As Large Language Models (LLMs) continue to advance quickly, one of their most sight after applications is in RAG systems. Retrieval-Augmented Generation, or RAG connects these models to external information sources, thereby increasing their usability. This helps ground their answers to facts, making them more reliable. In this article, we will compare the performance and accuracy of two notable models: Meta’s Llama 4 Scout and OpenAI’s GPT-4o in RAG systems. We will first build a RAG system using tools like LangChain, FAISS, and FastEmbed, and then do the evaluation and Llama 4 vs. GPT-4o comparison using the RAGAS framework.
Table of Contents
Getting to Know the Models
Before diving into the comparison, let’s briefly introduce the two models:
Llama 4 Scout
Llama 4 Scout is the most efficient model of Meta’s newly released Llama 4 family. The model that looks promising in benchmark tests, understands up to 10 million tokens, which is quite large. It’s also noted for handling sensitive questions with fewer refusals compared to some other models. Llama 4 on the Groq API is often noted for its inference speed as well.
Because Meta released its weights openly, developers can inspect and use its pre-trained parameters. This transparency makes it appealing for research and custom development.
Also Read: How to Access Meta’s Llama 4 Models via API
GPT-4o
GPT-4o represents OpenAI’s latest step in the GPT series. It brings improvements in reasoning ability, coding tasks, and the overall quality of its responses. It’s built to be efficient with computing resources while competing strongly against other top models.
Also Read: DeepSeek V3 vs Llama 4: Which Model Reigns Supreme?
What is RAGAS?
Evaluating a RAG system involves checking how well it retrieves information, and also how well it generates an answer based on that information. Simply looking at the final answer isn’t enough.
RAGAS (Retrieval-Augmented Generation Assessment Suite) provides metrics to evaluate different parts of the RAG process without needing a pre-written perfect answer. Key metrics used in RAGAS include:
- Faithfulness: Does the generated answer accurately represent the information found in the retrieved documents?
- Answer Relevancy: Is the answer actually relevant to the question asked?
- Context Precision & Recall: How effective was the retrieval step? Did it find relevant
Using these metrics, we can get a clearer picture of where a RAG system excels and where it might be failing. Now let’s see how we can implement RAG and evaluate the models using RAGAS.
RAG Implementation and Evaluation Using RAGAS
In this section, we’ll first delve into the steps and the related code from the Jupyter Notebook used to set up the RAG pipeline. We’ll include chat instances using both GPT-4o and Llama 4 Scout, via the Groq platform. We will then run the RAGAS evaluation on both the RAG systems.
Building the RAG System
Here are the steps to follow to build a RAG system using GPT-4o and Llama 4.
1. Install Necessary Libraries
First, we need to install the required Python packages for LangChain, Groq, OpenAI, vector stores (FAISS), PDF processing (PyMuPDF), embeddings (FastEmbed), and evaluation (Ragas).
!pip install -q langchain_groq langchain_community faiss-cpu pymupdf langchain fastembed langchain-openai2. Set Up API Keys
Next, we have to configure API keys for OpenAI and Groq. The code uses Google Colab’s userdata feature for secure key management.
import os
os.environ["OPENAI_API_KEY"] = “your_openai_api”
os.environ["GROQ_API_KEY"] = “your_groq_api”3. Import Libraries
We will now import the specific classes and functions needed from the installed libraries.
import os
import fitz
import numpy as np
import faiss
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datasets import Dataset
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_groq import ChatGroq
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision4. Initialize Language Models
Now is the main part. We need to create instances of the chat models we want to compare: GPT-4o and Llama 4 Scout (via Groq). While setting this up, note that temperature=1 allows for more variability in responses compared to temperature=0.
chat_model_4o = ChatOpenAI(temperature=1, model_name="gpt-4o")
chat_model_llama = ChatGroq(temperature=1,
model_name="meta-llama/llama-4-scout-17b-16e-instruct")5. Initialize Embedding Model and Text Splitter
Once the initialization is done, we can set up the model for converting text to vectors (FastEmbedEmbeddings). We also need to initialize the tool for breaking documents into smaller chunks (RecursiveCharacterTextSplitter).
embed_model = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")
splitter = RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=200)Explanation:
- FastEmbedEmbeddings is initialized with the BAAI/bge-base-en-v1.5 model, converting text into numerical embeddings.
- RecursiveCharacterTextSplitter is set to create text chunks of 1000 characters, with a 200-character overlap.
- Hugging Face warning appears if no HF token is configured but doesn’t affect public models like BGE.
6. Load and Chunk Documents
This code extracts text from PDF files located in a specified data folder and splits the extracted text into manageable chunks. (You can replace it with your own pdf). Here, we are using the SWE lancer research paper.
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
return "\n".join([page.get_text() for page in doc])
folder_path = "./data/"
documents = [extract_text_from_pdf(os.path.join(folder_path, f)) for f in os.listdir(folder_path) if f.endswith(".pdf")]
all_chunks = [chunk for doc in documents for chunk in splitter.split_text(doc)]Explanation:
- The
extract_text_from_pdffunction uses the fitz library to extract text from all pages of a PDF. - It lists PDF files in the specified folder_path (ensure the folder and files exist).
- The function splits the extracted text into smaller chunks using the defined splitter.
7. Create FAISS Vector Index
We then generate embeddings for all text chunks and build a FAISS index for fast similarity searching.
embeddings = np.array(embed_model.embed_documents(all_chunks))
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)Explanation:
- Checks if all_chunks are created and uses the embed_model (FastEmbed BGE) to convert them into embeddings.
- Embeddings are stored in a NumPy array, and a FAISS index (IndexFlatL2) is created for similarity search.
- The index is populated with embeddings, with error handling for empty chunks or embeddings.
8. Define RAG Core Functions (Retrieve and Answer)
These functions implement the core RAG logic: retrieving relevant chunks based on a query and generating an answer using an LLM with those chunks as context.
def retrieve_chunks(query, k=1):
query_embedding = np.array([embed_model.embed_query(query)])
_, I = index.search(query_embedding, k)
return [all_chunks[i] for i in I[0]]
def rag_answer(model, query, retrieved_docs):
prompt = PromptTemplate(
input_variables=["document", "question"],
template="""
You are a helpful AI assistant.
Use the CONTENT below to answer the QUESTION.
If the answer isn't in the content, reply: "I don't have the answer to the question."
CONTENT: {document}
QUESTION: {question}
"""
)
chain = prompt | model | StrOutputParser()
return chain.invoke({"document": "\n".join(retrieved_docs), "question": query})Explanation:
retrieve_chunksconverts the query into an embedding and uses the FAISS index to find the closest k vectors.- It returns the text chunks corresponding to the closest vectors’ indices.
rag_answerdefines a prompt template, combines it with the model and parser, and handles empty retrieval results.
We now have our RAG systems, powered by GPT-4o and Llama 4, ready to be tested.
Evaluating the RAG System Using RAGAS
Now let’s begin with the evaluation process using RAGAS. Our goal here is to see how each model behaves in a specific setup and gain practical insights based on the observed results. Here are the steps involved:
1. Define Evaluation Questions and References
For this, we first need to set up the specific questions and corresponding ground truth (reference) answers.
questions = [
"What is the main goal of the SWE Lancer system?",
"What problem does the SWE Lancer paper try to solve?",
"What are the key features of the SWE Lancer system?",
]
references = [
"The main goal of the SWE Lancer system is to improve software engineering productivity and automation.",
"The paper addresses the problem of inefficient software engineering workflows and proposes a machine learning-based solution.",
"Key features include modular design, machine learning integration, and scalability.",
]2. Test RAG Answer Generation (Single Query)
Before the full evaluation, let’s first test the rag_answer function with both models for a single question to see their raw output.
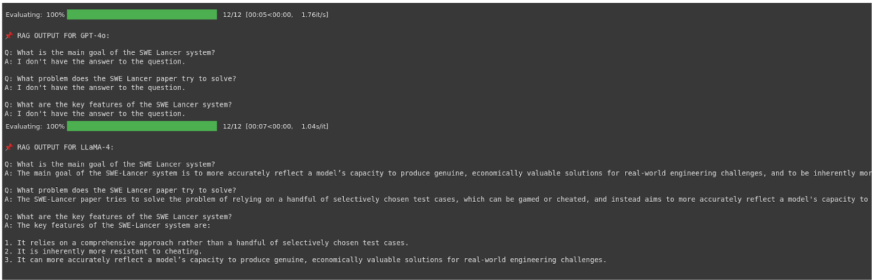
GPT-4o Test:
rag_answer(chat_model_4o, questions[2], retrieve_chunks(questions[2], k=1))Output:
I don’t have the answer to the question.
Explanation:
- Calls the
rag_answerfunction with GPT-4o, the third question, and the most relevant chunk for that question. - GPT-4o uses the retrieved context to answer, but if it’s insufficient, it states no answer is available.
- The model follows the prompt’s instruction and acknowledges when the content is not relevant.
Llama 4 Scout Test:
rag_answer(chat_model_llama, questions[2], retrieve_chunks(questions[2], k=1))Output:
The key features of the SWE-Lancer system are:\n\n1. It relies on a comprehensive set of test cases, rather than a handful of selectively chosen ones.\n2. It is inherently more resistant to cheating.\n3. It can accurately reflect a model’s capacity to produce genuine, economically valuable solutions for real-world engineering challenges.
Explanation:
- Calls
rag_answerwith the chat_model_llama (Llama 4 Scout via Groq) for the same question and retrieved chunk. - Llama 4 generates an answer, possibly from the retrieved chunk or by inferring beyond the context.
- Unlike GPT-4o, Llama 4 provides an answer even if the retrieved context may not be fully relevant.
3. Define the Full Evaluation Function (evaluate_model)
This function bundles the process of running all questions through the RAG pipeline for a given model and then scoring the results using RAGAS.
def evaluate_model(model, model_name):
answers, contexts = [], []
for q in questions:
docs = retrieve_chunks(q, k=1)
ans = rag_answer(model, q, docs)
answers.append(ans)
contexts.append(docs)
dataset = Dataset.from_dict({
"question": questions,
"answer": answers,
"contexts": contexts,
"reference": references, # required for some RAGAS metrics
})
metrics = [context_precision, context_recall, faithfulness, answer_relevancy]
result = evaluate(dataset=dataset, metrics=metrics)
df = result.to_pandas()
df["model"] = model_name
print(f"RAG OUTPUT FOR {model_name}:")
for q, a in zip(questions, answers):
print(f"\nQ: {q}\nA: {a}")
return dfExplanation:
- Iterates through each question, retrieves the top chunk, and generates answers using the model and
rag_answer. - Stores answers and contexts in a
datasets.Dataset, calculates evaluation metrics, and callsragas.evaluate. - Results are organized in a pandas DataFrame, with model name and raw Q&A outputs, and the scores are returned.
4. Run Full Evaluations and Display Results
We execute the evaluate_model function for both models and display the resulting DataFrames containing the RAGAS scores.
gpt4o_df = evaluate_model(chat_model_4o, "GPT-4o")
llama_df = evaluate_model(chat_model_llama, "LLaMA-4")Output
llama_df

Gpt4o_df

Explanation:
- Runs the evaluation using
evaluate_modelfor both GPT-4o and Llama 4 Scout, showing RAGAS progress and raw Q&A outputs. - The DataFrames (gpt4o_df and llama_df) show context_precision and context_recall as 0.0, indicating retrieval failure.
- Faithfulness is low for GPT-4o (due to refusals), but high for Llama 4 (consistent answers); answer_relevancy is high for Llama 4.
Now that the testing part is done, let’s look at the results.
Llama 4 vs. GPT-4o: Results and Analysis
The execution of the code provided clear, quantitative results via the RAGAS evaluation.
Qualitative Observations
Llama 4 Scout: As seen in the RAG output section and the single test, this model generated answers for all questions, even when the retrieved context was likely insufficient or irrelevant (indicated by RAGAS scores). The answers it provided sounded relevant to the questions asked.
GPT-4o: Consistently replied “I don’t have the answer to the question.” This aligns with the prompt’s instruction when the answer isn’t found in the provided context, indicating it correctly identifies the retrieved context as unhelpful for answering the specific questions.
Quantitative Summary
Here’s a summary of what the the RAGAS DataFrames (gpt4o_df, llama_df) show:
| Metric | LLaMA 4 Scout (Avg) | GPT-4o (Avg) | Interpretation Notes |
| Context Precision | 0.0 | 0.0 | Retrieval failed to find relevant chunks. |
| Context Recall | 0.0 | 0.0 | Retrieval failed to find relevant chunks. |
| Faithfulness | 1.0 | ~0.33 (Variable) | LLaMA stuck to the (irrelevant) context. GPT-4o refused. |
| Answer Relevancy | ~0.996 | 0.0 | LLaMA answers sound relevant. GPT-4o didn’t answer. |
Interpretation of the Result
Interpreting the RAGAS scores provides insights into the Llama 4 performance vs GPT-4o in handling retrieval failures within this specific test.
Llama 4 Scout’s Behavior
Despite poor context, Llama 4 generated answers that RAGAS deemed highly relevant (Answer Relevancy ~0.996) and perfectly faithful (Faithfulness 1.0). This means its answers, while potentially based on its internal knowledge rather than the retrieved text, were consistent with the single (irrelevant) chunk provided and sounded appropriate for the questions. It prioritized generating a plausible answer.
GPT-4o’s Behavior
GPT-4o strictly adhered to the prompt’s instruction to answer only from the context. Since the context was useless (Precision/Recall 0.0), it correctly refused to answer, resulting in Answer Relevancy 0.0. This highlights a key difference in apparent GPT-4o vs Llama 4 accuracy strategy when context is missing; GPT-4o favors silence over potential inaccuracy based on poor retrieval. Its lower average Faithfulness score reflects RAGAS sometimes penalizing these refusals, even though the refusal itself was faithful to the instruction given the bad context. It prioritized factual grounding and avoiding hallucination.
Conclusion
This experiment was to compare Llama 4 vs. GPT-4o on a specific RAG setup, using the RAGAS framework. Through our hands-on testing, we clearly demonstrated distinct behaviors between Llama 4 Scout and GPT-4o, especially when encountering retrieval failures.
Llama 4 Scout showed a tendency to produce plausible, relevant-sounding answers even with inadequate context. This is a characteristic potentially suitable for lower-stakes applications like brainstorming. Conversely, GPT-4o exhibited strong adherence to instructions by refusing to generate answers without sufficient retrieved information. This conservative approach makes it better suited for scenarios demanding high reliability and minimal hallucination.
The RAGAS framework proved essential, not only scoring the outputs but pinpointing the retrieval step’s failure (Context Precision/Recall = 0.0) as the root cause, thereby explaining the observed differences in model responses. Using this setup, you can compare the performance of any LLMs for real-world use cases.
Frequently Asked Questions
Q1. What is Retrieval-Augmented Generation (RAG)?
A. RAG enhances language models by retrieving external information before answering. This approach helps ground responses in facts, improving accuracy and relevance.
Q2. What is the purpose of an evaluation framework like RAGAS?
A. RAGAS provides specific metrics to objectively assess RAG system components like retrieval quality and answer faithfulness. It offers deeper insights than just evaluating the final answer.
Q3. Why compare different language models (like Llama 4 Scout and GPT-4o) within a RAG system?
A. Comparing models in RAG highlights their different behaviors with retrieved data. This understanding helps select the most suitable model based on specific application needs.
Q4. Which model is better for RAG: Llama 4 Scout or GPT-4o?
A. This test showed different approaches: Llama 4 answered despite poor retrieval, while GPT-4o refused, prioritizing safety. The “better” model depends entirely on the application’s specific requirements.
Q5. How can RAG system performance be improved?
A. Key improvements usually involve enhancing the information retrieval step (e.g., better search, chunking) or carefully tuning the prompts given to the language model.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕







