Today, computer vision applications are playing a transformative role in industries like healthcare, manufacturing, security, and retail. However, developing and deploying vision-based solutions has often been complex and time-consuming. VisionAgent, developed by the LandingAI team/Andrew Ng, is a generative Visual AI application builder designed to streamline the creation, iteration, and deployment of computer vision applications.
With Agentic Object Detection, VisionAgent eliminates the need for time-consuming data labeling and model training while outperforming traditional object detection systems. Its text prompt-based detection enables rapid prototyping and deployment, leveraging advanced reasoning capabilities for high-quality outputs and versatile recognition of complex objects and scenarios.
Key features include:
- Text prompt-based detection – No need for labeling or training
- Advanced reasoning for accurate and high-quality results
- Versatile recognition of complex objects and scenarios
VisionAgent goes beyond simple code generation, it acts as an AI-driven pilot that assists developers in planning, selecting tools, generating code, and deploying vision-based solutions efficiently. By leveraging advanced AI capabilities, developers can iterate on tasks within minutes instead of spending weeks fine-tuning solutions.
Table of contents
VisionAgent Ecosystem

VisionAgent consists of three core components that work together to provide a seamless development experience:
Understanding how these components interact is key to harnessing the full potential of VisionAgent.
1. VisionAgent Web App

The VisionAgent Web App is an intuitive, hosted platform that allows developers to prototype, refine, and deploy vision applications without requiring extensive setup. Designed for ease of use, this web-based interface enables users to:
- Upload and process data effortlessly
- Generate and test computer vision code
- Visualize and tweak results
- Deploy solutions as cloud endpoints or as a Streamlit app
This web app is an ideal choice for users who want a low-code approach to experimenting with AI-driven vision applications without dealing with complex local development environments.
2. VisionAgent Library

The VisionAgent Library is the core of the VisionAgent framework. It provides essential functionalities that allow developers to create and deploy AI-driven vision applications programmatically. Some of its key features include:
- Agent-based planning: Generates multiple solutions and selects the best one automatically.
- Tool selection and execution: Dynamically picks appropriate tools for different vision tasks.
- Code generation and evaluation: Produces efficient Python-based implementations.
- Built-in support for vision models: Uses a variety of computer vision models for tasks like object detection, image classification, and segmentation.
- Local and cloud integration: Allows running tasks locally or utilizing LandingAI’s cloud-hosted models for scalability.
For users who prefer a chat-based interface, VisionAgent also offers a Streamlit-powered chat app to interact with the agent more intuitively.
3. VisionAgent Tools Library

The VisionAgent Tools Library is a collection of pre-built tools that work with the VisionAgent framework. These tools are Python-based abstractions designed to execute specific computer vision tasks, such as:
- Object Detection – Identifies and locates objects in an image or video.
- Image Classification – Categorizes images based on trained AI models.
- QR Code Reading – Extracts encoded information from QR codes.
- Item Counting – Counts objects in an image for inventory or tracking purposes.
Each tool can interact with different vision models through a dynamic model registry, allowing users to switch between various models seamlessly. Additionally, developers can register custom tools if their use case is not covered by existing solutions.
The tools library does not include deployment services but provides the essential components needed to run vision models effectively.
Benchmark Evaluation

1. Categories & Approaches
- Landing AI (Agentic Object Detection) – This falls under the “Agentic” category.
- Microsoft Florence-2 – Categorized as “Open Set Object Detection.”
- Google OWLv2 – Also in the “Open Set Object Detection” category.
- Alibaba Qwen2.5-VL-7B-Instruct – Categorized as an “LMM” (Large Multimodal Model).
2. Metrics Evaluated
Each model is assessed based on three key performance metrics:
- Recall – Measures how well the model identifies all relevant objects. A higher recall means fewer missed detections.
- Precision – Measures how accurate the detections are, meaning fewer false positives.
- F1 Score – A harmonic mean of precision and recall, providing a balanced measure of performance.
3. Performance Comparison
| Model | Recall | Precision | F1 Score |
| Landing AI | 77.0% | 82.6% | 79.7% (highest) |
| Microsoft Florence-2 | 43.4% | 36.6% | 39.7% |
| Google OWLv2 | 81.0% | 29.5% | 43.2% |
| Alibaba Qwen2.5-VL-7B-Instruct | 26.0% | 54.0% | 35.1% |
4. Key Takeaways
- Landing AI’s Agentic Object Detection achieved the highest F1 Score (79.7%), meaning it balances precision and recall better than the others.
- Google OWLv2 had the highest recall (81.0%), meaning it detects the most objects but has lower precision.
- Alibaba’s Qwen2.5-VL-7B-Instruct had relatively low recall but moderate precision.
- Microsoft Florence-2 showed lower performance across all metrics compared to the other models.
Landing AI’s approach seems to provide the most balanced and effective performance in object detection tasks, as reflected in its highest F1 score. The other models have trade-offs, with some excelling in recall but lacking in precision, or vice versa.
Practical Working of VisionAgent
VisionAgent follows a structured process to provide outputs effectively:
- Upload an image you want to analyze
- Write a prompt (e.g., “detect people with glasses”)
- Our AI agent analyzes the image thoroughly
- Receive detection results on your image
1. Prompt: “Detect vegetables in and around the basket”
Step 1: Conversation
A user initiates a request, describing the vision task in natural language. VisionAgent interprets this prompt and confirms the task.
Input Image

Conversation
“I’ll help you write code to detect vegetables in and around the basket in the image. I’ll use object detection to identify various vegetables in the scene.”
Step 2: Planner
I need to first understand what’s in the image and get suggestions on how to detect vegetables in and around the basket. I’ll start by loading the image and using claude35_vqa and suggestion functions.
Planning Steps
- Understand the image contents using VQA (Visual Question Answering).
- Generate relevant suggestions for the best detection approach.
- Select tools that suit the task, such as object detection and color-based classification.
Example Plan
- Identify all objects in the image.
- Determine which objects are vegetables.
- Differentiate vegetables inside and outside the basket.
- Use a nested detection structure to analyze the spatial relationships.
Execution:
image = load_image('vegetablebasket.jpg')
claude35_vqa('Can you describe this image? What vegetables do you see in and around the basket?', [image])
suggestion('How can I detect vegetables in and around the basket in this image?', [image])Observation
[claude35_vqa output]
This image shows a beautiful array of fresh vegetables arranged around and in a wicker basket. The vegetables include:
1. Fresh carrots with green tops
2. Cauliflower
3. Onions
4. Potatoes
5. Broccoli
6. Eggplant
7. Red tomatoes
8. Yellow squash/zucchini
9. Purple cabbage
10. Green bell pepper
11. Red bell pepper
12. Cucumbers
13. Fresh garlic
14. Fresh herbs (appears to be parsley)
15. Green banana peppers or chili peppers
The vegetables appear to be very fresh and vibrant in color, arranged on what looks like a wooden surface or cutting board. The composition shows a nice variety of colors, from deep purples to bright reds, oranges, and greens, making it visually appealing and suggesting a healthy, nutritious selection of produce.
[end of claude35_vqa output]
[suggestions]
1. The vegetables are both in and around a basket, so relative_position would help in determining their locations with respect to the basket as an anchor point.
2. nested_structure applies because some vegetables are nested/contained within the basket while others are arranged outside it.
3. color would be useful since the vegetables are distinctly colored (red tomatoes, orange carrots, green broccoli, purple cabbage, etc.), making color a key identifier.
4. The problem does not involve small text, grid patterns, tracking in video, comparing sizes specifically, or dealing with extremely small objects in a large image. The depth position is visible but not crucial to the detection task.
[suggestion 0]
You need to find the color of objects in the image, you can use the following code to help with this task:
import numpy as np
import cv2
color_ranges = {
"red_lower": ((0, 100, 100), (int(179 * 20 / 360), 255, 255)),
"orange": ((int(179 * 21 / 360), 100, 100), (int(179 * 50 / 360), 255, 255)),
"yellow": ((int(179 * 51 / 360), 100, 100), (int(179 * 70 / 360), 255, 255)),
"green": ((int(179 * 71 / 360), 100, 100), (int(179 * 150 / 360), 255, 255)),
"cyan": ((int(179 * 151 / 360), 100, 100), (int(179 * 180 / 360), 255, 255)),
"blue": ((int(179 * 181 / 360), 100, 100), (int(179 * 265 / 360), 255, 255)),
"purple": ((int(179 * 266 / 360), 100, 100), (int(179 * 290 / 360), 255, 255)),
"pink": ((int(179 * 291 / 360), 100, 100), (int(179 * 330 / 360), 255, 255)),
"red_upper": ((int(179 * 331 / 360), 100, 100), (179, 255, 255)),
"white": ((0, 0, 200), (179, 25, 255)),
"gray": ((0, 0, 50), (179, 50, 200)),
"black": ((0, 0, 0), (179, 255, 30)),
}
def get_color(image, color_ranges):
hsv_image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
detected_colors = {}
for color, (lower, upper) in color_ranges.items():
upper_range = np.array(upper, dtype=np.uint8)
lower_range = np.array(lower, dtype=np.uint8)
mask = cv2.inRange(hsv_image, lower_range, upper_range)
detected_pixels = cv2.countNonZero(mask)
detected_colors[color] = detected_pixels
if "red_lower" in detected_colors and "red_upper" in detected_colors:
detected_colors["red"] = detected_colors["red_lower"] + detected_colors["red_upper"]
del detected_colors["red_lower"]
del detected_colors["red_upper"]
return sorted(detected_colors, key=detected_colors.get, reverse=True)[0]
[end of suggestion 0]
[suggestion 1]
You are trying to count objects within objects, or a nested structure. You can solve this by first detecting the outer objects, then cropping the image to the bounding box of each outer object and detecting the inner objects. You can use the following code to help with this task:
all_dets = <an object detection tool>("object", image)
height, width = image.shape[:2]
def area(box):
return (box[2] - box[0]) * (box[3] - box[1])
# only check inner detections on top 25 largest outer detections
largest_dets = sorted(dets, key=lambda x: area(x["bbox"]), reverse=True)[:25]
for det in largest_dets:
x1 = int(det["bbox"][0] * width)
y1 = int(det["bbox"][1] * height)
x2 = int(det["bbox"][2] * width)
y2 = int(det["bbox"][3] * height)
crop = image[y1:y2, x1:x2]
crop_height, crop_width = crop.shape[:2]
inner_dets = <an object detection tool>("object", crop)
for inner_det in inner_dets:
x1_inner = int(inner_det["bbox"][0] * crop_width)
y1_inner = int(inner_det["bbox"][1] * crop_height)
x2_inner = int(inner_det["bbox"][2] * crop_width)
y2_inner = int(inner_det["bbox"][3] * crop_height)
bbox = [
x1 + x1_inner,
y1 + y1_inner,
x1 + x2_inner,
y1 + y2_inner,
]
norm_bbox = [
bbox[0] / width,
bbox[1] / height,
bbox[2] / width,
bbox[3] / height,
]
all_dets.append(
{
"label": inner_det["label"],
"score": inner_det["score"],
"bbox": norm_bbox,
}
)
[end of suggestion 1]
[suggestion 2]
You are trying to locate an objects relative to 'anchor' objects. The 'anchor' objects can be detected fine, but there are many of the other objects and you only want to return the ones that are located relative to the 'anchor' objects as specified by the user. You can use the following code to help with this task:
# First find a model that can detect the location of the anchor objects
anchor_dets = <a model that can detect the location of the anchor objects>("anchor object", image)
# Then find a model that can detect the location of the relative objects
relative_dets = <a model that can detect the location of the relative objects>("relative object", image)
# This will give you relative objects 'above' the anchor objects since it's the
# distance between the lower left corner of the relative object and the upper left
# corner of the anchor object. The remaining functions can be used to get the other
# relative positions.
def above_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][0]) ** 2 + (
box1["bbox"][3] - box2["bbox"][1]
) ** 2
def below_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][0]) ** 2 + (
box1["bbox"][1] - box2["bbox"][3]
) ** 2
def right_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][2]) ** 2 + (
box1["bbox"][1] - box2["bbox"][1]
) ** 2
def left_distance(box1, box2):
return (box1["bbox"][2] - box2["bbox"][0]) ** 2 + (
box1["bbox"][1] - box2["bbox"][1]
) ** 2
closest_boxes = []
for anchor_det in anchor_dets:
# You can use any of the above functions to get the relative position
distances = [
(relative_det, above_distance(relative_det, anchor_det))
for relative_det in relative_dets
]
# You must grab the nearest object for each of the anchors. This line will give
# you the box directly above the anchor box (or below, left, right depending on
# the function used)
closest_box = min(distances, key=lambda x: x[1])[0]
closest_boxes.append(closest_box)
[end of suggestion 2]
[end of suggestions]
<count>9</count>Step 3: Execution
The planned steps are executed using the VisionAgent Library and Tools Library. This involves loading the image, running models, and generating detection outputs.
Planner
Based on Claude’s description and the suggestions, I need to detect vegetables both in and around the basket. This is a nested structure problem where I first need to detect the basket and then detect vegetables in relation to it. Let me first get a tool that can detect both the basket and vegetables.
Example Execution Code
image = load_image('vegetablebasket.jpg')
claude35_vqa('Can you describe this image? What vegetables do you see in and around the basket?', [image])
suggestion('How can I detect vegetables in and around the basket in this image?', [image])
get_tool_for_task('Detect basket and vegetables in the image', [image])Observation and Final Output
After execution, VisionAgent produces structured results:
- Detected vegetables categorized inside and outside the basket.
- Bounding box coordinates for each detected vegetable.
- A deployable AI model that can be used for real-world applications.
Output
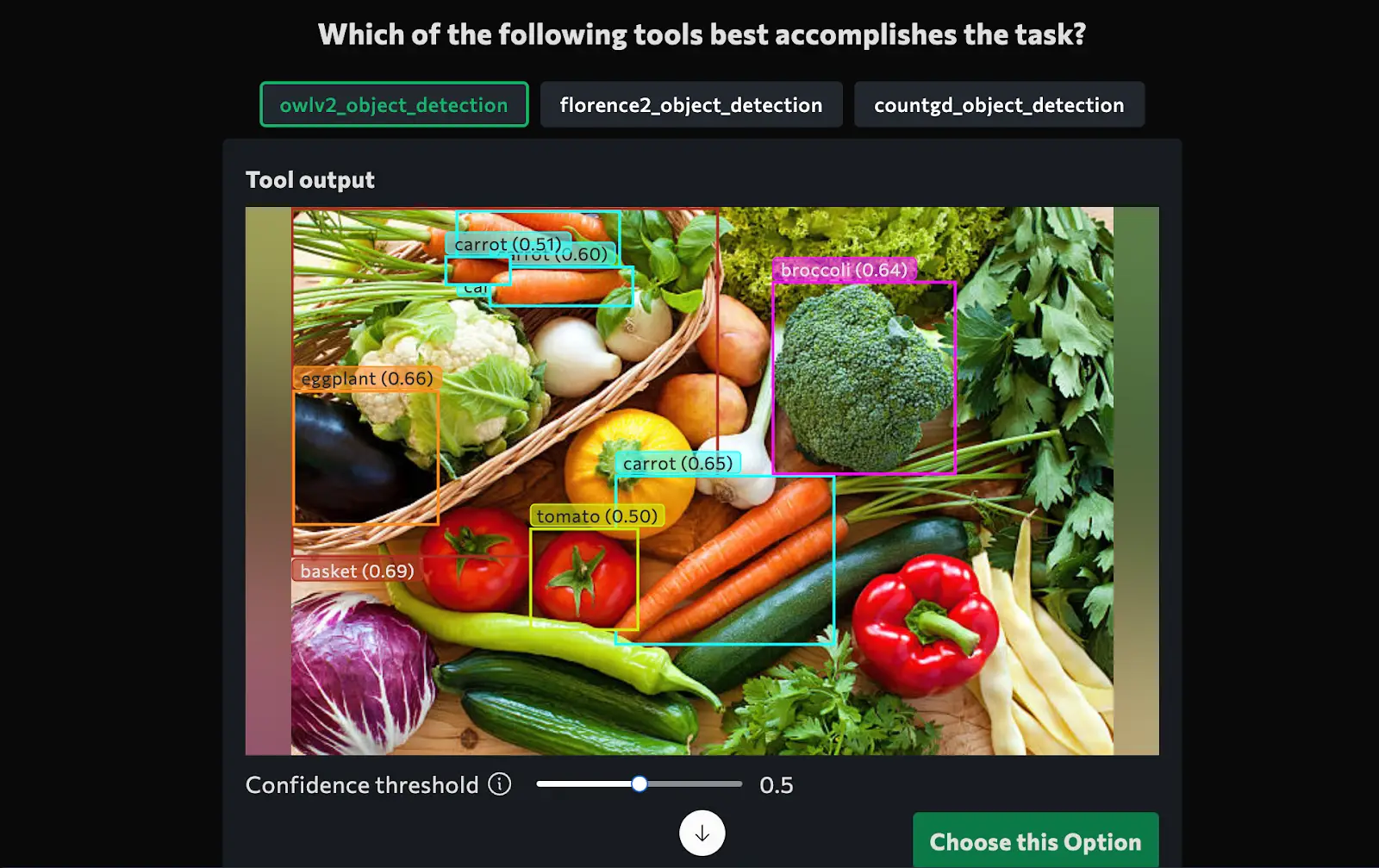
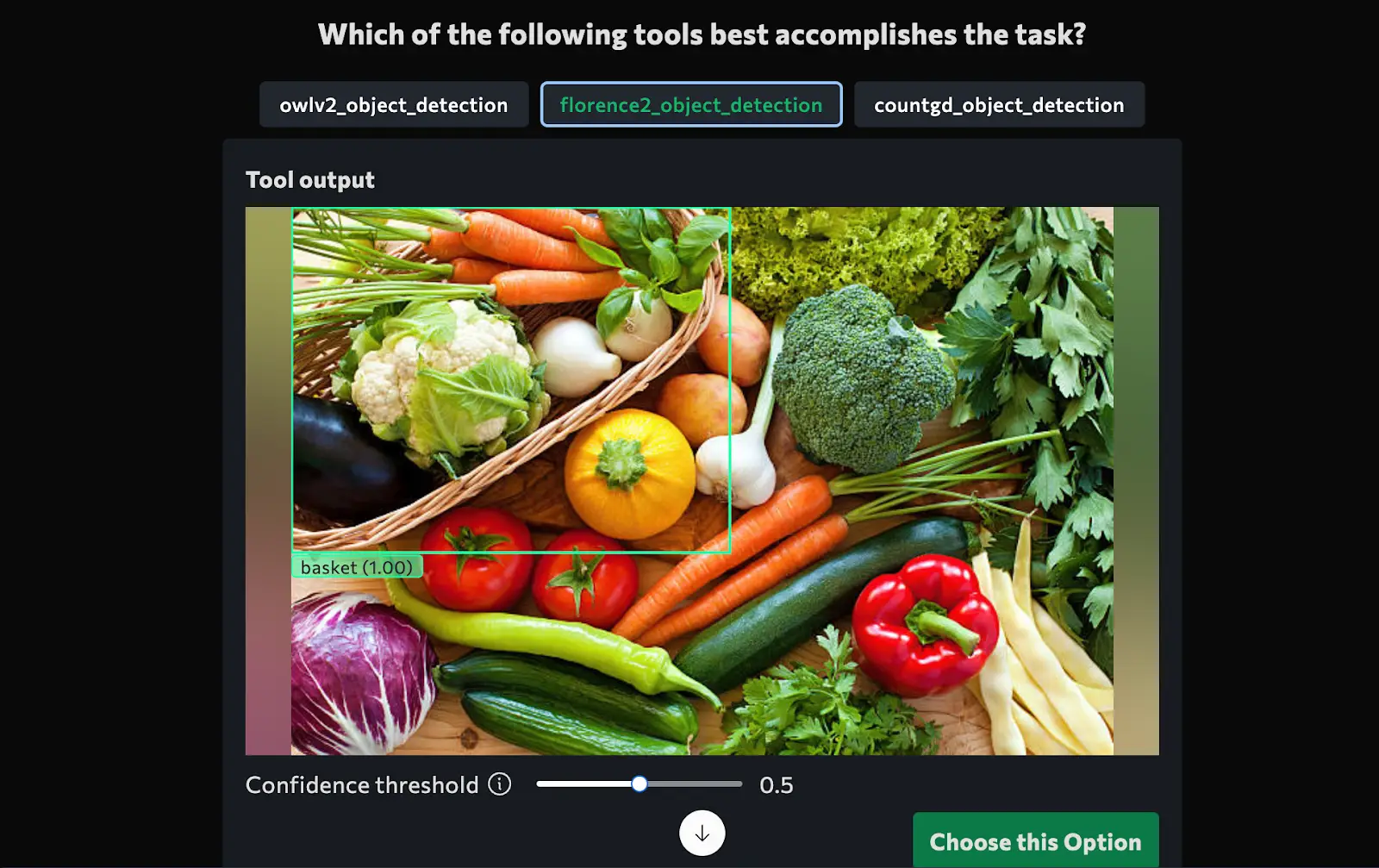
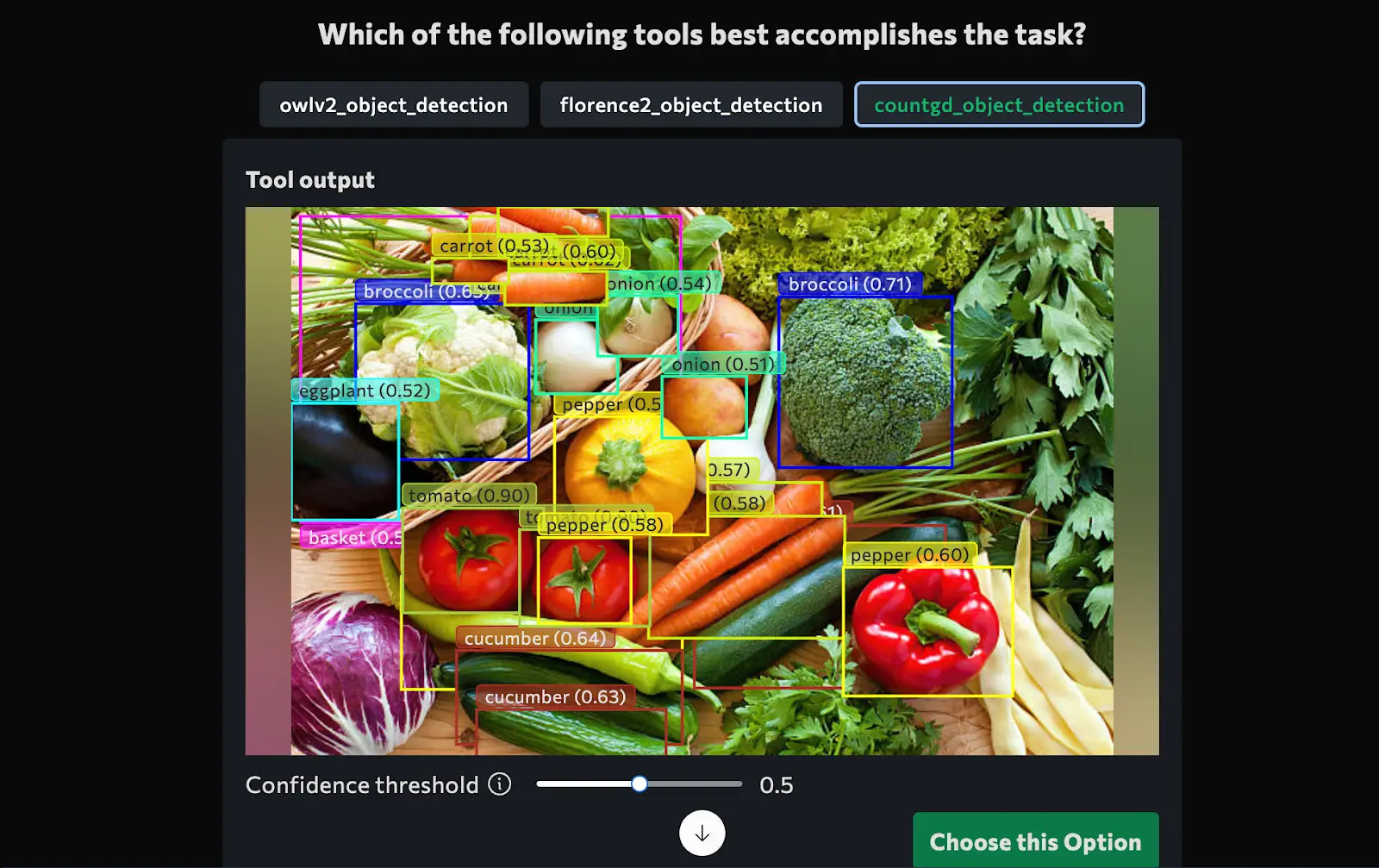
2. Prompt: “Identify red car in the video”
Input Video: Video Link
Step 1: Conversation
I’ll help you write code to identify and track red cars in the video. I’ll use object detection and color-based filtering to accomplish this task.
Step 2: Planner
I need to first understand what’s in the video and get suggestions on how to identify a red car. I’ll extract some frames and use claude35_vqa to describe the video content, then get suggestions.
Step 3: Execution
frames = extract_frames_and_timestamps('videoplayback(4).mp4', 1)
frames = [f["frame"] for f in frames]
claude35_vqa('Can you describe this video? Is there a red car in it?', frames[:5])
suggestion('How can I identify the red car in the video?', frames[:5])Observation
[claude35_vqa output]
Yes, there is a red car (#21) in this video sequence, which appears to be a NASCAR race clip showing an incident between two cars - a red #21 car and a black/gold #3 car with Winchester branding. The video shows them making contact around turn 4 of the track, with the cars getting close to each other and potentially trading paint. The sequence is labeled as "Josh Berry vs Austin Dillon" and shows what appears to be a tense racing moment between the two drivers. The text overlays indicate "WOAH TURN 4", "CONTACT", "BERRY", "A LOT", and "THERE" as the sequence progresses.
[end of claude35_vqa output]
[suggestions]
Based on the user's request to identify the red car in the video and the provided video frames, this is primarily a case of:
1. finding_features_with_video_tracking - The sequence shows a NASCAR race interaction between two cars (Josh Berry and Austin Dillon) where tracking the red #21 car through the turn and contact is key
2. color - The specific request mentions identifying the "red car", making color identification relevant
3. relative_position - The interaction between the two cars requires understanding their positions relative to each other through the turn and contact
The other categories don't apply because:
- This isn't about small text or large images
- There are no grid patterns or missing elements
- This isn't about comparing sizes or nested structures
- While there is some depth perception in racing, the request isn't specifically about determining depth position
[suggestion 0]
You need to find the color of objects in the image, you can use the following code to help with this task:
import numpy as np
import cv2
color_ranges = {
"red_lower": ((0, 100, 100), (int(179 * 20 / 360), 255, 255)),
"orange": ((int(179 * 21 / 360), 100, 100), (int(179 * 50 / 360), 255, 255)),
"yellow": ((int(179 * 51 / 360), 100, 100), (int(179 * 70 / 360), 255, 255)),
"green": ((int(179 * 71 / 360), 100, 100), (int(179 * 150 / 360), 255, 255)),
"cyan": ((int(179 * 151 / 360), 100, 100), (int(179 * 180 / 360), 255, 255)),
"blue": ((int(179 * 181 / 360), 100, 100), (int(179 * 265 / 360), 255, 255)),
"purple": ((int(179 * 266 / 360), 100, 100), (int(179 * 290 / 360), 255, 255)),
"pink": ((int(179 * 291 / 360), 100, 100), (int(179 * 330 / 360), 255, 255)),
"red_upper": ((int(179 * 331 / 360), 100, 100), (179, 255, 255)),
"white": ((0, 0, 200), (179, 25, 255)),
"gray": ((0, 0, 50), (179, 50, 200)),
"black": ((0, 0, 0), (179, 255, 30)),
}
def get_color(image, color_ranges):
hsv_image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
detected_colors = {}
for color, (lower, upper) in color_ranges.items():
upper_range = np.array(upper, dtype=np.uint8)
lower_range = np.array(lower, dtype=np.uint8)
mask = cv2.inRange(hsv_image, lower_range, upper_range)
detected_pixels = cv2.countNonZero(mask)
detected_colors[color] = detected_pixels
if "red_lower" in detected_colors and "red_upper" in detected_colors:
detected_colors["red"] = detected_colors["red_lower"] + detected_colors["red_upper"]
del detected_colors["red_lower"]
del detected_colors["red_upper"]
return sorted(detected_colors, key=detected_colors.get, reverse=True)[0]
[end of suggestion 0]
[suggestion 1]
First try to solve the problem using a VQA tool before using the tracking approach for a faster and easier solution:
answer = <VQA tool to answer your question>("<your prompt here>", image)
If that does not work, you can track the objects in the video and then identify features on those objects. You need to first get a tool that can track objects in a video, and then for each object find another tool to identify the features on the object. You can use the following code to help with this task:
track_predictions = <object tracking tool>("object", video_frames)
# Step 1: go through each frame and each prediction and extract the predicted bounding boxes as crops
obj_to_info = {}
for frame, frame_predictions in zip(video_frames, track_predictions):
for obj in frame_predictions:
if obj["label"] not in obj_to_info:
obj_to_info[obj["label"]] = []
height, width = frame.shape[:2]
crop = frame[
int(obj["bbox"][1] * height) : int(obj["bbox"][3] * height),
int(obj["bbox"][0] * width) : int(obj["bbox"][2] * width),
:,
]
# For each crop use an object detection tool, VQA tool or classification tool to identify if the object contains the features you want
output = <tool to identify your feature or multiple features>("<your feature(s) here>", crop)
obj_to_info[obj["label"]].extend(output)
print(f"{len(obj_to_info)} objects tracked")
objects_with_info = set()
for infos in obj_to_info:
for info in info:
if info["label"] == "<your feature here>":
objects_with_info.add(info)
break
print(f"{len(objects_with_info)} objects with features found")
[end of suggestion 1]
[suggestion 2]
You are trying to locate an objects relative to 'anchor' objects. The 'anchor' objects can be detected fine, but there are many of the other objects and you only want to return the ones that are located relative to the 'anchor' objects as specified by the user. You can use the following code to help with this task:
# First find a model that can detect the location of the anchor objects
anchor_dets = <a model that can detect the location of the anchor objects>("anchor object", image)
# Then find a model that can detect the location of the relative objects
relative_dets = <a model that can detect the location of the relative objects>("relative object", image)
# This will give you relative objects 'above' the anchor objects since it's the
# distance between the lower left corner of the relative object and the upper left
# corner of the anchor object. The remaining functions can be used to get the other
# relative positions.
def above_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][0]) ** 2 + (
box1["bbox"][3] - box2["bbox"][1]
) ** 2
def below_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][0]) ** 2 + (
box1["bbox"][1] - box2["bbox"][3]
) ** 2
def right_distance(box1, box2):
return (box1["bbox"][0] - box2["bbox"][2]) ** 2 + (
box1["bbox"][1] - box2["bbox"][1]
) ** 2
def left_distance(box1, box2):
return (box1["bbox"][2] - box2["bbox"][0]) ** 2 + (
box1["bbox"][1] - box2["bbox"][1]
) ** 2
closest_boxes = []
for anchor_det in anchor_dets:
# You can use any of the above functions to get the relative position
distances = [
(relative_det, above_distance(relative_det, anchor_det))
for relative_det in relative_dets
]
# You must grab the nearest object for each of the anchors. This line will give
# you the box directly above the anchor box (or below, left, right depending on
# the function used)
closest_box = min(distances, key=lambda x: x[1])[0]
closest_boxes.append(closest_box)
[end of suggestion 2]
[end of suggestions]
<count>9</count>Planner
Based on Claude’s description and the suggestions, I need to track cars in the video and identify the red one. Let me first get a tool for tracking cars in the video.
Execution
get_tool_for_task('Track cars in a NASCAR race video', frames[:5])Output
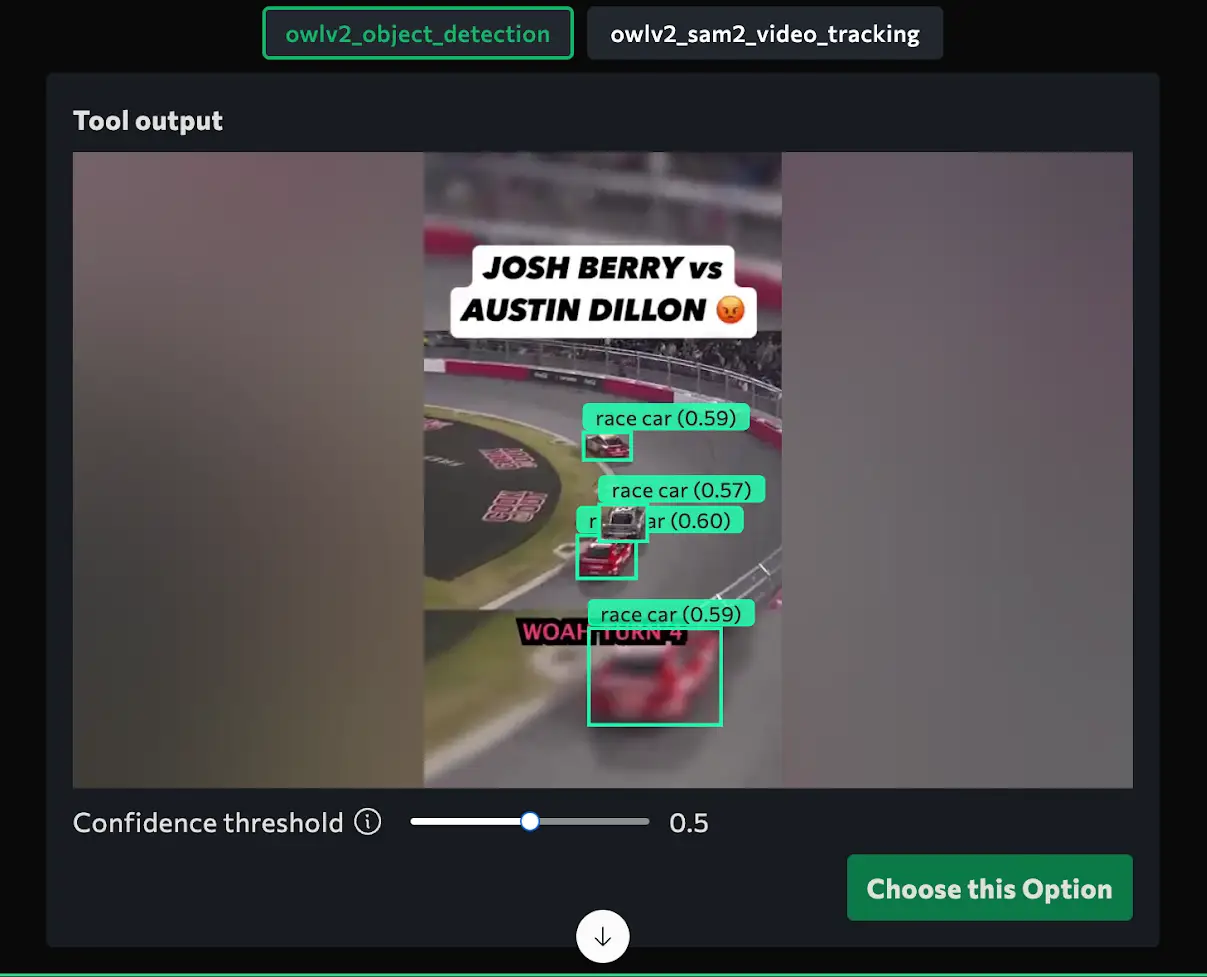
Conclusion
VisionAgent is transforming the way developers build, test, and deploy AI-driven vision applications. By automating tedious processes and providing ready-to-use tools, it significantly reduces development time while ensuring high-quality results. Whether you are an AI researcher, a developer, or a business looking to implement computer vision solutions, VisionAgent provides a fast, flexible, and scalable way to achieve your goals.
With ongoing advancements in AI, VisionAgent is expected to evolve further, incorporating even more powerful models and expanding its ecosystem to support a wider range of applications. Now is the perfect time to explore how VisionAgent can enhance your AI-driven vision projects.
Hi, I am Pankaj Singh Negi - Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.


Nice read