YOLO models have made significant contributions to computer vision in various applications, such as object detection, segmentation, pose estimation, vehicle speed detection, and multimodal tasks. While understanding their applications is crucial, it’s equally important to know how these models are built and how they work. This article will focus on that aspect.
In this article, we will be building the latest object detection model, Yolov11 from scratch in Pytorch. If you are new to YOLOv11, I would strongly recommend reading A Comprehensive Guide to YOLOv11 Object Detection.
Learning Objectives
- Understand the architecture and key components of YOLOv11 for advanced object detection.
- Learn how YOLOv11 handles multi-task learning for object detection, segmentation, and classification.
- Explore the role of YOLOv11’s backbone and neck in enhancing model performance.
- Examine the practical applications of YOLOv11 in real-world AI projects.
- Discover how YOLOv11 optimizes efficiency for deployment in both edge and cloud environments.
This article was published as a part of the Data Science Blogathon.
Table of contents
- What are YOLO Models?
- Diving into YOLOv11 Architecture
- YOLO Model Capabilities
- Exploring YOLOv11 Capabilities
- Core Components of YOLOv11: Convolution and Bottleneck Layers
- Spatial Pyramid Pooling and Fusion (SPPF) Layer
- Neural Network Neck: Feature Fusion and Transition Layer
- Code for Attention Module
- Code for PSAModule
- Code for C2PSA
- Understanding The Head
- Yolo Model Versions
- Complete YOLOv11 Model: Backbone, Neck and Head
- Analysis of Model
- What’s Next?
What are YOLO Models?
YOLO (You Only Look Once) models are known for their efficiency and reliability in object detection tasks. They offer a great balance of small model sizes, high accuracy, and impressive mean Average Precision (mAP) scores. The architecture of YOLO models plays a key role in their success, with optimized pipelines for real-time detection and minimal computational overhead. Over time, various YOLO versions have been released, each introducing innovations to improve performance, reduce latency, and expand application areas.
The YOLO family has evolved significantly from its original version, with each iteration—YOLOv2, YOLOv3, and beyond—offering improvements in detection accuracy, speed, and feature extraction. Versions like YOLOv4 and YOLOv5 introduced architectural advancements, including CSPNet and mosaic augmentation, enhancing performance. The later models, YOLOv6 to YOLOv8, focused on creating lightweight architectures ideal for edge device deployment while maintaining high performance. YOLOv11, however, takes a different approach, focusing more on practical applications than traditional research, with Ultralytics emphasizing real-world solutions over academic documentation, signaling a shift towards application-driven development.
Ultralytics has not published a formal research paper for YOLO11 due to the rapidly evolving nature of the models. We focus on advancing the technology and making it easier to use, rather than producing static documentation. Source
The accompanying table provides a comprehensive overview of the various YOLO versions, mapping their parameters to corresponding mAP scores, offering valuable insights into their comparative performance.
| Model | Size (pixels) | mAPval | Speed (CPU ONNX) | Speed (T4 TensorRT10) | Params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv11n | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| YOLOv11s | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| YOLOv11m | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
| YOLOv11 | 640 | 53.4 | 238.6 ± 1.4 | 6.2 ± 0.1 | 25.3 | 86.9 |
| YOLOv11x | 640 | 54.7 | 462.8 ± 6.7 | 11.3 ± 0.2 | 56.9 | 194.9 |
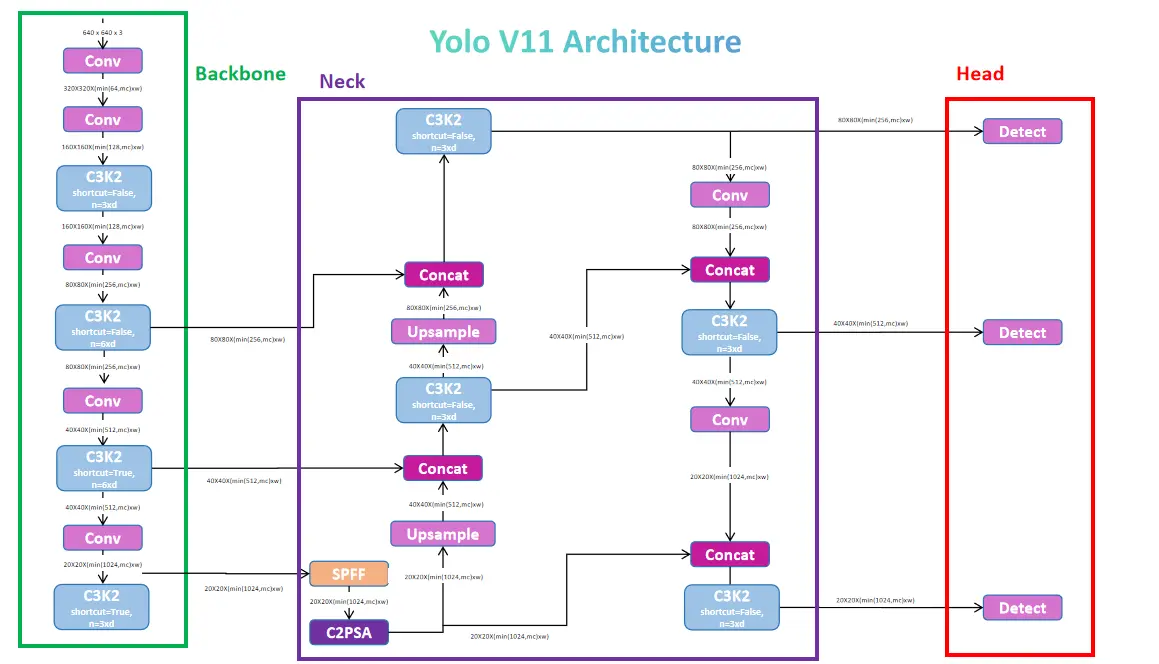
Diving into YOLOv11 Architecture
The YOLO models have a 3-section architecture: backbone, neck, and head. The backbone extracts useful features from the image using efficient bottleneck-based blocks. The neck processes the output from the backbone and passes the features to the head. The head defines the task of the model, with options like object detection, semantic segmentation, keypoint detection, image classification, and oriented object detection. This section also uses convolution blocks, but they are task-specific, which we will discuss in detail later.
YOLO Model Capabilities
Below we will look into some most common YOLO model capabilities:
- Object Detection: Identifying and locating objects within an image.

- Image Segmentation: Detecting objects and delineating their boundaries.

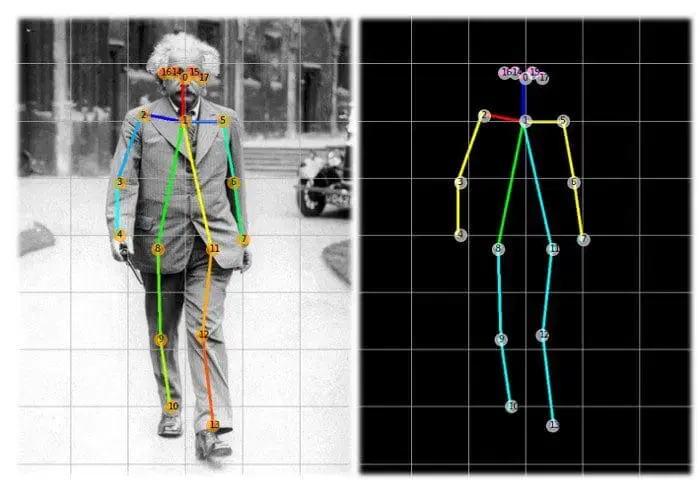
- Pose Estimation: Detecting and tracking keypoints on human bodies.
- Image Classification: Categorizing images into predefined classes.
- Oriented Object Detection (OBB): Detecting objects with rotation for higher precision.

Exploring YOLOv11 Capabilities
The term backbone is usually specified for the part where the behind-the-scenes works are done. That’s what is happening in the Yolo models too. The main task of any model is to extract useful features while considering parameters and speed. The YoloV11 model uses the DarkNet and DarkFPN backbone, which is used to extract features. To get a better understanding, assume the DarkNet model is similar to a CNN model which is generally used for classification or other tasks, but by removing the last layers of the model which help generate the outputs, we modify the architecture in such a way that, it will be useful for feature extraction.
The backbone in the YOLO model is used to extract 3 levels of different features. High-level features that are useful for extracting information on detection features, semantic features, facial attributes, etc. Medium-level features help extract information on shapes, contours, ROIs, and patterns. Low-level features are useful for detecting edges, shapes, textures, and gradients. The backbone model includes a series of convolutional and bottleneck blocks, along with a hybrid block called C2K3, which combines both types of blocks.
Core Components of YOLOv11: Convolution and Bottleneck Layers
Below we will understand the two most important layer:
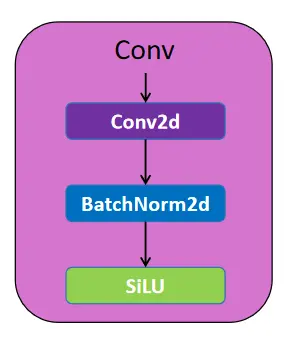
Convolution Layer
A convolutional layer is a component of a convolutional neural network (CNN) that extracts features from images. A batch normalization layer independently normalizes a mini-batch of data across all observations for each channel. The Convolution Block consists of a convolutional layer and a Batch Normalization layer before passing it to the SiLU activation function.
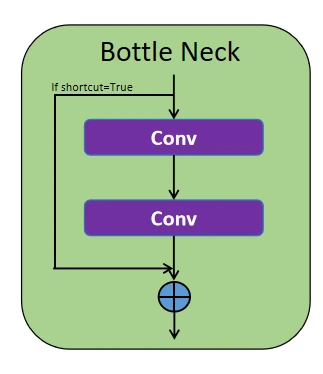
BottleNeck Layer
This block contains two convolution blocks in series with a concatenation function. If the shortcut parameter is true, the input is concatenated with the output from the second convolution block. If false, only the output from the second block is passed through. This structure is mainly used in blocks like C3K2 and SPFF, enhancing efficiency and improving learning.
Code Blocks
These are the utils codes :
# The autopad is used to detect the padding value for the Convolution layer
def autopad(k, p=None, d=1):
if d > 1:
# actual kernel-size
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
# auto-pad
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
# This is the activation function used in YOLOv11
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)Convolution Block (Con)
# The base Conv Block
class Conv(torch.nn.Module):
def __init__(self, in_ch, out_ch, activation, k=1, s=1, p=0, g=1):
# in_ch = input channels
# out_ch = output channels
# activation = the torch function of the activation function (SiLU or Identity)
# k = kernel size
# s = stride
# p = padding
# g = groups
super().__init__()
self.conv = torch.nn.Conv2d(in_ch, out_ch, k, s, p, groups=g, bias=False)
self.norm = torch.nn.BatchNorm2d(out_ch, eps=0.001, momentum=0.03)
self.relu = activation
def forward(self, x):
# Passing the input by convolution layer and using the activation function
# on the normalized output
return self.relu(self.norm(self.conv(x)))
def fuse_forward(self, x):
return self.relu(self.conv(x))Bottleneck Block
# The Bottlneck block
class Residual(torch.nn.Module):
def __init__(self, ch, e=0.5):
super().__init__()
self.conv1 = Conv(ch, int(ch * e), torch.nn.SiLU(), k=3, p=1)
self.conv2 = Conv(int(ch * e), ch, torch.nn.SiLU(), k=3, p=1)
def forward(self, x):
# The input is passed through 2 Conv blocks and if the shortcut is true and
# if input and output channels are same, then it will the input as residual
return x + self.conv2(self.conv1(x))
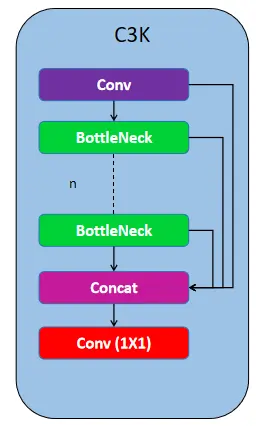
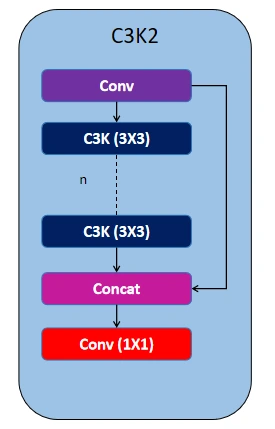
Now we you have got a brief understanding of the basic blocks, let’s dive into the architecture of the backbone. YOLOv11 uses C3K2 blocks to handle feature extraction at different stages of the backbone. The C3K2 block uses small-size kernels for efficient capturing of features. This block is an update over the previous existing block C2F which is used in Yolov8.
C3K Module
# The C3k Module
class C3K(torch.nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv1 = Conv(in_ch, out_ch // 2, torch.nn.SiLU())
self.conv2 = Conv(in_ch, out_ch // 2, torch.nn.SiLU())
self.conv3 = Conv(2 * (out_ch // 2), out_ch, torch.nn.SiLU())
self.res_m = torch.nn.Sequential(Residual(out_ch // 2, e=1.0),
Residual(out_ch // 2, e=1.0))
def forward(self, x):
y = self.res_m(self.conv1(x)) # Process half of the input channels
# Process the other half directly, Concatenate along the channel dimension
return self.conv3(torch.cat((y, self.conv2(x)), dim=1))
The C3K block consists of a Conv block followed by a series of bottleneck layers, with each layer’s features concatenated before passing through the final 1×1 Conv layer. In the C3K2 block, a Conv block is used first, followed by a series of C3K blocks, and then passed to the 1×1 Conv block. This structure makes feature extraction more efficient compared to the previous C2F block used in YOLOv8.
C3K2 Block Code
# The C3K2 Module
class C3K2(torch.nn.Module):
def __init__(self, in_ch, out_ch, n, csp, r):
super().__init__()
self.conv1 = Conv(in_ch, 2 * (out_ch // r), torch.nn.SiLU())
self.conv2 = Conv((2 + n) * (out_ch // r), out_ch, torch.nn.SiLU())
if not csp:
# Using the CSP Module when mentioned True at shortcut
self.res_m = torch.nn.ModuleList(Residual(out_ch // r) for _ in range(n))
else:
# Using the Bottlenecks when mentioned False at shortcut
self.res_m = torch.nn.ModuleList(C3K(out_ch // r, out_ch // r) for _ in range(n))
def forward(self, x):
y = list(self.conv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.res_m)
return self.conv2(torch.cat(y, dim=1))
The backbone model architecture start with a Conv Block for the given image input of size 640 and 3 channels and then continues with 4 sets of Conv Block with C3K2 Block. Then finally use a Spatial Pyramid Pooling Fast (SPFF) Block.
Spatial Pyramid Pooling and Fusion (SPPF) Layer
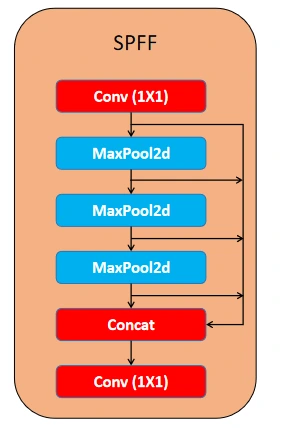
SPPF module (Spatial Pyramid Pooling Fast), which was designed to pool features from different regions of an image at varying scales. This improves the network’s ability to capture objects of different sizes, especially small objects. It pools features using multiple max-pooling operations. The block contains a 1X1 Conv Block followed by a series of MaxPool2D Layers with a concat block using all the residuals from the Maxpool2D layers, and then ending with a 1X1 Conv Block.
We extract three outputs (feature maps) from the backbone, corresponding to different levels of granularity in the image. This approach helps detect small objects in finer detail (P5) and larger objects through higher-level features (P3). Low-level features come from the 2nd set of Conv Block and C3K2 Block. Medium-level features are from the 3rd set, while higher-level features come from the 4th set. Therefore, for a given input image, the backbone produces three outputs: P3, P4, and P5 in a list.
Code Block for SPPF
# Code for SPFF Block
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x) # Starting with a Conv Block
y1 = self.m(x) # First MaxPool layer
y2 = self.m(y1) # Second MaxPool layer
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1)) # Ending with Conv BlockNeural Network Neck: Feature Fusion and Transition Layer
Below section is a continuous series of blocks used to process the extracted features from the block. Before diving into the neck section, YOLOv11 also uses the C2PSA block. This block helps process low-level objects by utilizing the attention mechanism.
C2PSA
C2PSA refers to a Conv Block that uses two Partial Spatial Attention (PSA) blocks. The PSA block combines Attention, Conv, and FFNs to focus on the important objects in the feature map given to it, and the modified version of PSA is C2PSA. This block starts with a 1×1 Conv Block, then splits the feature map in half, sequentially applying two PSA blocks. A concat block adds the output of the second PSA block to the unprocessed split, and the block ends with another 1×1 Conv block. This architecture helps to process the feature maps in separate branches, and later concatenate. This ensures the model focuses on information, computational cost and accuracy simultaneously.
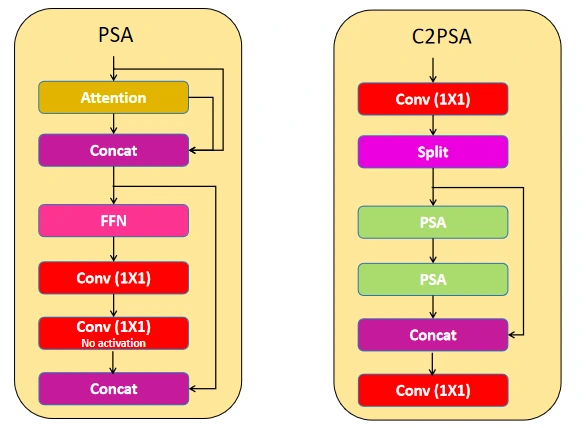
Code for Attention Module
The code defines an Attention module that uses multi-head attention. It initializes components like query, key, and value (QKV) layers and processes input through convolution layers. In the forward method, the input is split into queries, keys, and values, and attention scores are computed. The output is a weighted sum of the values, refined through additional convolution layers, enhancing feature representation and capturing spatial dependencies.
# Code for the Attention Module
class Attention(torch.nn.Module):
def __init__(self, ch, num_head):
super().__init__()
self.num_head = num_head
self.dim_head = ch // num_head
self.dim_key = self.dim_head // 2
self.scale = self.dim_key ** -0.5
self.qkv = Conv(ch, ch + self.dim_key * num_head * 2, torch.nn.Identity())
self.conv1 = Conv(ch, ch, torch.nn.Identity(), k=3, p=1, g=ch)
self.conv2 = Conv(ch, ch, torch.nn.Identity())
def forward(self, x):
b, c, h, w = x.shape
qkv = self.qkv(x)
qkv = qkv.view(b, self.num_head, self.dim_key * 2 + self.dim_head, h * w)
q, k, v = qkv.split([self.dim_key, self.dim_key, self.dim_head], dim=2)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(b, c, h, w) + self.conv1(v.reshape(b, c, h, w))
return self.conv2(x)Code for PSAModule
The PSABlock module combines attention and convolutional layers to enhance feature representation. It first applies an attention module to capture dependencies, then processes the output through two convolution blocks. The final output combines the original input and the processed features, enhancing information flow and learning.
# Code for the PSAModule
class PSABlock(torch.nn.Module):
# This Module has a sequential of one Attention module and 2 Conv Blocks
def __init__(self, ch, num_head):
super().__init__()
self.conv1 = Attention(ch, num_head)
self.conv2 = torch.nn.Sequential(Conv(ch, ch * 2, torch.nn.SiLU()),
Conv(ch * 2, ch, torch.nn.Identity()))
def forward(self, x):
x = x + self.conv1(x)
return x + self.conv2(x)
Code for C2PSA
Coming back to the neck part, it is also a part of the features extraction and this mainly focuses on features processing. The neck part processes the three levels of features, each with different channel sizes. To tackle this, the model adjusts all the channels to the same number and then extracts them using intermediate layers. Let’s go in the detail.
Implementation
# PSA Block Code
class PSA(torch.nn.Module):
def __init__(self, ch, n):
super().__init__()
self.conv1 = Conv(ch, 2 * (ch // 2), torch.nn.SiLU())
self.conv2 = Conv(2 * (ch // 2), ch, torch.nn.SiLU())
self.res_m = torch.nn.Sequential(*(PSABlock(ch // 2, ch // 128) for _ in range(n)))
def forward(self, x):
# Passing the input to the Conv Block and splitting into two feature maps
x, y = self.conv1(x).chunk(2, 1)
# 'n' number of PSABlocks are made sequential, and then passes one them (y) of
# the feature maps and concatenate with the remaining feature map (x)
return self.conv2(torch.cat(tensors=(x, self.res_m(y)), dim=1))
The low-level features (P5) are of shape 20X20X1024, the medium-level features (P4) are of shape 40X40X512 and the high-level features (P5) are of shape 80X80X256. We first pass the low-level features (output of SPFF) to C2PSA, which outputs attention-based features focused on spatial information. We then upsample the output to the shape of P4 and concatenate it with P4 features. Next, we upsample the combined features to the shape of P3 and concatenate them with P3 features. This process upscales and concatenates all the features. Finally, we send the features to the C3K2 block to process them better using the Bottlenecks.
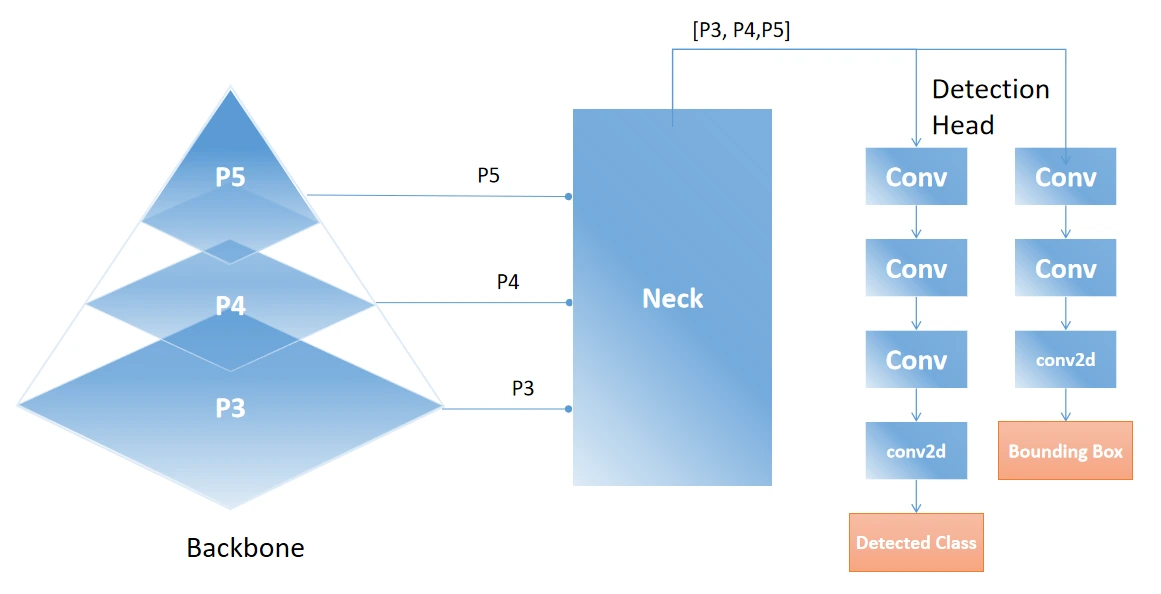
We name the output of the C3K2 block as feat1, which represents the high-level features that will be sent to the head section. We downsample feat1, concatenate it with P4, and send it to the C3K2 block. The output, feat2, consists of the medium-level features that will be sent to the head section. We repeat the same process with the low-level features, concatenate them with P5 (output of C2PSA), and send them to the C3K2 block. The output, feat3, represents the low-level features sent to the head section.
We will code the neck part at last including the head part.
The head section will have a list of 3 outputs containing feat1, feat2, and feat3. Let’s explore the Head section and see how the three features are used for tasks like Object Detection, Segmentation, and Keypoint Detection.
Understanding The Head
YOLO model uses three task heads: the Detection Head, Segmentation Head, and Keypoint Detection Head.
The main head is the Detection Head, which uses three features for DFL (Focal Loss), Box Detection, and Class Detection. The DFL block calculates the focal loss, while the Box Detection consists of sequential convolution layers that output a shape of 4, representing the coordinates of the box. Class Detection also uses sequential layers of the convolutional layer to process the features using the SiLU activation function and output of a single class and later passed with the sigmoid function to get a one-hot encoding output.
DFL Function Code
class DFL(nn.Module):
# Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, c, a = x.shape
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
The segmentation and key point detection used this Detection block as their parent class and processed their output according to their shapes, segmentation outputs the shape equal to the image shape and the key point detection outputs the shape of [17,3] or [17,2] based on the requirement. The key points are generally 17 key points for the person 2 are the x and y coordinated 17 are the locations in the person, 3 are the x and y coordinated and another variable indicating it is for the visibility of key point purposes.
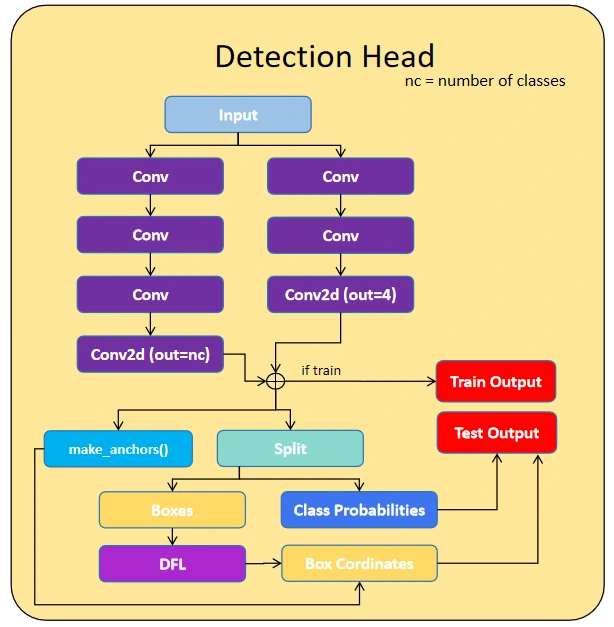
Yolo Model Versions
We know that there are 5 versions of the YOLO model, i.e., nano (n), small (s), medium (m), large (l), and extra large (x). The main difference between these versions is the sizes of the feature maps they process. The feature map shapes can determined using the backbone output shapes, for the nano versions the output feature map shapes are 40x40x64, 20x20x128 and 20x20x256, for the small version we get the shapes, 40x40x128, 20x20x256 and 20x20x512.
We need to achieve the dynamic channel setting, to get this problem solved we set depth and width while defining the model and also mention when to use the C3K Modules to be used in the C3K2 block as a list of boolean values. These three inputs to the main model function can make 5 versions of the YOLO model from nano to extra large. The depth is used in the backbone to repeat the number of C3K modules and the width represents the image resolution.
Complete YOLOv11 Model: Backbone, Neck and Head
Let’s focus on the Object Detection task and Let’s Code the complete Yolo Model.
The Backbone
class DarkNet(torch.nn.Module):
def __init__(self, width, depth, csp):
super().__init__()
self.p1 = []
self.p2 = []
self.p3 = []
self.p4 = []
self.p5 = []
# p1/2
self.p1.append(Conv(width[0], width[1], torch.nn.SiLU(), k=3, s=2, p=1))
# p2/4
self.p2.append(Conv(width[1], width[2], torch.nn.SiLU(), k=3, s=2, p=1))
self.p2.append(CSP(width[2], width[3], depth[0], csp[0], r=4))
# p3/8
self.p3.append(Conv(width[3], width[3], torch.nn.SiLU(), k=3, s=2, p=1))
self.p3.append(CSP(width[3], width[4], depth[1], csp[0], r=4))
# p4/16
self.p4.append(Conv(width[4], width[4], torch.nn.SiLU(), k=3, s=2, p=1))
self.p4.append(CSP(width[4], width[4], depth[2], csp[1], r=2))
# p5/32
self.p5.append(Conv(width[4], width[5], torch.nn.SiLU(), k=3, s=2, p=1))
self.p5.append(CSP(width[5], width[5], depth[3], csp[1], r=2))
self.p5.append(SPP(width[5], width[5]))
self.p5.append(PSA(width[5], depth[4]))
self.p1 = torch.nn.Sequential(*self.p1)
self.p2 = torch.nn.Sequential(*self.p2)
self.p3 = torch.nn.Sequential(*self.p3)
self.p4 = torch.nn.Sequential(*self.p4)
self.p5 = torch.nn.Sequential(*self.p5)
def forward(self, x):
p1 = self.p1(x)
p2 = self.p2(p1)
p3 = self.p3(p2)
p4 = self.p4(p3)
p5 = self.p5(p4)
return p3, p4, p5
The Neck
class DarkFPN(torch.nn.Module):
def __init__(self, width, depth, csp):
super().__init__()
self.up = torch.nn.Upsample(scale_factor=2)
self.h1 = CSP(width[4] + width[5], width[4], depth[5], csp[0], r=2)
self.h2 = CSP(width[4] + width[4], width[3], depth[5], csp[0], r=2)
self.h3 = Conv(width[3], width[3], torch.nn.SiLU(), k=3, s=2, p=1)
self.h4 = CSP(width[3] + width[4], width[4], depth[5], csp[0], r=2)
self.h5 = Conv(width[4], width[4], torch.nn.SiLU(), k=3, s=2, p=1)
self.h6 = CSP(width[4] + width[5], width[5], depth[5], csp[1], r=2)
def forward(self, x):
p3, p4, p5 = x
p4 = self.h1(torch.cat(tensors=[self.up(p5), p4], dim=1))
p3 = self.h2(torch.cat(tensors=[self.up(p4), p3], dim=1))
p4 = self.h4(torch.cat(tensors=[self.h3(p3), p4], dim=1))
p5 = self.h6(torch.cat(tensors=[self.h5(p4), p5], dim=1))
return p3, p4, p5
The Head
The make_anchors function generates anchor points and their corresponding strides for object detection. It processes feature maps at different scales, creating a grid of anchor coordinates (centre points) with an optional offset for alignment. The function outputs tensors of anchor points and strides, which are crucial for defining regions in object detection tasks where bounding boxes are predicted.
def make_anchors(x, strides, offset=0.5):
assert x is not None
anchor_tensor, stride_tensor = [], []
dtype, device = x[0].dtype, x[0].device
for i, stride in enumerate(strides):
_, _, h, w = x[i].shape
sx = torch.arange(end=w, device=device, dtype=dtype) + offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + offset # shift y
sy, sx = torch.meshgrid(sy, sx)
anchor_tensor.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_tensor), torch.cat(stride_tensor)
The fuse_conv function merges a convolution layer (conv) and a normalization layer (norm) into a single convolution layer by adjusting its weights and biases. This is commonly used during model optimization for deployment, as it removes the need for separate normalization layers, improving inference speed and reducing memory usage without altering the model’s behaviour.
def fuse_conv(conv, norm):
fused_conv = torch.nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_norm = torch.diag(norm.weight.div(torch.sqrt(norm.eps + norm.running_var)))
fused_conv.weight.copy_(torch.mm(w_norm, w_conv).view(fused_conv.weight.size()))
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_norm = norm.bias - norm.weight.mul(norm.running_mean).div(torch.sqrt(norm.running_var + norm.eps))
fused_conv.bias.copy_(torch.mm(w_norm, b_conv.reshape(-1, 1)).reshape(-1) + b_norm)
return fused_convThe Object Detection Head
class Head(torch.nn.Module):
anchors = torch.empty(0)
strides = torch.empty(0)
def __init__(self, nc=80, filters=()):
super().__init__()
self.ch = 16 # DFL channels
self.nc = nc # number of classes
self.nl = len(filters) # number of detection layers
self.no = nc + self.ch * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
box = max(64, filters[0] // 4)
cls = max(80, filters[0], self.nc)
self.dfl = DFL(self.ch)
self.box = torch.nn.ModuleList(
torch.nn.Sequential(Conv(x, box,torch.nn.SiLU(), k=3, p=1),
Conv(box, box,torch.nn.SiLU(), k=3, p=1),
torch.nn.Conv2d(box, out_channels=4 * self.ch,kernel_size=1)) for x in filters)
self.cls = torch.nn.ModuleList(
torch.nn.Sequential(Conv(x, x, torch.nn.SiLU(), k=3, p=1, g=x),
Conv(x, cls, torch.nn.SiLU()),
Conv(cls, cls, torch.nn.SiLU(), k=3, p=1, g=cls),
Conv(cls, cls, torch.nn.SiLU()),
torch.nn.Conv2d(cls, out_channels=self.nc,kernel_size=1)) for x in filters)
def forward(self, x):
for i, (box, cls) in enumerate(zip(self.box, self.cls)):
x[i] = torch.cat(tensors=(box(x[i]), cls(x[i])), dim=1)
if self.training:
return x
self.anchors, self.strides = (i.transpose(0, 1) for i in make_anchors(x, self.stride))
x = torch.cat([i.view(x[0].shape[0], self.no, -1) for i in x], dim=2)
box, cls = x.split(split_size=(4 * self.ch, self.nc), dim=1)
a, b = self.dfl(box).chunk(2, 1)
a = self.anchors.unsqueeze(0) - a
b = self.anchors.unsqueeze(0) + b
box = torch.cat(tensors=((a + b) / 2, b - a), dim=1)
return torch.cat(tensors=(box * self.strides, cls.sigmoid()), dim=1)
Defining the YOLOv11 Model
class YOLO(torch.nn.Module):
def __init__(self, width, depth, csp, num_classes):
super().__init__()
self.net = DarkNet(width, depth, csp)
self.fpn = DarkFPN(width, depth, csp)
img_dummy = torch.zeros(1, width[0], 256, 256)
self.head = Head(num_classes, (width[3], width[4], width[5]))
self.head.stride = torch.tensor([256 / x.shape[-2] for x in self.forward(img_dummy)])
self.stride = self.head.stride
self.head.initialize_biases()
def forward(self, x):
x = self.net(x)
x = self.fpn(x)
return self.head(list(x))
def fuse(self):
for m in self.modules():
if type(m) is Conv and hasattr(m, 'norm'):
m.conv = fuse_conv(m.conv, m.norm)
m.forward = m.fuse_forward
delattr(m, 'norm')
return selfDefining Different Versions of YOLOv11 Models
class YOLOv11:
def __init__(self):
self.dynamic_weighting = {
'n':{'csp': [False, True], 'depth' : [1, 1, 1, 1, 1, 1], 'width' : [3, 16, 32, 64, 128, 256]},
's':{'csp': [False, True], 'depth' : [1, 1, 1, 1, 1, 1], 'width' : [3, 32, 64, 128, 256, 512]},
'm':{'csp': [True, True], 'depth' : [1, 1, 1, 1, 1, 1], 'width' : [3, 64, 128, 256, 512, 512]},
'l':{'csp': [True, True], 'depth' : [2, 2, 2, 2, 2, 2], 'width' : [3, 64, 128, 256, 512, 512]},
'x':{'csp': [True, True], 'depth' : [2, 2, 2, 2, 2, 2], 'width' : [3, 96, 192, 384, 768, 768]},
}
def build_model(self, version, num_classes):
csp = self.dynamic_weighting[version]['csp']
depth = self.dynamic_weighting[version]['depth']
width = self.dynamic_weighting[version]['width']
return YOLO(width, depth, csp, num_classes)Analysis of Model
Now that we have defined our model, we must check whether all the code blocks and the whole model architecture are correctly designed. To do this, we need to define the model, check for the model parameters, and cross-check with the official parameter count given. This method allows us to confirm that the model architecture is built correctly. To do this, we need to install a library named thop.
GFLOPS : (Giga Floating-Point Operations Per Second)
This metric measures a model’s computation performance, particularly in computer vision. It represents the number of floating-point operations performed per second. It is critical to check the use case and the relationship between the model and the respective hardware. A higher GFLOPS value typically indicates faster processing, enabling real-time performance and supporting complex models in applications such as autonomous vehicles and medical imaging.
Checking the GLOPS
We can use the profile function from thop library to check the GLOPS and parameters count. First, we need to define a random tensor of 3 channel image of size 640. The input tensor shape needs to be in the dimension of (batch size, number of channels, width, height). We declare this input store it in the dummy_input variable, and initialize the model of the nano version with 80 classes. Then we give the model, dummy_input to the profile function and it returns the FLOPS and Parameters. Then we print the FLOPS in Giga forms, representing it as GLOPS and the parameter count of the model. Through this process, we determine the GLOPS and Parameter count using the thop library.
!pip install thop
from thop.profile import profile
dummy_input = torch.randn(1, 3, 640, 640)
model = YOLOv11().build_model(version='n', num_classes=80)
flops, params = profile(model, (dummy_input,), verbose=False)
print(f"Params: {params / 1e6:.3f}M")
print(f"GFLOPs: {flops / 1e9:.3f}")
These are the model parameters that we have got and they match with the official parameters count given by the Ultralytics, Hence our model building is correct! Source
Model Architecture
To analyze the model architecture and determine, indicating each layer and its output shape of the feature map, we use the torchinfo library to show the model architecture with parameters count. This is known as model summary, also we will be going to import the function named summary from the torchinfo. This function takes input from the model and also the input_data to showcase the model summary, and input_data is optional. Here is the code to print the model summary using the torchinfo library.
!pip install torchinfo
import torch
from torchinfo import summary
# Knowing the device in which the current env is running
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Creating input tensor and moving it to the device
dummy_input = torch.randn(1, 3, 640, 640).to(device)
# Creating the model and moving it to the device
model = YOLOv11().build_model(version='n', num_classes=80).to(device)
# Now run the summary function from torchinfo
summary(model, input_data=dummy_input)
The output you get for the nano version
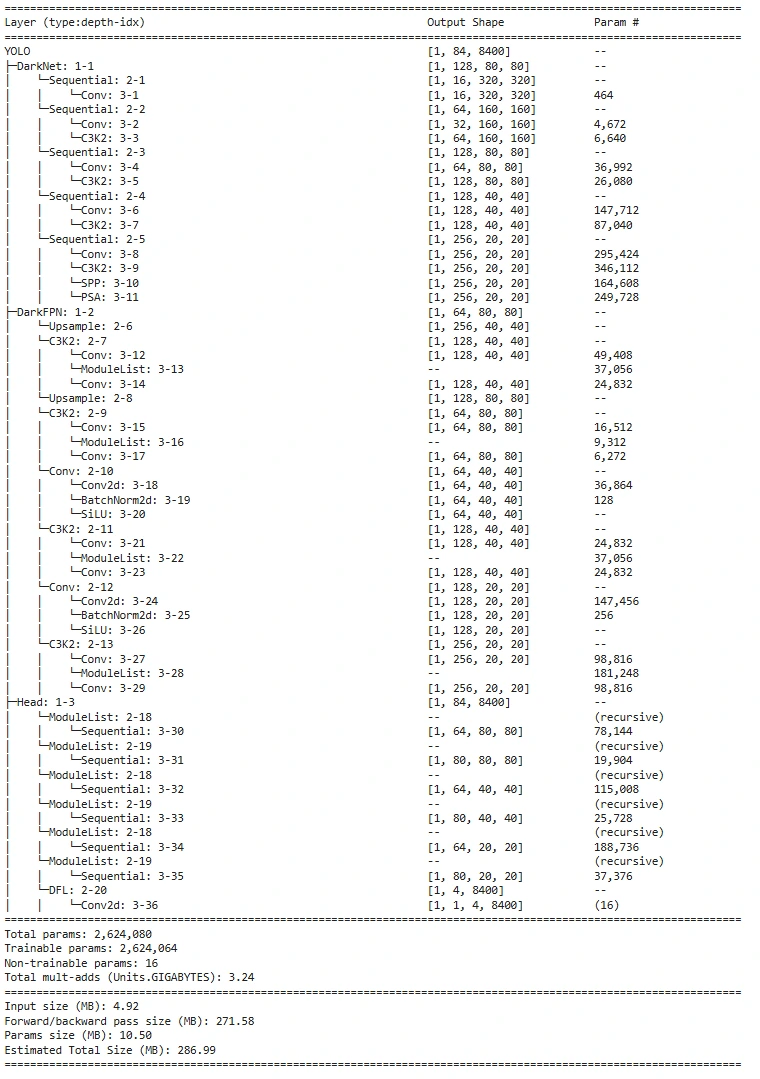
Yeah! You’ve learned how to build a model from scratch by understanding its basics. However, the work of a real computer vision engineer is far from over. The next step is writing the train and test code for datasets in COCO or YOLO format. For those interested in testing the model, let’s dive into how to print the output for a random tensor.
Testing the Model with random input tensor
Instead of taking a meaningful image, let’s use a random torch tensor for experimental and understanding purposes. We give the tensor’s model input and then examine the model output.
# the dummy input of random values
dummy_input = torch.randn(1, 3, 640, 640)
# defining the model of nano version
model = YOLOv11().build_model(version='n', num_classes=80)
# lets print the output
output = model(dummy_input)
print(f"Type of the output :{type(output)}, Length of the output: {len(output)}")
print(f"The shapes each output feature map : {output[0].shape, output[2].shape, output[2].shape}")
By this code, you see that the output from the model isn’t the expected bounding box and class, but instead, we are getting the three pyramid feature maps output. Because the model is defaulted in train mode, these feature maps will be the output when the model is in train mode. Let’s see what is the output in eval mode.
# Move the model to eval model
model.eval()
eval_output = model(dummy_input)
# Let' see what are the outputs
print(f"Output shape: {eval_output.shape}")
# Expected outcome : torch.Size([1, 84, 8400])The output here is a torch tensor of shape [1,84,8400]. Here 1 is the batch size of the input, and 84 is the number of outputs per anchor. It includes 4 values for the bounding box and 80 class probabilities and 8400 is the total number of anchors/predictions. From this, we will use a concept named Non-Maximum Suppression (NMS) which is a technique used in object detection to eliminate redundant bounding boxes for the same object. It works by ranking predictions based on their confidence scores and iteratively selecting the highest-scoring box while suppressing others with significant overlap beyond a predefined threshold. This ensures that only the most relevant and non-overlapping detections are retained, improving the clarity and precision of the output. We will get back to this concept in the next article.
What’s Next?
If you are thinking that we have built the model and know how to process the output too, then what’s next? The next task is related to dataset processing, training and validation data loader, training code and testing code with performance metrics calculation. All topics will be completely covered in the upcoming article, so stay tuned on Analytics Vidhya.
Conclusion
YOLOv11 continues the legacy of the YOLO family by introducing an optimized architecture that balances accuracy, speed, and efficiency. With its advanced backbone, neck, and head components, the model excels in tasks like object detection, segmentation, and pose estimation. Its practical, application-driven design makes it a powerful tool for real-world AI solutions, pushing the boundaries of deep learning-based detection models.
Key Takeaways
- YOLOv11 builds on previous YOLO versions with an enhanced backbone and feature extraction techniques.
- It supports multiple tasks, including object detection, segmentation, and classification.
- The model’s architecture emphasizes efficiency with C3K and C3K2 modules for improved feature learning.
- YOLOv11 prioritizes real-world applications over traditional research documentation.
- Its optimized design makes it suitable for deployment in edge and high-performance computing environments.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am Nikhileswara Rao Sulake, a DRDO and DIAT certified AI Professional from Andhra Pradesh. I am an AI practitioner working in the domain of Deep Learning and Computer Vision. I am proficient in ML, DL, CV, NLP and AR technologies. I am currently working on research papers on Deep Learning and Computer Vision.





