Imagine an AI that can write poetry, draft legal documents, or summarize complex research papers—but how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
Enter ROUGE (Recall-Oriented Understudy for Gisting Evaluation), a powerful toolkit that serves as a linguistic microscope for machine-generated text. Born in the realm of text summarization, ROUGE has evolved into a cornerstone metric for assessing the performance of Large Language Models across natural language processing (NLP) tasks. It’s not just a measurement tool—it’s a bridge between the raw output of AI systems and the nuanced expectations of human communication.

Table of contents
- Metric Description in LLM Context
- Why ROUGE Matters for LLM Evaluation?
- Types of ROUGE for LLM Evaluation
- How to Use ROUGE for LLM Evaluation?
- ROUGE Implementation in Python
- ROUGE Implementation with and without Aggregation
- ROUGE: The Stand-Up Comedian of Metrics
- Use Cases of ROUGE
- Limitations and Bias in ROUGE
- Conclusion
- Frequently Asked Questions
Metric Description in LLM Context
In the realm of Large Language Models, ROUGE serves as a precision-focused evaluation metric that compares generated model outputs against reference texts or expected responses. In contrast to conventional accuracy metrics, ROUGE offers a more sophisticated evaluation of how effectively an LLM retains the structural integrity, semantic meaning, and vital substance of intended outputs.
Using skip-grams, n-grams, and the longest common subsequence, ROUGE assesses the degree of overlap between the generated text (hypothesis) and the reference text (ground truth). In jobs like summarization, where recollection is more crucial than accuracy, ROUGE is very helpful. ROUGE gives priority on capturing all of the pertinent information from the reference text, in contrast to BLEU, which is precision-focused. ROUGE does not fully capture semantic meaning, though, hence complementary measures like BERTScore and METEOR are required even if it offers valuable insights.
Why ROUGE Matters for LLM Evaluation?
For LLMs, ROUGE helps determine how well a generated response aligns with expected human-written text. It is particularly useful in:
- Text summarization: Checking how well the summary preserves key details from the original text.
- Text generation tasks: Comparing chatbot or AI assistant responses with reference answers.
- Machine translation evaluation: Measuring how closely a translation matches a reference translation.
- Question-answering systems: Assessing if generated answers contain relevant information.
Types of ROUGE for LLM Evaluation
ROUGE provides multiple variants tailored to different aspects of text similarity evaluation. Each type is useful in assessing different language model outputs, such as summaries, responses, or translations. Below are the key ROUGE variants commonly used in LLM evaluation:
Source: Rouge Types
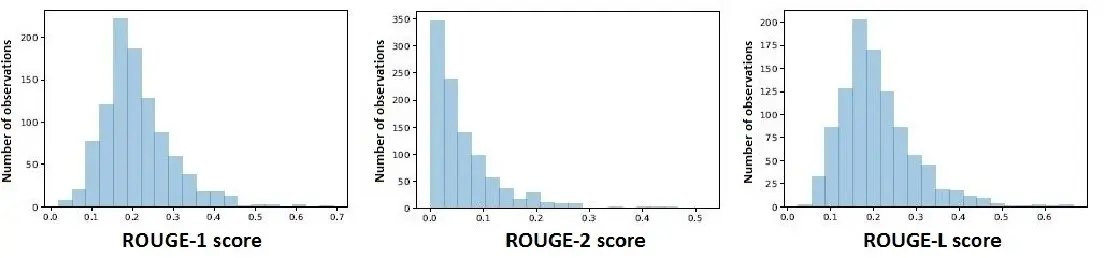
ROUGE-N (N-gram Overlap)
ROUGE-N measures the overlap of n-grams (continuous sequences of words) between the generated text and reference text. It is widely used in summarization and translation evaluation.
Formula:
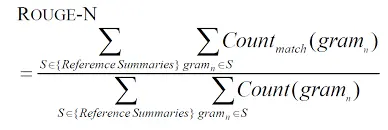
Code Example:
from rouge import Rouge
generated_text = "The cat is sitting on the mat."
reference_text = "A cat sat on the mat."
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_text)
print(scores[0]['rouge-1']) # ROUGE-1 score (unigram overlap)
print(scores[0]['rouge-2']) # ROUGE-2 score (bigram overlap)Output:
{
"rouge-1": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-2": {"r": 0.33, "p": 0.25, "f": 0.28}
}ROUGE-S (Skip-Bigram Overlap)
ROUGE-S (Skip-Bigram) measures the overlap of word pairs that appear in the same order but not necessarily adjacent. It captures semantic similarity better than strict n-gram matching.
Formula:

Code Example:
print(scores[0]['rouge-s'])Output:
{
"rouge-s": {"r": 0.55, "p": 0.4, "f": 0.46}
}ROUGE-W (Weighted LCS)
ROUGE-W is a weighted version of ROUGE-L that gives higher weight to longer contiguous matching sequences. It is useful for assessing fluency and coherence in LLM-generated text.
Formula:

Code Example:
print(scores[0]['rouge-w'])Output:
{
"rouge-w": {"r": 0.72, "p": 0.58, "f": 0.64}
}ROUGE-L (Longest Common Subsequence – LCS)
ROUGE-L measures the longest common subsequence (LCS) between the reference and generated texts. It is useful for measuring sentence fluency and syntactic correctness.
Formula:

Code Example:
print(scores[0]['rouge-l'])Output:
{
"rouge-l": {"r": 0.75, "p": 0.6, "f": 0.66}
}ROUGE-SU (Skip-Bigram with Unigrams)
ROUGE-SU is an extension of ROUGE-S that also considers unigrams, making it more flexible for evaluating LLM-generated responses where individual word matches matter.
Formula:

Code Example:
print(scores[0]['rouge-su'])Output:
{
"rouge-su": {"r": 0.68, "p": 0.52, "f": 0.59}
}ROUGE-Lsum (LCS for Summarization)
ROUGE-Lsum is a variant of ROUGE-L specifically designed for evaluating summarization models. It computes LCS over the entire document-summary pair, instead of sentence-by-sentence comparison.
Formula:

Code Example:
print(scores[0]['rouge-lsum'])Output:
{
"rouge-lsum": {"r": 0.72, "p": 0.59, "f": 0.65}
}| ROUGE TYPE | MEASURES | BEST FOR |
| ROUGE-N | N-gram overlap (Unigrams, Bigrams, etc.) | Basic text similarity |
| ROUGE-S | Skip-Bigram overlap | Capturing flexible phrasing |
| ROUGE-W | Weighted LCS | Evaluating fluency and coherence |
| ROUGE-L | Longest Common Subsequence | Measuring sentence structure |
| ROUGE-SU | Skip-bigrams + Unigrams | Handling varied text structures |
| ROUGE-Lsum | LCS for summaries | Summarization tasks |
How to Use ROUGE for LLM Evaluation?
Input: ROUGE requires three main inputs.
Generated Text (Hypothesis)
This is the text output produced by a model, such as an LLM-generated summary or response. The generated text is evaluated against a reference text to determine how well it captures key information. The quality of the hypothesis directly impacts the ROUGE score, as longer, more detailed responses may achieve higher recall but lower precision.
Reference Text (Ground Truth)
The reference text serves as the ideal or correct response, typically written by humans. It acts as a benchmark for evaluating the generated text’s accuracy. In many cases, multiple reference texts are used to account for variations in wording and phrasing. Using multiple references can provide a more balanced assessment, as different human-written texts might convey the same meaning in different ways.
Evaluation Parameters
ROUGE allows users to specify different evaluation settings based on their needs. The key parameters include:
- N-gram size: Defines the number of words in a sequence used for overlap comparison (e.g., ROUGE-1 for unigrams, ROUGE-2 for bigrams).
- LCS (Longest Common Subsequence) weight: Adjusts the impact of longer shared word sequences in ROUGE-L calculations.
- Aggregation method: Determines how scores are averaged when multiple reference texts are available. Common approaches include macro-averaging (averaging across all references) and micro-averaging (considering occurrences proportionally across all instances).
Output
ROUGE provides numerical scores that indicate the similarity between the generated and reference texts. These scores are calculated for different ROUGE variants and include three main components:
- Recall (r) – Measures how much of the reference text appears in the generated text.
- Precision (p) – Measures how much of the generated text matches the reference text.
- F1-score (f) – The harmonic mean of recall and precision, balancing both metrics.
A typical output from ROUGE (in Python) looks like this:
{
"rouge-1": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-2": {"r": 0.2, "p": 0.16, "f": 0.18},
"rouge-l": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-s": {"r": 0.55, "p": 0.4, "f": 0.46}
}Among these, ROUGE-L and ROUGE-S provide additional insights into text similarity. ROUGE-L focuses on the longest common subsequence (LCS), making it useful for evaluating fluency and sentence structure. On the other hand, ROUGE-S (Skip-Bigram) measures word pair overlaps even when they are not adjacent, capturing more flexible phrasing.
The computed scores can vary when multiple reference texts are available. In such cases, ROUGE allows aggregation across multiple references using two methods:
- Macro-averaging: Computes ROUGE scores for each reference separately and then averages them.
- Micro-averaging: Combines all reference texts and evaluates them collectively, giving more weight to longer references.
For instance, when aggregating ROUGE scores across multiple reference texts, we obtain:
Macro-Averaged Scores:
ROUGE-1 F1-score: 0.71
ROUGE-2 F1-score: 0.21
ROUGE-L F1-score: 0.67
ROUGE-S F1-score: 0.51
Micro-Averaged Scores:
ROUGE-1 F1-score: 0.72
ROUGE-2 F1-score: 0.24
ROUGE-L F1-score: 0.69
ROUGE-S F1-score: 0.53These aggregated scores provide a more reliable evaluation of model performance when multiple references exist. By considering macro-averaging, which treats each reference equally, and micro-averaging, which accounts for variations in reference length, ROUGE ensures a more balanced assessment of text generation quality.
ROUGE Implementation in Python
We will now implement ROUGE in Python.
Step1: Importing libraries
from rouge import RougeStep2: Example Implementation
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
class LLMEvaluator:
def __init__(self, model_name):
self.rouge = Rouge()
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
def evaluate_model_response(self, prompt, reference_response):
# Generate model response
inputs = self.tokenizer(prompt, return_tensors="pt")
output = self.model.generate(**inputs, max_length=100)
generated_response = self.tokenizer.decode(output[0])
# Compute ROUGE scores
rouge_scores = self.rouge.get_scores(generated_response, reference_response)[0]
return {
'generated_response': generated_response,
'rouge_scores': rouge_scores
}
ROUGE Implementation with and without Aggregation
Step 1: Importing libraries
We first import the Rouge class from the rouge package to compute similarity scores between generated and reference text.
from rouge import RougeStep 2: Example Implementation
We define a LLMEvaluator class that loads a pre-trained causal language model and tokenizer. The class generates responses for a given prompt and computes ROUGE scores by comparing them with a reference response.
# Example: Single reference text vs. generated text
generated_text = "A cat was sitting on a mat."
reference_text = "The cat sat on the mat."
rouge = Rouge()
# Compute ROUGE scores without aggregation (single reference)
scores = rouge.get_scores(generated_text, reference_text)
print("ROUGE Scores (Without Aggregation):")
print(scores)
# Example with multiple references
reference_texts = [
"The cat sat on the mat.",
"A small cat rested on the mat.",
"A feline was sitting quietly on a rug."
]
# Compute ROUGE scores with aggregation
aggregated_scores = rouge.get_scores(generated_text, reference_texts, avg=True)
print("\nROUGE Scores (With Aggregation across Multiple References):")
print(aggregated_scores)Step 3: Output
Without aggregation (Single Reference)
[
{
"rouge-1": {"r": 0.75, "p": 0.6, "f": 0.66},
"rouge-2": {"r": 0.2, "p": 0.16, "f": 0.18},
"rouge-l": {"r": 0.75, "p": 0.6, "f": 0.66}
}
]
With aggregation (Multiple References)
{
"rouge-1": {"r": 0.78, "p": 0.65, "f": 0.71},
"rouge-2": {"r": 0.25, "p": 0.20, "f": 0.22},
"rouge-l": {"r": 0.80, "p": 0.67, "f": 0.73}
}ROUGE: The Stand-Up Comedian of Metrics
Top 3 Translation Jokes ROUGE Would Appreciate:
- Why did the translator go to therapy? Too many unresolved references!
- What’s a language model’s favorite dance? The N-gram Shuffle!
- How does ROUGE tell a joke? With perfect recall and precision!
Beyond the humor, ROUGE represents a critical breakthrough in understanding how machines comprehend language. It’s not just about counting words – it’s about capturing the soul of communication.
Use Cases of ROUGE
- Evaluating Summarization Models: ROUGE is the standard metric for summarization tasks.
- Assessing LLM Performance: Used to compare LLM-generated content with human-written references.
- Machine Translation Evaluation: Helps in measuring similarity with reference translations.
- Dialogue Generation: Evaluates chatbot and conversational AI responses.
- Automated Content Scoring: Used in educational platforms to assess student-generated answers.
- Text-Based Question Answering: Helps measure how accurately AI-generated answers align with expected responses.
The Translation Roulette Challenge
def translation_detective_game():
translations = [
"The cat sat on the mat.",
"A feline occupied a floor covering.",
"Whiskers found horizontal support on the textile surface."
]
print("🕵️ ROUGE DETECTIVE CHALLENGE 🕵️")
print("Guess which translation is closest to the original!")
# Simulated ROUGE scoring (with a twist of humor)
def rouge_score(text):
# Totally scientific detective method
return random.uniform(0.5, 0.9)
for translation in translations:
score = rouge_score(translation)
print(f"Translation: '{translation}'")
print(f"Mystery Score: {score:.2f} 🕵️♀️")
print("\nCan you crack the ROUGE code?")
translation_detective_game()
Limitations and Bias in ROUGE
We will now look into the limitations and bias in ROUGE.
- Surface-Level Comparison: ROUGE focuses on n-gram overlap, ignoring meaning and context.
- Synonym and Paraphrasing Issues: It penalizes variations even if they preserve meaning.
- Bias Toward Longer Texts: Higher recall can inflate scores without truly improving quality.
- Does Not Measure Fluency or Grammar: It does not capture sentence coherence and readability.
- Inability to Handle Factual Correctness: ROUGE does not verify whether generated content is factually accurate.
Conclusion
ROUGE is like a GPS for language models—useful for navigation, but unable to truly understand the journey. As AI continues to push boundaries, our evaluation metrics must evolve from mere number-crunching to genuine comprehension. The future of LLM assessment isn’t about counting word matches, but about capturing the essence of human communication—nuance, creativity, and meaning.
While ROUGE provides a crucial first step in quantifying text similarity, it remains just that—a first step. The true difficulty is in creating assessment measures that can differentiate between a technically sound response and one that is genuinely intelligent. As language models advance, our evaluation techniques must also advance, evolving from straightforward measurement instruments to complex interpreters of text produced by machines.
Key Takeaways
- ROUGE is a critical metric for evaluating Large Language Model (LLM) outputs in summarization, translation, and text generation tasks.
- Different ROUGE variants (ROUGE-N, ROUGE-L, ROUGE-S) measure text similarity using n-grams, longest common subsequence, and skip-bigrams.
- ROUGE prioritizes recall over precision, making it particularly useful for evaluating how much key information is retained.
- It has limitations, as it does not fully capture semantic meaning, requiring complementary metrics like BERTScore and METEOR.
- Python implementation of ROUGE allows developers to assess model-generated text against human-written references effectively.
Frequently Asked Questions
Q1. What is ROUGE used for?
A. ROUGE is an evaluation metric used to assess text similarity in NLP tasks like summarization and machine translation.
Q2. How does ROUGE differ from BLEU?
A. ROUGE focuses on recall (capturing key information), while BLEU emphasizes precision (matching exact words and phrases).
Q3. What are the key ROUGE variants?
A. The main types are ROUGE-N (n-gram overlap), ROUGE-L (longest common subsequence), and ROUGE-S (skip-bigram overlap).
Q4. Can ROUGE evaluate semantic meaning?
A. No, ROUGE measures lexical overlap but does not fully capture meaning; BERTScore and METEOR are better for semantics.
Q5. How is ROUGE implemented in Python?
A. The rouge library in Python allows users to compute ROUGE scores by comparing generated text with reference text.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]




