Have you ever thought about how to evaluate AI text evaluation effectively? Whether it’s text summarization, chatbot responses, or machine translation, we need a means to compare AI results to human expectations. This is where METEOR comes in useful!
METEOR (Metric for Evaluation of Translation with Explicit Ordering) is a powerful evaluation metric designed to assess the accuracy and fluency of machine-generated text. It takes word order, stemming, and synonyms into account, unlike more traditional approaches like BLEU. Intrigued? Let’s dive in!
Learning Objectives
- Understand how AI text evaluation works and how METEOR improves accuracy by considering word order, stemming, and synonyms.
- Learn the advantages of METEOR over traditional metrics in AI text evaluation, including its ability to align better with human judgment.
- Explore the formula and key components of METEOR, including precision, recall, and penalty.
- Gain hands-on experience implementing METEOR in Python using the NLTK library.
- Compare METEOR with other evaluation metrics to determine its strengths and limitations in NLP tasks.
Table of contents
- What is a METEOR Score?
- How Does METEOR Work?
- Key Features of METEOR
- Formula of METEOR Score and Explanation
- Evaluation of METEOR Metric
- How to Implement METEOR in Python?
- Advantages of the METEOR Score
- Limitations of the METEOR Score
- Practical Applications of METEOR Score
- How Does METEOR Compare to Other Metrics?
- Conclusion
- Frequently Asked Questions
What is a METEOR Score?
METEOR (Metric for Evaluation of Translation with Explicit Ordering) is an NLP evaluation metric originally designed for machine translation but now widely used for evaluating various natural language generation tasks, including those performed by Large Language Models (LLMs).
Unlike simpler metrics that focus solely on exact word matches, METEOR was developed to address the limitations of other metrics by incorporating semantic similarities and alignment between a machine-generated text and its reference text(s).
Quick Check: Think of METEOR as a sophisticated judge that doesn’t just count matching words but understands when different words mean similar things!
How Does METEOR Work?
METEOR evaluates text quality through a step-by-step process:

- Alignment: First, METEOR creates an alignment between the words in the generated text and reference text(s).
- Matching: It identifies matches based on:
- Exact matches (identical words)
- Stem matches (words with the same root)
- Synonym matches (words with similar meanings)
- Paraphrase matches (phrases with similar meanings)
- Scoring: METEOR calculates precision, recall, and a weighted F-score.
- Penalty: It applies a fragmentation penalty to account for word order and fluency.
- Final Score: The final METEOR score combines the F-score and penalty.

It improves upon older methods by incorporating:
- Precision & Recall: Ensures a balance between correctness and coverage.
- Synonyms Matching: Identifies words with similar meanings.
- Stemming: Recognizes words in different forms (e.g., “run” vs. “running”).
- Word Order Penalty: Penalizes incorrect word sequence while allowing slight flexibility.
Try It Yourself: Consider these two translations of a French sentence:
- Reference: “The cat is sitting on the mat.”
- Translation A: “The feline is sitting on the mat.”
- Translation B: “Mat the one sitting is cat the.”
Which do you think would get a higher METEOR score? (Translation A would score higher because while it uses a synonym, the order is preserved. Translation B has all the right words but in a completely jumbled order, triggering a high fragmentation penalty.)
Key Features of METEOR
METEOR stands out from other evaluation metrics with these distinctive characteristics:
- Semantic Matching: Goes beyond exact matches to recognize synonyms and paraphrases
- Word Order Consideration: Penalizes incorrect word ordering
- Weighted Harmonic Mean: Balances precision and recall with adjustable weights
- Language Adaptability: Can be configured for different languages
- Multiple References: Can evaluate against multiple reference texts

Why It Matters: These features make METEOR particularly valuable for evaluating creative text generation tasks where there are many valid ways to express the same idea.
Formula of METEOR Score and Explanation
The METEOR score is calculated using the following formula:
METEOR = (1 – Penalty) × F_mean
Where:
F_mean is the weighted harmonic mean of precision and recall:

- P (Precision) = Number of matched words in the candidate / Total words in candidate
- R (Recall) = Number of matched words in the candidate / Total words in reference
Penalty accounts for fragmentation:
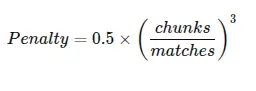
- chunks is the total number of chunks
- matched_chunks is the total number of matched words
Evaluation of METEOR Metric
METEOR has been extensively evaluated against human judgments:

- Correlation with Human Judgment: Studies show METEOR correlates better with human evaluations compared to metrics like BLEU, particularly for evaluating fluency and adequacy.
- Performance Across Languages: METEOR performs consistently across different languages, especially when language-specific resources (like WordNet for English) are available.
- Robustness: METEOR shows greater stability when evaluating shorter texts compared to n-gram based metrics.
Research Finding: In studies comparing various metrics, METEOR typically achieves correlation coefficients with human judgments in the range of 0.60-0.75, outperforming BLEU which usually scores in the 0.45-0.60 range.
How to Implement METEOR in Python?
Implementing METEOR is straightforward using the NLTK library in Python:
Step1: Install Required Libraries
Below we will first install all required libraries.
pip install nltkStep2: Download Required NLTK Resources
Next we will download required NLTK resources.
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4')Example Code
Here’s a comprehensive example showing how to calculate METEOR scores in Python:
import nltk
from nltk.translate.meteor_score import meteor_score
# Ensure required resources are downloaded
nltk.download('wordnet', quiet=True)
nltk.download('omw-1.4', quiet=True)
# Define reference and hypothesis texts
reference = "The quick brown fox jumps over the lazy dog."
hypothesis_1 = "The fast brown fox jumps over the lazy dog."
hypothesis_2 = "Brown quick the fox jumps over the dog lazy."
# Calculate METEOR scores
score_1 = meteor_score([reference.split()], hypothesis_1.split())
score_2 = meteor_score([reference.split()], hypothesis_2.split())
print(f"Reference: {reference}")
print(f"Hypothesis 1: {hypothesis_1}")
print(f"METEOR Score 1: {score_1:.4f}")
print(f"Hypothesis 2: {hypothesis_2}")
print(f"METEOR Score 2: {score_2:.4f}")
# Example with multiple references
references = [
"The quick brown fox jumps over the lazy dog.",
"A swift brown fox leaps above the sleepy hound."
]
hypothesis = "The fast brown fox jumps over the sleepy dog."
# Convert strings to lists of tokens
references_tokenized = [ref.split() for ref in references]
hypothesis_tokenized = hypothesis.split()
# Calculate METEOR score with multiple references
multi_ref_score = meteor_score(references_tokenized, hypothesis_tokenized)
print("\nMultiple References Example:")
print(f"References: {references}")
print(f"Hypothesis: {hypothesis}")
print(f"METEOR Score: {multi_ref_score:.4f}")Example Output:
Reference: The quick brown fox jumps over the lazy dog.
Hypothesis 1: The fast brown fox jumps over the lazy dog.
METEOR Score 1: 0.9993
Hypothesis 2: Brown quick the fox jumps over the dog lazy.
METEOR Score 2: 0.7052
Multiple References Example:
References: ['The quick brown fox jumps over the lazy dog.', 'A swift brown fox leaps above the sleepy hound.']
Hypothesis: The fast brown fox jumps over the sleepy dog.
METEOR Score: 0.8819
Challenge for you: Try modifying the hypotheses in various ways to see how the METEOR score changes. What happens if you replace words with synonyms? What if you completely rearrange the word order?
Advantages of the METEOR Score
METEOR offers several advantages over other metrics:
- Semantic Understanding: Recognizes synonyms and paraphrases, not just exact matches
- Word Order Sensitivity: Considers fluency through its fragmentation penalty
- Balanced Evaluation: Combines precision and recall in a weighted manner
- Linguistic Resources: Leverages language resources like WordNet
- Multiple References: Can evaluate against multiple reference translations
- Language Flexibility: Adaptable to different languages with appropriate resources
- Interpretability: Components (precision, recall, penalty) can be analyzed separately
Best For: Complex evaluation scenarios where semantic equivalence matters more than exact wording.
Limitations of the METEOR Score
Despite its strengths, METEOR has some limitations:
- Resource Dependency: Requires linguistic resources (like WordNet) which may not be equally available for all languages
- Computational Overhead: More computationally intensive than simpler metrics like BLEU
- Parameter Tuning: Optimal parameter settings may vary across languages and tasks
- Limited Context Understanding: Still doesn’t fully capture contextual meaning beyond phrase level
- Domain Sensitivity: Performance may vary across different text domains
- Length Bias: May favor certain text lengths in some implementations
Consider This: When evaluating specialized technical content, METEOR might not recognize domain-specific equivalences unless supplemented with specialized dictionaries.
Practical Applications of METEOR Score
METEOR finds application in various natural language processing tasks:
- Machine Translation Evaluation: Its original purpose, comparing translations across languages
- Summarization Assessment: Evaluating the quality of automatic text summaries
- LLM Output Evaluation: Measuring the quality of text generated by language models
- Paraphrasing Systems: Evaluating automatic paraphrasing tools
- Image Captioning: Assessing the quality of automatically generated image descriptions
- Dialogue Systems: Evaluating responses in conversational AI
Real-World Example: The WMT (Workshop on Machine Translation) competitions have used METEOR as one of their official evaluation metrics, influencing the development of commercial translation systems.
How Does METEOR Compare to Other Metrics?
Let’s compare METEOR with other popular evaluation metrics:
| Metric | Strengths | Weaknesses | Best For |
| METEOR | Semantic matching, word order sensitivity | Resource dependency, computational cost | Tasks where meaning preservation is critical |
| BLEU | Simplicity, language-independence | Ignores synonyms, poor for single sentences | High-level system comparisons |
| ROUGE | Good for summarization, simple to implement | Focuses on recall, limited semantic understanding | Summarization tasks |
| BERTScore | Contextual embeddings, strong correlation with humans | Computationally expensive, complex | Nuanced semantic evaluation |
| ChrF | Character-level matching, good for morphologically rich languages | Limited semantic understanding | Languages with complex word forms |
Choose METEOR when evaluating creative text where there are multiple valid ways to express the same meaning, and when reference texts are available.
Conclusion
METEOR represents a significant advancement in natural language generation evaluation by addressing many limitations of simpler metrics. Its ability to recognize semantic similarities, account for word order, and balance precision and recall makes it particularly valuable for evaluating LLM outputs where exact word matches are less important than preserving meaning.
As language models continue to evolve, evaluation metrics like METEOR will play a crucial role in guiding their development and assessing their performance. While not perfect, METEOR’s approach to evaluation aligns well with how humans judge text quality, making it a valuable tool in the NLP practitioner’s toolkit.
For tasks where semantic equivalence matters more than exact wording, METEOR provides a more nuanced evaluation than simpler n-gram based metrics, helping researchers and developers create more natural and effective language generation systems.
Key Takeaways
- METEOR enhances AI text evaluation by considering word order, stemming, and synonyms, offering a more human-aligned assessment.
- Unlike traditional metrics, AI text evaluation with METEOR provides better accuracy by incorporating semantic matching and flexible scoring.
- METEOR performs well across languages and multiple NLP tasks, including machine translation, summarization, and chatbot evaluation.
- Implementing METEOR in Python is straightforward using the NLTK library, allowing developers to assess text quality effectively.
- Compared to BLEU and ROUGE, METEOR offers better semantic understanding but requires linguistic resources like WordNet.
Frequently Asked Questions
Q1. What is METEOR in NLP?
A. METEOR (Metric for Evaluation of Translation with Explicit ORdering) is an evaluation metric designed to assess the quality of machine-generated text by considering word order, stemming, synonyms, and paraphrases.
Q2. How does METEOR differ from BLEU?
A. Unlike BLEU, which relies on exact word matches and n-grams, METEOR incorporates semantic understanding by recognizing synonyms, stemming, and paraphrasing, making it more aligned with human evaluations.
Q3. Why is METEOR better for evaluating AI-generated text?
A. METEOR accounts for fluency, coherence, and meaning preservation by penalizing incorrect word ordering and rewarding semantic similarity, making it a more human-like evaluation method than simpler metrics.
Q4. Can METEOR be used for tasks beyond machine translation?
A. Yes, METEOR is widely used for evaluating summarization, chatbot responses, paraphrasing, image captioning, and other natural language generation tasks.
Q5. Does METEOR work for multiple reference texts?
A. Yes, METEOR can evaluate a candidate text against multiple references, improving the accuracy of its assessment by considering different valid expressions of the same idea.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]






