The creation and deployment of applications that utilize Large Language Models (LLMs) comes with their own set of problems. LLMs have non-deterministic nature, can generate plausible but false information and tracing their actions in convoluted sequences can be very troublesome. In this guide, we’ll see how Langfuse comes up as an essential instrument for solving these problems, by offering a strong foundation for whole observability, assessment, and prompt handling of LLM applications.
Table of contents
What is Langfuse?
Langfuse is a groundbreaking observability and assessment platform that is open source and specifically created for LLM applications. It is the foundation for tracing, viewing, and debugging all the stages of an LLM interaction, starting from the initial prompt and ending with the final response, whether it is a simple call or a complicated multi-turn conversation between agents.

Langfuse is not only a logging tool but also a means of systematically evaluating LLM performance, A/B testing of prompts, and collecting user feedback which in turn helps to close the feedback loop essential for iterative improvement. The main point of its value is the transparency that it brings to the LLMs world, thus letting the developers to:
- Understand LLM behaviour: Find out the exact prompts that were sent, the responses that were received, and the intermediate steps in a multi-stage application.
- Find issues: Locate the source of errors, low performance, or unexpected outputs rapidly.
- Quality evaluation: Effectiveness of LLM responses can be measured against the pre-defined metrics with both manual and automated measures.
- Refine and improve: Data-driven insights can be used to perfect prompts, models, and application logic.
- Handle prompts: control the version of prompts and test them to get the best LLM.
Key Features and Concepts
There are various key features that Langfuse offers like:
- Tracing and Monitoring
Langfuse helps us capturing the detailed traces of every interaction that LLM has. The ‘trace’ is basically the representation of an end-to-end user request or application flow. Within a trace, logical units of work is denoted by “spans” and calls to an LLM refers to “generations”.
- Evaluation
Langfuse allows evaluation both manually and programmatically as well. Custom metrics can be defined by the developers which can then be used to run evaluations for different datasets and then be integrated as LLM-based evaluators.
- Prompt Management
Langfuse provides direct control over prompt management along with storage and versioning capabilities. It is possible to test various prompts through A/B testing and at the same time maintain accuracy across diverse places, which paves the way for data-driven prompt optimization as well.
- Feedback Collection
Langfuse absorbs the user suggestions and incorporates them right into your traces. You will be able to link particular remarks or user ratings to the precise LLM interaction that resulted in an output, thus giving us the real-time feedback for troubleshooting and enhancing.

Why Langfuse? The Problem It Solves
Traditional software observability tools have very different characteristics and do not satisfy the LLM-powered applications criteria in the following aspects:
- Non-determinism: LLMs will not always produce the same outcome even for an identical input which makes debugging quite challenging. Langfuse, in turn, records each interaction’s input and output giving a clear picture of the operation at that moment.
- Prompt Sensitivity: Any minor change in a prompt might alter LLM’s answer completely. Langfuse is there to help keeping track of prompt versions along with their performance metrics.
- Complex Chains: The majority of LLM applications are characterized by a combination of multiple LLM calls, different tools, and retrieving data (e.g., RAG architectures). The only way to know the flow and to pinpoint the place where the bottleneck or the error is the tracing. Langfuse presents a visual timeline for these interactions.
- Subjective Quality: The term “goodness” for an LLM’s answer is often synonymous with personal opinion. Langfuse enables both objective (e.g., latency, token count) and subjective (human feedback, LLM-based evaluation) quality assessments.
- Cost Management: Calling LLM APIs comes with a price. Understanding and optimizing your costs will be easier if you have Langfuse monitoring your token usage and call volume.
- Lack of Visibility: The developer is not able to see how their LLM applications are performing on the market and therefore it is hard for them to make these applications gradually better because of the lack of observability.
Langfuse does not only offer a systematic method for LLM interaction, but it also transforms the development process into a data-driven, iterative, engineering discipline instead of trial and error.
Getting Started with Langfuse
Before you can start using Langfuse, you must first install the client library and set it up to transmit data to a Langfuse instance, which could either be a cloud-hosted or a self-hosted one.
Installation
Langfuse has client libraries available for both Python and JavaScript/TypeScript.
Python Client
pip install langfuse JavaScript/TypeScript Client
npm install langfuse Or
yarn add langfuse Configuration
After installation, remember to set up the client with your project keys and host. You can find these in your Langfuse project settings.
- public_key: This is for the frontend applications or for cases where only limited and non-sensitive data are getting sent.
- secret_key: This is for backend applications and scenarios where the full observability, including sensitive inputs/outputs, is a requirement.
- host: This refers to the URL of your Langfuse instance (e.g., https://cloud.langfuse.com).
- environment: This is an optional string that can be used to distinguish between different environments (e.g., production, staging, development).
For security and flexibility reasons, it is considered good practice to define these as environment variables.
export LANGFUSE_PUBLIC_KEY="pk-lf-..."
export LANGFUSE_SECRET_KEY="sk-lf-..."
export LANGFUSE_HOST="https://cloud.langfuse.com"
export LANGFUSE_ENVIRONMENT="development"Then, initialize the Langfuse client in your application:
Python Example
from langfuse import Langfuse
import os
langfuse = Langfuse(public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"), secret_key=os.environ.get("LANGFUSE_SECRET_KEY"), host=os.environ.get("LANGFUSE_HOST"))JavaScript/TypeScript Example
import { Langfuse } from "langfuse";
const langfuse = new Langfuse({ publicKey: process.env.LANGFUSE_PUBLIC_KEY, secretKey: process.env.LANGFUSE_SECRET_KEY, host: process.env.LANGFUSE_HOST});Setting up Your First Trace
The fundamental unit of observability in Langfuse is the trace. A trace typically represents a single user interaction or a complete request lifecycle. Within a trace, you log individual LLM calls (generation) and arbitrary computational steps (span).
Let’s illustrate with a simple LLM call using OpenAI’s API.
Python Example
import os
from openai import OpenAI
from langfuse import Langfuse
from langfuse.model import InitialGeneration
# Initialize Langfuse
langfuse = Langfuse(
public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),
secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),
host=os.environ.get("LANGFUSE_HOST"),
)
# Initialize OpenAI client
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def simple_llm_call_with_trace(user_input: str):
# Start a new trace
trace = langfuse.trace(
name="simple-query",
input=user_input,
metadata={"user_id": "user-123", "session_id": "sess-abc"},
)
try:
# Create a generation within the trace
generation = trace.generation(
name="openai-generation",
input=user_input,
model="gpt-4o-mini",
model_parameters={"temperature": 0.7, "max_tokens": 100},
metadata={"prompt_type": "standard"},
)
# Make the actual LLM call
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": user_input}],
temperature=0.7,
max_tokens=100,
)
response_content = chat_completion.choices[0].message.content
# Update generation with the output and usage
generation.update(
output=response_content,
completion_start_time=chat_completion.created,
usage={
"prompt_tokens": chat_completion.usage.prompt_tokens,
"completion_tokens": chat_completion.usage.completion_tokens,
"total_tokens": chat_completion.usage.total_tokens,
},
)
print(f"LLM Response: {response_content}")
return response_content
except Exception as e:
# Record errors in the trace
trace.update(
level="ERROR",
status_message=str(e)
)
print(f"An error occurred: {e}")
raise
finally:
# Ensure all data is sent to Langfuse before exit
langfuse.flush()
# Example call
simple_llm_call_with_trace("What is the capital of France?")Eventually, your next step after executing this code would be to go to the Langfuse interface. There will be a new trace “simple-query” that consists of one generation “openai-generation”. It’s possible for you to click it in order to view the input, output, model used, and other metadata.
Core Functionality in Detail
Learning to work with trace, span, and generation objects is the main requirement to take advantage of Langfuse.
Tracing LLM Calls
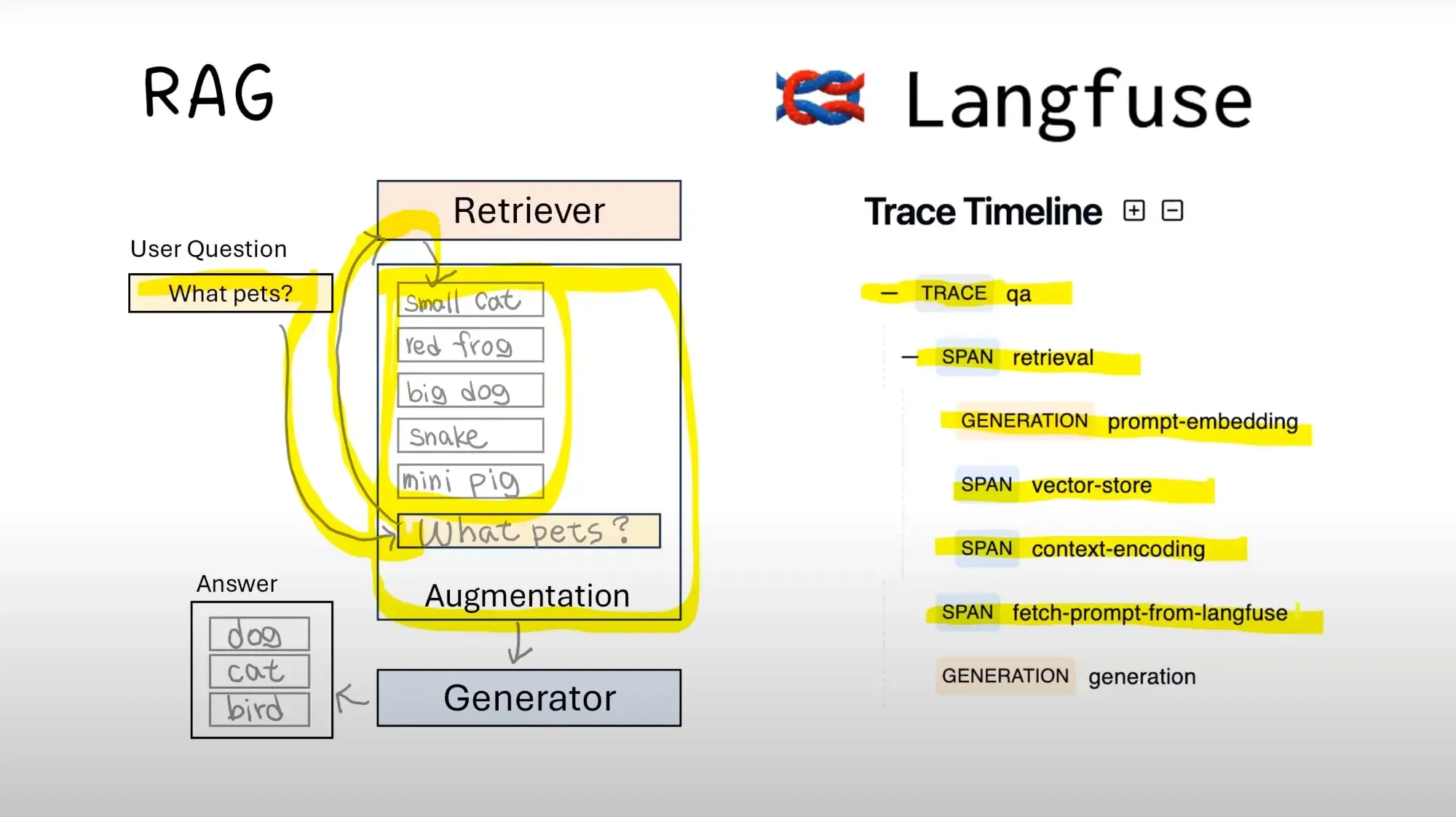
langfuse.trace(): This command starts a new trace. The top-level container for a whole operation.- name: The trace’s very descriptive name.
- input: The first input of the whole procedure.
- metadata: A dictionary of any key-value pairs for filtering and analysis (e.g.,
user_id,session_id,AB_test_variant). - session_id: (Optional) An identifier shared by all traces that come from the same user session.
- user_id: (Optional) An identifier shared by all interactions of a particular user.
trace.span(): This is a logical step or minor operation within a trace that is not a direct input-output interaction with the LLM. Tool calls, database lookups, or complex calculations can be traced in this way.- name: Name of the span (e.g. “retrieve-docs”, “parse-json”).
- input: The input relevant to this span.
- output: The output created by this span.
- metadata: The span metadata is formatted as additional.
- level: The severity level (INFO, WARNING, ERROR, DEBUG).
- status_message: A message that is linked to the status (e.g. error details).
- parent_observation_id: Connects this span to a parent span or trace for nested structures.
trace.generation(): Signifies a particular LLM invocation.- name: The name of the generation (for instance, “initial-response”, “refinement-step”).
- input: The prompt or messages that were communicated to the LLM.
- output: The reply received from the LLM.
- model: The precise LLM model that was employed (for example, “gpt-4o-mini“, “claude-3-opus“).
- model_parameters: A dictionary of particular model parameters (like
temperature,max_tokens,top_p). - usage: A dictionary displaying the number of tokens utilized (
prompt_tokens,completion_tokens,total_tokens). - metadata: Additional metadata for the LLM invocation.
- parent_observation_id: Links this generation to a parent span or trace.
- prompt: (Optional) Can identify a particular prompt template that is under management in Langfuse.
Conclusion
Langfuse makes the development and upkeep of LLM-powered applications a less strenuous undertaking by turning it into a structured and data-driven process. It does this by giving developers access to the interactions with the LLM like never before through extensive tracing, systematic evaluation, and powerful prompt management.
Moreover, it encourages the developers to debug their work with certainty, speed up the iteration process, and keep on improving their AI products in terms of quality and performance. Hence, Langfuse provides the necessary instruments to make sure that LLM applications are trustworthy, cost-effective, and really powerful, no matter if you are developing a basic chatbot or a sophisticated autonomous agent.
Frequently Asked Questions
Q1. What problem does Langfuse solve for LLM applications?
A. It gives you full visibility into every LLM interaction, so you can track prompts, outputs, errors, and token usage without guessing what went wrong.
Q2. How does Langfuse help with prompt management?
A. It stores versions, tracks performance, and lets you run A/B tests so you can see which prompts actually improve your model’s responses.
Q3. Can Langfuse evaluate the quality of LLM outputs?
A. Yes. You can run manual or automated evaluations, define custom metrics, and even use LLM-based scoring to measure relevance, accuracy, or tone.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]





