In this tutorial, we explore how to set up and execute a sophisticated retrieval-augmented generation (RAG) pipeline in Google Colab. We leverage multiple state-of-the-art tools and libraries-including Gemma 3 for language and vision tasks, Docling for document conversion, LangChain for chain-of-thought orchestration, and Milvus as our vector database build a multimodal system that understands and processes text, tables, and images. Let’s dive into each component and see how they work together.
Table of contents
- What is Multimodal RAG?
- Proposed Architecture of Multimodal RAG with Gemma 3
- Overview of Libraries and Tools
- Building Multimodal Rag with Gemma 3
- Terminal Setup with Colab-Xterm
- Installing and Managing Ollama Models
- Installing Essential Python Packages
- Logging and Hugging Face Authentication
- Configuring Vision and Language Models (Gemma 3)
- Document Conversion with Docling
- Image Processing and Encoding
- Creating a Vector Database with Milvus
- Building the Retrieval-Augmented Generation (RAG) Chain
- Executing Queries and Retrieving Information
- Use Cases
- Conclusion
What is Multimodal RAG?
Multimodal RAG (Retrieval-Augmented Generation) extends traditional text-based RAG systems by integrating multiple data modalities, in this case, text, tables, and images. This means that the pipeline not only processes and retrieves text but also leverages vision models to understand and describe image content, making the solution more comprehensive. This multimodal approach is particularly beneficial for documents like annual reports that often contain visual elements, such as charts and diagrams.
Proposed Architecture of Multimodal RAG with Gemma 3
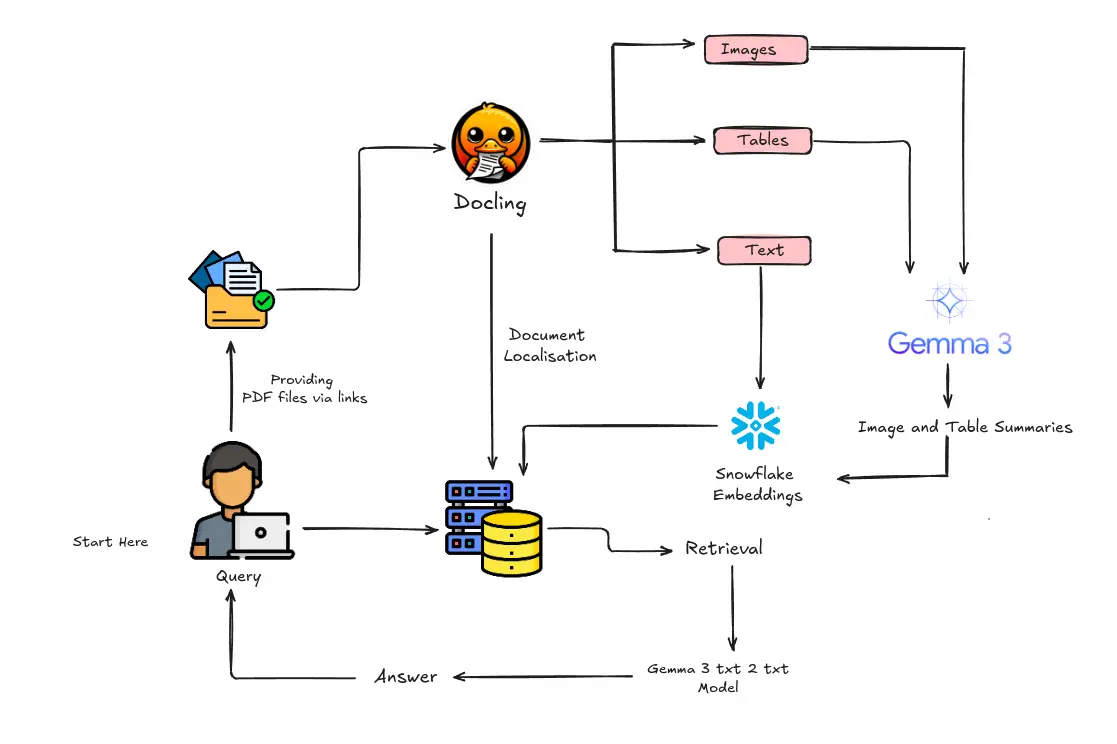
The aim of this project is to build a robust multimodal RAG pipeline that can ingest documents (like PDFs), process text and images, store document embeddings in a vector database, and answer queries by retrieving relevant information. This setup is particularly useful for applications such as analyzing annual reports, extracting financial statements, or summarizing technical papers. By integrating various libraries and tools, we combine the power of language models with document conversion and vector search to create a comprehensive end-to-end solution.
Overview of Libraries and Tools
The pipeline uses several key libraries and tools:
- Colab-Xterm Extension: This adds terminal support in Colab, allowing us to run shell commands and manage the environment efficiently.
- Ollama Models: Provides pre-trained models such as Gemma3, which are used for both language and vision tasks.
- Transformers: From Hugging Face, for model loading and tokenization.
- LangChain: Orchestrates the chain of processing steps, from prompt creation to document retrieval and generation.
- Docling: Converts PDF documents into structured formats, enabling extraction of text, tables, and images.
- Milvus: A vector database that stores document embeddings and supports efficient similarity search.
- Hugging Face CLI: Used for logging into Hugging Face to access certain models.
- Additional Utilities: Such as Pillow for image processing and IPython for display functionalities.
Also read: A Comprehensive Guide to Building Multimodal RAG Systems
Building Multimodal Rag with Gemma 3
We are building multimodal rag: This approach improves contextual understanding, accuracy, and relevance, especially in fields like healthcare, research, and media analysis. By leveraging cross-modal embeddings, hybrid retrieval strategies, and vision-language models, multimodal RAG systems can provide richer and more insightful responses. The key challenge lies in efficiently integrating and retrieving multimodal data while maintaining coherence and scalability. As AI progresses, developing optimized architectures and retrieval strategies will be crucial for unlocking the full potential of multimodal intelligence.
Terminal Setup with Colab-Xterm
First, we install the colab-xterm extension to bring a terminal environment directly into Colab. This allows us to run system commands, install packages, and manage our session more flexibly.
!pip install colab-xterm # Install colab-xterm
%load_ext colabxterm # Load the xterm extension
%xterm # Launch an xterm terminal session in Colab
This terminal support is especially useful for installing additional dependencies or managing background processes.
Installing and Managing Ollama Models
We pull specific Ollama models into our environment using simple shell commands. For example:
!ollama pull gemma3:4b
!ollama pull llama3.2
!ollama listThese commands ensure that we have the necessary language and vision models available, such as the powerful Gemma 3 model, which is central to our multimodal processing.
Installing Essential Python Packages
The next step involves installing a host of packages required for our pipeline. This includes libraries for deep learning, text processing, and document handling:
! pip install transformers pillow langchain_community langchain_huggingface langchain_milvus docling langchain_ollamaBy installing these packages, we prepare the environment for everything from document conversion to retrieval-augmented generation.
Logging and Hugging Face Authentication
Setting up logging is crucial for monitoring pipeline operations:
import logging
logging.basicConfig(level=logging.INFO)We also log in to Hugging Face using their CLI to access certain pre-trained models:
!huggingface-cli loginThis authentication step is necessary for fetching model artifacts and ensuring smooth integration with Hugging Face’s ecosystem.
Configuring Vision and Language Models (Gemma 3)
The pipeline leverages the Gemma 3 model for both vision and language tasks. For the language side, we set up the model and tokenizer:
This dual setup enables the system to generate textual descriptions from images, making the pipeline truly multimodal.
Document Conversion with Docling
1. Converting PDFs to Structured Documents
We employ Docling’s DocumentConverter to convert PDFs into structured documents. The conversion process involves extracting text, tables, and images from the source PDFs:
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
pdf_pipeline_options = PdfPipelineOptions(
do_ocr=False,
generate_picture_images=True,
)
format_options = { InputFormat.PDF: PdfFormatOption(pipeline_options=pdf_pipeline_options) }
converter = DocumentConverter(format_options=format_options)
# Define the sources (URLs) of the documents to be converted.
# "https://arxiv.org/pdf/1706.03762"
sources = [
"https://www.pwc.com/jm/en/research-publications/pdf/basic-understanding-of-a-companys-financials.pdf"
]
# Convert the PDF documents from the sources into an internal document format.
conversions = { source: converter.convert(source=source).document for source in sources }Input File

We’ll be using PwC’s publicly available financial statements. I’ve included the PDF link, and you’re welcome to add your own source links as well!
2. Extracting and Chunking Content
After conversion, we chunk the document into manageable pieces, separating text from tables and images. This segmentation allows each component to be processed independently:
from docling_core.transforms.chunker.hybrid_chunker import HybridChunker
from langchain_core.documents import Document
# Process text chunks (excluding pure table segments)
texts: list[Document] = []
for source, docling_document in conversions.items():
for chunk in HybridChunker(tokenizer=embeddings_tokenizer).chunk(docling_document):
# Skip table-only chunks; process tables separately
if len(chunk.meta.doc_items) == 1:
continue
document = Document(
page_content=chunk.text,
metadata={"source": source, "ref": "reference details"}
)
texts.append(document)This approach not only improves processing efficiency but also facilitates more precise vector storage and retrieval later.
Image Processing and Encoding
Images from the documents are processed using Pillow. We convert images into base64-encoded strings that can be embedded directly into prompts:
import base64, io, PIL.Image, PIL.ImageOps
def encode_image(image: PIL.Image.Image, format: str = "png") -> str:
image = PIL.ImageOps.exif_transpose(image) or image
image = image.convert("RGB")
buffer = io.BytesIO()
image.save(buffer, format)
encoding = base64.b64encode(buffer.getvalue()).decode("utf-8")
return f"data:image/{format};base64,{encoding}"Subsequently, these images are fed into our vision model to generate descriptive text, enhancing the multimodal capabilities of our pipeline.
Creating a Vector Database with Milvus
To enable fast and accurate retrieval of document embeddings, we set up Milvus as our vector store:
import tempfile
from langchain_core.vectorstores import VectorStore
from langchain_milvus import Milvus
db_file = tempfile.NamedTemporaryFile(prefix="vectorstore_", suffix=".db", delete=False).name
vector_db: VectorStore = Milvus(
embedding_function=embeddings_model,
connection_args={"uri": db_file},
auto_id=True,
enable_dynamic_field=True,
index_params={"index_type": "AUTOINDEX"},
)Documents—whether text, tables, or image descriptions—are then added to the vector database, enabling fast and accurate similarity searches during query execution.
Building the Retrieval-Augmented Generation (RAG) Chain
1. Prompt Creation and Document Wrapping
Using LangChain’s prompt templates, we create custom prompts to feed context and queries into our language model:
from langchain.prompts import PromptTemplate
prompt = "{input} Given the context: {context}"
prompt_template = PromptTemplate.from_template(template=prompt)Each retrieved document is wrapped using a document prompt template, ensuring that the model understands the structure of the input context.
2. Assembling the RAG Pipeline
We combine the prompt with the vector store to create a retrieval chain that first fetches relevant documents and then uses them to generate a coherent answer:
from langchain.chains.retrieval import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
combine_docs_chain = create_stuff_documents_chain(
llm=model,
prompt=prompt_template,
document_prompt=PromptTemplate.from_template(template="""\
Document {doc_id}
{page_content}"""),
document_separator="\n\n",
)
rag_chain = create_retrieval_chain(
retriever=vector_db.as_retriever(),
combine_docs_chain=combine_docs_chain,
)Queries are then executed against this chain, retrieving context and generating responses based on both the query and the stored document embeddings.
Executing Queries and Retrieving Information
Once the RAG chain is established, you can run queries to retrieve relevant information from your document database. For example:
query = "Explain Three Key Financial Statements Notes"
outputs = rag_chain.invoke({"input": query})
Markdown(outputs['answer'])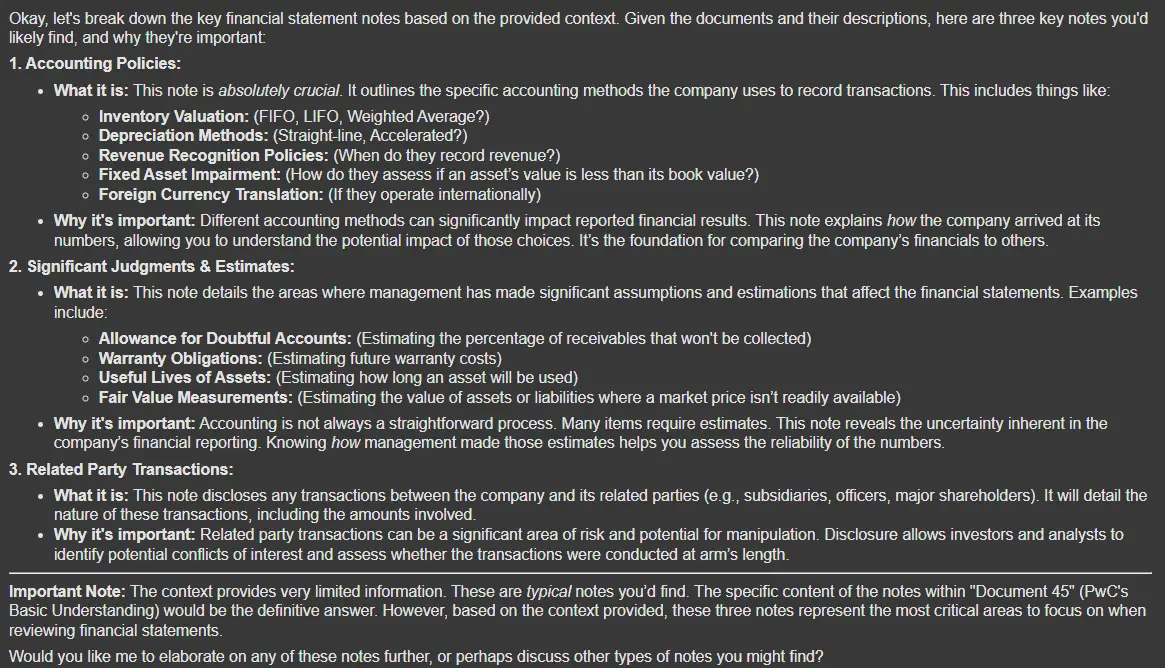
query = "tell me the Contents of an annual report"
outputs = rag_chain.invoke({"input": query})
Markdown(outputs['answer'])
query = "what are the benefits of an annual report?"
outputs = rag_chain.invoke({"input": query})
Markdown(outputs['answer'])
The same process can be applied for various queries, such as explaining financial statement notes or summarizing an annual report, thereby demonstrating the versatility of the pipeline.
Here’s the full code: AV-multimodal-gemma3-rag
Use Cases
This pipeline has numerous applications:
- Financial Reporting: Automatically extract and summarize key financial statements, cash flow elements, and annual report details.
- Document Analysis: Convert PDFs into structured data for further analysis or machine learning tasks.
- Multimodal Search: Enable search and retrieval from mixed media documents, combining textual and visual content.
- Business Intelligence: Provide quick insights into complex documents by aggregating and synthesizing information across modalities.
Conclusion
In this tutorial, we demonstrated how to build a multimodal RAG with Gemma 3 in Google Colab. By integrating tools like Colab-Xterm, Ollama models (Gemma 3), Docling, LangChain, and Milvus, we created a system capable of processing text, tables, and images. This powerful setup not only enables effective document retrieval but also supports complex query answering and analysis in diverse applications. Whether you’re dealing with financial reports, research papers, or business intelligence tasks, this pipeline offers a versatile and scalable solution.
Happy coding, and enjoy exploring the possibilities of multimodal retrieval-augmented generation!
Data Scientist @ Analytics Vidhya | CSE AI and ML @ VIT Chennai
Passionate about AI and machine learning, I'm eager to dive into roles as an AI/ML Engineer or Data Scientist where I can make a real impact. With a knack for quick learning and a love for teamwork, I'm excited to bring innovative solutions and cutting-edge advancements to the table. My curiosity drives me to explore AI across various fields and take the initiative to delve into data engineering, ensuring I stay ahead and deliver impactful projects.

