In today’s digital world, businesses and individuals aim to provide instant and accurate answers to website visitors. With increased demand for seamless communication, AI-driven chatbots have become a crucial tool for user interaction and offering useful information in a split second. Chatbots can search, comprehend, and utilize website data efficiently, making customers satisfied and enhancing the customer experience for companies. In this article, we will explain how to build a chatbot that fetches information from a website, processes it efficiently, and engages in meaningful conversations with the assistance of Qwen-2.5, LangChain, and FAISS. we will learn the main components and integration process.
Learning Objectives
- Understand the importance of AI-powered chatbots for businesses.
- Learn how to extract and process website data for chatbot use.
- Gain insights into using FAISS for efficient text retrieval.
- Explore the role of Hugging Face embeddings in chatbot intelligence.
- Discover how to integrate Qwen-2.5-32b for generating responses.
- Build an interactive chatbot interface using Streamlit.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Why Use a Website Chatbot?
- How Does This Chatbot Work?
- Building a Custom Chatbot Using Qwen-2.5-32b and LangChain
- Step 1: Setting Up the Foundation
- Step 2: Handling Windows Event Loop (For Compatibility)
- Step 3: Importing Required Libraries
- Step 4: Importing LangChain Modules
- Step 5: Loading Environment Variables
- Step 6: Fetching and Processing Website Data
- Step 7: Building FAISS Vector Store
- Step 8: Loading the Groq LLM
- Step 9: Setting Up Retrieval Chain
- Step 10: Displaying Chat History
- Step 11: Accepting User Input
- Step 12: Processing User Queries
- Final Output
- Testing the Chatbot
- Conclusion
- Frequently Asked Questions
Why Use a Website Chatbot?
Many businesses struggle with handling large volumes of customer queries efficiently. Traditional customer support teams often face delays, leading to frustrated users and increased operational costs. Moreover, hiring and training support agents can be expensive, making it difficult for companies to scale effectively.
A chatbot helps by offering instant and automated responses to user questions without needing a human. Businesses are able to cut support costs considerably, increase customer interaction, and provide users with instant answers to their questions. AI-based chatbots are capable of handling large volumes of data, determining the right information in a matter of seconds, and reacting correctly based on the context, making them very beneficial for businesses nowadays.
Website chatbots are mostly used in E-learning platforms, E-commerce websites, customer support platforms, and news websites.
Also Read: Building a Writing Assistant with LangChain and Qwen-2.5-32B
Key Components of the Chatbot
- Unstructured URL Loader: Extracts content from the website.
- Text Splitter: Breaks down large documents into manageable chunks.
- FAISS (Facebook AI Similarity Search): Stores and retrieves document embeddings efficiently.
- Qwen-2.5-32b: A powerful language model that understands queries and generates responses.
- Streamlit: A framework to create an interactive chatbot interface.
How Does This Chatbot Work?
Here’s a flowchart explaining the working of our chatbot.
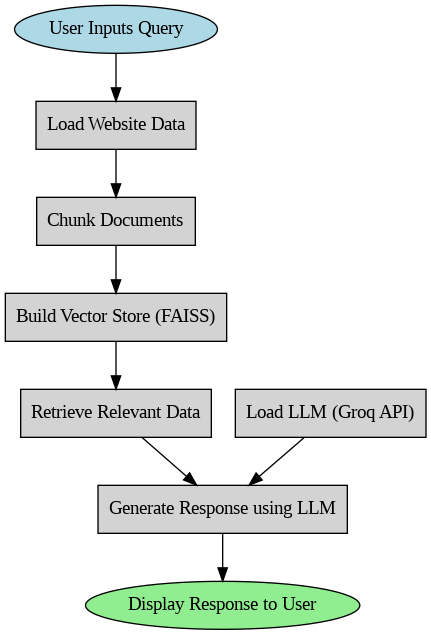
Building a Custom Chatbot Using Qwen-2.5-32b and LangChain
Now let’s see how to build a custom website chatbot using Qwen-2.5-32b, LangChain, and FAISS.
Step 1: Setting Up the Foundation
Let’s begin by setting up the prerequisites.
1. Environment Setup
# Create a Environment
python -m venv env
# Activate it on Windows
.\env\Scripts\activate
# Activate in MacOS/Linux
source env/bin/activate2. Install the Requirements.txt
pip install -r https://raw.githubusercontent.com/Gouravlohar/Chatbot/refs/heads/main/requirements.txt3. API Key Setup
Paste the API key in .env file.
API_KEY="Your API KEY PASTE HERE"Now let’s get into the actual coding part.
Step 2: Handling Windows Event Loop (For Compatibility)
import sys
import asyncio
if sys.platform.startswith("win"):
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())Ensures compatibility with Windows by setting the correct event loop policy for asyncio, as Windows uses a different default event loop.
Step 3: Importing Required Libraries
import streamlit as st
import os
from dotenv import load_dotenv- Streamlit is used to create the chatbot UI.
- os is used to set environment variables.
- dotenv helps load API keys from a .env file.
os.environ["STREAMLIT_SERVER_FILEWATCHER_TYPE"] = "none" This disables Streamlit’s file watcher to improve performance by reducing unnecessary file system monitoring.
Step 4: Importing LangChain Modules
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import UnstructuredURLLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_groq import ChatGroq
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate- HuggingFaceEmbeddings : Converts text into vector embeddings.
- FAISS : Stores and retrieves relevant document chunks based on queries.
- UnstructuredURLLoader : Loads text content from web URLs.
- RecursiveCharacterTextSplitter : Splits large text into smaller chunks for processing.
- ChatGroq : Uses the Groq API for AI-powered responses.
- create_retrieval_chain – Constructs a pipeline that retrieves relevant documents before passing them to the LLM.
- create_stuff_documents_chain – Combines retrieved documents into a format suitable for LLM processing.
Step 5: Loading Environment Variables
load_dotenv()
groq_api_key = os.getenv("API_KEY")
if not groq_api_key:
st.error("Groq API Key not found in .env file")
st.stop()- Loads the Groq API key from the .env file.
- If the key is missing, the app shows an error and stops execution.
1. Function to Load Website Data
def load_website_data(urls):
loader = UnstructuredURLLoader(urls=urls)
return loader.load()- Uses UnstructuredURLLoader to fetch content from a list of URLs.
2. Function to Chunk Documents
def chunk_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
return text_splitter.split_documents(docs)- Splits large text into 500-character chunks with 50-character overlap for better context retention.
3. Function to Build FAISS Vector Store
def build_vectorstore(text_chunks):
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
return FAISS.from_documents(text_chunks, embeddings)- Converts text chunks into vector embeddings using all-MiniLM-L6-v2.
- Stores embeddings in a FAISS vector database for efficient retrieval.
4. Function to Load Qwen-2.5-32b
def load_llm(api_key):
return ChatGroq(groq_api_key=api_key, model_name="qwen-2.5-32b", streaming=True)- Loads Groq’s Qwen-2.5-32b model for generating responses.
- Enables streaming for a real-time response experience.
5. Streamlit UI Setup
st.title("Custom Website Chatbot(Analytics Vidhya)")6. Conversation History Setup
if "conversation" not in st.session_state:
st.session_state.conversation = []- Stores chat history in st.session_state so messages persist across interactions.
Step 6: Fetching and Processing Website Data
urls = ["https://www.analyticsvidhya.com/"]
docs = load_website_data(urls)
text_chunks = chunk_documents(docs)- Loads content from Analytics Vidhya.
- Splits the content into small chunks.
Step 7: Building FAISS Vector Store
vectorstore = build_vectorstore(text_chunks)
retriever = vectorstore.as_retriever()Stores processed text chunks in FAISS . Then Converts the FAISS vectorstore into a retriever that can fetch relevant chunks based on user queries.
Step 8: Loading the Groq LLM
llm = load_llm(groq_api_key)Step 9: Setting Up Retrieval Chain
system_prompt = (
"Use the given context to answer the question. "
"If you don't know the answer, say you don't know. "
"Use detailed sentences maximum and keep the answer accurate. "
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
])
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=combine_docs_chain
)- Defines a system prompt to ensure accurate, context-based answers.
- Uses ChatPromptTemplate to format the chatbot’s interactions.
- Combines retrieved documents (combine_docs_chain) to provide context to the LLM.
This step creates a qa_chain by linking the retriever (FAISS) with the LLM, ensuring responses are based on retrieved website content.
Step 10: Displaying Chat History
for msg in st.session_state.conversation:
if msg["role"] == "user":
st.chat_message("user").write(msg["message"])
else:
st.chat_message("assistant").write(msg["message"])This displays previous conversation messages.
Step 11: Accepting User Input
user_input = st.chat_input("Type your message here") if hasattr(st, "chat_input") else st.text_input("Your message:")- Uses st.chat_input (if available) for a better chat UI.
- Falls back to st.text_input for compatibility.
Step 12: Processing User Queries
if user_input:
st.session_state.conversation.append({"role": "user", "message": user_input})
if hasattr(st, "chat_message"):
st.chat_message("user").write(user_input)
else:
st.markdown(f"**User:** {user_input}")
with st.spinner("Processing..."):
response = qa_chain.invoke({"input": user_input})
assistant_response = response.get("answer", "I'm not sure, please try again.")
st.session_state.conversation.append({"role": "assistant", "message": assistant_response})
if hasattr(st, "chat_message"):
st.chat_message("assistant").write(assistant_response)
else:
st.markdown(f"**Assistant:** {assistant_response}")This code handles user input, retrieval, and response generation in a chatbot. When a user enters a message, it is stored in st.session_state.conversation and displayed in the chat interface. A loading spinner appears while the chatbot processes the query using qa_chain.invoke({“input”: user_input}), which retrieves relevant information and generates a response. The assistant’s reply is extracted from the response dictionary, ensuring a fallback message if no answer is found. Finally, the assistant’s response is stored and displayed, maintaining a smooth and interactive chat experience.
Get the full code on GitHub here
Final Output

Testing the Chatbot
Now let’s try out a few prompts on the chatbot we just built.
Prompt: “Can you list some ways to engage with the Analytics Vidhya community?”
Response:

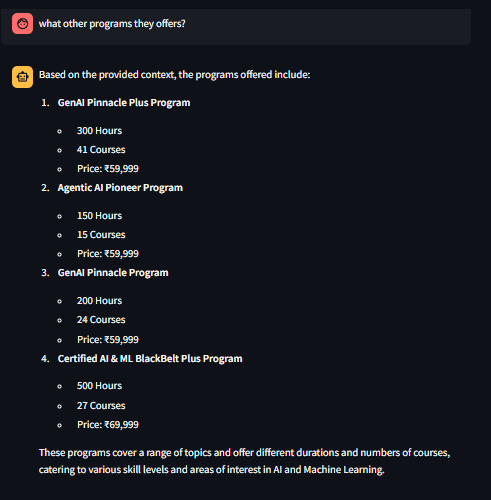
Prompt: “what other programs they offers?”
Response:
Conclusion
AI chatbots have transformed the manner in which people communicate on the internet. Using advanced models like Qwen-2.5-32b, businesses and individuals can make sure that their chatbot responds well and suitably. As technology continues to advance, using AI chatbots on websites will be the order of the day, and people will be able to access information easily.
In the future, developments like having long conversations, voice questioning, and interacting with bigger knowledge pools can further advance chatbots even more.
Key Takeaways
- The chatbot fetches content from the Analytics Vidhya website, processes it, and stores it in a FAISS vector database for quick retrieval.
- It splits website content into 500-character chunks with a 50-character overlap, ensuring better context retention when retrieving relevant information.
- The chatbot uses Qwen-2.5-32b to generate responses, leveraging retrieved document chunks to provide accurate, context-aware answers.
- Users can interact with the chatbot using a chat interface in Streamlit, and conversation history is stored for seamless interactions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Q1. How does this chatbot fetch data from a website?
A. It uses UnstructuredURLLoader from LangChain to extract content from specified URLs.
Q2. Why is FAISS used in this chatbot?
A. FAISS (Facebook AI Similarity Search) helps store and retrieve relevant text chunks efficiently based on user queries.
Q3. What model is used for generating responses?
A. The chatbot uses Groq’s Qwen-2.5-32B, a powerful LLM, to generate answers based on retrieved website content.
Q4. Can this chatbot be extended to multiple websites?
A. Yes! Simply modify the urls list to include more websites, and the chatbot will fetch, process, and retrieve information from them.
Q5. How does the chatbot ensure accurate responses?
A. It follows a Retrieval-Augmented Generation (RAG) approach, meaning it retrieves relevant website data first and then generates an answer using LLM.
Hi I'm Gourav, a Data Science Enthusiast with a medium foundation in statistical analysis, machine learning, and data visualization. My journey into the world of data began with a curiosity to unravel insights from datasets.





