Businesses today handle a large volume of queries from customers, sales teams, and internal stakeholders. Manually responding to these queries is a slow and inefficient process, often leading to delays and inconsistent answers. A query resolution system powered by AI ensures fast, accurate, and scalable responses. It works by retrieving relevant information and generating precise answers using Retrieval-Augmented Generation (RAG). In this article, I will be sharing with you my journey of building a RAG-based query resolution system using LangChain, ChromaDB, and CrewAI.
Table of Contents
Why Do We Need an AI-powered Query Resolution System?
Now, manual responses take time and may, therefore, lead to delays. Customers expect instant replies, and businesses need quick access to accurate information. An AI-driven system automates query handling, reducing workload and improving consistency. It enhances productivity, speeds up decision-making, and provides reliable responses across different sectors.
An AI-powered query resolution system is useful in customer support, where it automates responses and improves customer satisfaction. In sales and marketing, it provides real-time product details and customer insights. Industries like finance, healthcare, education, and e-commerce benefit from automated query handling, ensuring smooth operations and better user experiences.
Understanding the RAG Workflow
Before diving into the implementation, let’s first understand how a Retrieval-Augmented Generation (RAG) system works.
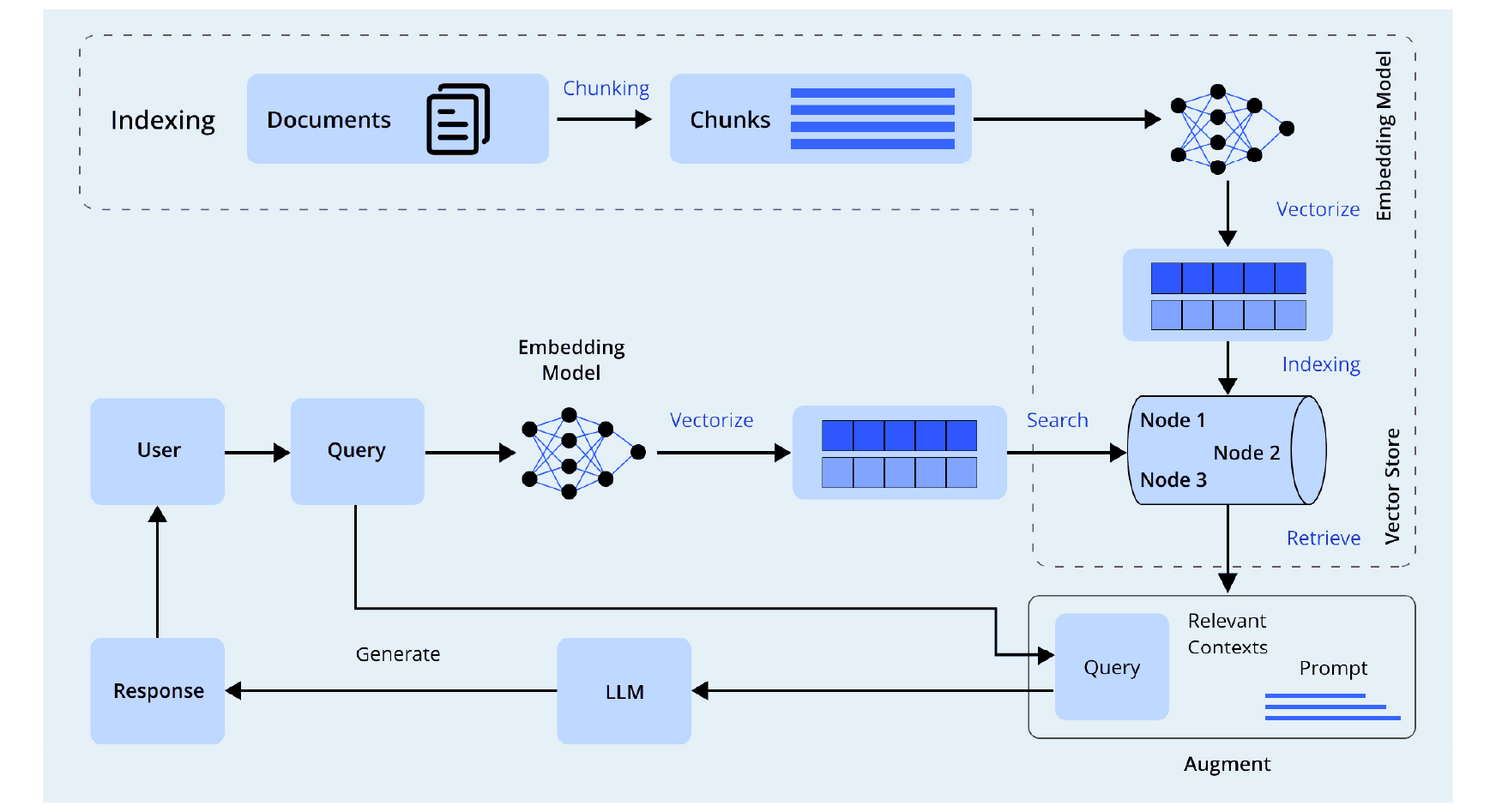
The architecture consists of three key stages: Indexing, Retrieval, and Generation.
1. Building a Vector Store (Document Processing & Storage)
The system first processes and stores relevant documents to make them easily searchable. Here’s how the indexing process works:
- Documents & Chunking: Large documents are broken into smaller text chunks for efficient retrieval.
- Embedding Model: These text chunks are converted into vector representations using an AI-based embedding model.
- Vector Store: The vectorized data is indexed and stored in a database (e.g., ChromaDB) for fast lookup.
2. Query Processing & Retrieval
When a user submits a query, the system retrieves relevant data before generating a response. Here are the steps involved in query processing and retrieval:
- User Query Input: The user submits a question or request.
- Vectorization: The query is converted into a numerical vector using the embedding model.
- Search & Retrieval: The system searches for the most relevant chunks in the vector store and retrieves them.
3. Augmentation & Response Generation
To generate a well-informed response, the system augments the query with retrieved data. Given below are the steps involved in response generation.
- Augment Query: The retrieved document chunks are combined with the original query.
- LLM Processing: A large language model (LLM) generates a final response using both the query and the retrieved context.
- Final Response: The system provides a factual and context-aware answer to the user.
Now that you know how RAG systems work, let’s learn how to build a RAG-based query resolution system.
Building a RAG-based Query Resolution System
In this article, I will walk you through building a RAG-based Query Resolution System that efficiently answers learner queries using an AI agent. To keep things simple, I will demonstrate a simplified version of the project and explain how it works.
Before we get into the hands-on, here’s a preview of how we are going to build our RAG-based query resolution system with LangChain and CrewAI.
Selecting the Right Data for Query Resolution
Before building a RAG-based query resolution system, the most important factor to consider is data – specifically, the types of data required for effective retrieval. A well-structured knowledge base is essential, as the accuracy and relevance of responses depend on the quality of the data available. Below are the key data types that should be considered for different purposes:
- Customer Support Data: FAQs, troubleshooting guides, product manuals, and past customer interactions.
- Sales & Marketing Data: Product catalogs, pricing details, competitor analysis, and customer inquiries.
- Internal Knowledge Base: Company policies, training documents, and standard operating procedures (SOPs).
- Financial & Legal Documents: Compliance guidelines, financial reports, and regulatory policies.
- User-Generated Content: Forum discussions, chat logs, and feedback forms that provide real-world user queries.
Selecting the right data sources was crucial for our learner query resolution system, to ensure accurate and relevant responses. Initially, I experimented with different types of data to determine which provided the best results. First, I used PowerPoint slides (PPTs), but they didn’t yield comprehensive answers as expected. Next, I incorporated common queries, which improved response accuracy but lacked sufficient context. Then, I tested past discussions, which helped in making responses more relevant by leveraging previous learner interactions. However, the most effective approach turned out to be using subtitles from course videos, as they provided structured and detailed content directly related to learner queries. This approach helps in providing quick and relevant answers, making it useful for e-learning platforms and educational support systems.
Structuring the Query Resolution System
Before coding, it is important to structure the Query Resolution System. The best way to do this is by defining the key tasks it needs to perform.
The system will handle three main tasks:
- Extract and store course content from subtitles (SRT files).
- Retrieve relevant course materials based on learner queries.
- Use an AI-powered agent to generate structured responses.
To achieve this, the system is divided into three components, each handling a specific function. This ensures efficiency and scalability.
The system consists of:
- Subtitle Processing – Extracts text from SRT files, processes it, and stores embeddings in ChromaDB.
- Retrieval – Searches and retrieves relevant course materials based on learner queries.
- Query Answering Agent – Uses CrewAI to generate structured and accurate responses.
Each component ensures efficient query resolution, personalized responses, and smooth content retrieval. Now that we have our structure, let’s move on to implementation.
Implementation Steps
Now that we have our structure, let’s move on to implementation.
1. Importing Libraries
To build the AI-powered learning support system, we first need to import essential libraries.
import pysrt
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from crewai import Agent, Task, Crew
import pandas as pd
import astLet’s understand these libraries.
- pysrt – For extracting text from SRT subtitle files.
- langchain.text_splitter.RecursiveCharacterTextSplitter – Splits large text into smaller chunks for better retrieval.
- langchain.schema.Document – Represents structured text documents.
- langchain.embeddings.OpenAIEmbeddings – Converts text into numerical vectors for similarity searches.
- langchain.vectorstores.Chroma – Stores embeddings in a vector database for efficient retrieval.
- crewai (Agent, Task, Crew) – Defines AI agents that process learner queries.
- pandas – Handles structured data in the form of DataFrames.
- ast – Helps in parsing string-based data structures into Python objects.
- os – Provides system-level operations like reading environment variables.
- tqdm – Displays progress bars during long-running tasks.
2. Setting Up the Environment
To use OpenAI’s API for embeddings, we must load the API key and configure the model settings.
Step 1: Read the API key from a local text file.
with open('/home/janvi/Downloads/openai.txt', 'r') as file:
openai_api_key = file.read()Step 2: Store the API key as an environment variable so it can be accessed by other components.
os.environ['OPENAI_API_KEY'] = openai_api_key
Step3: Specify the OpenAI model to be used for processing embeddings.
os.environ["OPENAI_MODEL_NAME"] = 'gpt-4o-mini'
By setting up these configurations, we ensure seamless integration with OpenAI’s API, allowing our system to process and store embeddings efficiently.
3. Extracting and Storing Subtitle Data
Subtitles often contain valuable insights from video lectures, making them a rich source of structured content for AI-based retrieval systems. Extracting and processing subtitle data effectively allows for efficient search and retrieval of relevant information when answering learner queries.
Step 1: Extracting Text from SRT Files
To preserve educational insights, we are using pysrt to read and preprocess text from SRT files. This ensures the extracted content is structured and ready for further processing and storage..
def extract_text_from_srt(srt_path):
"""Extracts text from an SRT subtitle file using pysrt."""
subs = pysrt.open(srt_path)
text = " ".join(sub.text for sub in subs)
return textSince courses may have multiple subtitle files, we systematically organize and iterate through course materials stored in predefined folders. This allows for seamless text extraction and further processing.
# Define course names and their respective folder paths
course_folders = {
"Introduction to Deep Learning using PyTorch": "C:\M\Code\GAI\Learn_queries\Subtitle_Introduction_to_Deep_Learning_Using_Pytorch",
"Building Production-Ready RAG systems using LlamaIndex": "C:\M\Code\GAI\Learn_queries\Subtitle of Building Production-Ready RAG systems using LlamaIndex",
"Introduction to LangChain - Building Generative AI Apps & Agents": "C:\M\Code\GAI\Learn_queries\Subtitle_introduction_to_langchain_using_agentic_ai"
}
# Dictionary to store course names and their respective .srt file paths
course_srt_files = {}
# Iterate through course folder mappings
for course, folder_path in course_folders.items():
srt_files = []
# Walk through the directory to find .srt files
for root, _, files in os.walk(folder_path):
srt_files.extend(os.path.join(root, file) for file in files if file.endswith(".srt"))
# Add to dictionary if there are .srt files
if srt_files:
course_srt_files[course] = srt_filesThis extracted text forms the foundation of our AI-driven learning support system, enabling advanced retrieval and query resolution.
Step 2: Storing Subtitles in ChromaDB
In this part, we will break down the process of storing course subtitles in ChromaDB, including text chunking, embedding generation, persistence, and cost estimation.
a. Persistent Directory for ChromaDB
The persist_directory is a folder path where the stored data will be saved, allowing us to retain embeddings even after restarting the program. Without this, the database would reset after each execution.
persist_directory = "./subtitles_db"
ChromaDB is used as a vector database to store and retrieve embeddings efficiently.
b. Splitting Text into Smaller Chunks
Large documents (like entire course subtitles) exceed token limits for embeddings. To handle this, we use RecursiveCharacterTextSplitter to break text into smaller, overlapping chunks to improve search accuracy.
# Text splitter to break documents into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)Each chunk is 1,000 characters long, ensuring that the text is broken into manageable pieces. To maintain context between chunks, 200 characters from the previous chunk are included in the next one. This overlap helps preserve important details and improves retrieval accuracy.
c. Initializing OpenAI Embeddings and ChromaDB Vector Store
We need to convert text into numerical vector representations for similarity search. OpenAI’s embeddings allow us to encode our course content into a format that can be searched efficiently.
# Initialize OpenAI embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)Here, OpenAIEmbeddings() initializes the embedding model using our OpenAI API key (openai_api_key). This ensures that every text chunk gets converted into a high-dimensional vector representation.
d. Initializing ChromaDB
Now, we store these vector embeddings in ChromaDB.
# Initialize Chroma vectorstore with persistent directory
vectorstore = Chroma(
collection_name="course_materials",
embedding_function=embeddings,
persist_directory=persist_directory
)
The collection_name=”course_materials” creates a dedicated collection in ChromaDB to organize all course-related embeddings. The embedding_function=embeddings specifies OpenAI embeddings for converting text into numerical vectors. The persist_directory=persist_directory ensures that all stored embeddings remain available in ./subtitles_db/, even after restarting the program.
Step 3: Estimating Cost of Storing Course Data
Before adding documents to the vector database, it is essential to estimate the cost of token usage. Since OpenAI charges per 1,000 tokens, we calculate the expected cost to manage expenses efficiently.
a. Defining Pricing Parameters
Since OpenAI charges per 1,000 tokens, we estimate the cost before adding documents.
import time
# OpenAI Pricing (adjust based on the model being used)
COST_PER_1K_TOKENS = 0.0001 # Cost per 1K tokens for 'text-embedding-ada-002'
TOKENS_PER_CHUNK_ESTIMATE = 750 # Approximate tokens per 1000-character chunk
# Track total tokens and cost
total_tokens = 0
total_cost = 0
# Start timing
start_time = time.time()
The COST_PER_1K_TOKENS = 0.0001 defines the cost per 1,000 tokens when using OpenAI embeddings. The TOKENS_PER_CHUNK_ESTIMATE = 750 estimates that each 1,000-character chunk contains about 750 tokens. The total_tokens and total_cost variables track the total processed data and cost incurred during execution. The start_time variable records the starting time to measure how long the process takes.
b. Checking and Adding Courses to ChromaDB
We want to avoid reprocessing courses that are already stored in the vector database. So for that we are querying ChromaDB to check if the course already exists. If the course is not found, we extract and store its subtitle data.
# Add new courses to the vectorstore if they don't already exist
for course, srt_list in course_srt_files.items():
# Check if the course already exists in the vectorstore
existing_docs = vectorstore._collection.get(where={"course": course})
if not existing_docs['ids']:
# Course not found, add it
srt_texts = [extract_text_from_srt(srt) for srt in srt_list]
course_text = "\n\n\n\n".join(srt_texts) # Join SRT texts with four new lines
doc = Document(page_content=course_text, metadata={"course": course})
chunks = text_splitter.split_documents([doc])The subtitles are extracted using the extract_text_from_srt() function. Multiple subtitle files are then joined together using \n\n\n\n to improve readability. A Document object is created, storing the full subtitle text along with its metadata. Finally, the text is split into smaller chunks using text_splitter.split_documents() for efficient processing and retrieval.
c. Estimating Token Usage and Cost
Before adding the chunks to ChromaDB, we estimate the cost.
# Estimate cost before adding documents
chunk_count = len(chunks)
batch_tokens = chunk_count * TOKENS_PER_CHUNK_ESTIMATE
batch_cost = (batch_tokens / 1000) * COST_PER_1K_TOKENS
total_tokens += batch_tokens
total_cost += batch_costThe chunk_count represents the number of chunks generated after splitting the text. The batch_tokens estimates the total number of tokens based on the chunk count. The batch_cost calculates the estimated cost for processing the current course. The total_tokens and total_cost accumulate values across all courses to track overall processing and expenses.
d. Adding Chunks to ChromaDB
vectorstore.add_documents(chunks)
print(f"Added course: {course} (Chunks: {chunk_count}, Cost: ${batch_cost:.4f})")
else:
print(f"Course already exists: {course}")The processed chunks are stored in ChromaDB for efficient retrieval. A message is displayed, indicating the number of chunks added and the estimated processing cost.
Once all courses are processed, we calculate and display the final results.
# End timing
end_time = time.time()
# Display cost and time
print(f"\nCourse Embeddings Update Completed! 🚀")
print(f"Total Chunks Processed: {total_tokens // TOKENS_PER_CHUNK_ESTIMATE}")
print(f"Estimated Total Tokens: {total_tokens}")
print(f"Estimated Cost: ${total_cost:.4f}")
print(f"Total Time Taken: {end_time - start_time:.2f} seconds")
The total processing time is calculated using (end_time – start_time). The system then displays the number of chunks processed, the estimated token usage, and the overall cost. Finally, it provides a summary of the entire embedding process.
Output:

From the output, we can see that a total of 739 chunks were processed in 10 seconds, with an estimated cost of $0.0554.
4. Querying and Responding to Learner Queries
Once the subtitles are stored in ChromaDB, the system needs a way to retrieve relevant content when a learner submits a query. This retrieval process is handled using similarity search, which identifies stored text segments which are most relevant to the input query.
How it Works:
- Query Input: The learner submits a question related to the course.
- Filtering by Course: The system ensures that retrieval is restricted to the relevant course material.
- Similarity Search in ChromaDB: The query is converted into an embedding, and ChromaDB retrieves the most similar stored text chunks.
- Returning the Top Results: The system selects the top three most relevant text segments.
- Formatting the Output: The retrieved text is formatted and presented as context for further processing.
# Define retrieval tool with metadata filtering
def retrieve_course_materials(query: str, course = course):
"""Retrieves course materials filtered by course name."""
filter_dict = {"course": course}
results = vectorstore.similarity_search(query, k=3, filter=filter_dict)
return "\n\n".join([doc.page_content for doc in results])Example queries:
course_name = "Introduction to Deep Learning using PyTorch"
question = "What is gradient descent?"
context = retrieve_course_materials(query=question, course= course_name)
print(context)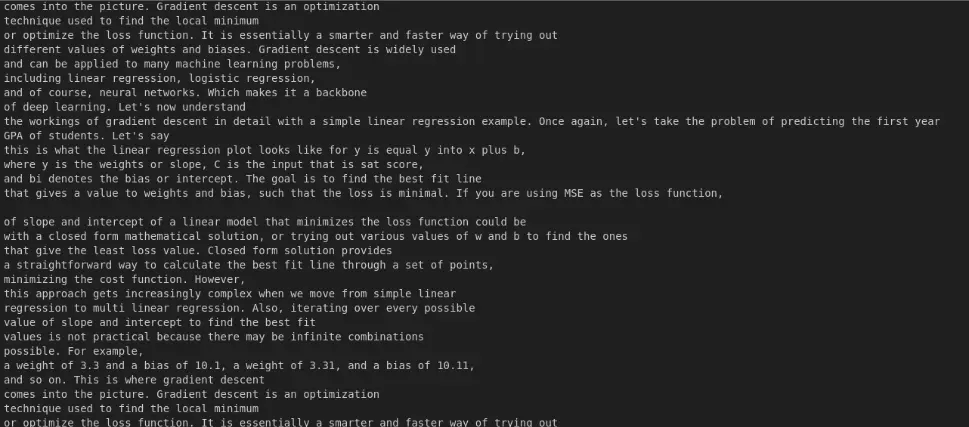
The output consists of the retrieved content from ChromaDB, filtered by course name and question, using similarity search to find the most relevant information.
Why is Similarity Search Used?
- Semantic Understanding: Unlike keyword searches, similarity search finds text semantically related to the query.
- Efficient Retrieval: Instead of scanning entire documents, the system retrieves only the most relevant parts.
- Improved Answer Quality: By filtering by course and ranking results by relevance, learners receive highly targeted content.
This mechanism ensures that when a learner submits a question, they receive relevant and contextually accurate information from stored course materials.
5. Implementing the AI Query Answering Agent
Once relevant course material is retrieved from ChromaDB, the next step is to use an AI-powered agent to formulate meaningful responses to learner queries. CrewAI is used to define an intelligent agent responsible for analyzing queries and generating well-structured responses.
Now, let’s see how it works.
Step 1: Defining the Agent
The query answering agent is created with a clear role and backstory to guide its behavior when responding to learner queries.
# Define the agent with a well-structured role and backstory
query_answer_agent = Agent(
role = "Learning Support Specialist",
goal = "You help learners with their queries with the best possible response",
backstory = """You lead the Learners Query resolution department of
an Ed tech company focussed on self paced courses on topics related to
Data Science, Machine Learning and Generative AI. You respond to learner
queries related to course content, assignments, technical and administrative issues.
You are polite, diplomatic and take ownership of things which could be
imporved in your oragnisation.
""",
verbose = False,
)
Let’s understand what is happening in the code block. Firstly, we are providing the role as Learning Support Specialist since the agent acts as a virtual tutor that answers student queries. Then, we define the goal, ensuring that the agent prioritizes accuracy and clarity in its responses. Lastly, we set verbose=False, which keeps the execution silent unless debugging is needed. This well-defined agent role ensures that responses are helpful, structured, and aligned with the educational platform’s tone.
Step 2: Defining the Task
After defining the agent, we need to assign it a task
query_answering_task = Task(
description= """
Answer the learner queries to the best of your abilities. Try to keep your response concise with less than 100 words.
Here is the query: {query}
Here is similar content from the course extracted from subtitles, which you should use only when required: {relevant_content} .
Since this content is extracted from course subtitles, there may be spelling errors, make sure to correct these, while using this information in your response.
There may be some previous discussion with the learner on this thread. Here is the python list of past discussions: {thread} .
In this thread, the content which starts with 'learner' is the question by the student and the content which starts with 'support'
is the response given by you. Use this past discussion appropriatly to come with a great reply.
This is the full name of the learner: {learner_name}
Address each learner by their first name, if you are not sure what the first name is, simply start with Hi.
Also mention some appropriate and encouraging comforting lines at the end of the reponse, like "hope you found this helpful",
"I hope this information is useful. Keep up the great work!", "Glad to assist! Feel free to reach out anytime." etc.
If you are not sure about the answer mention - "Sorry, I am not sure about this, I will get back to you"
""",
expected_output = "A crisp accurate response to the query",
agent=query_answer_agent)
Let’s break down the task provided to the AI agent. The query handling involves processing {query}, which represents the learner’s question. The response should be concise (under 100 words) and accurate. When using course content, {relevant_content} is extracted from subtitles stored in ChromaDB, and the AI must correct any spelling errors before including the content in its response.
If past discussions exist, {thread} helps maintain continuity. Learner queries start with “learner”, while past responses begin with “support”, allowing the agent to provide context-aware answers. Personalization is achieved using {learner_name}—the agent addresses students by their first name or defaults to “Hi” if uncertain.
To make responses more engaging, the AI adds a positive closing statement, such as “Hope you found this helpful!” or “Feel free to reach out anytime.” If the AI is unsure about an answer, it explicitly states: “Sorry, I am not sure about this, I will get back to you.” This approach ensures politeness, clarity, and a structured response format, enhancing learner engagement and trust.
Step 3: Initializing the CrewAI Instance
Now that we have both the agent and the task, we initialize CrewAI, which enables the agent to process queries dynamically.
# Create the Crew
response_crew = Crew(
agents=[query_answer_agent],
tasks=[query_answering_task],
verbose=False
)
The agents=[query_answer_agent] parameter adds the Learning Support Specialist agent to the crew. The tasks=[query_answering_task] assigns the query answering task to this agent. Setting verbose=False keeps the output minimal unless debugging is needed. CrewAI enables the system to process multiple learner queries simultaneously, making it scalable and efficient for dynamic query handling.
Why Use CrewAI for Query Answering?
- Structured Responses: Ensures that each response is well-organized and informative.
- Context Awareness: Utilizes retrieved course material and past discussions to improve response quality.
- Scalability: Can handle multiple queries dynamically by processing them as tasks within CrewAI.
- Efficiency: Reduces response time by streamlining the query resolution workflow.
By implementing this AI-powered answering system, learners receive well-informed responses tailored to their specific queries.
Step 4: Generating Responses for Multiple Learner’s Queries
Once the AI agent is set up, it needs to dynamically process learner queries stored in a structured dataset.
The below code processes learner queries stored in a CSV file and generates responses using an AI agent. It first loads the dataset containing learner queries, course details, and discussion threads. The reply_to_query function extracts relevant details like the learner’s name, course name, and current query. If previous discussions exist, they are retrieved for context. If the query contains an image, it is skipped. The function then fetches related course materials from ChromaDB and sends the query, relevant content, and past discussions to the AI agent for generating a structured response.
df = pd.read_csv(filepath_or_buffer='C:\M\Code\GAI\Learn_queries/filtered_data_top3_courses.csv')
def reply_to_query(df_new=df_new, index=1):
learner_name = df_new.iloc[index]["thread_starter"]
course_name = df_new.iloc[index]["course"]
if df_new.iloc[index]['number_of_replies']>1:
thread = ast.literal_eval(df_new.iloc[index]["modified_thread"])
else:
thread = []
question = df_new.iloc[index]["current_query"]
if df_new.iloc[index]['has_image'] == True:
return " "
context = retrieve_course_materials(query = question , course=course_name)
response_result = response_crew.kickoff(inputs={"query": question, "relevant_content": context, "thread": thread, "learner_name": learner_name})
print('Q: ', question)
print('\n')
print('A: ', response_result)
print('\n\n')Testing the function, it is executed for one query (index=1)
reply_to_query(df, index=1)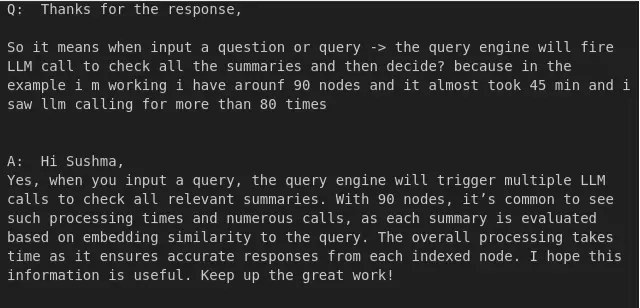
From this we can see that it works fine just for one index.
Now, iterating through all queries, processing each one while handling potential errors. This ensures efficient automation of query resolution, allowing multiple learner queries to be processed dynamically.
for i in range(len(df)):
try:
reply_to_query(df, index=i)
except:
print("Error in index number: ", i)
continueWhy is This Step Important?
- Automates Query Processing: The system can handle multiple learner queries efficiently.
- Ensures Contextual Relevance: Responses are generated based on retrieved course materials and past discussions.
- Scalability: The method allows the AI agent to process and respond to thousands of queries dynamically.
- Improved Learning Support: Learners receive personalized, data-driven responses to their queries.
This step ensures that every learner query is analyzed, contextualized, and answered effectively, enhancing the overall learning experience.
Output:
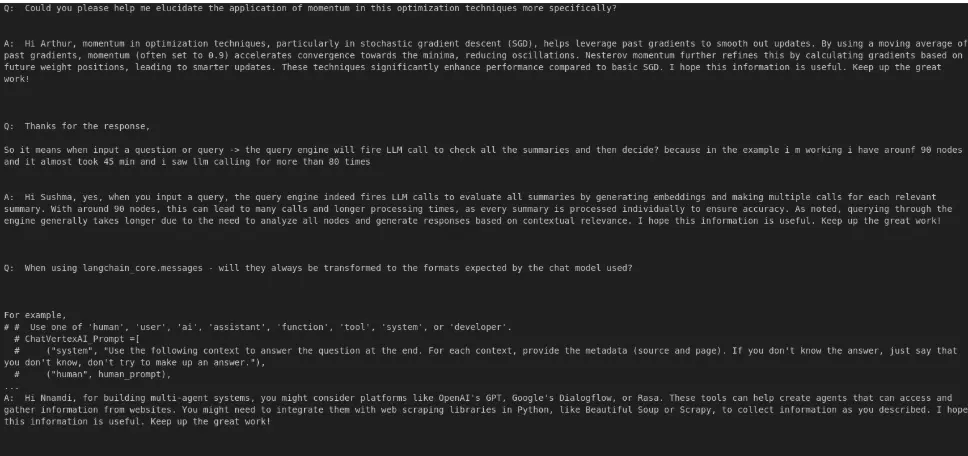
From the output we can see that the process of replying to the query has become automated, followed by question and then answer.
Future Improvements
To upgrade the RAG-Based Query Resolution System, several enhancements can be made:
- Common Questions and Their Solutions: Implementing a structured FAQ system within the query resolution framework will help in providing instant answers to frequently asked questions, reducing dependency on live support.
- Image Processing Ability: Adding the capability to analyze and extract relevant information from images (such as screenshots, charts, or scanned documents) will enhance the system’s versatility, making it more useful in educational and customer support domains.
- Improving the Image Column Boolean: Refining the logic behind the image column detection to correctly identify and process image-based queries with greater accuracy.
- Semantic Chunking and Different Chunking Techniques: Experimenting with various chunking strategies, such as semantic chunking, fixed-length segmentation, and hybrid approaches, can improve retrieval accuracy and contextual understanding of responses.
Conclusion
This RAG-Based Query Resolution System leverages LangChain, ChromaDB, and CrewAI to automate learner support efficiently. It extracts subtitles, stores them as embeddings in ChromaDB, and retrieves relevant content using similarity search. A CrewAI agent processes queries, references past discussions, and generates structured responses, ensuring accuracy and personalization.
The system enhances scalability, retrieval efficiency, and response quality, making self-paced learning more interactive. Future improvements include multi-modal support, better retrieval optimization, and enhanced response generation. By automating query resolution, this system streamlines learning support, providing learners with faster, context-aware responses and improving overall engagement.
Frequently Asked Questions
Q1. What is LangChain, and why is it used in this project?
A. LangChain is a framework for building applications powered by language models (LLMs). It helps in processing, retrieving, and generating responses from text-based data. In this project, LangChain is used for splitting text into chunks, generating embeddings, and retrieving course materials efficiently.
Q2. How does ChromaDB store and retrieve course content?
A. ChromaDB is a vector database designed for storing and retrieving embeddings. It converts course materials into numerical representations, allowing similarity-based searches to find relevant content when a learner submits a query.
Q3. What role does CrewAI play in answering learner queries?
A. CrewAI enables the creation of AI agents that handle tasks dynamically. In this project, it powers a Learning Support Specialist agent that retrieves course materials, processes past discussions, and generates structured responses for learner queries.
Q4. Why are OpenAI embeddings used for text processing?
A. OpenAI embeddings convert text into numerical vectors, making it easier to perform similarity searches. This helps in efficiently retrieving relevant course materials based on a learner’s query.
Q5. How does the system process subtitles (SRT files)?
A. The system uses pysrt to extract text from subtitle (SRT) files. The extracted content is then chunked, embedded using OpenAI embeddings, and stored in ChromaDB for retrieval when needed.
Q6. Can this system handle multiple queries at once?
A. Yes, the system is scalable and can process multiple learner queries dynamically using CrewAI’s task management. This ensures quick and efficient responses.
Q7. What future improvements can be made to this system?
A. Future enhancements include multi-modal support for images and videos, better retrieval optimization, and improved response generation techniques to provide even more accurate and contextual answers.
Hi, I am Janvi, a passionate data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.


