Implementing an automatic grading system for handwritten answer sheets using a multi-agent framework streamlines evaluation, reduces manual effort, and enhances consistency. A multi-agent system (MAS) consists of autonomous agents that extract information, grade answers, and suggest improvements. By leveraging Handwritten Answer Evaluation using Griptape, educators can automate grading, ensuring accuracy and efficiency. This approach allows teachers to focus more on personalized feedback and student development while maintaining fairness and reliability in assessments with Handwritten Answer Evaluation using Griptape.
Learning Objectives
- Understand the fundamentals, key features, and components of multi-agent systems.
- Explore real-world applications where multi-agent systems are transforming industries.
- Learn about Griptape and its role in building complex AI architectures.
- Gain hands-on experience in constructing a multi-agent system for automatic grading with Handwritten Answer Evaluation using Griptape.
- Discover how multi-agent systems can generate suggestions for improving handwritten answers.
This article was published as a part of the Data Science Blogathon.
Table of contents
What are Multi Agentic Systems?
Multi-Agent Systems (MAS) are complex systems composed of multiple interacting intelligent agents, each with its own specialized capabilities and goals. These agents can be software programs, robots, drones, sensors, humans, or a combination thereof. MAS leverage collective intelligence, cooperation, and coordination among agents to solve problems that are too complex for a single agent to handle alone.
Key Characteristics of Multi-Agent Systems
- Autonomy: Agents operate with a degree of independence, making decisions based on their local views of the environment.
- Decentralization: Control is distributed among agents, allowing the system to function even if some components fail.
- Self-Organization: Agents can adapt and organize themselves based on emergent behaviors, leading to efficient division of labor and conflict resolution.
- Real-Time Operation: MAS can respond immediately to changing situations without human intervention, making them suitable for applications like disaster response and traffic management.
MAS can adapt to changing environments by adding or removing agents, making them highly scalable for complex problem-solving. Decentralized control ensures continued system operation despite component failures. MAS can tackle large-scale tasks by combining the expertise of multiple agents, outperforming single-agent systems.
What Constitutes Multi Agentic Systems?
The core components of multi-agent systems include agents, which are autonomous entities with specific roles and goals, acting as the cognitive core of the system. Tasks represent specific jobs assigned to these agents, ensuring that their efforts are directed towards achieving the system’s objectives. Tools extend the capabilities of agents, allowing them to interact with external systems and perform specialized tasks efficiently. Additionally, processes outline how agents interact and coordinate actions, ensuring that tasks are executed in harmony. The environment provides the context in which agents operate, influencing their decisions and actions.
Finally, communication protocols enable agents to share information and negotiate, fostering collaboration or competition depending on the system’s design. These components work together to enable complex problem-solving and adaptability in multi-agent systems.
Some Key Application Areas of Multi Agentic System
Multi-agent AI systems can be incredibly useful in a variety of applications across different industries. Here are some examples:
- Supply Chain Management: Multi-agent systems can optimize logistics by coordinating agents representing suppliers, manufacturers, distributors, and retailers. These agents share real-time inventory data, predict demand, and manage resources efficiently, reducing stockouts and holding cost.
- Healthcare: In healthcare, multi-agent systems aid in disease prediction, patient allocation, workflow optimization, and personalized treatment. Agents can monitor patient health in real-time, notify medical staff about anomalies, and enhance communication between patients and healthcare providers.
- Transportation Systems: Multi-agent systems improve traffic flow by coordinating traffic signals, surveillance cameras, and information systems. These agents optimize routes, reduce congestion, and respond to real-time conditions like accidents or roadwork.
- Smart Grids for Energy Management: Agents in smart grids manage different aspects of electricity distribution, from generation to smart meters. They work together to balance energy supply and demand, integrate renewable sources, and maintain grid stability
GripTape For Building Multi-agent Systems
Griptape is a modular Python framework designed to build and operate multi-agent systems, which are crucial components of agentic AI systems. These systems enable large language models to autonomously handle complex tasks by integrating multiple AI agents that work together seamlessly. Griptape simplifies the creation of such systems by providing structures like agents, pipelines, and workflows, allowing developers to build business logic using Python and ensuring better security, performance, and cost efficiency.
Core Components of GripTape

- Agent Structure: Griptape agents are part of a modular framework that allows developers to create structures like agents, pipelines, and workflows. These structures are composed of different types of tasks that enable interaction with large language models (LLMs) and external systems.
- Tools and Engines: Agents in Griptape can be equipped with various tools and engines. Specialized components, called tools, perform specific tasks like calculation or summarization, while engines, typically LLMs, process prompts and generate outputs.
- Input and Output Handling: Agents take in input directly, which can be a prompt or a set of arguments. They use their tools and engines to process the input and generate output, which is accessible through the agent’s output attribute.
- Task Memory and Off-Prompt Data Handling: Griptape agents can handle off-prompt data, allowing them to process information beyond the initial prompt, which is useful for tasks that require additional context or data retrieval.
- Drivers for Diverse Use Cases: Griptape provides a range of drivers that facilitate interactions with different LLMs and data processing systems, making it versatile for various applications.
Our Solution: Agents and Tasks
With the increasing prevalence of online classes and various modes of education, there is a growing shortage of staff to evaluate students’ exams. The slow pace of evaluation remains a major bottleneck in improving instructors’ productivity. Teachers often spend a significant amount of time grading hundreds of answer sheets, time that could be better utilized for tasks like projects, research, or directly assisting students. This issue is particularly relevant as multiple-choice exams are not always effective in assessing a student’s understanding of a subject. In this article, we will develop a multi-agent system designed to automatically grade handwritten papers.
Implementing a multi-agent system for automatic grading of handwritten answer sheets can significantly streamline the evaluation process for educators. This system utilizes specialized agents to extract relevant information from the sheets, assess the answers based on predefined criteria, and even provide suggestions for improved responses. By automating these tasks, teachers can focus on more critical aspects of education, such as personalized feedback and student development. This technology can also enhance grading consistency and reduce the time spent on manual evaluation.
We will build this system using GripTape on Google Colab with T4 GPU (Free Tier).
Hands on Implementation of Automatic Grading of Answer Sheets
Automating handwritten answer evaluation with a multi-agent system can improve accuracy, efficiency, and consistency. By leveraging Griptape, educators can streamline grading, reduce manual effort, and ensure fair assessments.
Step 1: Installing and Importing Necessary Libraries
The code below installs necessary dependencies for working with Griptape, Ollama, and Langchain, followed by importing various modules to facilitate creating and managing agents, tasks, and tools for handling different data types and web searches. It prepares the environment to execute a multi-agent system using AI models and external tools like file management and web search.
!pip install griptape
!sudo apt update
!sudo apt install -y pciutils
!pip install langchain-ollama
!curl -fsSL https://ollama.com/install.sh | sh
!pip install ollama==0.4.2
!pip install "duckduckgo-search>=7.0.1"
import os
from griptape.drivers.prompt.ollama import OllamaPromptDriver
import requests
from griptape.drivers.file_manager.local import LocalFileManagerDriver
from griptape.drivers.prompt.openai import OpenAiChatPromptDriver
from griptape.loaders import ImageLoader
from griptape.structures import Agent
from griptape.tools import FileManagerTool, ImageQueryTool
from griptape.tasks import PromptTask, StructureRunTask
from griptape.drivers.structure_run.local import LocalStructureRunDriver
from griptape.structures import Agent, Workflow
from griptape.drivers.web_search.duck_duck_go import DuckDuckGoWebSearchDriver
from griptape.structures import Agent
from griptape.tools import PromptSummaryTool, WebSearchToolStep 2: Starting Ollama Server & Pulling the Model
The following code starts the ollama server. We also pull “minicpm-v” model from ollama so that this vision model can be used to extract text from handwritten notes.
import threading
import subprocess
import time
def run_ollama_serve():
subprocess.Popen(["ollama", "serve"])
thread = threading.Thread(target=run_ollama_serve)
thread.start()
time.sleep(5)
!ollama pull minicpm-v
Step 3: Setting OpenAI API Key
import os
os.environ["OPENAI_API_KEY"] = ""Step 4: Creating an Agent to Read Handwritten Answer Sheets
The code below defines the “image_dir” that stores our images or handwritten answer sheets. Also a a function reading_answersheet is defined that initializes an agent with tools for managing files and querying images using a vision language model (“minicpm-v”). The agent uses a file manager and an image query tool to process images.
images_dir = os.getcwd()
def reading_answersheet():
driver = LocalFileManagerDriver(workdir=images_dir)
return Agent(
tools=[
FileManagerTool(file_manager_driver=driver),
ImageQueryTool(
prompt_driver=OllamaPromptDriver(model="minicpm-v"), image_loader=ImageLoader(file_manager_driver=driver)
),
]Step 5: Creating an Agent For Evaluation of Answers using Web
This code defines a function evaluation_answer that creates an agent with tools for web search using DuckDuckGo.
def evaluation_answer():
return Agent(
tools=[WebSearchTool(web_search_driver=DuckDuckGoWebSearchDriver()), PromptSummaryTool(off_prompt=False)],
)Step 6: Creating Tasks For Reading Handwritten Answers, Scoring them and Suggesting Improvements
We use this image for automatic evaluation. We save it in our current working directory as “sample.jpg”. Its a handwritten answer sheet. This agentic system will first extract the hand written answers, then evaluate which answers are correct, score them and finally suggest improvements.
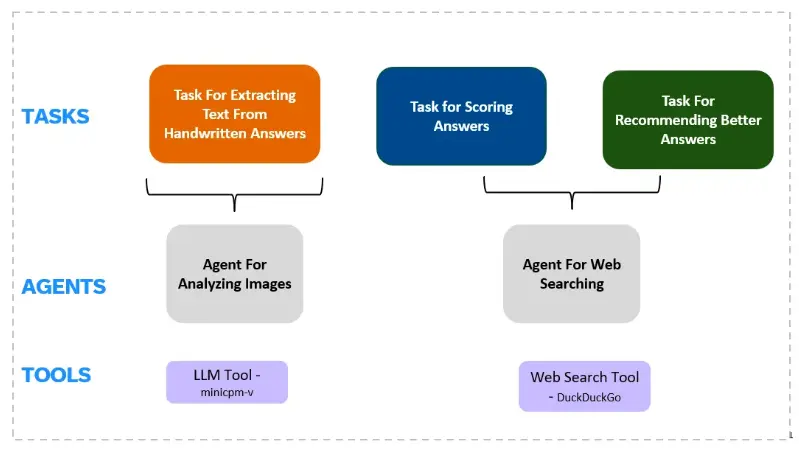
In the following code blocks, we define three different tasks –
- research_task – For extracting texts from handwritten answer sheets. Uses “reading_answersheet” agent
- evaluate_task – For scoring the answers based on the extracted text from the handwritten answer sheets. Uses “evaluation_answer” agent
- answer_improvement – For suggesting improvements to the current answers. Uses “evaluation_answer” agent
image_file_name = "sample.jpg"
team = Workflow()
research_task = StructureRunTask(
(
"""Extract IN TEXT FORMAT ALL THE LINES GIVEN IMAGE %s"""%(image_file_name),
),
id="research",
structure_run_driver=LocalStructureRunDriver(
create_structure=reading_answersheet,
),
)
evaluate_task =StructureRunTask(
(
"""Verify whether all the ANSWER containing lines in the TEXT {{ parent_outputs["research"] }} is correct and Score only on FACTUAL CORRECTNESS FOR each of these lines on a scale of 1 to 10 based on the correctness of the line.
DONT BE too strict in evaluation. IGNORE LINES WHICH DO NOT FIT IN THE CONTEXT AND MAY BE JUNK.
""",
),id="evaluate",
structure_run_driver=LocalStructureRunDriver(
create_structure=evaluation_answer,
)
)
answer_improvement = StructureRunTask(
(
"""ADD TO THE PREVIOUS OUTPUT, SUGGESTIONS ON HOW THE ANSWERS IN THE ANSWER containing lines in the TEXT {{ parent_outputs["research"] }} CAN BE IMPROVED BY PROVIDING BETTER OR MORE ACCURATE ANSWERS FOR THOSE ANSWERS THAT DO NOT HAVE 10 SCORE BASED ON THE OUTPUT {{ parent_outputs["evaluate"] }}.
DO INCLUDE THE WHOLE OUTPUT FROM THE PREVIOUS AGENT {{ parent_outputs["evaluate"] }} AS WELL IN THE FINAL OUTPUT.
""",
),
structure_run_driver=LocalStructureRunDriver(
create_structure=evaluation_answer,
)
)
Step 7: Starting the Workflow and Running it
This code adds tasks as child tasks to a parent workflow (research_task and evaluate_task), then runs the workflow with the tasks (research_task, evaluate_task, and answer_improvement) and prints the output of the result. The workflow orchestrates task execution and captures the final output. Here, the “answer_improvement” task in added as a child to both “evaluate_task” and “research_task” so that it is run post the first two tasks.
research_task.add_child(evaluate_task)
evaluate_task.add_child(answer_improvement)
research_task.add_child(answer_improvement)
team = Workflow(
tasks=[research_task,evaluate_task,answer_improvement],
)
answer = team.run()
print(answer.output)Analysis of Outputs
Input Image

Output:

As seen from the output, this agentic system not only scores each of the answers but also suggests improvement for each of the answers which can be very helpful to both teachers and students, whoever is using this system.
Another Example

Output

As seen from the output, this agentic system not only scores each of the answers but also suggests improvement for each of the answers. We only see for the second answer, the system is not able to verify from the web and therefore scores it as 5 out of 10. We would need a human intervention for answers like these at the end of the loop. Despite this, agentic systems like this can for sure help teachers speed up evaluation of hundreds of answer sheet.
Conclusion
The implementation of a Handwritten Answer Evaluation using Griptape for the automatic grading of handwritten answer sheets offers a transformative solution to the educational sector. By automating the grading process, educators can save valuable time, ensure more consistent evaluations, and focus on providing personalized feedback to students. Leveraging frameworks like Handwritten Answer Evaluation using Griptape further enhances the flexibility and scalability of the system, making it a highly effective tool for modernizing assessments. This approach not only benefits teachers but also improves the overall fairness and reliability of academic evaluations.
Key Takeaways
- Implementing a multi-agent system (MAS) for automatic grading of handwritten answer sheets can drastically reduce manual grading time, allowing educators to focus on more personalized student feedback and development.
- Automation helps standardize grading, ensuring consistency and fairness in assessments, reducing potential biases inherent in manual evaluations.
- MAS leverage the power of multiple autonomous agents working together, making it an ideal solution for complex tasks like grading, where agents handle tasks such as information extraction, assessment, and feedback generation independently.
- MAS are highly scalable and adaptable, making them well-suited to handle large volumes of data and adjust to evolving requirements, such as adding or modifying grading criteria.
- The Griptape framework simplifies the creation and management of multi-agent systems, providing a modular and efficient approach to develop AI-driven solutions for real-world challenges like Handwritten Answer Evaluation using Griptape.
Frequently Asked Questions
Q1. What is a Multi-Agent System (MAS)?
A. A Multi-Agent System (MAS) is a decentralized framework composed of multiple autonomous agents that interact with each other within a shared environment to achieve individual or collective goals. These agents can be software programs, robots, sensors, or other intelligent entities that make decisions based on their local data.
Q2. How does an automatic grading system using MAS work?
A. The automatic grading system uses multiple specialized agents to perform tasks such as extracting information from handwritten answer sheets, grading the answers based on predefined criteria, and suggesting improvements. These tasks are carried out independently but cooperatively, helping educators evaluate answers more efficiently and consistently.
Q3. What are the benefits of using a MAS for grading handwritten answer sheets?
A. The main benefits of using MAS for grading are reduced manual grading time, enhanced consistency and fairness in assessments, the ability for educators to focus on personalized feedback and student development, and improved reliability in the grading process.
Q4. How does GripTape facilitate building a Multi-Agent System?
A. GripTape is a modular Python framework that simplifies the creation of multi-agent systems. It provides structures like agents, pipelines, and workflows to help developers design complex AI architectures. With GripTape, developers can build and operate multi-agent systems efficiently, leveraging tools and engines to handle diverse tasks such as grading and feedback generation.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Nibedita completed her master’s in Chemical Engineering from IIT Kharagpur in 2014 and is currently working as a Senior Data Scientist. In her current capacity, she works on building intelligent ML-based solutions to improve business processes.




