With the multimodal space expanding rapidly, thanks to models like Runway’s Gen-4, OpenAI’s Sora, and some quietly impressive video synthesis efforts by ByteDance, it was only a matter of time before Meta AI joined the bandwagon. And now, they have. Meta has released a research paper along with demo examples of their new video generation model, MoCha (Movie Character Animator). But how does it stand out in this increasingly crowded field? What makes it different from Sora, Pika, or any of the current AI video generation models? And more importantly, how can you use it to your benefit as a creator, developer, or researcher? These are the questions we’ll explore in this post. Let’s decode Meta’s MoCha together.
Table of contents
What is Meta’s MoCha?
MoCha (short for Movie Character Animator) is an end-to-end model that takes two inputs:
- A natural language prompt describing the character, scene, and actions
- A speech audio clip to drive lip-sync, emotion, and gestures
And then, it outputs a cinematic-quality video, no reference image, no keypoints, no extra control signals.
Just prompt + voice

That may sound simple, but under the hood, MoCha is solving a multi-layered problem: synchronizing speech with facial movement, generating full-body gestures, maintaining character consistency, and even managing turn-based dialogue between multiple speakers.
Why Talking Characters Matter?
Most existing video generation tools either focus on realistic environments (like Pika, Sora) or do facial animation with limited expression (like SadTalker or Hallo3).
But storytelling, especially cinematic storytelling, demands more.
It needs characters who move naturally, show emotion, respond to one another, and inhabit their environment in a coherent way. That’s where MoCha comes in. It’s not about just syncing lips, it’s about bringing a scene to life.
Also Read: Sora vs Veo 2: Which One Creates More Realistic Videos?
Key Features of MoCha
Here’s what stood out to me after reading the paper and reviewing the benchmarks:
End-to-End Generation with No Crutches
MoCha doesn’t rely on skeletons, keypoints, or 3D face models like many others do. This means no dependency on manually curated priors or handcrafted control. Instead, everything flows directly from text and speech. That makes it:
- Scalable across data
- Easier to generalize
- More adaptable to various shot types
Speech-Video Window Attention

Source: Meta Research Paper
This is one of the technical highlights. Generating a full video in parallel often ruins speech alignment. MoCha solves that with a clever attention trick: each video token only looks at a local window of audio tokens, just enough to capture phoneme-level timing without getting distracted by the full sequence.
Result: Tight lip-sync without frame mismatch.
Joint Training on Speech and Text
MoCha combines 80% speech-labeled video and 20% text-only video during training. It even substitutes speech tokens with zero vectors for T2V samples. That might sound like a training hack, but it’s actually quite smart: it gives MoCha a broader understanding of motion, even in the absence of audio, while preserving lip-sync learning.
Multi-Character Turn-Based Dialogue
This part surprised me. MoCha doesn’t just generate one character talking, it supports multi-character interactions in different shots.

How? Through structured prompts:
- First, define each character (e.g., Person1, Person2)
- Then describe each clip using those tags
That way, the model keeps track of who’s who, even when they reappear across different shots.
Examples of Videos Generated with Meta’s MoCha
They have uploaded quiet a lot of examples here. I am going to pick the best ones here:
Emotion Control
Action Control
Multi-Characters
Multi-character Conversation with Turn-based Dialogue
Also Read: OpenAI Sora vs AWS Nova: Which is Better for Video
MoCha-Bench: A Benchmark Built for Talking Characters
Along with the model, Meta introduced MoCha-Bench, a purpose-built benchmark for evaluating talking character generation. And it’s more than just a dataset—it’s a reflection of how seriously the team approached this task. Most existing benchmarks are designed for general video or face animation tasks. But MoCha-Bench is tailored to the very challenges MoCha is solving: lip-sync accuracy, expression quality, full-body motion, and multi-character interactions. Key components:
- 150 manually curated examples
- Each example contains:
- A structured text prompt
- A speech clip
- Evaluation clips in both close-up and medium shots
- Scenarios include:
- Emotions like anger, joy, surprise
- Activities like cooking, walking, live-streaming
- Different camera framings and transitions
The team went a step further by enriching prompts using LLaMA 3, making them more expressive and diverse than typical datasets.
Evaluation Approach
They didn’t just run automated metrics, they also ran comprehensive human evaluations. Each video was rated across five axes:
- Lip-sync quality
- Facial expression naturalness
- Action realism
- Prompt alignment
- Visual quality
On top of that, they benchmarked MoCha against SadTalker, AniPortrait, and Hallo3, using both subjective scores and synchronization metrics like Sync-C and Sync-D. This benchmark sets a new standard for evaluating speech-to-video models, especially for use cases where characters need to perform and not just speak. If you’re working in this space or plan to, MoCha-Bench gives you a realistic gauge of what “good” should look like.
Model Architecture
If you’re curious about the technical side, here’s a simplified walkthrough of how MoCha works under the hood:
- Text → Encoded via a transformer to capture scene semantics.
- Speech → Processed through Wav2Vec2, then passed through a single-layer MLP to match the video token dimensions.
- Video → Encoded by a 3D VAE, which compresses temporal and spatial resolution into latent video tokens.
- Diffusion Transformer (DiT) → Applies self-attention to video tokens, followed by cross-attention with text and speech inputs (in that order).
Unlike autoregressive video models, MoCha generates all frames in parallel. But thanks to its speech-video window attention, each frame stays tightly synced to the relevant part of the audio—resulting in smooth, realistic articulation without drift.
You can find more details here.
Training Details
MoCha uses a multi-stage training pipeline:
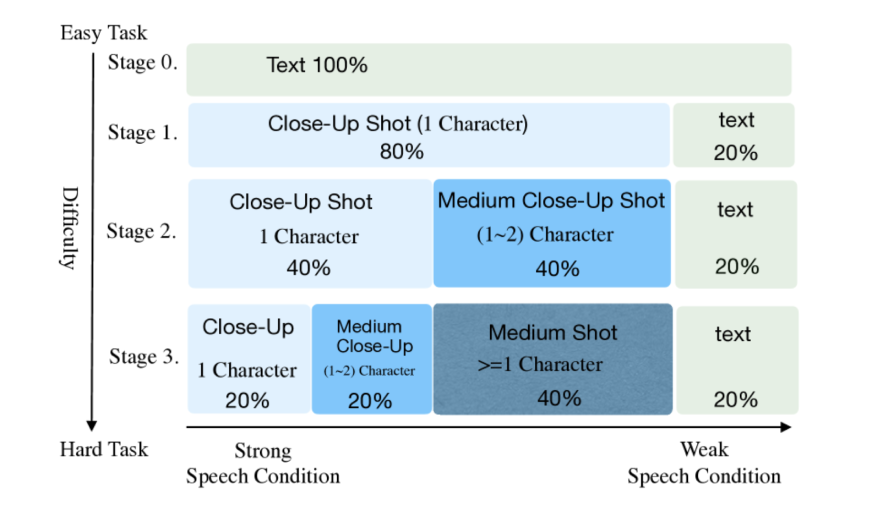
- Stage 0: Text-only video training (close-up shots)
- Stage 1: Add close-up speech-labeled videos
- Stage 2-3: Introduce medium shots, full-body gestures, and multi-character clips
Each stage reduces earlier data by half while gradually raising task difficulty.
This approach helps the model first master lip-sync (where speech is most predictive) before tackling more complex body motion.
Benchmarks and Performance
Let’s have a look at the benchmarks and performance of this model:

The chart shows human evaluation scores for MoCha and three baseline models (Hallo3, SadTalker, AniPortrait) across five criteria: lip-sync, expression, action, text alignment, and visual quality. MoCha consistently scores above 3.7, outperforming all baselines. SadTalker and AniPortrait score lowest in action naturalness due to their limited head-only motion. Text alignment is marked N/A for those two, as they don’t support text input. Overall, MoCha’s outputs are rated closest to cinematic realism across all categories.
Sync Accuracy
The following models were tested on 2 parameters:
- Sync-C: Higher is better (shows how well the lips follow the audio)
- Sync-D: Lower is better (shows how much mismatch there is)
| Model | Sync-C (↑) | Sync-D (↓) |
|---|---|---|
| MoCha | 6.037 | 8.103 |
| Hallo3 | 4.866 | 8.963 |
| SadTalker | 4.727 | 9.239 |
| AniPortrait | 1.740 | 11.383 |
MoCha had the most accurate lip-sync and the least confusion between audio and mouth movement.
What Happens If You Remove Key Features?
The researchers also tested what happens if they remove some important parts of the model.
| Version | Sync-C | Sync-D |
|---|---|---|
| Full MoCha | 6.037 | 8.103 |
| Without joint training | 5.659 | 8.435 |
| Without window attention | 5.103 | 8.851 |
Takeaway:
- Joint training (using both speech and text video during training) helps the model understand more types of scenes.
- Windowed attention is what keeps the lip-sync sharp and prevents the model from drifting off-sync.
Removing either one hurts performance noticeably.
My View on Meta’s MoCha
While there’s no public demo or GitHub repo (yet), the videos shared in the official project page are genuinely impressive. I was particularly struck by:
- The consistency of gestures with speech tone
- How well the model handled back-and-forth conversations
- Realistic hand movements and camera dynamics in medium shots
If these capabilities become accessible via an API or open model in the future, it could unlock an entire wave of tools for filmmakers, educators, advertisers, and game developers.
End Note
We’ve seen major leaps in AI-generated content over the past year—from image diffusion models to large language agents. But MoCha brings something new: a step closer to script-to-screen generation.
No keyframes. No manual animation. Just natural language and a voice.
If future iterations of MoCha build on this foundation – adding longer scenes, background elements, emotional dynamics, and real-time responsiveness, it could change how content is created across industries. For now, it’s a remarkable research achievement. Definitely one to watch closely.
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.





