In the fast-paced world of academic research, efficiently gathering, synthesizing, and presenting information is crucial. Manually sourcing and summarizing literature can be tedious, diverting researchers from deeper analysis and discovery. This is where a Multi-Agent Research Assistant System using Pydantic comes in—an intelligent architecture where specialized agents collaborate to handle complex tasks with modularity and scalability. However, managing multiple agents introduces challenges in data consistency, validation, and structured communication. Multi-Agent Research Assistant Systems using Pydantic provide a solution by enforcing clear data schemas, ensuring robust handling, and reducing system complexity.
In this blog, we’ll walk through building a structured multi-agent research assistant using Pydantic, integrating tools like Pydantic-ai and arxiv, with step-by-step code explanations and expected outcomes.
Learning Objectives
- Understand the role of structured data modeling in a Multi-Agent Research Assistant System using Pydantic to ensure reliable and consistent communication among intelligent agents.
- Define and implement clear, structured data schemas using Multi-Agent Research Assistant Systems using Pydantic for seamless integration, modular agent orchestration, and efficient automated research workflows.
- Design and orchestrate modular agents, each responsible for specific tasks such as query refinement, data retrieval, keyword extraction, and summarization.
- Integrate external APIs (like arXiv) seamlessly into automated workflows using structured agent interactions.
- Generate professional-quality outputs (e.g., PDF reports) directly from structured agent outputs, significantly enhancing the practical usability of your automated research workflows.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Defining Clear Data Models with Pydantic
- Structuring the Multi-Agent Framework
- Refining Research Queries with the Prompt Processor Agent
- Fetching Research Papers Efficiently with the Paper Retrieval Agent
- Extracting Valuable Keywords with the Keyword Extraction Agent
- Summarizing Papers Concisely with the Summarization Agent
- Bringing it all Together: Agentic Orchestration
- Generating Professional Outputs with Structured Data
- Multi-Agent System in Action: Practical Examples
- Conclusion
- Frequently Asked Questions
Defining Clear Data Models with Pydantic
In multi-agent systems, clearly defined structured data models are foundational. When multiple intelligent agents interact, each agent depends on receiving and sending well-defined, predictable data. Without a structured schema, even minor inconsistencies can lead to system-wide errors that are notoriously difficult to debug.
Using Pydantic, we can address this challenge elegantly. Pydantic provides a simple yet powerful way to define data schemas in Python. It ensures data consistency, significantly reduces potential runtime bugs, and facilitates seamless validation at every step of an agent’s workflow.
Below is a practical example of defining structured data models using Pydantic, which our agents will use for clear communication:
from pydantic import BaseModel, Field
class PaperMetadata(BaseModel):
title: str = Field(..., description="Title of the paper")
abstract: str = Field(..., description="Abstract of the paper")
authors: list[str] = Field(..., description="List of authors")
publication_date: str = Field(..., description="Publication date")Explanation of Each Field
- title : The title of the retrieved research paper. It’s vital for quick reference, organizing, and display purposes by various agents.
- abstract : Contains a concise summary or abstract provided by the paper’s authors. This abstract is crucial for keyword extraction and summarization agents.
- authors : Lists the authors of the paper. This metadata can assist in further queries, author-specific analyses, or citation tracking.
- publication_date : Represents the date the paper was published or submitted. This is important for sorting, filtering, and ensuring recency in research.
Each agent in our multi-agent system relies on these structured fields. Let’s briefly introduce the agents we’ll build around this data model. In our system, we’ll design five specialized agents:
- Prompt Processor Agent
- Paper Retrieval Agent
- Keyword Extraction Agent
- Summarization Agent
- Router (Orchestrator) Agent
Each agent communicates seamlessly by passing data structured precisely according to the models we’ve defined using Pydantic. This clear structure ensures that each agent’s input and output are predictable and validated, significantly reducing runtime errors and enhancing system robustness.
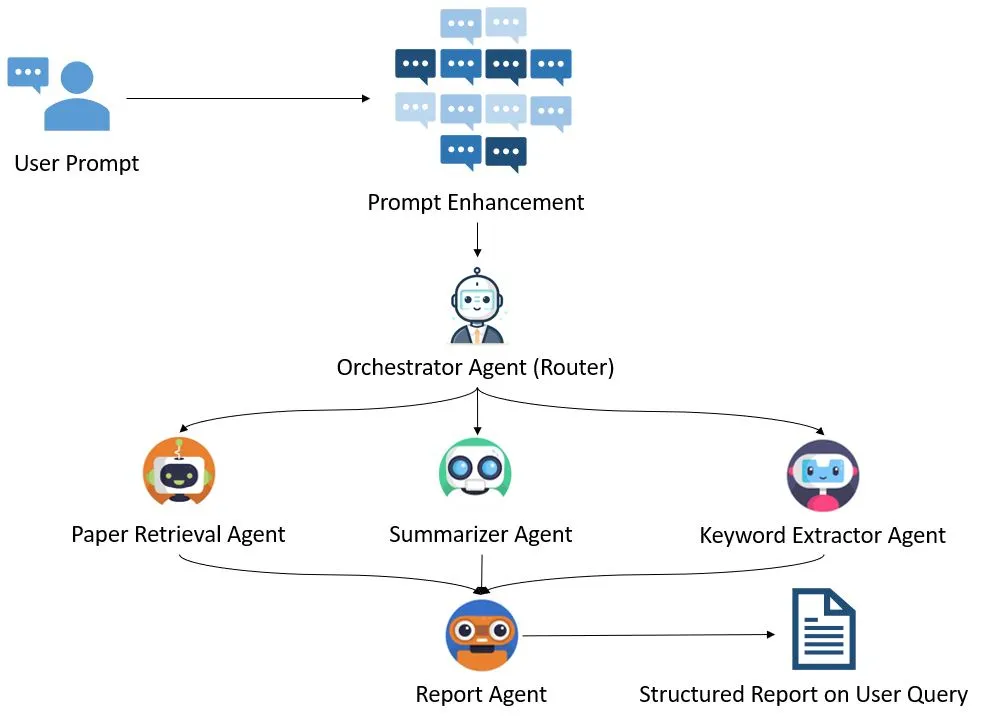
Next, we’ll dive deeper into each agent, clearly explaining their implementation, role, and expected outputs.
Structuring the Multi-Agent Framework
With clear and validated data models defined using Pydantic, we now turn to the design and structure of our multi-agent framework. Each agent in our framework has a dedicated responsibility and interacts seamlessly with other agents to perform complex tasks collaboratively.
In our system, we have defined five specialized agents, each serving a clear and distinct role:
Prompt Processor Agent
The Prompt Processor Agent is the first step in the workflow. Its primary responsibility is to take a user’s raw input or query (such as “AI agents in reinforcement learning”) and refine it into a more precise, structured search query. This refinement significantly improves the relevance of results returned by external research databases.
Responsibilities:
- Receives the user’s initial query.
- Generates a refined and structured search query for maximum relevance.
Paper Retrieval Agent
The Paper Retrieval Agent receives the refined query from the Prompt Processor. It communicates directly with external academic databases (like arXiv) to retrieve a list of relevant academic papers based on the refined query.
Responsibilities:
- Interacts with external APIs (e.g., arXiv API).
- Retrieves a structured list of papers, each represented using the PaperMetadata model.
Keyword Extraction Agent
Upon receiving paper abstracts, the Keyword Extraction Agent automatically identifies and extracts the most relevant keywords. These keywords help researchers quickly assess the focus and relevance of each paper.
Responsibilities:
- Extracts meaningful keywords from abstracts.
- Facilitates quick assessment and categorization of papers.
Summarization Agent
The Summarization Agent takes each paper’s abstract and generates concise, informative summaries. Summaries provide researchers with quick insights, saving substantial reading time and effort.
Responsibilities:
- Produces concise and clear summaries from paper abstracts.
- Enables faster evaluation of paper content relevance.
Router Agent (Orchestrator)
The Router Agent is central to our multi-agent system. It coordinates the entire workflow, managing communication and data flow among all other agents. It initiates the Prompt Processor, passes refined queries to the Paper Retrieval Agent, and further routes paper abstracts to the Keyword Extraction and Summarization agents. Ultimately, the Router compiles all results into a structured final report.
Responsibilities:
- Coordinates interactions and data flow between all agents.
- Manages the asynchronous orchestration of agent workflows.
- Aggregates the outputs (keywords, summaries, paper metadata) into structured final reports.
Brief Explanation of Agent Interactions
Our agents interact in a clear, sequential workflow:
- Prompt Processor Agent receives and refines the user query.
- The refined query is sent to the Paper Retrieval Agent, retrieving relevant papers.
- For each retrieved paper, the Router Agent sends the abstract simultaneously to:
- Once keywords and summaries are generated, the Router Agent compiles and aggregates them into a final structured report.
By structuring our agents this way, we achieve a modular, maintainable, and highly scalable research assistant system. Each agent can be individually enhanced, debugged, or even replaced without impacting the overall system stability. Next, we’ll dive deeper into each agent’s actual implementation details, along with clearly explained code snippets and expected outputs.
Refining Research Queries with the Prompt Processor Agent
When searching vast academic databases like arXiv, the quality and specificity of the query directly influence the relevance and usefulness of returned results. A vague or broad query like “AI agents” might yield thousands of loosely relevant papers, making it challenging for researchers to identify truly valuable content. Thus, it’s crucial to refine initial queries into precise, structured search statements.
The Prompt Processor Agent addresses this exact challenge. Its primary responsibility is to transform the user’s general research topic into a more specific, clearly scoped query. This refinement significantly improves the quality and precision of retrieved papers, saving researchers considerable effort.
Below, we present the implementation of the Prompt Processor, leveraging basic heuristics to create structured queries:
@prompt_processor_agent.tool
async def process_prompt(ctx: RunContext[ResearchContext], topic: str) -> str:
topic = topic.strip().lower()
# Basic heuristic refinement
if ' in ' in topic:
# Split the topic into key parts if it contains 'in', to form precise queries.
subtopics = topic.split(' in ')
main_topic = subtopics[0].strip()
context = subtopics[1].strip()
refined_query = f"all:{main_topic} AND cat:{context.replace(' ', '_')}"
else:
# Fallback: Assume it's a broader topic
refined_query = f"ti:\"{topic}\" OR abs:\"{topic}\""
return refined_query
Explanation of the Improved Implementation
- Input normalization: The agent starts by trimming and converting the input topic to lowercase to ensure consistency.
- Contextual parsing: If the user’s topic includes the keyword “in” (for example, “AI agents in reinforcement learning”), the agent splits it into two clear parts:
- A primary topic (AI agents)
- A specific context or subfield (reinforcement learning)
- Structured query building: Using these parsed components, the agent generates a precise query that explicitly searches the primary topic across all fields (all:) and restricts the search to papers categorized or closely related to the specified context.
- Fallback handling: If the topic does not explicitly include contextual cues, the agent generates a structured query that searches directly within the title (ti:) and abstract (abs:) fields, boosting relevance for general searches.
Expected Output Example
When provided with the user query: “AI agents in reinforcement learning”
The Prompt Processor Agent would output the refined query as: “all:ai agents AND cat:reinforcement_learning“
For a broader query, such as: “multi-agent systems”
The agent’s refined query would be: ‘ti:”multi-agent systems” OR abs:”multi-agent systems“
While this implementation already significantly improves search specificity, there’s room for further sophistication, including:
- Natural Language Processing (NLP) techniques for better semantic understanding.
- Incorporation of synonyms and related terms to expand queries intelligently.
- Leveraging a large language model (LLM) to interpret user intent and form highly optimized queries.
These refined queries are structured to optimize search relevance and retrieve highly targeted academic papers.
Fetching Research Papers Efficiently with the Paper Retrieval Agent
After refining our search queries for maximum relevance, the next step is retrieving appropriate academic papers. The Paper Retrieval Agent serves precisely this role: it queries external academic databases, such as arXiv, to collect relevant research papers based on our refined query.
By integrating seamlessly with external APIs like arXiv’s API, the Paper Retrieval Agent automates the cumbersome manual task of searching and filtering through vast amounts of academic literature. It uses structured data models (defined earlier using Pydantic) to ensure consistent, clean, and validated data flows downstream to other agents, like summarizers and keyword extractors.
Below is a practical example of the Paper Retrieval Agent’s implementation:
@paper_retrieval_agent.tool
async def fetch_papers(ctx: RunContext[ResearchContext]) -> list[PaperMetadata]:
search = arxiv.Search(
query=ctx.deps.query,
max_results=5,
sort_by=arxiv.SortCriterion.SubmittedDate
)
results = list(search.results())
papers = []
for result in results:
published_str = (
result.published.strftime("%Y-%m-%d")
if hasattr(result, "published") and result.published is not None
else "Unknown"
)
paper = PaperMetadata(
title=result.title,
abstract=result.summary,
authors=[author.name for author in result.authors],
publication_date=published_str
)
papers.append(paper)
return papersExplanation of the Implementation
- The agent uses the refined query (ctx.deps.query) received from the Prompt Processor Agent to initiate a search via the arXiv API.
- It specifies max_results=5 to retrieve the five latest papers relevant to the query, sorted by their submission date.
- Each retrieved result from arXiv is structured explicitly into a PaperMetadata object using our previously defined Pydantic model. This structured approach ensures validation and data consistency.
- The structured data is collected into a list and returned, ready for consumption by downstream agents.
Highlighting Pydantic’s Role
Using Pydantic models to structure responses from external APIs provides significant benefits:
- Data validation: Ensures all required fields (title, abstract, authors, publication date) are always provided and correctly formatted.
- Consistency: Guarantees downstream agents receive uniformly structured data, simplifying processing logic.
- Debugging and Maintenance: Structured schemas significantly reduce errors, improving maintainability and simplifying debugging.
Expected Output Example
Upon executing the retrieval agent with a refined query (e.g., “all:ai agents AND cat:reinforcement_learning”), you would expect structured outputs like:
[
{
"title": "Deep Reinforcement Learning with Agentic Systems",
"abstract": "This paper discusses advancements in agentic reinforcement
learning...",
"authors": ["Alice Smith", "John Doe"],
"publication_date": "2025-03-20"
},
{
"title": "Agent Coordination in Reinforcement Learning Environments",
"abstract": "We explore methods for improving multi-agent coordination...",
"authors": ["Jane Miller", "Bob Johnson"],
"publication_date": "2025-03-18"
}
// (three additional similar structured results)
]
Such structured outputs empower further automated analysis by subsequent agents, enabling efficient keyword extraction and summarization.
Extracting Valuable Keywords with the Keyword Extraction Agent
Once relevant papers have been retrieved, efficiently categorizing and summarizing their content is crucial. Researchers often need quick ways to identify the core concepts and key ideas within a large body of literature without having to read every abstract in detail.
This is where Keyword Extraction plays a pivotal role. Automatically extracting keywords from abstracts helps researchers quickly determine the main focus of each paper and identify emerging trends or group-related research more effectively.
The Keyword Extraction Agent explicitly targets this need. Given a paper’s abstract, it identifies a set of essential terms representing the abstract’s content.
Code Snippet (Keyword Extraction Agent):
@keyword_extraction_agent.tool
async def extract_keywords(ctx: RunContext[ResearchContext], abstract: str)
-> KeywordResult:
# Basic keyword extraction logic (placeholder implementation)
words = abstract.split()
seen = set()
unique_words = []
for word in words:
normalized = word.strip('.,;:"()').lower()
if normalized and normalized not in seen:
seen.add(normalized)
unique_words.append(normalized)
if len(unique_words) >= 5:
break
return KeywordResult(keywords=unique_words)
Explanation of the Implementation
- The agent takes the paper abstract as input.
- It splits the abstract text into individual words, normalizing them to remove punctuation and converting them to lowercase.
- It then gathers the first five unique words as keywords. This is a simplified implementation intended to demonstrate keyword extraction clearly.
- Finally, it returns a structured KeywordResult containing these extracted keywords.
Highlighting Pydantic’s Benefit
By using Pydantic’s clearly defined schema (KeywordResult), keyword outputs remain structured and consistent, making it simple for downstream agents (like the summarization or orchestration agents) to consume this data without ambiguity.
Expected Output Example
Given a sample abstract:
"This paper discusses advancements in agentic reinforcement learning,
focusing on deep learning techniques for enhancing agent cooperation."The Keyword Extraction Agent would produce an output like:
["this", "paper", "discusses", "advancements"]Note: This simplistic extraction logic is a placeholder demonstrating basic keyword extraction. Actual production implementations would typically employ more advanced Natural Language Processing (NLP) techniques (such as TF-IDF, RAKE, or language model-based extraction) to generate keywords of higher relevance.
Summarizing Papers Concisely with the Summarization Agent
In an academic research environment, time efficiency is critical. Researchers often face an overwhelming number of papers and abstracts. Automated summaries allow quick scanning and identification of the most relevant research without reading through entire abstracts or papers.
The Summarization Agent tackles this challenge directly. It generates concise and meaningful summaries from the paper abstracts, enabling researchers to rapidly determine each paper’s relevance and decide whether deeper investigation is warranted.
Code Snippet (Summarization Agent)
@summary_agent.tool
async def summarize_paper(ctx: RunContext[ResearchContext], abstract: str)
-> PaperSummary:
summary_text = abstract[:150] + "..." if len(abstract) > 150 else abstract
return PaperSummary(summary=summary_text)Explanation of the Implementation
- The agent accepts the paper abstract as input.
- It generates a short summary by extracting the first 150 characters from the abstract, appending “…” if the abstract exceeds this length.
- The summary is then returned as a structured PaperSummary object, ensuring consistent formatting and facilitating further automation or reporting tasks.
This simple summarization approach provides a quick snapshot of each paper’s content. While straightforward, it’s effective for initial assessments, enabling researchers to quickly screen multiple abstracts.
Expected Output Example (Text Only)
Given the abstract:
"This paper discusses advancements in agentic reinforcement learning,
focusing on deep learning techniques for enhancing agent cooperation in
multi-agent environments. We propose novel algorithms and evaluate their
effectiveness through extensive simulations."The Summarization Agent would produce:
"This paper discusses advancements in agentic reinforcement learning,
focusing on deep learning techniques for enhancing agent cooperation in
multi-age..."Potential for Advanced Summarization Techniques
While our implementation offers immediate value, integrating advanced summarization models—such as transformer-based language models (e.g., GPT models, T5, or BART)—could significantly enhance summary quality, coherence, and contextual accuracy.
Leveraging sophisticated summarization techniques would yield more informative and contextually precise summaries, further improving researchers’ efficiency and accuracy when evaluating papers.
Now, we can move on to the final and central piece of our system: The Router Agent (Orchestrator).
Bringing it all Together: Agentic Orchestration
At the heart of a multi-agent system lies the orchestration logic. This component ensures smooth coordination and communication among various specialized agents, managing workflows, dependencies, and the sequential or parallel execution of tasks.
In our research assistant system, the Router Agent (Orchestrator) plays this central role. It coordinates data flow between individual agents such as the Prompt Processor, Paper Retrieval, Keyword Extraction, and Summarization agents. Doing so ensures efficient handling of user queries, retrieval of relevant research, extraction of meaningful insights, and clear presentation of results.
Let’s now examine how the Router Agent orchestrates this entire workflow:
Code Snippet (Router Agent Orchestration)
@router_agent.tool
async def orchestrate_workflow(ctx: RunContext[ResearchContext]) -> str:
print("Starting prompt processing...")
refined_query = await prompt_processor_agent.run(ctx.deps.query,
deps=ctx.deps)
print(f"Refined Query: {refined_query.data}")
print("Fetching papers...")
papers = await paper_retrieval_agent.run(refined_query.data, deps=ctx.deps)
print(f"Fetched {len(papers.data)} papers.")
response = "Final Report:\n"
for paper in papers.data:
print(f"\nProcessing paper: {paper.title}")
print("Extracting keywords...")
keywords = await keyword_extraction_agent.run(paper.abstract,
deps=ctx.deps)
print(f"Extracted Keywords: {keywords.data.keywords}")
print("Generating summary...")
summary = await summary_agent.run(paper.abstract, deps=ctx.deps)
print(f"Generated Summary: {summary.data.summary}")
response += (
f"\nTitle: {paper.title}\n"
f"Keywords: {keywords.data.keywords}\n"
f"Summary: {summary.data.summary}\n"
)
return responseStep-by-step Explanation of Orchestration Logic
- Prompt Processing:
- The Router Agent first passes the initial user query to the Prompt Processor Agent.
- The Prompt Processor refines the query, and the Router logs the refined query clearly.
- Paper Retrieval:
- Using the refined query, the Router invokes the Paper Retrieval Agent to fetch relevant academic papers from arXiv.
- After retrieval, it logs the number of papers fetched, enabling visibility into the system’s activity.
- Processing Each Paper: For each paper retrieved, the Router performs two key tasks simultaneously:
- Keyword Extraction: It passes each abstract to the Keyword Extraction Agent and logs the keywords extracted.
- Summarization: It also invokes the Summarization Agent for each abstract, logging the concise summary obtained.
- Aggregating Results: The Router aggregates all information—titles, keywords, summaries—into a structured, human-readable “Final Report.”
- The asynchronous (async/await) nature of the orchestration allows simultaneous task execution, significantly improving workflow efficiency, especially when dealing with external API calls.
- Structured logging at each step provides clear visibility into the workflow, facilitating easier debugging, traceability, and future maintenance or expansion of the system.
With our orchestration clearly defined, we can now conclude the pipeline by generating professional, structured reports.
Generating Professional Outputs with Structured Data
Ultimately, the value of an automated research assistant lies not only in its efficiency but also in the clarity and professionalism of its final outputs. Researchers often prefer structured, easy-to-read documents that consolidate key insights clearly. Converting structured data from our multi-agent system into professional reports (like PDFs) enhances readability and usefulness.
With the structured data output we have from our Router Agent, generating a polished PDF report is straightforward. Here’s how we leverage the structured data to create clear, visually appealing PDF reports using Python:
Code Snippet (PDF Generation)
def generate_pdf_report(report_text: str, output_filename: str = "Final_Report.pdf"):
import markdown2
from xhtml2pdf import pisa
# Convert the structured markdown text to HTML
html_text = markdown2.markdown(report_text)
# Create and save the PDF file
with open(output_filename, "w+b") as result_file:
pisa.CreatePDF(html_text, dest=result_file)
Explanation of the PDF Generation Logic
- Markdown Conversion: The structured final report, generated by our Router Agent, is initially in a structured text or markdown format. We convert this markdown text into HTML using the markdown2 library.
- PDF Generation: The xhtml2pdf library takes the converted HTML content and generates a professional-looking PDF file, neatly formatted for readability.
- Ease Due to Structured Data: The structured outputs from our agents, facilitated by our Pydantic data models, ensure the markdown content is consistently formatted. This consistency simplifies conversion into high-quality PDFs without manual intervention or additional parsing complexity.
Expected Output
A professional PDF is generated after running the snippet with our structured report as input. This PDF will neatly present each paper’s title, keywords, and summary clearly, making it easy for researchers to quickly review, distribute, or archive their findings.
With this step, our multi-agent research assistant pipeline is complete, effectively automating literature discovery, processing, and reporting in a structured, efficient, and professional manner. Next, we look into a few practical examples of the magnetic framework.
Multi-Agent System in Action: Practical Examples
Let’s explore how our multi-agent research assistant performs across different research scenarios. We’ll demonstrate the system’s effectiveness by presenting three distinct prompts. Each example showcases how a simple user query transforms into a comprehensive, structured, and professionally formatted research report.
Example 1: Reinforcement Learning Agents
For our first scenario, we explore recent research on applying reinforcement learning to robotics.
User Prompt:
"Reinforcement learning agents in robotics"Below is a screenshot of the multi-agent workflow output, clearly illustrating how the prompt was refined, relevant papers retrieved, keywords extracted, and summaries generated.
Starting prompt processing...
Refined Query: all:reinforcement learning agents AND cat: robotics
Fetching papers...
<ipython-input-5-08d1ccafd1dc>:46: DeprecationWarning: The 'Search.results' method
is deprecated, use 'Client.results' instead
results
Fetched
list(search.results())
papers.
Starting prompt processing...
Refined Query: all: ("reinforcement learning agents" OR "reinforcement learning" OR
"RL agents") AND cat: robotics Fetching papers...
Fetched
papers.
Starting prompt processing... Starting prompt processing.... Starting prompt
processing.... Starting prompt processing...
Starting prompt processing...
Refined Query: all: ("reinforcement learning agents" OR "RL agents") AND cat:
robotics
Fetching papers...
Refined Query: ti:"reinforcement learning agents robotics" OR abs: "reinforcement
learning agents robotics"
Fetching papers...
Refined Query: all: ("reinforcement learning agents" OR "reinforcement learning" OR
"RL agents") AND cat: robotics
Fetching papers...
Refined Query: all: ("reinforcement learning agents" OR "RL agents") AND cat:
robotics
Fetching papers...
Refined Query: ti: "reinforcement learning agents" OR ti:"reinforcement learning" OR
ti: "RL agents" OR abs: "reinforcement learning agents" OR abs: "reinforcement
learning" OR abs: "RL agents" AND cat: robotics Fetching papers...
Notice above how the user prompt is being refined iteratively for better search capabilities.
Fetched 1 papers.
Processing paper: An Architecture for Unattended Containerized (Deep) Reinforcement
Learning with Webots Extracting keywords...
Extracted Keywords: ['data science', 'reinforcement learning', '3D worlds',
'simulation software', 'Robotino', 'model development', 'unattended training', 'Webots', 'Robot Operating System', 'APIs', 'container technology', 'robot tasks']
Generating summary... Summary: This paper reviews tools and approaches for training
reinforcement learning agents in 3D environments, specifically for the Robotino robot. It addresses the challenge of separating the simulation environment from the
model development envi Starting prompt processing... Refined Query: ti:
"reinforcement learning agents for robotics" OR abs: "reinforcement learning agents
for robotics"
Fetching papers...
Fetched 1 papers.
Processing paper: An Architecture for Unattended Containerized (Deep) Reinforcement
Learning with Webots Extracting keywords...
Extracted Keywords: ['data science', 'reinforcement learning', '3D simulation',
'Robotino', 'simulation software', 'Webots', 'Robot Operating System', 'unattended
training pipelines', 'APIS', 'model development', 'container technology', 'virtual
wo Generating summary... Summary: This paper reviews tools and approaches for
training reinforcement learning agents in 3D worlds, focusing on the Robotino
robot. It highlights the challenge of integrating simulation environments for
virtual world creators and model develo Final Report:
### Comprehensive Report on "Reinforcement Learning Agents for Robotics"
#### Title:
An Architecture for Unattended Containerized (Deep) Reinforcement Learning with
Webots
#### Authors:
Tobias Haubold, Petra Linke
#### Publication Date: February 6, 2024 #### Abstract:
As data science applications gain traction across various industries, the tooling
landscape is evolving to support the lifecycle of these applications, addressing
challenges to enhance productivity. In this context, reinforcement learning (RL)
for This paper reviews various tools and strategies for training reinforcement
learning agents specifically for robotic applications in 3D spaces, utilizing the
Robotino robot. It examines the critical issue of separating the simulation
environment for The authors propose a solution that isolates data scientists from
the complexities of simulation software by using Webots for simulation, the Robot
Operating System (ROS) for robot communication, and container technology to create
a clear division #### Keywords:
Data Science
Reinforcement Learning
- 3D Worlds
- Simulation Software
Robotino
Model Development
The multi-agent system draws and collates the information from arxiv into a single report.
You can download the complete structured PDF report below:
Download
Example 2: Quantum Machine Learning
In the second scenario, we investigate current developments in quantum machine learning.
User Prompt:
"Quantum machine learning techniques"The following screenshot demonstrates how the system refined the query, retrieved relevant papers, performed keyword extraction, and provided concise summaries.
Starting prompt processing...
Refined Query: ti: "quantum machine learning techniques" OR abs: "quantum machine
learning techniques"
Fetching papers...
<ipython-input-5-08d1ccafd1dc>:46: DeprecationWarning: The 'Search.results' method
is deprecated, use 'Client.results' instead
results list (search.results())
Fetched 5 papers.
Processing paper: Experimental demonstration of enhanced quantum tomography via
quantum reservoir processing Extracting keywords...
Extracted Keywords: ['quantum machine learning', 'quantum reservoir processing',
'continuous-variable state reconstruction', 'bosonic circuit quantum
electrodynamics', 'measurement outcomes', 'reconstruction Generating summary...
Summary: This paper presents an experimental demonstration of quantum reservoir
processing for continuous-variable state reconstruction using bosonic quantum
circuits. It shows that the method efficiently lea Processing paper: Detection
states of ions in a Paul trap via conventional and quantum machine learning
algorithms Extracting keywords...
Extracted Keywords: ['trapped ions', 'quantum technologies', 'quantum computing'
, 'state detection', 'high-fidelity readouts', 'machine learning', 'convolution',
'support vector machine', 'quantum annealing', Generating summary... Summary: This
work develops and benchmarks methods for detecting quantum states of trapped
ytterbium ions using images from a sensitive camera and machine learning
techniques. By applying conventional and qua Processing paper: Satellite image
classification with neural quantum kernels Extracting keywords...
Extracted Keywords: ['quantum machine learning', 'satellite image classification',
'earth observation', 'solar panels', 'neural quantum kernels', 'quantum neural networks', 'classical pre-processing', 'dimens Generating summary... Summary: This
paper presents a novel quantum machine learning approach for classifying satellite
images, particularly those with solar panels, relevant to earth observation. It
combines classical pre-processi Processing paper: Harnessing Quantum Extreme
Learning Machines for image classification
Extracting keywords...
Extracted Keywords: ['quantum machine learning', 'image classification', 'quantum
extreme learning machine', 'quantum reservoir', 'feature map', 'dataset
preparation', 'Principal Component Analysis', 'Auto-En Generating summary...
Summary: This research explores quantum machine learning techniques for image
classification, focusing on a quantum extreme learning machine that utilizes a
quantum reservoir. It analyzes various encoding met Processing paper: Quantum
Generative Adversarial Networks: Generating and Detecting Quantum Product States
Extracting keywords...
Extracted Keywords: ['quantum machine learning', 'QGAN', 'quantum product states',
'image generation', 'decoherence', 'NISQ devices', 'GAN MinMax', 'quantum style
parameters', 'generator', 'discriminator'] Generating summary... Summary: The paper
introduces a Quantum Generative Adversarial Network (OGAN), leveraging quantum
machine learning to generate and discriminate quantum product states, a task with
no classical analog. It util
Download the full PDF report for detailed insights:
Download Quantum_Machine_Learning_Report.pdf
Example 3: AI Agents
For our third scenario, we examine how multi-agent systems are being applied .
User Prompt:
"Multi-agent systems"Below, you can clearly see the screenshot of our system’s output, which shows structured query refinement, retrieval of pertinent research papers, keyword extraction, and summarization.
Starting prompt processing...
Refined Query: ti:"ai agents" OR abs: "ai agents"
Fetching papers...
<ipython-input-5-08d1ccafd1dc>:46: DeprecationWarning: The 'Search.results' method
is deprecated, use 'Client.results' instead
results list (search.results())
Fetched 5 papers.
Processing paper: Verbal Process Supervision Elicits Better Coding Agents Extracting
keywords...
Extracted Keywords: ['large language models', 'AI agents', 'code generation',
'software engineering', 'CURA', 'code understanding', 'reasoning agent', 'verbal
process supervision', 'benchmark improvement', 'BigC Generating summary...
Summary: This work introduces CURA, a code understanding and reasoning agent system
enhanced with verbal process supervision (VPS), which achieves a 3.65% improvement
on challenging benchmarks. When combined wit
Processing paper: How to Capture and Study Conversations Between Research
Participants and ChatGPT: GPT for Researchers (g4r.org) Extracting keywords...
Extracted Keywords: ['large language models', 'LLMs', 'GPT for Researchers', 'G4R',
'AI systems', 'human-AI communication', 'consumer interactions', 'AI-assisted
decision-making', 'GPT Interface', 'research tool Generating summary... Summary: The
paper introduces GPT for Researchers (G4R), a free online platform designed to aid
researchers in studying interactions with large language models (LLMs) like
ChatGPT. G4R allows researchers to enab Processing paper: Collaborating with AI
Agents: Field Experiments on Teamwork, Productivity, and Performance Extracting
keywords...
Extracted Keywords: ['AI agents', 'productivity', 'performance', 'work processes',
'MindMeld', 'experimentation platform', 'human-AI teams', 'communication', 'collaboration', 'multimodal workflows', 'AI personal Generating summary... Summary:
This study introduces MindMeld, a platform for human-AI collaboration, showing that
AI agents can significantly improve productivity and performance in team settings.
In an experiment with 2310 particip Processing paper: Metacognition in Content-
Centric Computational Cognitive C4 Modeling Extracting keywords...
Extracted Keywords: ['AI agents', 'human behavior', 'metacognition', 'C4 modeling',
'cognitive robotic applications', 'neuro symbolic processing', 'LEIA Lab',
'cognitive capabilities', 'information storage', 'LL Generating summary... Summary:
This paper discusses the necessity of metacognition for AI agents to replicate
human behavior through effective information processing. It introduces content-
centric computational cognitive (C4) modelin Processing paper: OvercookedV2:
Rethinking Overcooked for Zero-Shot Coordination
Extracting keywords...
Extracted Keywords: ['AI agents', 'zero-shot coordination (ZSC)', 'Overcooked',
'state augmentation', 'coordination capabilities', 'out-of-distribution challenge',
'OvercookedV2', 'asymmetric information', 'stoc Generating summary... Summary: This
paper explores the challenges of zero-shot coordination (ZSC) in AI agents using
the Overcooked environment. It introduces a state augmentation mechanism to improve
training by incorporating states Starting prompt processing...
Refined Query: ti: "ai agents" OR abs: "ai agents"
Fetching papers...
Fetched 5 papers.
Processing paper: Verbal Process Supervision Elicits Better Coding Agents
Extracting keywords...
You can download the professionally formatted PDF report from the link below:
Download Multi_Agent_Systems_Report.pdf
Each example clearly illustrates our multi-agent framework’s ability to swiftly and effectively automate research workflows—from refining initial queries to generating structured, professional reports, all leveraging the structured data validation power of Pydantic.
Conclusion
In this blog, we’ve explored the design and implementation of a structured, scalable, and efficient Multi-Agent Research Assistant System using Pydantic. By clearly defining structured data models, we’ve ensured consistency and reliability across interactions between multiple intelligent agents—ranging from refining user prompts, retrieving relevant academic papers, extracting meaningful keywords, and summarizing complex abstracts, to orchestrating the entire workflow seamlessly. Through practical examples, we’ve demonstrated how this robust framework automates and significantly simplifies complex academic research tasks, culminating in professional-quality, ready-to-use reports.
Key Takeaways
- Pydantic ensures structured data handling, significantly reducing errors and simplifying agent interactions.
- Clear agent roles and responsibilities make multi-agent systems modular, maintainable, and scalable.
- Refined and structured queries dramatically enhance the relevance and usefulness of retrieved research.
- Automated keyword extraction and summarization save researchers valuable time, enabling rapid content assessment.
- Effective orchestration with structured logging and asynchronous workflows enhances system efficiency and ease of debugging.
By adopting such a structured multi-agent approach, developers and researchers can significantly enhance productivity, clarity, and efficiency in their research automation pipelines.
Bonus: While it was challenging to include the detailed outputs for each code block to maintain the scope of the blog, the entire code for the agentic system discussed here is being open-sourced to allow better learning and usability for the readers! (Code)
Frequently Asked Questions
Q1. What makes Pydantic particularly useful in multi-agent systems?
A. Pydantic provides powerful runtime data validation and clearly defined schemas, ensuring reliable communication and consistency among different agents in a multi-agent setup.
Q2. Can I integrate other external APIs or databases apart from arXiv in this multi-agent workflow?
A. Yes, the modular design allows seamless integration with various external APIs or databases—simply by defining appropriate agents and using structured data models.
Q3. Is the simplistic keyword extraction and summarization logic shown here sufficient for production use?
A. The provided keyword extraction and summarization implementations are simplified for demonstration purposes. For production use, more advanced NLP techniques or fine-tuned language models are recommended to improve accuracy and relevance.
Q4. How can I improve the orchestration and efficiency of my agents?
A. Leveraging asynchronous programming and structured logging (as shown in this blog) greatly improves agent efficiency. Additionally, deploying your agents in distributed or cloud environments can further enhance scalability and responsiveness.
Q5. Can the final reports generated by this system be customized or formatted differently?
A. Absolutely! Because the data is structured using Pydantic models, the final report generation can easily be adapted to various formats like Markdown, HTML, PDF, or even interactive dashboards.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Advancing language model research by day and writing about my work online by night. I explore AI breakthroughs and transform complex studies into clear, engaging insights that empower professionals and enthusiasts alike.
Thanks for stopping by my profile!





