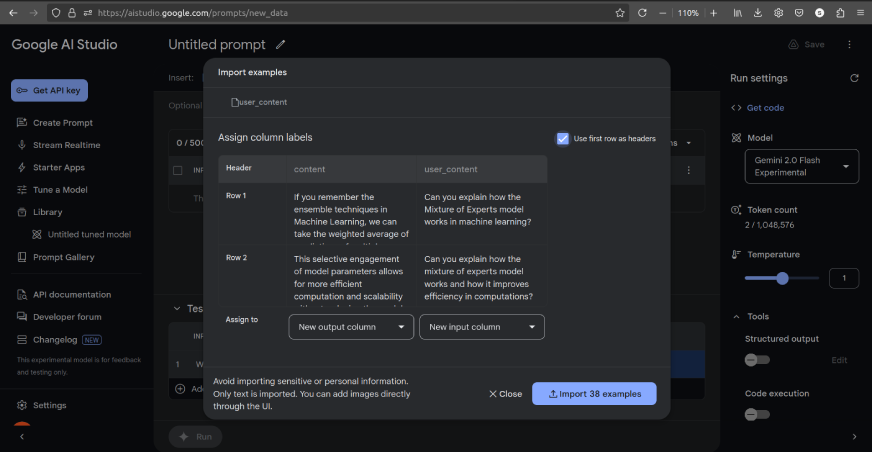
- Assign user_content as input column and content as output column.
- Then, import the examples. We can delete any unnecessary columns and then save the data using the ‘Save’ button in the top-right corner.
Fine-tuning in AI Studio
To fine-tune a model, go to https://aistudio.google.com/tune.
The screen will look like this:
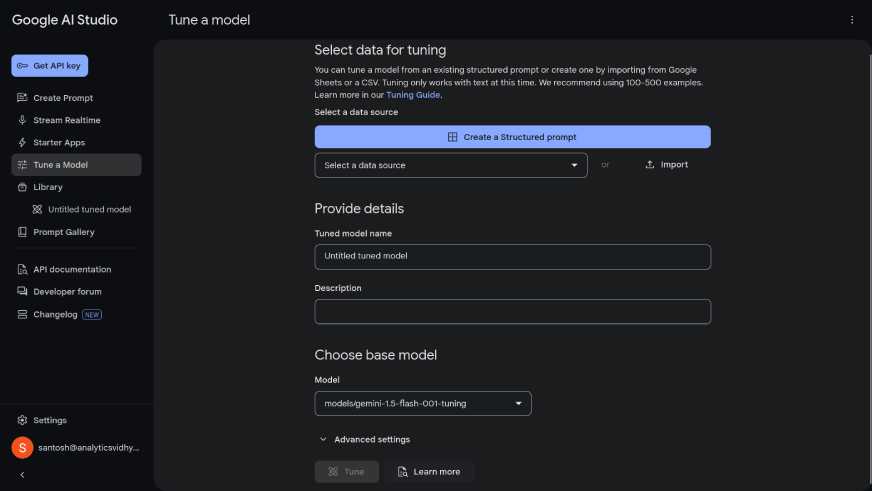
Now, follow the below steps:
- Select the imported data from the dropdown menu.
- Give the tuned model a name.
- To learn more about advanced settings, refer to https://ai.google.dev/gemini-api/docs/model-tuning.
- Once done, click on ‘Tune’.
You can find the tuned models in the ‘Library’ as follows:
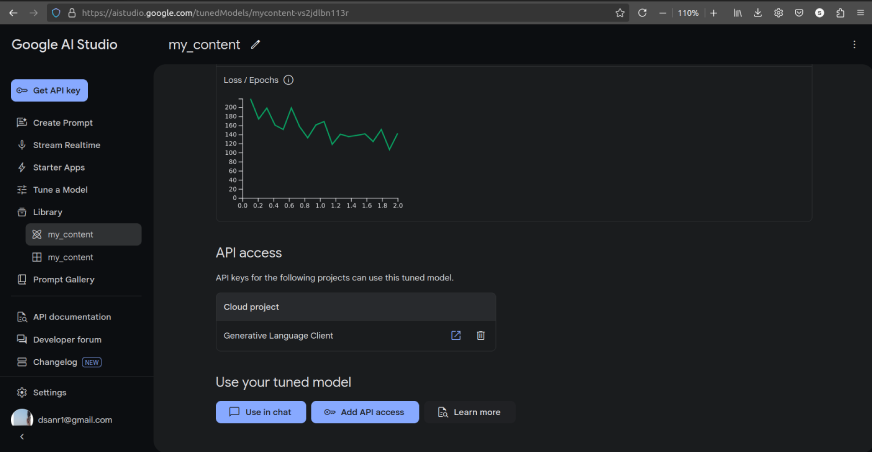
We can also use the model in the chat as shown in the above image.
Conclusion
Fine-tuning large language models using OpenAI Platform and Google AI Studio enables users to tailor models to specific needs. This could be to make the LLM adopt unique writing styles or improve its domain-specific performance. Both platforms provide intuitive workflows for data preparation and training, supporting structured formats to optimize model behavior. With accessible tools and clear documentation, they empower users to unlock the full potential of LLMs by aligning them closely with desired tasks and objectives.
Frequently Asked Questions
Q1. What is fine-tuning in the context of large language models (LLMs)?
A. Fine-tuning is the process of training a pre-trained language model on custom data to adapt its behaviour to specific tasks, styles, or domains. It involves providing examples of input-output pairs to guide the model’s responses in alignment with user requirements.
Q2. What data format is required for fine-tuning in OpenAI Platform and Google AI Studio?
A. OpenAI Platform requires data in a structured JSONL format, typically with roles such as “system,” “user,” and “assistant.” Google AI Studio uses a simpler format with `text_input` and `output` fields, where the input and desired output are clearly defined.
Q3. How much data is needed for effective fine-tuning?
A. While small datasets with 30–50 examples may show some results, larger datasets with 100–500 examples generally yield better performance by providing the model with diverse and context-rich scenarios.
Q4. How do the costs of fine-tuning compare between OpenAI Platform and Google AI Studio?
A. OpenAI charges for fine-tuning based on token usage during training, with higher costs for larger models. Google AI Studio currently offers free fine-tuning for Gemini 1.5 Flash models, making it a cost-effective choice for experimentation.
Q5. What are the key benefits of fine-tuning an LLM?
A. Fine-tuning allows users to customize a model to align with specific requirements, such as generating content in a particular tone or style, improving accuracy for domain-specific tasks, and enhancing the overall user experience by making the model more relevant to the intended use case.
I am working as an Associate Data Scientist at Analytics Vidhya, a platform dedicated to building the Data Science ecosystem. My interests lie in the fields of Natural Language Processing (NLP), Deep Learning, and AI Agents.





