Financial reports are critical for assessing a company’s health. They span hundreds of pages, making it difficult to extract specific insights efficiently. Analysts and investors spend hours sifting through balance sheets, income statements and footnotes just to answer simple questions such as – What was the company’s revenue in 2024? With recent advancements in LLM models and vector search technologies, we can automate financial report analysis using LlamaIndex and related frameworks. This blog post explores how we can use LlamaIndex, ChromaDB, Gemini2.0, and Ollama to build a robust financial RAG system that answers queries from lengthy reports with precision.
Learning Objectives
- Understand the need for financial report retrieval systems for efficient analysis.
- Learn how to preprocess and vectorize financial reports using LlamaIndex.
- Explore ChromaDB for building a robust vector database for document retrieval.
- Implement query engines using Gemini 2.0 and Llama 3.2 for financial data analysis.
- Discover advanced query routing techniques using LlamaIndex for enhanced insights.
This article was published as a part of the Data Science Blogathon.
Table of contents
Why do we need a Financial Report Retrieval System?
Financial reports contain critical insights about a company’s performance, including revenue, expenses, liabilities, and profitability. However, these reports are huge, lengthy, and full of technical jargon, making it extremely time consuming for analysts, investors, and executives to extract relevant information manually.
A financial Report Retrieval System can automate this process by enabling natural language queries. Instead of searching through PDFs, users can simply ask questions like, “What was the revenue in 2023?” or “Summarize the liquidity concerns for 2023.” The system quickly retrieves and summarizes relevant sections, saving hours of manual effort.
Project Implementation
For project implementation we need to first set up the environment and install the required libraries:
Step 1: Setting Up the Environment
We will start by creating and conda env for our development work.
$conda create --name finrag python=3.12
$conda activate finragStep 2: Install essential Python libraries
Installing libraires is the crucial step for any project implementation:
$pip install llama-index llama-index-vector-stores-chroma chromadb
$pip install llama-index-llms-gemini llama-index-llms-ollama
$pip install llama-index-embeddings-gemini llama-index-embeddings-ollama
$pip install python-dotenv nest-asyncio pypdfStep 3: Creating Project Directory
Now create a project directory and create a file named .env and on that file put all your API keys for secure API key management.
# on .env file
GOOGLE_API_KEY="<your-api-key>"We load the environment variable from that .env file to store the sensitive API key securely. This ensures that our Gemini API or Google API remains protected.
We will do our project using Jupyter Notebook.
Create a Jupyter Notebook file and start implementing step by step.
Step 4: Loading API key
Now we will load the API key below:
import os
from dotenv import load_dotenv
load_dotenv()
GEMINI_API_KEY = os.getenv("GOOGLE_API_KEY")
# Only to check .env is accessing properly or not.
# print(f"GEMINI_API_KEY: {GEMINI_API_KEY}")Now, our enviroment ready so we can go to the next most important phase.
Documents Processing with Llamaindex
Collecting Motorsport Games Inc. financial report from AnnualReports website.
Download Link here.
First page looks like:

This reports have a total of 123 pages, but I just take the financial statements of the reports and create a new PDF for our project.
How I do it? It is very easy with PyPDF libraries.
from pypdf import PdfReader
from pypdf import PdfWriter
reader = PdfReader("NASDAQ_MSGM_2023.pdf")
writer = PdfWriter()
# page 66 to 104 have financial statements.
page_to_extract = range(66, 104)
for page_num in page_to_extract:
writer.add_page(reader.pages[page_num])
output_pdf = "Motorsport_Games_Financial_report.pdf"
with open(output_pdf, "wb") as outfile:
writer.write(output_pdf)
print(f"New PDF created: {output_pdf}")The new report file has only 38 pages, which will help us to embed the document quickly.
Loading and Splitting Financial Reports
In your project data directory, put your newly created Motorsport_Games_Financial_report.pdf file, which will be indexed for the project.
Financial reports are typically in PDF format, containing extensive tabular data, footnotes, and legal statements. We use LlamaIndex’s SimpleDirectoryReader to load these documents and convert them to documents.
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()Since reports are very large to process as a single documents, we slit them into smaller chunk or nodes. Each chunk corresponds to a page or section, it helps retrieval more efficiently.
from copy import deepcopy
from llama_index.core.schema import TextNode
def get_page_nodes(docs, separator="\n---\n"):
"""Split each document into page node, by separator."""
nodes = []
for doc in docs:
doc_chunks = doc.text.split(separator)
for doc_chunk in doc_chunks:
node = TextNode(
text=doc_chunk,
metadata=deepcopy(doc.metadata),
)
nodes.append(node)
return nodesTo understand the process of the document ingestion see below diagram.
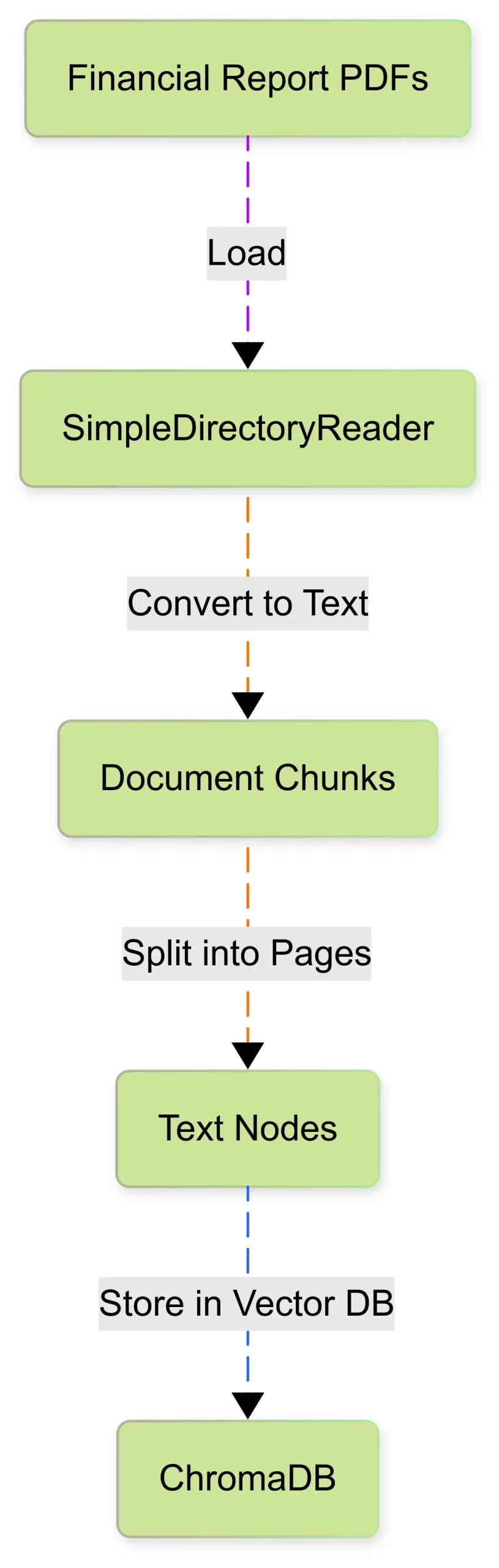
Now our financial data is ready for vectorizing and storing for retrieval.
Building the Vector Database with ChromaDB
We will use ChromaDB for fast, accurate, and local vector database. Our embedded representation of financial text will be stored into ChromaDB.
We initialize the vector database and configure Nomic-embed-text model using Ollama for local embedding generation.
import chromadb
from llama_index.llms.gemini import Gemini
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import Settings
embed_model = OllamaEmbedding(model_name="nomic-embed-text")
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("financial_collection")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)Finally, we create a Vector Index using LLamaIndex’s VectorStoreIndex. This index links our vector database to LlamaIndex’s query engine.
from llama_index.core import VectorStoreIndex, StorageContext
storage_context = StorageContext.from_defaults(vector_store=vector_store)
vector_index = VectorStoreIndex.from_documents(documents=documents, storage_context=storage_context, embed_model=embed_model)The above code will create the Vector Index using nomic-embed-text from financial text documents. It will take time, depending on your local system specification.
When your indexing is done, then you can use the code for reuse that is embedded when necessary without re-indexing again.
vector_index = VectorStoreIndex.from_vector_store(
vector_store=vector_store, embed_model=embed_model
)This will allow you use chromadb embedding file from the storage.
Now our heavy loading was done, time for query the report and relax.
Query Financial Data with Gemini 2.0
Once our financial data is indexed, we can ask natural language questions and receive accurate answers. For querying we will use Gemini-2.0 Flash model which interacts with our vector database to fetch relevant sections and generate insights responses.
Setting-up Gemini-2.0
from llama_index.llms.gemini import Gemini
llm = Gemini(api_key=GEMINI_API_KEY, model_name="models/gemini-2.0-flash")
Initiate query engine using Gemini 2.0 with vector index
query_engine = vector_index.as_query_engine(llm=llm, similarity_top_k=5)Example Queries and Response
Below we have multiple queries with different responses:
Query-1
response = query_engine.query("what is the revenue of on 2022 Year Ended December 31?")
print(str(response))Response

Corresponding image from Report:

Query-2
response = query_engine.query(
"what is the Net Loss Attributable to Motossport Games Inc. on 2022 Year Ended December 31?"
)
print(str(response))Response

Corresponding image from Report:
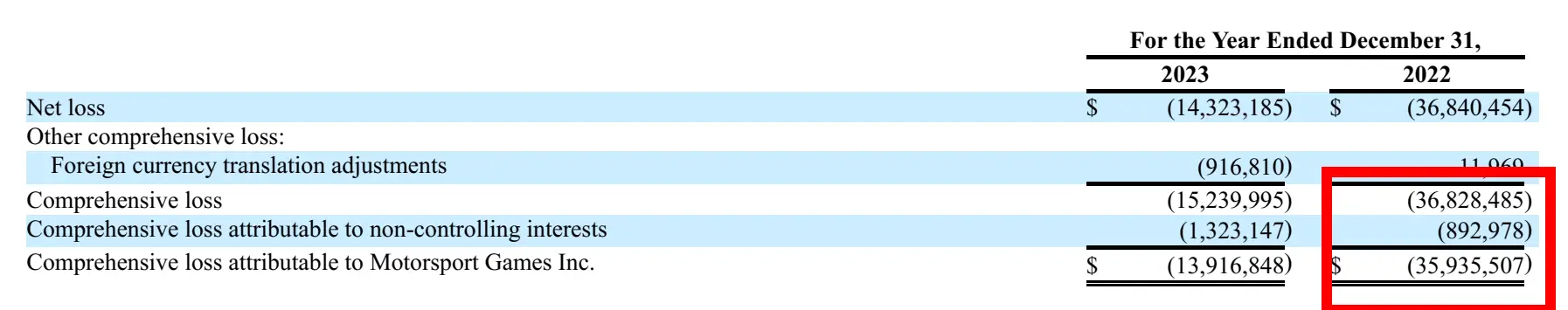
Query-3
response = query_engine.query(
"What are the Liquidity and Going concern for the Company on December 31, 2023"
)
print(str(response))Response

Query-4
response = query_engine.query(
"Summarise the Principal versus agent considerations of the company?"
)
print(str(response))Response

Corresonding image from Report:

Query-5
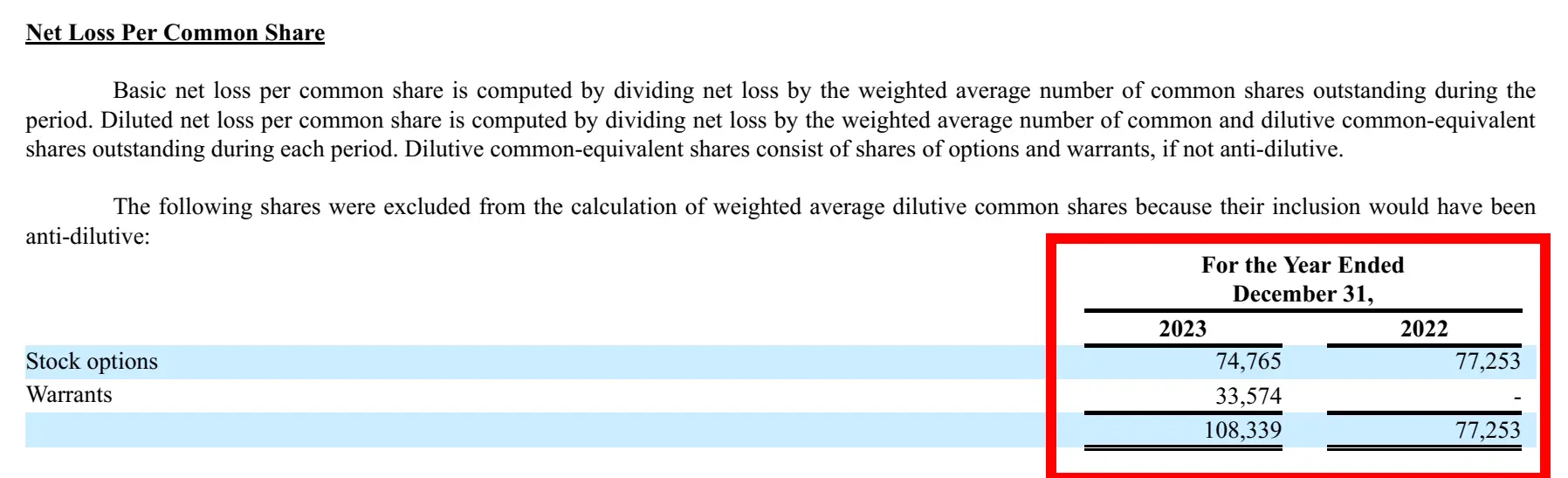
response = query_engine.query(
"Summarise the Net Loss Per Common Share of the company with financial data?"
)
print(str(response))Response

Corresonding image from Report:
Query-6
response = query_engine.query(
"Summarise Property and equipment consist of the following balances as of December 31, 2023 and 2022 of the company with financial data?"
)
print(str(response))Response

Corresponding image from Report:

Query-7
response = query_engine.query(
"Summarise The Intangible Assets on December 21, 2023 of the company with financial data?"
)
print(str(response))Response

Query-8
response = query_engine.query(
"What are leases of the company with yearwise financial data?"
)
print(str(response))Response
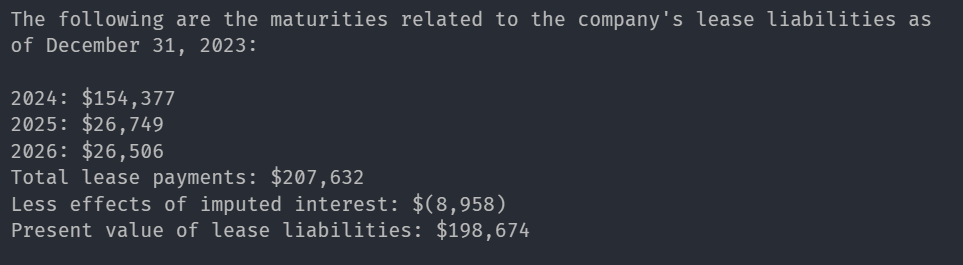
Corresponding image from Report:

Local Query Using Llama 3.2
Leverage Llama 3.2 locally to query financial reports without relying on cloud-based models.
Seting Up Llama 3.2:1b
local_llm = Ollama(model="llama3.2:1b", request_timeout=1000.0)
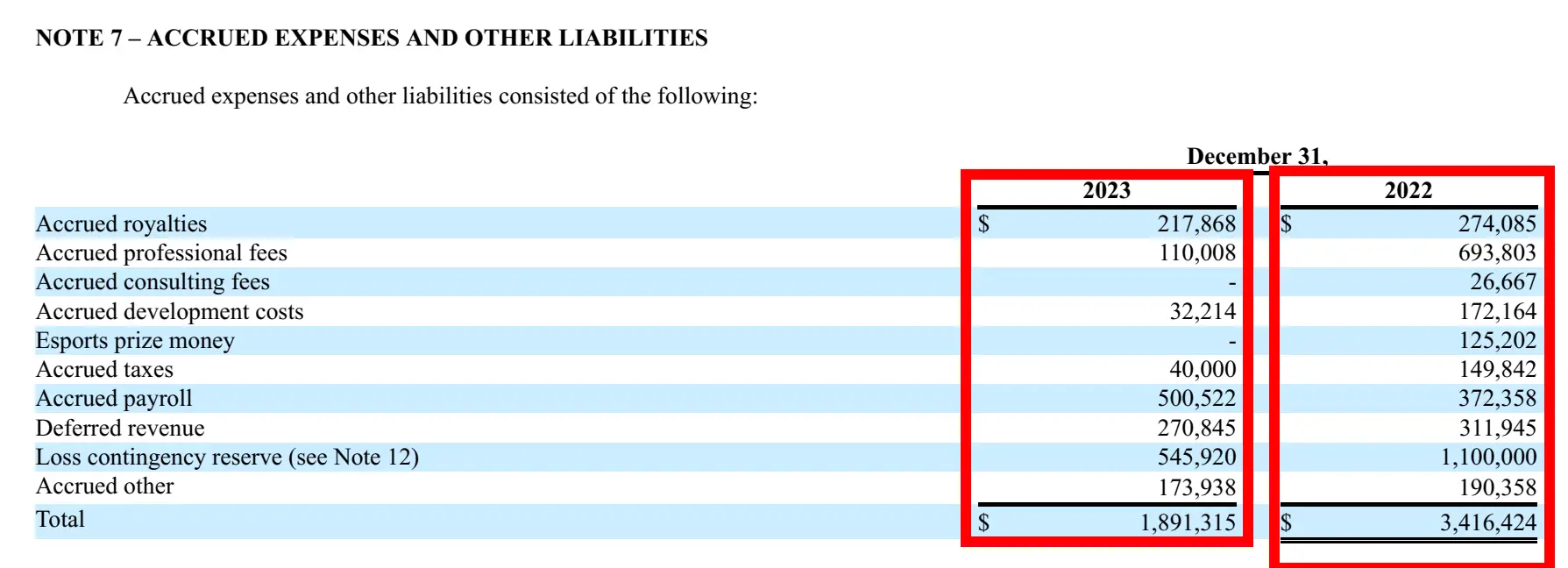
local_query_engine = vector_index.as_query_engine(llm=local_llm, similarity_top_k=3)Query-9
response = local_query_engine.query(
"Summary of chart of Accrued expenses and other liabilities using the financial data of the company"
)
print(str(response))Response
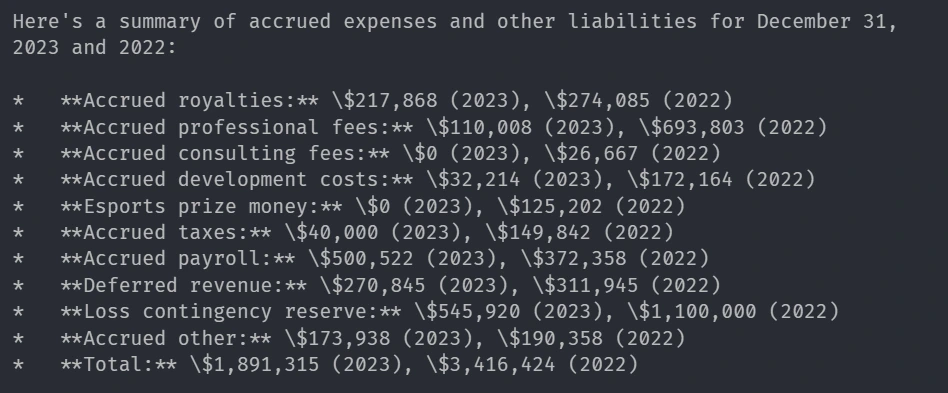
Corresonding image from Report:
Advanced Query Routing with LlamaIndex
Sometimes, we need both detailed retrieval and summarized insights. We can do this by combining both vector index and summary index.
- Vector Index for precise document retrieval
- Summary Index for concise financial summaries
We have already built the Vector Index, now we will create a summary Index that uses a hierarchical approach to summarizing financial statements.
from llama_index.core import SummaryIndex
summary_index = SummaryIndex(nodes=page_nodes)Then integrate RouterQueryEngine, which conditionally decides whether to retrieve data from the summary index or the vector index based on the query type.
from llama_index.core.tools import QueryEngineTool
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelectorNow creating summary query engine
summary_query_engine = summary_index.as_query_engine(
llm=llm, response_mode="tree_summarize", use_async=True
)This summary query engine goes into the summary tool. and the vector query engine into the vector tool.
# Creating summary tool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to Motorsport Games Company."
),
)
# Creating vector tool
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description=(
"Useful for retriving specific context from the Motorsport Games Company."
),
)Both of the tools is done now we connect these tools through Router so that when query ass through the router it will decide which tool to use by analyzing user query.
# Router Query Engine
adv_query_engine = RouterQueryEngine(
llm=llm,
selector=LLMSingleSelector.from_defaults(llm=llm),
query_engine_tools=[summary_tool, vector_tool],
verbose=True,
)Our advanced query system is fully set up, now query our newly favored advanced query engine.
Query-10
response = adv_query_engine.query(
"Summarize the charts describing the revenure of the company."
)
print(str(response))Response

You can see that our intelligent router will decide to use the summary tool because in the query user asks for summary.
Query-11
response = adv_query_engine.query("What is the Total Assets of the company Yearwise?")
print(str(response))Response
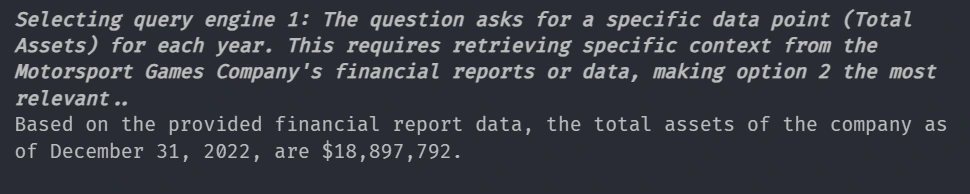
And here the Router selects Vector tool because the user asks for specific information, not summary.
All the code used in this article is here
Conclusion
We can efficiently analyze the financial reports with LlamaIndex, ChromaDB and Advanced LLMs. This system enables automated financial insights, real-time querying, and powerful summarization. This type of system makes financial analysis more accessible and efficient to take better decisions during investing, trading, and doing business.
Key Takeaways
- LLM powered document retrieval system can drastically reduce the time spent on analyzing complex financial reports.
- A hybrid approach using cloud and local LLMs ensures a cost-effective, privacy, and flexible way to design a system.
- LlamaIndex’s modular framework allows for an easy way to automate the financial report rag workflows
- This type of system can be adapted for different domains such as legal documents, medical reports and regulatory filing, which makes it a versatile RAG solution.
Frequently Asked Questions
Q1. How does the system handles different financial reports?
A. The system is designed to process any structured financial documents by breaking them into text chunks, embedding them and storing them in ChromaDB. New reports can be added dynamically without requiring a complete re-indexing.
Q2. Can this be extended to generate financial charts and visualizations?
A. Yes, by integrating Matplotlib, Pandas and Streamlit, you can visualize trends such as revenue growth, net loss analysis, or asset distribution.
Q3. How does the query routing system improve accuracy?
A. The RouterQueryEngine automatically detects whether a query requires a summarized response or specific financial data retrieval. This reduces irrelevant outputs and ensures precision in responses.
Q4. In this system suitable for real-time financial analysis?
A. It can, but it depends on how frequently the vector store is updated. You can use OpenAI embedding API for continuous ingestion pipeline for real-time financial report query dynamically.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A self-taught, project-driven learner, love to work on complex projects on deep learning, Computer vision, and NLP. I always try to get a deep understanding of the topic which may be in any field such as Deep learning, Machine learning, or Physics. Love to create content on my learning. Try to share my understanding with the worlds.






