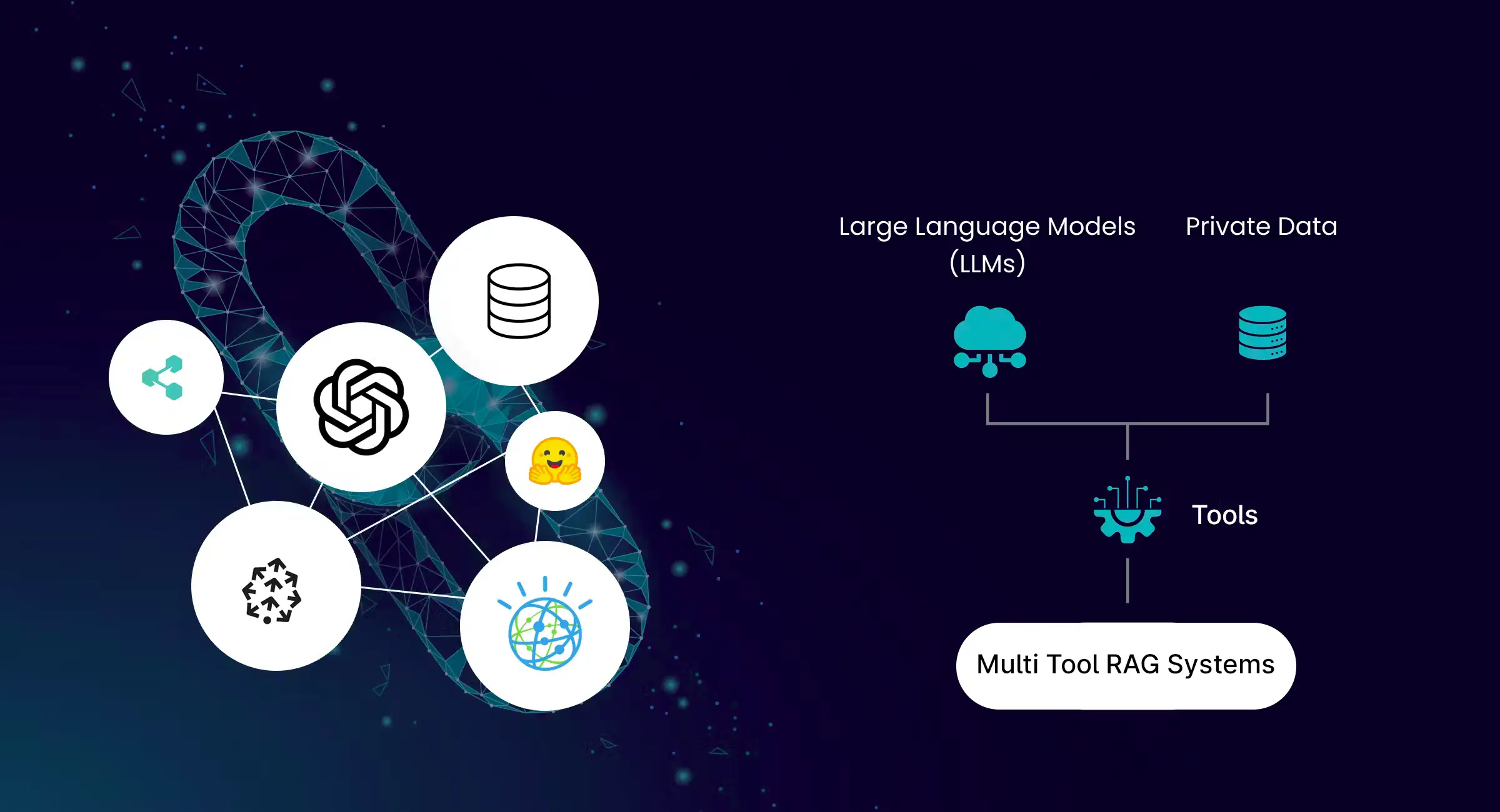
Retrieval-Augmented Generation commonly known as RAG is the latest advancement in the field of Artificial IntellienceI and Natural Language Processing. It is an AI framework that enhances the accuracy and reliability of Generative AI models by incorporating relevant information from external databases as context during generation. Fundamentally, we can say that RAG is a hybrid of two critical components.
- The Retrieval-based component involves various techniques to access and extract information from external knowledge sources.
- The Generative-based component excels in generating human-like text based on its training ability.

But what really makes RAG stand out is its ability to find the perfect sync between these two components, that allows it to deeply understand the meaning behind a user query and generate responses that are not only accurate but also contextually rich.
Why Has RAG Become Important Lately?
RAG helps overcome some of the limitations of the pre-existing generative AI models, particularly Large Language Models (LLMs).

- RAGs help overcome knowledge-based limitations:
While existing LLMs may be powerful, their knowledge base is limited to the point in time where they were trained. The pace at which updates and information are passed on in today’s world makes these models slack. RAG helps solve this major problem by retrieving up-to-date, relevant information on the go from external sources which allows an LLM to provide more accurate and relevant responses. By dynamically retrieving up-to-date information, RAG has also helped solve the problem of hallucination. Traditional Generative AI models tend to generate incorrect information because these traditional models predict text based solely on patterns they came across during training.
- RAGs can help models handle large or specialized domains:
It is expensive and inconvenient to train an LLM in a single specialized domain. In order to overcome this problem, RAG allows models to dynamically retrieve information on the go making it a much more efficient approach for specialized domains such as medicine, finance, law, and so on, where the accuracy and relevancy of the generated information are critical.
- RAGs help reduce the overall model size:
Traditional Generative AI models rely on the massive data it is trained upon to learn and recreate patterns. By simply applying RAG to the models, one can create a smaller model and retrieve information on the go, as and when required which makes these models much largely scalable and highly efficient in terms of resources.
- RAGs can also provide the user with a source citation:
RAG-based Generative AI models can clearly provide sources based on which they have generated the responses which help enhance transparency and credibility of the provided output resulting in an increased overall trust in AI-generated content.
Without a doubt, RAG has become the go-to technique when it comes to performance enhancement of your Generative AI models and in scenarios where the required information has to be up-to-date with a high reliability factor.
A Comprehensive Guide to Building Agentic RAG Systems with LangGraph
Graph RAG: Enhancing Retrieval-Augmented Generation with Graph Structures
A Guide to Evaluate RAG Pipelines with LlamaIndex and TRULens
Enhancing RAG with Retrieval Augmented Fine-tuning
Unveiling Retrieval Augmented Generation (RAG)| Where AI Meets Human Knowledge
Understanding Multimodal RAG: Benefits and Implementation Strategies
Improving Real-World RAG Systems: Key Challenges & Practical Solutions
Deconstructing RAG’s Mechanics
Now that you understand the importance of RAG, let’s understand the basic steps involved in the process.

- The first step in the working of a RAG model is Data Ingestion. The generative AI model begins by receiving the user input and then processing it.

- The model then proceeds to analyze the input provided by the user to grasp its meaning and intent.

- With the implementation of RAG, the model utilizes access to external knowledge sources and begins to retrieve information based on its understanding. This step further enhances the understanding of the user’s query to enhance comprehension.
- The model then proceeds to craft a response using its existing generative capabilities and the knowledge obtained from the external sources ensuring the responses are factually accurate and contextually relevant with an additional human touch.
Note: Memory also plays an extremely crucial role in RAG effectively combining the integrated retrieved knowledge with the next generation process. RAGs can “remember” and recall relevant information generated during a conversation with a user which allows it to apply this previous retrieval into subsequent multiple queries. This makes RAG context-aware over time making it handy for complex tasks.
From this, you’ve obtained an overview of the mechanics behind RAG. But what powers RAG is the external sources of data. In the next section let’s look at the different external data sources that empower the RAG framework.
How to Build a RAG Evaluator Python Package with Poetry?
12 RAG Pain Points and their Solutions
How to Find the Best Multilingual Embedding Model for Your RAG?
RAG Application with Cohere Command-R and Rerank – Part 1
External Data Sources that Empower the RAG Framework
APIs and Real-time Databases
Application Programming Interfaces, commonly referred to as APIs are real-time databases that are rich in information and provide the most up-to-the-minute data to any RAG-driven model. Any data that is accessible to the public is available to a model using APIs.

Document Repositories
Document repositories are fundamental when it comes to expanding the knowledge base of RAGs. They offer both structured information such as knowledge graphs or relational databases as well as unstructured information such as raw text, webpages, documents and so on which do not follow any specific structure. Note that both these forms of data are key to any RAG-based model.
Webpages and Scraping
Web scraping, just like the name suggests, is used to refer to the method of browsing web pages and scraping information off them. This source of dynamic web content is critical to a RAG making it a crucial source for real-time data retrieval.
Databases and Structured Information
Databases provide structured data that can be queried and extracted. Additionally, RAG models can utilize databases to retrieve specific information, thereby enhancing the accuracy of their responses.
With the basics covered in detail, next, let’s understand the fundamental difference between methods such as prompt engineering, RAG, fine-tuning and pretraining a model.
Building RAG Application using Cohere Command-R and Rerank – Part 2
Fine-Tuning and RAG: Which One Is Better?
A Beginner’s Guide to Evaluating RAG Pipelines Using RAGAS
How to select between Fine-Tuning and RAG?
There are several factors one must take into consideration when selecting the suitable approach for a task such as the particular problem you wish to solve, the amount of data available specific to the domain for which you wish to solve the problem, and resource constraints. Based on the previous section, we have a brief idea. Let’s break it down further in this section to understand when to select between Fine-Tuning and RAG.

Flexibility:
RAG is considered to be a much more flexible model as it doesn’t require any particular retraining to adapt to new knowledge. It dynamically scrapes external resources for up-to-date information on any specific domain. Fine-tuning, on the other hand, requires the model to be trained again every single time updated data or resources need to be incorporated.
Efficiency and Performance
This makes RAG a much more efficient model for tasks where real-time information or large-scale knowledge integration is needed as the retraining involved in fine-tuning requires way more resources to be allocated. In scenarios where the user has a well outlined task and a large amount of training data available, then fine-tuning will be the more handy approach but note that this model will not be able to handle any real-time updates.
Resources Required:
Since RAGs are capable of scraping data off the web and other external resources, the model is much more lightweight in comparison to a fine tuned model which requires a very large amount of labeled data. GPUs or TPUs to update the model weights on your task-specific data. RAG also generally has a lower retraining cost, but the catch is that retrieving information from a large repository can introduce latency and infrastructure costs.
Let’s look at some key applications of RAG in Industries in the next section.
Learn More: A Comprehensive Guide to Fine-Tuning Large Language Models
Practical Applications of RAG in Industries
- Meta developed its RAG model particularly to improve the retrieval-augmented question-answering systems. Meta leveraged RAG in their customer-facing tools to effectively answer the queries of users in a way that is based majorly on factual information retrieved from large-scale knowledge sources and user manuals.
- Google also unvieled Vertex AI Search in earlier 2024 and made generally available in August, to utilize their deep experience in retrieval of information and generative AI to help enterprises enable their customers, employees, and other stakeholders to discover critical information at speed, uncover hidden insights across data, and improve productivity. The easy setup and out-of-box capabilities of Vertex AI Search reduce the time it takes to build search applications from weeks and months to mere days or hours.
- Microsoft’s Copilot is a prominent example of the use of RAG in conversational AI. Microsoft has integrated Copilot into Word and Excel which can help users retrieve relevant data or information and use it to generate reports and even write e-mails.
- IBM Watsonx Assistant uses RAG in healthcare to retrieve their patient data, medical history, and previous clinical diagnosis, to generate recommendations for a recommended treatment plan and diagnoses.
- Elsevier, a scientific publishing company, has lately started to implement RAGs in their AI-based research tools. These tools are capable of retrieving information from millions of academic papers available in their database and then provide the user with a crisp summary or recommendations for researchers even on domain specific topics such as cancer research and so on.
- Salesforce has integrated its search engine Einstein GPT with RAGs in their knowledge management systems. This allows their sales teams as well as the customer support teams to retrieve required documentation, answer FAQs, or generate user manuals with ease and generate accurate responses for customers.
- Bloomberg is the first of it’s kind to use RAGs in its financial services. Their model BloombergGPT successfully retrieves up-to-date stock market information and reports and generates insights and reports based on this data saving the time taken if this had to be done manually.
Apart from these real-world practical examples, Agentic RAG has started creating a buzz in the world of AI. Agentic RAG is the term used to refer to a system when a RAG model completes tasks autonomously by making logic backed decisions from the retrieved information. Rather than taking actions completely based on a user’s query, the RAG system thinks ahead and collates the relevant information in advance, allowing for a faster and dynamic real-time decision. Agentic RAGs in the near future can surely help in complex decision making scenarios such as financial analysis where real-time decisions enhance productivity.
Similarly another innovation in the field of AI involving RAG lately has been the incorporation of RAG chatbots. These are systems that utilize the RAG framework to create fully automated chatbots that can respond with the most up to date information from external resources. This makes them ideal for customer care services, healthcare domain and even for legal advice due to the nature of the responses which are not just factually accurate but also contextually rich and relevant to the user’s query.
With these practical examples of how RAG is leveraged clearly demonstrates its growing adoption and acceptance across industries. In the next section let’s understand the drawbacks of RAGs.
Also read: How to Build a RAG Chatbot for Insurance?
Drawbacks of RAGs

Throughout this article, you may have already come across several drawbacks of RAG. Let’s quickly summarize them in this section.
- Since RAGs are highly dependent on the quality of the retrieved information, if inaccuracies exist in them, then the generated content also may not be completely reliable.
- There still exists a significant delay when RAGs are given very large databases or repositories to extract information from. This significant latency makes RAGs less suitable in scenarios where the given application may be time-sensitive.
- Since RAGs combine 2 different architectures, even though the model may be lightweight, the overall architecture is complex. Additionally, you may require more infrastructure to maintain and enhance the retrieval process search as search indexes which makes RAG models difficult to maintain. This poses a challenge to the scalability of RAG models too owing to the difficulty in maintaining them.
- While RAGs can scrape information off both structured and unstructured data, there still exists a major difficulty when a RAG is required to collect the most relevant information from unstructured data such as webpages or free text. This may lead to low quality in the generated output.
- Hallucinations still continue to be one of the biggest drawbacks that any Generative AI based model faces.
Overall, there still exist certain challenges that need to be addressed even though RAG based models have significantly improved performance. In the next section, let’s look at what to expect in the near future from RAGs.
Also read: 12 RAG Pain Points and their Solutions
The Future of RAGs (What to Expect)

With the rate at which advancements are happening in today’s world, we can expect several major advancements in RAGs.
- First off, we can surely expect advancements in semantic search and dense vector retrieval. These techniques will improve the precision with which RAG retrieves content from external sources and thus expand its grip over more specialized domains.
- We can also expect future RAG systems to focus on personalized customer data retrieval, to ensure they consume content that suits their likes and needs based on historical data. This technology can also help improve recommendation systems and reduce the burden on customer services.
- Currently, one of the major drawbacks with respect to RAGs is the latency in retrieving large-scale data. Surely, we can expect RAGs to retrieve data even more effortlessly while scaling up their ability to handle massive knowledge repositories.
- We can also expect models that update on their own by integrating with external databases and APIs. These techniques will help RAG models learn and consume information continuously from real-time data, reducing any requirement of manual retraining and giving improved performance too.
- One can also expect RAG-based models to play a crucial role in retrieving not just text data but also image data from external sources, proving to be a game changer for content creators, media analysts, and so on.
- We can also expect cross-modal integration using RAG in the near future where combined data from external sources including audio, video, and text will be used to produce diverse outputs. This can be crucial for tasks such as interactive virtual assistants, augmented reality systems, and autonomous vehicles. We can also expect these RAG-based models to integrate with IoT sensors and make real-time decisions relying solely on historical data and logic.
With all these advancements expected to arrive in the near future, there are certain ethical considerations that also need to be taken into account.
Also read: A Guide to Building Agentic RAG Systems with LangGraph
Ethical Considerations and Fairness in RAG Models
Bias and Unverified Information: One key point to remember is that do not believe everything you read on the web. RAG systems, if not prone, but are certainly at the risk of pulling out biased or unverified information from external sources that may be open to the public. This biased information can affect the overall accuracy and fairness of the generated content. As these systems solely depend on external data fetched from resources, it is challenging is to ensure that the data retrieved is neutral and factually verified.
Accountability and Transparency: As RAG models grow in importance, they need to be transparent to understand how companies train their models. Problems related to data transparency and fair access to information may arise if certain bigger companies bring the money factor into the data retrieval process
Sensitive and Personal Data: Just like with any AI-based model, the concern regarding sensitive and personal data is never-ending. Since the RAG model retrieves data from external sources, companies must maintain a policy over private data and put measures in place so that RAG systems cannot access them without proper authorization. This is key especially when it comes to healthcare and legal domains where RAG is currently expanding.
We hope you have understood the basics of RAG, along with its framework, practical applications, ethical considerations and also took a sneak peek into what the future looks like for RAG based applications.Also, don’t forget to checkout our free course on RAG at – Building first RAG systems using Llamaindex
By combining the creativity of generative models with the precision of targeted data retrieval, RAG systems can deliver responses that are not only informative but also contextually spot-on.
Take a look at the Top 5 RAG tools or libraries that are leading the charge. LangChain, LlamaIndex, Haystack, RAGatouille, and EmbedChain.
For those of you looking to unlock your full potential, Join the GenAI Pinnacle Program where you can learn how to build such Agentic AI systems in detail! Revolutionize your AI learning and development journey through 1:1 mentorship with Generative AI experts, an advanced curriculum offering over 200 hours of intensive learning, and mastery of 26+ GenAI tools and libraries. Elevate your skills and become a leader in AI.
Resources of RAG to Read
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Fine-tune the Entire RAG Architecture (including DPR retriever) for Question-Answering
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
RAFT: Adapting Language Model to Domain Specific RAG
End-to-End Training of Neural Retrievers for Open-Domain Question Answering
RAGAS: Automated Evaluation of Retrieval Augmented Generation
PaperQA: Retrieval-Augmented Generative Agent for Scientific Research
Retrieval-Augmented Generation for Large Language Models: A Survey
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
Books on Retrieval-Augmented Generation(RAG)
Retrieval Augmented Generation (RAG) AI: A Comprehensive Guide to Building and Deploying Intelligent Systems with RAG AI (AI Explorer Series) – Link
Also read: 9 Best Large Language Model (LLM) Books of All Time
Mastering RAG Models: A Practical Guide to Building Retrieval-Augmented Generation Systems for Enhanced NLP Applications and Improved Text Generation of LLMs – Link
Also read: A Simple Guide to Retrieval Augmented Generation
Frequently Asked Questions
Q1. What is a RAG?
Ans. Retrieval-Augmented Generation commonly known as RAG is the latest advancement in the field of AI and Natural Language Processing. It is an AI framework that enhances the accuracy and reliability of Generative AI models by incorporating relevant information from external databases as context during generation.
Q2. Why are RAGs important?
Ans. RAGs play a crucial role by leveraging external sources of data to retrieve up-to-date relevant information based on which content is generated depending on the query input by the user. It is suitable for tasks that require real-time-data
Q3. Why should I use a RAG over Fine-tuning a model?
Ans. While it is not mandated to use a RAG, in certain scenarios where you do not have enough data to train a model over a specific domain, RAGs may be more suitable. If you are short of resources, but have sufficient data based on the domain, then fine tuning your base model would be a more suitable option.
Q4. Are RAGs completely reliable?
Ans. RAGs help retrieve up-to-date relevant information from external data sources, but always keep in mind that since RAGs depend heavily on external data sources to generate their content, the source also has to be reliable. Else, the model may generate inaccurate information.
Q5. Does implementing RAGs require more resources?
Ans. While RAGs do require sufficient computational resources, note that RAGs reduce the need for a large pre-trained model as data retrieval is done from external sources. This means that the model is smaller and more scalable.