Summary
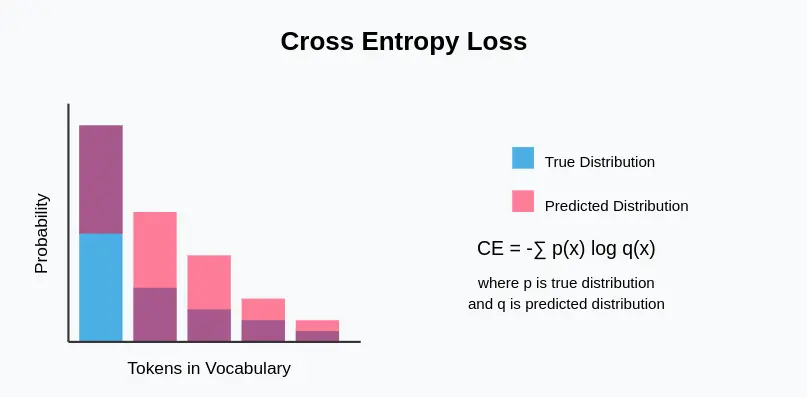
- Cross entropy measures, in bits, how surprising the true token is under your model’s predicted distribution.
- Cross entropy is the objective you actively optimize during both pre‑training and fine‑tuning, but it’s also used passively as an evaluation metric.
- Cross entropy is used to train and evaluate language models for tasks such as machine translation, text generation, and sentiment analysis.
Cross entropy loss stands as one of the cornerstone metrics in evaluating language models, serving as both a training objective and an evaluation metric. In this comprehensive guide, we’ll explore what cross entropy loss is, how it works specifically in the context of large language models (LLMs), and why it matters so much for understanding model performance.
Whether you’re a machine learning practitioner, a researcher, or someone looking to understand how modern AI systems are trained and evaluated, this article will provide you with a thorough understanding of cross entropy loss and its significance in the world of language modeling.
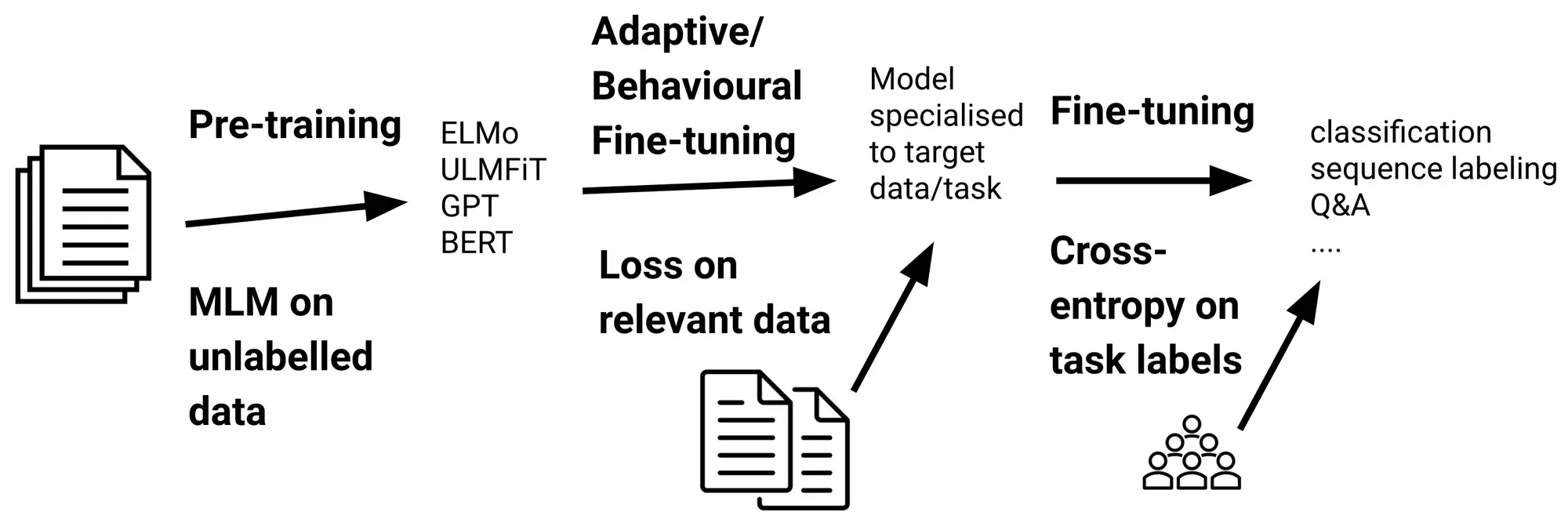
Table of contents
What is Cross Entropy Loss?
Cross entropy loss measures the performance of a classification model whose output is a probability distribution. In the context of language models, it quantifies the difference between the predicted probability distribution of the next token and the actual distribution (usually a one-hot encoded vector representing the true next token).
Key Features of Cross-Entropy Loss
- Information Theory Foundation: Rooted in information theory, cross entropy measures how many bits of information are needed to identify events from one probability distribution (the true distribution) if a coding scheme optimized for another distribution (the predicted one) is used.
- Probabilistic Output: Works with models that produce probability distributions rather than deterministic outputs.
- Asymmetric: Unlike some other distance metrics, cross entropy is not symmetric—the ordering of the true and predicted distributions matters.
- Differentiable: Critical for gradient-based optimization methods used in neural network training.
- Sensitive to Confidence: Heavily penalizes confident but wrong predictions, encouraging models to be uncertain when appropriate.
Also Read: How to Evaluate a Large Language Model (LLM)?
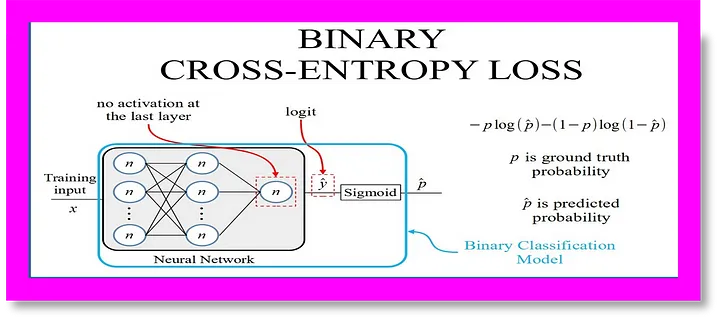
Binary Cross Entropy & Formula
For binary classification tasks (such as simple yes/no questions or sentiment analysis), binary cross entropy is used:
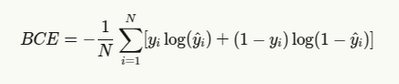
Where:
- yi is the true label (0 or 1)
- yi is the predicted probability
- N is the number of samples
Binary cross entropy is also known as log loss, particularly in machine learning competitions.
Cross Entropy as a Loss Function
During training, cross entropy serves as the objective function that the model tries to minimize. By comparing the model’s predicted probability distribution with the ground truth, the training algorithm adjusts model parameters to reduce the discrepancy between predictions and reality.
Cross Entropy’s Role in LLMs
In Large Language Models, cross entropy loss plays several crucial roles:
- Training Objective: The primary goal during pre-training and fine-tuning is to minimize loss.
- Evaluation Metric: Used to evaluate model performance on held-out data.
- Perplexity Calculation: Perplexity, another common LLM evaluation metric, is derived from cross entropy: Perplexity=2^{CrossEntropy}.
- Model Comparison: Different models can be compared based on their loss on the same dataset.
- Transfer Learning Assessment: This can indicate how well a model transfers knowledge from pre-training to downstream tasks.
How Does It Work?
For language models, cross entropy loss works as follows:
- The model predicts a probability distribution over the entire vocabulary for the next token.
- This distribution is compared with the true distribution (usually a one-hot vector where the actual next token has probability 1).
- The negative log-likelihood of the true token under the model’s distribution is calculated.
- This value is averaged over all tokens in the sequence or dataset.
Formulas and Explanation
The general formula for cross entropy loss in language modeling is:
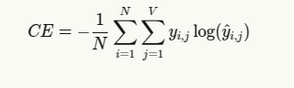
Where:
- N is the number of tokens in the sequence
- V is the vocabulary size
- yi, j is 1 if token j is the correct next token at position i, otherwise 0
- yi, j is the predicted probability of token j at position i
Since we’re usually dealing with a one-hot encoded ground truth, this simplifies to:
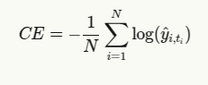
Where ti is the index of the true token at position i.
Cross Entropy Loss Implementation in PyTorch and TensorFlow Code
# PyTorch Implementation
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# Simple Language Model in PyTorch
class SimpleLanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(SimpleLanguageModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
# x shape: [batch_size, sequence_length]
embedded = self.embedding(x) # [batch_size, sequence_length, embedding_dim]
lstm_out, _ = self.lstm(embedded) # [batch_size, sequence_length, hidden_dim]
logits = self.fc(lstm_out) # [batch_size, sequence_length, vocab_size]
return logits
# Manual Cross Entropy Loss calculation
def manual_cross_entropy_loss(logits, targets):
"""
Computes cross entropy loss manually
Args:
logits: Raw model outputs [batch_size, sequence_length, vocab_size]
targets: True token indices [batch_size, sequence_length]
"""
batch_size, seq_len, vocab_size = logits.shape
# Reshape for easier processing
logits = logits.reshape(-1, vocab_size) # [batch_size*sequence_length, vocab_size]
targets = targets.reshape(-1) # [batch_size*sequence_length]
# Convert logits to probabilities using softmax
probs = F.softmax(logits, dim=1)
# Get probability of the correct token for each position
correct_token_probs = probs[range(len(targets)), targets]
# Compute negative log likelihood
nll = -torch.log(correct_token_probs + 1e-10) # Add small epsilon to prevent log(0)
# Average over all tokens
loss = torch.mean(nll)
return loss
# Example usage
def pytorch_example():
# Parameters
vocab_size = 10000
embedding_dim = 128
hidden_dim = 256
batch_size = 32
seq_length = 50
# Sample data
inputs = torch.randint(0, vocab_size, (batch_size, seq_length))
targets = torch.randint(0, vocab_size, (batch_size, seq_length))
# Create model
model = SimpleLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Get model outputs
logits = model(inputs)
# PyTorch's built-in loss function
criterion = nn.CrossEntropyLoss()
# For CrossEntropyLoss, we need to reshape
pytorch_loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
# Our manual implementation
manual_loss = manual_cross_entropy_loss(logits, targets)
print(f"PyTorch CrossEntropyLoss: {pytorch_loss.item():.4f}")
print(f"Manual CrossEntropyLoss: {manual_loss.item():.4f}")
return model, logits, targets
# TensorFlow Implementation
def tensorflow_implementation():
import tensorflow as tf
# Parameters
vocab_size = 10000
embedding_dim = 128
hidden_dim = 256
batch_size = 32
seq_length = 50
# Simple Language Model in TensorFlow
class TFSimpleLanguageModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(TFSimpleLanguageModel, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(hidden_dim, return_sequences=True)
self.fc = tf.keras.layers.Dense(vocab_size)
def call(self, x):
embedded = self.embedding(x)
lstm_out = self.lstm(embedded)
return self.fc(lstm_out)
# Create model
tf_model = TFSimpleLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Sample data
tf_inputs = tf.random.uniform((batch_size, seq_length), minval=0, maxval=vocab_size, dtype=tf.int32)
tf_targets = tf.random.uniform((batch_size, seq_length), minval=0, maxval=vocab_size, dtype=tf.int32)
# Get model outputs
tf_logits = tf_model(tf_inputs)
# TensorFlow's built-in loss function
tf_loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
tf_loss = tf_loss_fn(tf_targets, tf_logits)
# Manual cross entropy calculation in TensorFlow
def tf_manual_cross_entropy(logits, targets):
batch_size, seq_len, vocab_size = logits.shape
# Reshape
logits_flat = tf.reshape(logits, [-1, vocab_size])
targets_flat = tf.reshape(targets, [-1])
# Convert to probabilities
probs = tf.nn.softmax(logits_flat, axis=1)
# Get correct token probabilities
indices = tf.stack([tf.range(tf.shape(targets_flat)[0], dtype=tf.int32), tf.cast(targets_flat, tf.int32)], axis=1)
correct_probs = tf.gather_nd(probs, indices)
# Compute loss
loss = -tf.reduce_mean(tf.math.log(correct_probs + 1e-10))
return loss
manual_tf_loss = tf_manual_cross_entropy(tf_logits, tf_targets)
print(f"TensorFlow CrossEntropyLoss: {tf_loss.numpy():.4f}")
print(f"Manual TF CrossEntropyLoss: {manual_tf_loss.numpy():.4f}")
return tf_model, tf_logits, tf_targets
# Visualizing Cross Entropy
def visualize_cross_entropy():
# True label is 1 (one-hot encoding would be [0, 1])
true_label = 1
# Range of predicted probabilities for class 1
predicted_probs = np.linspace(0.01, 0.99, 100)
# Calculate cross entropy loss for each predicted probability
cross_entropy = [-np.log(p) if true_label == 1 else -np.log(1-p) for p in predicted_probs]
# Plot
plt.figure(figsize=(10, 6))
plt.plot(predicted_probs, cross_entropy)
plt.title('Cross Entropy Loss vs. Predicted Probability (True Class = 1)')
plt.xlabel('Predicted Probability for Class 1')
plt.ylabel('Cross Entropy Loss')
plt.grid(True)
plt.axvline(x=1.0, color='r', linestyle='--', alpha=0.5, label='True Probability = 1.0')
plt.legend()
plt.show()
# Visualize loss landscape for binary classification
probs_0 = np.linspace(0.01, 0.99, 100)
probs_1 = 1 - probs_0
# Calculate loss for true label = 0
loss_true_0 = [-np.log(1-p) for p in probs_0]
# Calculate loss for true label = 1
loss_true_1 = [-np.log(p) for p in probs_0]
plt.figure(figsize=(10, 6))
plt.plot(probs_0, loss_true_0, label='True Label = 0')
plt.plot(probs_0, loss_true_1, label='True Label = 1')
plt.title('Cross Entropy Loss for Different True Labels')
plt.xlabel('Predicted Probability for Class 1')
plt.ylabel('Cross Entropy Loss')
plt.legend()
plt.grid(True)
plt.show()
# Run examples
if __name__ == "__main__":
print("PyTorch Example:")
pt_model, pt_logits, pt_targets = pytorch_example()
print("\nTensorFlow Example:")
try:
tf_model, tf_logits, tf_targets = tensorflow_implementation()
except ImportError:
print("TensorFlow not installed. Skipping TensorFlow example.")
print("\nVisualizing Cross Entropy:")
visualize_cross_entropy()Code Analysis:
I have implemented cross entropy loss in both PyTorch and TensorFlow, showing both built-in functions and manual implementations. Let’s walk through the key components:
- SimpleLanguageModel: A basic LSTM-based language model that predicts probabilities for the next token.
- Manual Cross Entropy Implementation: Shows how cross entropy is calculated from first principles:
- Convert logits to probabilities using softmax
- Extract the probability of the correct token
- Take the negative log of these probabilities
- Average across all tokens
- Visualizations: The code includes visualizations showing how loss changes with different predicted probabilities.
Output:
PyTorch Example:
PyTorch CrossEntropyLoss: 9.2140
Manual CrossEntropyLoss: 9.2140
TensorFlow Example:
TensorFlow CrossEntropyLoss: 9.2103
Manual TF CrossEntropyLoss: 9.2103
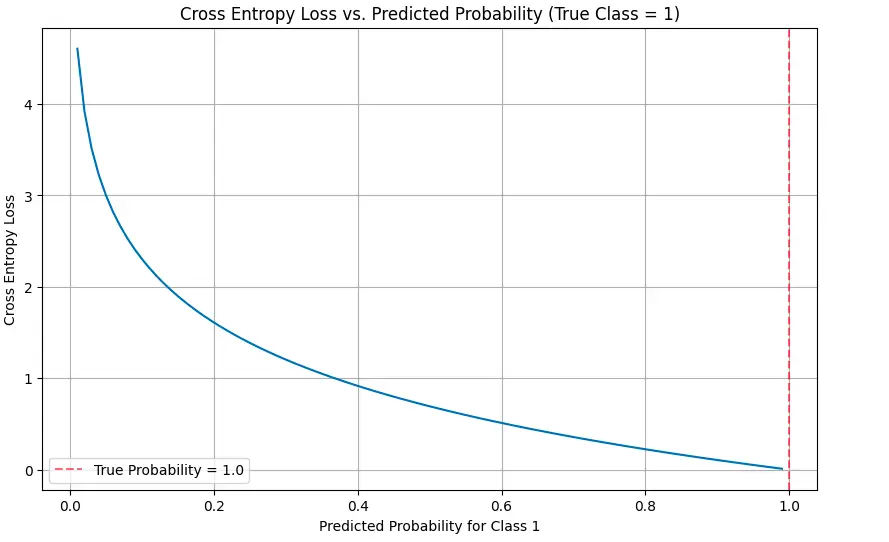
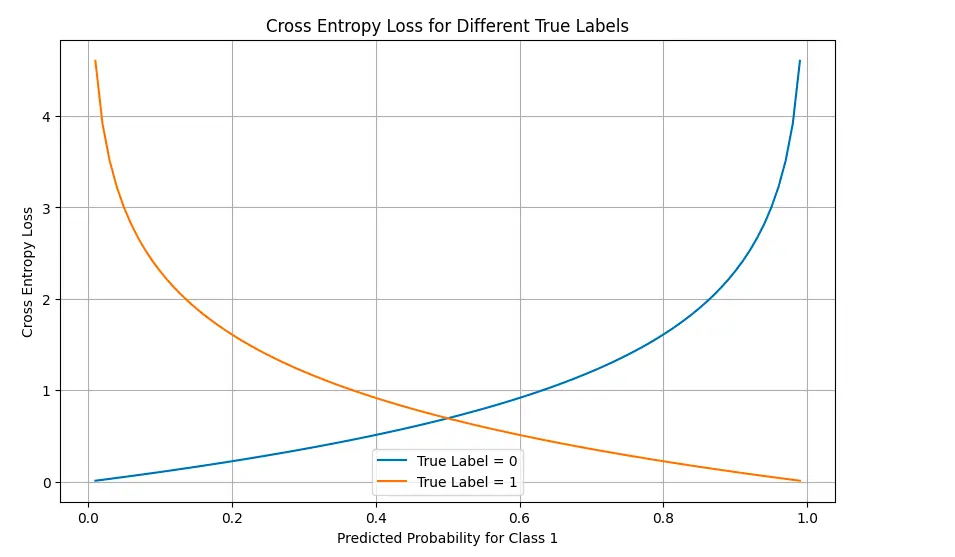
The visualizations illustrate how the loss increases dramatically as predictions diverge from the true labels, especially when the model is confidently wrong.
Advantages and Limitations
| Advantages | Limitations |
| Differentiable and smooth, enabling gradient-based optimization | Can be numerically unstable with very small probabilities (requires epsilon handling) |
| Naturally handles probabilistic outputs | May need label smoothing to prevent overconfidence |
| Well-suited for multi-class problems | Can be dominated by common classes in imbalanced datasets |
| Theoretically well-founded in information theory | Doesn’t directly optimize for specific evaluation metrics (like BLEU or ROUGE) |
| Computationally efficient | Assumes tokens are independent, ignoring sequential dependencies |
| Penalizes confident but wrong predictions | Less interpretable than metrics like accuracy or perplexity |
| Can be decomposed per token for analysis | Doesn’t account for semantic similarity between tokens |
Practical Applications
Cross entropy loss is used extensively in language model applications:
- Training Foundation Models: Cross entropy loss is the standard objective function for pre-training large language models on massive text corpora.
- Fine-tuning: When adapting pre-trained models to specific tasks, cross entropy remains the go-to loss function.
- Sequence Generation: Even when generating text, the loss during training influences the quality of the model’s outputs.
- Model Selection: When comparing different model architectures or hyperparameter settings, loss on validation data is a key metric.
- Domain Adaptation: Measuring how cross entropy changes across domains can indicate how well a model generalizes.
- Knowledge Distillation: Used to transfer knowledge from larger “teacher” models to smaller “student” models.
Comparison with Other Metrics
While cross entropy loss is fundamental, it’s often used alongside other evaluation metrics:
- Perplexity: Exponential of the cross entropy; more interpretable as it represents how “confused” the model is
- BLEU/ROUGE: For generation tasks, these metrics capture n-gram overlap with reference texts
- Accuracy: Simple percentage of correct predictions, less informative than cross entropy
- F1 Score: Balances precision and recall for classification tasks
- KL Divergence: Measures how one probability distribution diverges from another
- Earth Mover’s Distance: Accounts for semantic similarity between tokens, unlike cross entropy
Also Read: Top 15 LLM Evaluation Metrics to Explore in 2025
Conclusion
Cross entropy loss stands as an indispensable tool in the evaluation and training of language models. Its theoretical foundations in information theory, combined with its practical advantages for optimization, make it the standard choice for most NLP tasks.
Understanding cross entropy loss provides insight not just into how models are trained but also into their fundamental limitations and the trade-offs involved in language modeling. As language models continue to evolve, cross entropy loss remains a cornerstone metric, helping researchers and practitioners measure progress and guide innovation.
Whether you’re building your language models or evaluating existing ones, a thorough understanding of cross entropy loss is essential for making informed decisions and interpreting results correctly.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at riya.bansal@analyticsvidhya.com






